SQL Server Installation maakt standaard meerdere systeemdatabases per instance om die instance te onderhouden en te beheren. In dit artikel zullen we deze systeemdatabases onderzoeken en hun verantwoordelijkheden begrijpen.
SQL Server-systeemdatabases
In SQL Server worden tijdens het installatieproces systeemdatabases gemaakt om de SQL Server-instantiespecifieke configuratiedetails op te slaan om normaal te kunnen functioneren. Elke installatie van SQL Server creëert minimaal 5 systeemdatabases en 1 replicatiegerelateerde systeemdatabase genaamd distributiedatabase die door gebruikers wordt gemaakt als Replicatie in dat geval is geconfigureerd. Elke systeemdatabase heeft zijn doel en we zullen dit later in dit artikel in detail onderzoeken.
De systeemdatabases zijn:
- Master – Standaard geïnstalleerd
- Msdb – Standaard geïnstalleerd
- Model – Standaard geïnstalleerd
- Tempdb – Standaard geïnstalleerd
- Bron – Standaard geïnstalleerd . Geïntroduceerd in SQL Server 2005 en beschikbaar in latere versies van SQL Server en dus niet beschikbaar in SQL Server 2000 en eerdere versies.
- Distributie – Gemaakt door gebruikersactie . Gebruikers kunnen de distributiedatabase maken om replicatie te configureren.
Om de systeemdatabase te bekijken die is geïnstalleerd in SQL Server, kunnen we SSMS gebruiken.
Maak verbinding met uw SQL Server-instantie, vouw Databases uit > Systeemdatabases :
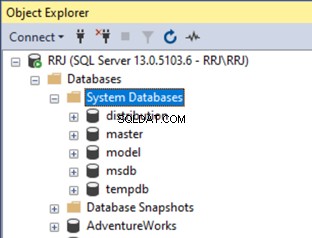
Is het je opgevallen dat de Bron database ontbreekt in de bovenstaande lijst? Het punt is dat de resourcedatabase een speciale systeemdatabase is die niet wordt vermeld in de SSMS Object Explorer. We kunnen echter de gegevens van de resourcedatabase opvragen vanuit een systeem-DMV met de naam sys.sysaltfiles en voer de query uit:
SELECT dbid, db_name(dbid) database_name, fileid, name, filename
FROM sys.sysaltfiles
WHERE dbid NOT BETWEEN 5 AND 11
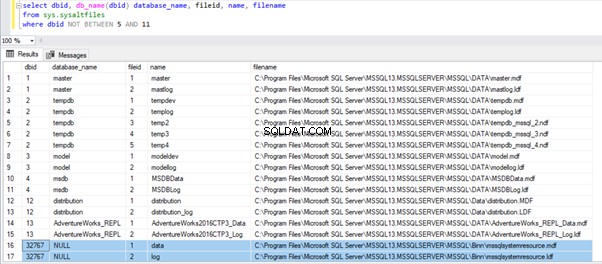
In de resultaten kunnen we de systeemdatabases in volgorde zien:master, tempdb, model, msdb, distributie , en tot slot de dbid 32767 dat is een bronnendatabase. Deze brondatabase geeft echter geen databasenaam weer omdat deze geen vermelding heeft in sys.databases . Ik heb een aantal gebruikersdatabases tussen dbid 5 en 11 uitgesloten en AdventureWorks_REPL toegevoegd als voorbeeld om aan te tonen dat DMV ook gebruikersdatabases kan weergeven. We zullen later meer in detail treden over de Resource-database en andere systeemdatabases.
SQL-systeemdatabasebeperkingen
Aangezien systeemdatabases kritieke systeemconfiguratiedetails bevatten, moeten er passende beveiligingsmaatregelen worden genomen om te voorkomen dat gegevens per ongeluk worden verwijderd. Daarom hebben systeemdatabases de onderstaande beperkingen in vergelijking met gebruikersdatabases:
Systeemdatabases kunnen niet offline worden gehaald
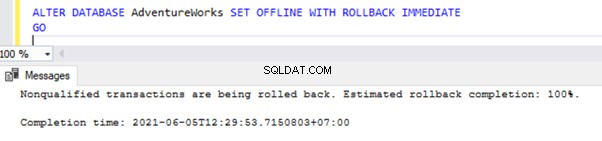
We kunnen een gebruikersdatabase offline halen met het ALTER DATABASE-commando, zoals hieronder weergegeven:
ALTER DATABASE AdventureWorks SET OFFLINE WITH ROLLBACK IMMEDIATE
GO
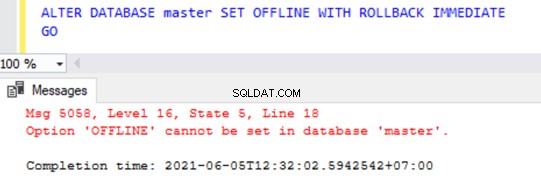
Als we echter proberen een van de systeemdatabases OFFLINE te halen met de bovenstaande opdracht, krijgen we een foutmelding zoals hieronder weergegeven:
Systeemdatabases kunnen niet worden verwijderd
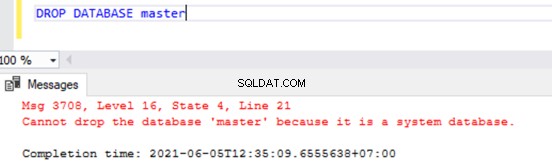
Hoewel we de gebruikersdatabases kunnen verwijderen door de opdracht DROP DATABASE uit te voeren
DROP DATABASE AdventureWorksAls we proberen een van de systeemdatabases te DROPPEN, krijgen we de onderstaande foutmelding:
Eigenaar van systeemdatabases kan niet worden gewijzigd
De eigenaar van de systeemdatabase is sa standaard. Het kan niet worden gewijzigd. Pogingen om de eigenaar van de systeemdatabase te hernoemen zullen fouten veroorzaken.
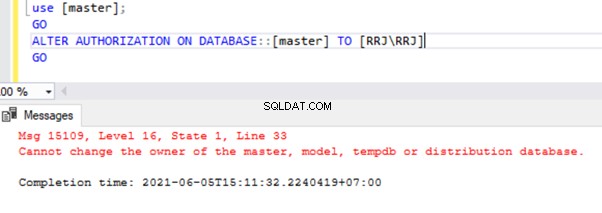
Er is echter een uitzondering. Het is mogelijk om de eigenaar van de msdb . te wijzigen database.
use [master];
GO
ALTER AUTHORIZATION ON DATABASE::[master] TO [RRJ\RRJ]
GO
Databasenaam van systeemdatabases kan niet worden gewijzigd
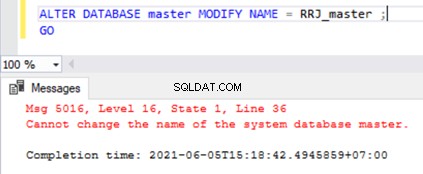
Als we proberen de systeemdatabases te hernoemen, krijgen we een foutmelding zoals hieronder weergegeven:
ALTER DATABASE master MODIFY NAME = RRJ_master;
GO
De verzameling van systeemdatabases kan niet worden gewijzigd
Systeemdatabases worden gemaakt met de sorteernaam die is gekozen tijdens de installatie van SQL Server. Eenmaal geïnstalleerd, kan de sortering van systeemdatabases niet worden gewijzigd. De enige manier om de sortering van de systeemdatabases te wijzigen, is door de SQL Server-instantie opnieuw te installeren met de juiste sortering.
Primaire bestandsgroep van systeemdatabases kan niet worden ingesteld op READ_ONLY-modus
Aangezien de systeemdatabase kritieke informatie vastlegt met betrekking tot SQL Server-instanties, staat SQL Server niet toe dat de primaire gegevensbestanden die zich in de primaire bestandsgroep bevinden, worden ingesteld als alleen-lezen .
De functie voor het vastleggen van gegevens wijzigen kan niet worden ingeschakeld op systeemdatabases
Deze functie wordt gebruikt om elke DML-wijziging te volgen die plaatsvindt in een database op de bijgehouden tabellen. Als we proberen de functie Gegevens vastleggen wijzigen in te schakelen voor systeemdatabases, treedt de fout op:
use master
GO
exec sys.sp_cdc_enable_db

Nu we duidelijk zijn over het verschil tussen systeemdatabases en gebruikersdatabases, kunnen we de doeleinden van elke systeemdatabase in meer detail onderzoeken.
Hoofddatabase in SQL Server
De hoofdsysteemdatabase bevat belangrijke configuratiedetails met betrekking tot de SQL Server-instantie . SQL Server vertrouwt erop wanneer het een bepaald exemplaar start. Als het om de een of andere reden onmogelijk is om de hoofddatabase te starten, kan de SQL Server-instantie ook niet starten.
Deze belangrijke details die zijn opgeslagen in de hoofddatabase, omvatten de aanmeldingsaccounts, gegevens van de gekoppelde server, eindpunten, systeemconfiguratie-instellingen en details over alle gebruikersdatabases.
Nu komt de vraag. Hoe weet de SQL Server-service waar de gegevens en logbestanden van de hoofddatabase beschikbaar zijn? Het antwoord ligt in de opstartconfiguratieparameters van de SQL Server-service.
Om de parameters voor de opstartconfiguratie van een SQL Server-instantie te bekijken, moeten we eerst iets weten over het ingebouwde hulpprogramma met de naam SQL Server Configuration Manager . Het helpt bij het beheren van alle SQL Server-gerelateerde services van alle instances die beschikbaar zijn op de specifieke server. Om deze gegevens te bekijken, opent u de SQL Server Configuration Manager en het zal de lijst weergeven zoals hieronder getoond:
Klik op SQL Server Services om de lijst met beschikbare services op deze server of pc te bekijken:
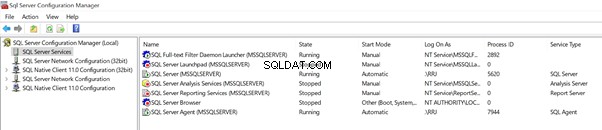
Wacht even! Het ziet er bekend uit voor de services.msc een lijst van alle services die beschikbaar zijn op de server, maar met alleen SQL Server-gerelateerde services.
Laten we services.msc openen om te zien hoe het eruit ziet en om de verschillen te verifiëren tussen SQL Server Configuration Manager en services.msc om te vergelijken welke beter is.
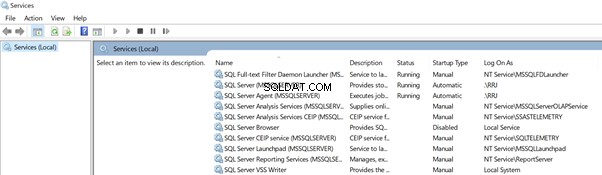
De SQL Server Configuration Manager geeft de proces-ID weer van de services die momenteel worden uitgevoerd. We konden dat niet vinden in services.msc . Natuurlijk kunnen we deze informatie uit Windows Taakbeheer halen, maar SQL Server Configuration Manager heeft ons geholpen dit op één plek te bekijken.
Laten we nu een gedetailleerd overzicht nemen. Klik met de rechtermuisknop op de SQL Server-service vanuit services.msc . U ziet de onderstaande menu's:Algemeen , Aanmelden , Herstel , en Afhankelijkheden .
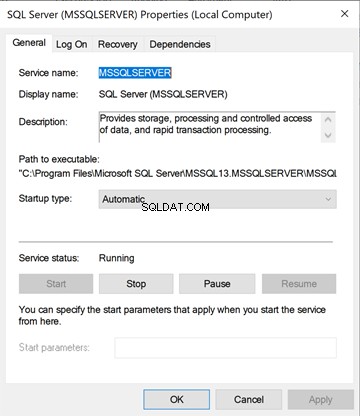
Klik vanuit SQL Server Configuration Manager met de rechtermuisknop op de SQL Server(MSSQLSERVER) service> Eigenschappen . Het bevat de onderstaande menu's - Aanmelden, Service. FileStream, Advanced, Alwayson OnHigh Availability , en Opstartparameters .
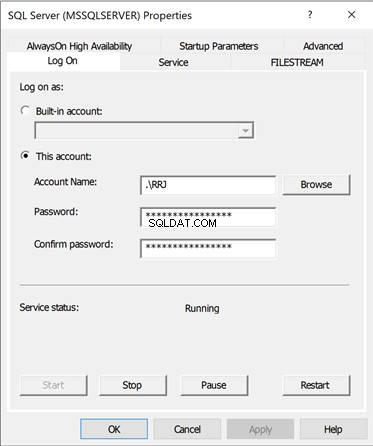
De opstartparameters van de service die de locatie van de hoofddatabasegegevens en logbestanden opslaat was alleen beschikbaar in de SQL Server Configuration Manager .
Klik op Opstartparameters om de details te bekijken – voor Bestaand Parameters . U ziet de volgende informatie:
- De fysieke locatie van de hoofddatabase Databestand
- De fysieke locatie van de hoofddatabase Transactielogboekbestand
- De fysieke locatie van de ErrorLog-map waar fouten met betrekking tot SQL Server Service zich bevinden.
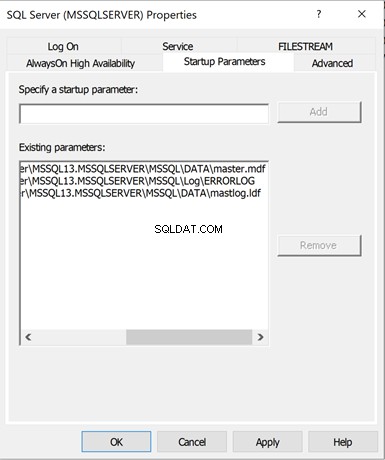
We kunnen meer opstartparameters toevoegen, zoals modus voor één gebruiker (-m) , enz. Daarvoor moeten we de benodigde waarden specificeren in Specificeer een opstartparameter en klik op Toevoegen .
We hebben gemerkt dat SQL Server Configuration Manager niet alleen geavanceerde details weergeeft, maar ons ook in staat stelt veel geavanceerde configuraties uit te voeren met betrekking tot SQL Server-service. Daarom zou ik persoonlijk aanraden om SQL Server Configuration Manager te gebruiken om SQL Server-gerelateerde services te stoppen/starten in vergelijking met de standaard Services.msc-optie.
Aanbevolen werkwijzen voor hoofddatabase
Aangezien de hoofddatabase kritieke details over de SQL Server-instantie opslaat, wordt aanbevolen om de best practices te volgen bij het verwerken van die database.
- Elke configuratiewijziging op een exemplaar van SQL Server wordt opgeslagen in de hoofddatabase. U moet dus altijd een volledige back-up van de hoofddatabase maken om de laatste status te herstellen voor het geval we de hoofddatabase herstellen vanuit de volledige back-up, zoals vereist.
- Hoewel gebruikers met SQL Server gebruikerstabellen of andere objecten in de hoofddatabase kunnen maken, wordt dit niet aanbevolen. De hoofddatabase moet eenvoudig en schoon blijven. Als u gebruikersobjecten in de hoofddatabase moet maken, moet u vaker volledige back-ups van de hoofddatabase maken.
- SQL Server ondersteunt de Opstartprocedure optie om bepaalde opgeslagen procedures uit te voeren bij het starten van een SQL Server-instantie. Het gebruikt de sp_procoption procedure. Wees voorzichtig bij het gebruik van deze optie, omdat het hebben van een niet-optimale code of recursieve logica van invloed kan zijn op de opstarttijd van de SQL Server-instantie.
Als SQL Server niet kon starten vanwege problemen met de hoofddatabase, moeten we de hoofddatabase herstellen vanaf de laatst bekende goede back-up.
Modeldatabase in SQL Server
Zoals de naam aangeeft, de Modelsysteemdatabase fungeert als een model of sjabloon voor het maken van een gebruikersdatabase in termen van het bestandspad, de initiële grootte, instellingen voor automatisch groeien, het herstelmodel en andere configuratie-opties .
Alle gebruikersobjecten zoals tabellen, procedures, enz. die in de modeldatabases worden gemaakt, worden ook automatisch gemaakt voor nieuwe gebruikersdatabases in die SQL Server-instantie.
Laten we dit verifiëren door een nieuwe tabel te maken in de modeldatabase:
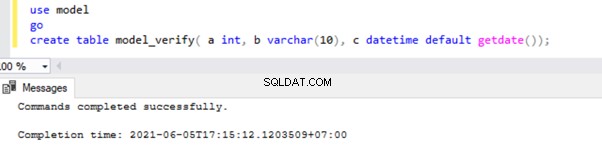
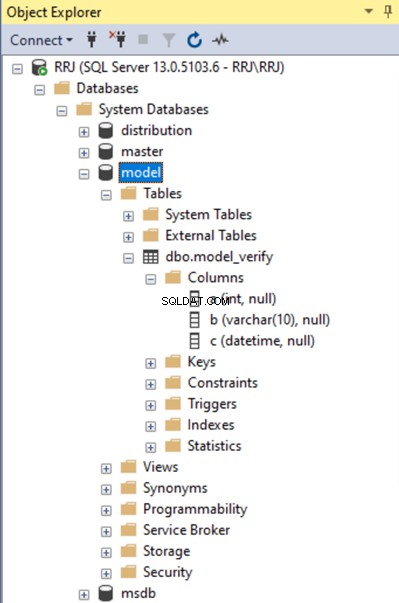
Laten we eens kijken of deze tabel aanwezig is in de modeldatabase:
De modeldatabase slaat ook het standaard bestandspad van gebruikersdatabases op, zoals hieronder weergegeven in de Database-eigenschappen van de msdb database.
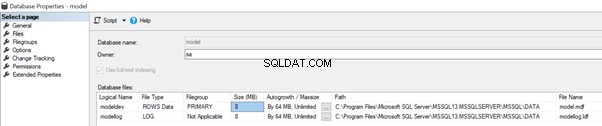
Volgens de huidige configuratie is de Initiële bestandsgrootte van beide gegevens en Logbestanden is ingesteld op 8 MB met automatische groei voor beide op 64 MB.
Als u een gebruikersdatabase in een ander bestandspad moet maken in plaats van de bestandslocatie van de modeldatabase, kunnen we deze wijzigen in de Servereigenschappen van dat SQL Server-exemplaar.
Klik in SSMS met de rechtermuisknop op Server > Eigenschappen > Database-instellingen . Bekijk de standaardlocaties van de database:
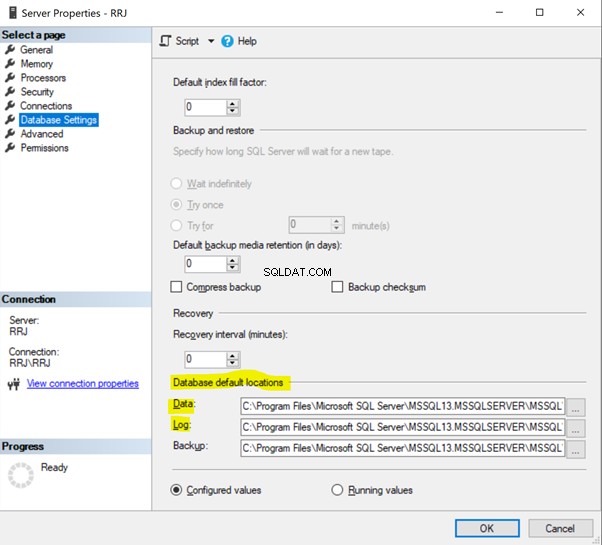
Wijzig het bestandspad in het gewenste pad en klik op OK . De gebruikersdatabase Gegevens en Log bestanden worden gemaakt in het nieuwe pad dat u heeft opgegeven.
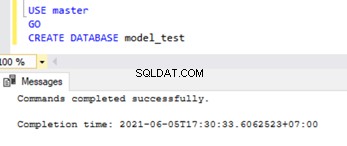
Laten we een nieuwe database maken met de naam model_test en controleer de nieuwe database-gegevens- en logbestandspaden samen met de initiële en autogrowth-bestandseigenschappen en de model_verify tabel over de nieuwe database.
Laten we de model_test . verifiëren Paden voor gegevens- en logbestanden. Klik met de rechtermuisknop op de model_test database> Eigenschappen > Bestanden :
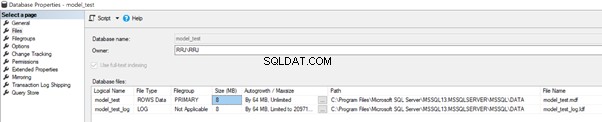
Zoals we kunnen zien, zijn de Gegevens en Log bestanden van de model_test database worden gemaakt volgens het pad dat beschikbaar is in de modeldatabase. De waarde voor de initiële bestandsgrootte van de gegevens- en logbestanden is 8 MB. De Autogrowth-waarde is 64 MB. Deze waarden komen overeen met de configuratie van de modeldatabase.
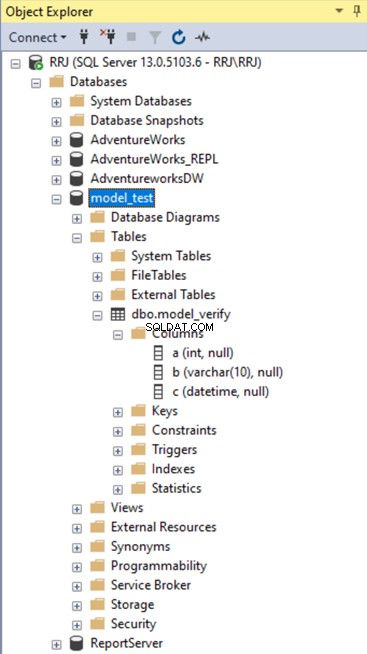
Nu gaan we controleren of de model_verify tabel is gemaakt in de model_test databank. We kunnen deze nieuwe database zien.
Dit geldt behalve voor tabellen ook voor weergaven, opgeslagen procedures, functies en alle objecten die in de modeldatabases zijn gemaakt.
Aanbevolen werkwijzen voor modeldatabase
Aangezien de modeldatabase fungeert als een sjabloon voor het maken van een nieuwe gebruikersdatabase, moeten we de onderstaande werkwijzen implementeren wanneer we ermee omgaan:
- Als u wijzigingen wilt aanbrengen in de configuratie van de modeldatabase (bijv. initiële bestandsgrootte, Autogrowth-grootte, aanmaken, wijzigen of verwijderen van gebruikersobjecten), maakt u onmiddellijk een volledige back-up van de modeldatabase.
- Aangezien alle gebruikersobjecten die in de modeldatabases zijn gemaakt, worden gemaakt op gebruikersdatabases, moet u ervoor zorgen dat u alleen vereiste objecten toevoegt. Anders worden er veel onnodige objecten gemaakt in alle gebruikersdatabases en besteedt u veel tijd aan het sorteren en opschonen van uw databases.
- Configureer de parameters Initiële bestandsgrootte en Autogrowth voor de gegevens- en logbestanden. Het helpt om de gegevens- en logbestanden in de gebruikersdatabases beter te beheren en de prestaties te verbeteren.
MSDB-database
De msdb-systeemdatabase slaat de onderstaande kritieke informatie op in de systeemtabellen:
- SQL Server Agent-gerelateerde items zoals taken, taakgeschiedenis, waarschuwingen, operators, proxy's, enz.
- SQL Server-functies zoals Service Broker en Database Mail met de configuratie- en geschiedenisdetails.
- SQL Server-back-up- en herstelgegevens worden opgeslagen in de msdb-databasetabellen.
- Verzendconfiguraties, replicatieagentprofielen en gegevensverzamelaarconfiguraties loggen.
- Onderhoudsplannen, SSIS-pakketten en enkele andere details.
Met andere woorden, de msdb-systeemdatabase slaat alle kritieke informatie op met betrekking tot SQL Server Agent Services en enkele andere gerelateerde services.
Aanbevolen werkwijzen voor msdb-database
De msdb-database slaat veel kritieke configuratie-informatie op met betrekking tot SQL Server Agents, Jobs en Database Mail. Het slaat ook historische details op. Daarom moeten we de onderstaande praktijken implementeren bij het omgaan met de msdb-database:
- In een SQL Server-instantie met veel databases of Jobs die zijn geconfigureerd, zal de grootte van de msdb-database in de loop van de tijd continu toenemen. Daarom moeten er dagelijks volledige back-ups worden geïmplementeerd voor de msdb-databases, samen met andere gebruikersdatabases. Als msdb veel kritieke informatie ontvangt, kunnen we het herstelmodel van de msdb-database wijzigen in Full en vervolgens ook Transactielogboekback-up implementeren.
- Hoewel gebruikers met SQL Server gebruikersobjecten kunnen maken in de msdb-database, wordt aangeraden geen gebruikerstabellen of objecten in de msdb-database te maken en de omvang van de msdb-database verder te vergroten.
- Voer regelmatig een opschoning uit van msdb-systeemtabellen om de grootte van de msdb-database onder controle te houden en de prestatie-impact te vermijden van het hebben van enorme gegevens over meerdere tabellen.
Tempdb-database
De tempdb-systeemdatabase kan worden beschouwd als een globaal werkgebied dat beschikbaar is voor alle gebruikers die zijn verbonden met de SQL Server-instantie om hun SELECT- of andere bewerkingen uit te voeren .
De Tempdb-database bevat de onderstaande objecttypen terwijl gebruikers hun bewerkingen uitvoeren:
- Tijdelijke objecten die expliciet door gebruikers zijn gemaakt, kunnen lokale of globale tijdelijke tabellen en indexen zijn, tabelvariabelen, tabellen die worden gebruikt in functies met tabelwaarde en cursors.
- Interne objecten gemaakt door de database-engine, zoals:
- Werktabellen gebruikt voor tussenresultaten voor spools, cursors, sorteringen en tijdelijke grote objecten (LOB)
- Werkbestanden voor Hash Join- of Hash-aggregatiebewerkingen
- Tussenliggende sorteerresultaten bij het maken of opnieuw opbouwen van indexen als SORT_IN_TEMPDB is ingesteld op AAN en andere bewerkingen zoals GROUP BY, ORDER BY of UNION-query's
- Versiearchieven die de functie voor rijversiebeheer ondersteunen, ofwel een gemeenschappelijke versieopslag of een online versieopslag voor het bouwen van een index.
Telkens wanneer de SQL Server-service start of herstart, wordt de tempdb-database opnieuw gemaakt met behulp van de modeldatabase. Dus tempdb is de enige systeemdatabase waarvan geen back-up kan worden gemaakt .
Als we proberen er een back-up van te maken, krijgen we foutmeldingen:
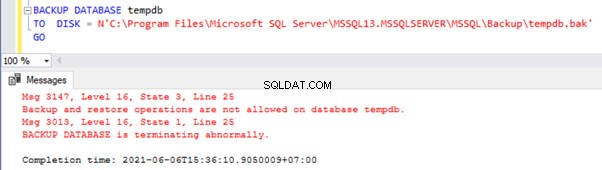
Aangezien we tempdb gebruiken in bijna alle gebruikersbewerkingen, vormt deze database een significant prestatieprobleem in verschillende versies van SQL Server. Vanaf SQL Server 2016 waren er verschillende optimalisatietechnieken geïmplementeerd door Microsoft - we zullen ze later bespreken.
Voordat we ingaan op de aanbevolen werkwijzen voor de tempdb-database, laten we eens kijken naar de gegevensbestanden onder de standaardconfiguratie zoals hieronder weergegeven:
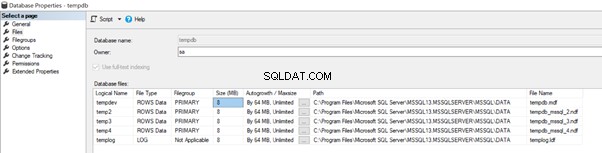
Voor mijn huidige SQL Server-instantie hebben we 4 gegevensbestanden en één logbestand voor de tempdb-database.
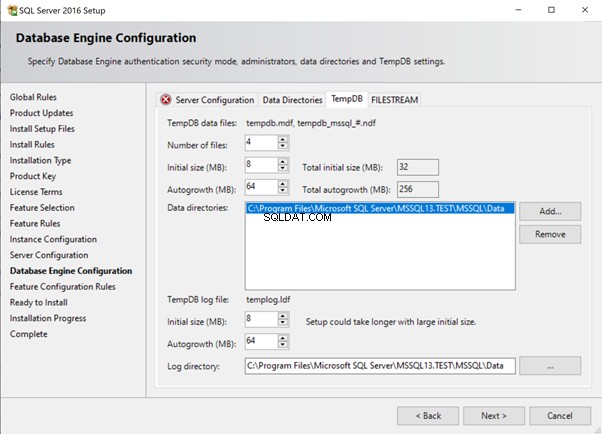
Vanaf SQL Server 2016 hebben we het SQL Server-installatieprogramma waarmee we meerdere bestanden aan tempdb kunnen toevoegen. De bovenstaande 4 bestanden met een initiële grootte van 8 MB en een Autogrowth-grootte van 64 MB zijn gemaakt met behulp van de onderstaande standaardopties.
Als we een enkel gegevensbestand in de tempdb-database hebben, proberen alle logische kernen die beschikbaar zijn in de server toegang te krijgen tot hetzelfde gegevensbestand van tempdb, wat resulteert in een prestatieknelpunt.
Als u meerdere gegevensbestanden heeft, worden bepaalde kernen logisch aan één bestand gekoppeld. We hebben dus minder twist over tempdb-gegevensbestanden. Dit zal de prestatie-impact op de tempdb-gegevensbestanden verbeteren.
Aanbevolen werkwijzen voor tempdb-database
Aangezien de tempdb-database een globaal werkgebied is voor alle gebruikersactiviteiten, neemt de tempdb-grootte toe op basis van de gebruikersactiviteiten. Het kan een prestatieknelpunt zijn voor de hele SQL Server-instantie.
Daarom moeten we de volgende praktijken implementeren:
- Plaats de tempdb-gegevens en logbestanden op hoogwaardige opslag om hogere IOPS te krijgen voor betere prestaties.
- Zorg ervoor dat de tempdb-database is opgedeeld in meerdere gegevensbestanden om conflicten te verminderen en prestatieknelpunten in de tempdb-database te voorkomen.
- Als het aantal logische kernen kleiner is dan 8, kunnen we één tempdb-gegevensbestand per logische kern hebben. In ons testexemplaar hadden we 4 logische kernen. Daarom zouden 4 gegevensbestanden op tempdb voldoende moeten zijn.
- Als het aantal logische kernen meer dan 8 is, begin dan met 8 gegevensbestanden en verhoog met 4 gegevensbestanden als er strijd- en prestatieproblemen worden waargenomen in de tempdb-database.
- Als het aantal logische cores in een server 32 of 64 is, kunnen we beginnen met 8 databestanden. Het betekent dat 4 cores of 8 cores logisch zijn gekoppeld aan een enkel gegevensbestand.
Voor meer duidelijkheid over meerdere tempdb-gegevensbestanden, raad ik u het uitstekende artikel van Paul Randal aan.
- Zorg ervoor dat tempdb-gegevensbestanden zijn geconfigureerd met een optimale initiële bestandsgrootte. Idealiter zou dit moeten worden bereikt door middel van vallen en opstaan. Tempdb met optimale initiële bestandsgrootte heeft de neiging om minder vaak te groeien in vergelijking met tempdb geconfigureerd met de kleinere initiële bestandsgrootte die de neiging heeft om meerdere keren te groeien, wat leidt tot fragmentatie. In de huidige configuratie zijn bijvoorbeeld alle bestanden geconfigureerd met een aanvankelijke bestandsgrootte van 8 MB die te klein is om SQL-workloads aan te kunnen. Pas dus de Trial and Error-benadering toe en stel de initiële bestandsgrootte in op 512 MB of 1 GB, of een andere waarde.
- Zorg ervoor dat alle tempdb-gegevensbestanden zijn ingesteld op gelijke bestandsgrootte. Auto-groei eigenschappen moeten gelijk worden gedefinieerd. In ons scenario zijn alle bestanden ingesteld op 64 MB autogrowth. Door de Autogrowth-grootte in te stellen op 512 MB of 1 GB, of een andere geschikte waarde, kunt u frequente autogrowth in tempdb-gegevensbestanden verminderen.
- Zorg ervoor dat de initiële bestandsgrootte en Autogrowth voor het tempdb-logbestand zijn geconfigureerd op een optimale waarde die vergelijkbaar is met tempdb-gegevensbestanden. Aangezien het herstelmodel van tempdb standaard is ingesteld op Eenvoudig en niet kan worden gewijzigd, zou het voldoende moeten zijn om de initiële bestandsgrootte en autogrowth-eigenschap van het tempdb-logbestand te configureren.
Tempdb is essentieel voor de prestaties van SQL Server-instanties. We zullen in onze volgende artikelen gedetailleerd ingaan op de veelvoorkomende problemen waarmee tempdb wordt geconfronteerd en hoe u deze optimaal kunt verkleinen.
Brondatabase in SQL Server
De Resource System-database is de enige alleen-lezen systeemdatabase die niet wordt vermeld onder systeemdatabases in SSMS, zoals eerder gezien.
De Database-ID (dbid) van resourcedatabases in alle instances zal 32767 zijn, wat ook het maximale aantal databases is dat wordt ondersteund binnen een SQL Server-instance. Het kan worden opgevraagd vanuit de sys.sysaltfiles systeem DMV. De onderstaande SELECT-query uitvoeren op sys.sysaltfiles retourneert de resultatenset tonen waar de gegevens- en logbestanden van de bronnendatabase zich bevinden:
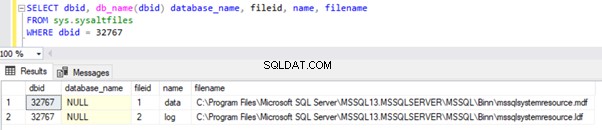
We kunnen fysieke bestanden van de bronnendatabase zien die beschikbaar zijn in het bovengenoemde pad. De wijzigingsdatum geeft de tijd aan van de installatie van de SQL Server-instantie of de laatste keer dat Service Packs (SP) of Cumulatieve Update (CU) op deze instantie zijn toegepast.

De resourcedatabase bevat alle systeemobjecten, zoals sys.objects , sys.databases , sys.sysaltfiles , enz. fysiek erin. Deze database geeft logischerwijs al deze objecten weer onder het sys-schema over alle databases die beschikbaar zijn in de instantie . Aangezien de bronnendatabase alleen-lezen is, kunnen er geen gebruikersobjecten of gegevens op worden gemaakt.
De Resource-systeemdatabase is geïntroduceerd vanaf SQL Server 2005 om de upgrade van SQL Server naar een nieuwe versie van SP of CU sneller te maken. Voordat die optie werd geïntroduceerd, betekenden al dergelijke upgrades en updates dat wijzigingen van toepassing zouden zijn op alle databases, waardoor het upgradeproces ingewikkelder en tijdrovender werd. Nu is elke upgrade van de SQL Server-versie of SP- of CU-update alleen een upgrade of vervanging van de resourcedatabase.
Omdat de resourcedatabase alleen-lezen is en niet zichtbaar is voor gebruikers, is er geen tussenkomst van de gebruiker nodig. Als u een back-up van de resourcedatabase wilt opnemen in uw planning voor hoge beschikbaarheid of noodherstel, maakt u gewoon een bestandsback-up van de bestanden mssqlsystemresource.mdf en mssqlsystemresource.ldf na het stoppen van SQL Server Services (SQL Server-service staat het kopiëren van de bestanden niet toe terwijl SQL Server Service actief is) en sla het op een veilige locatie op. Zorg ervoor dat u het niet bijwerkt op een exemplaar van SQL Server dat wordt uitgevoerd met een andere versie van SP- of CU-niveaus, omdat dit onverwachte problemen kan veroorzaken.
Distributiedatabase in SQL Server
De database van het distributiesysteem is het hart van Replication. Gebruikers kunnen een distributiedatabase maken of configureren als onderdeel van de replicatie-installatie met behulp van de wizard Distributie configureren of de wizard Publicatie maken. We hebben de stappen voor het maken van distributiedatabases in detail beschreven als onderdeel van mijn vorige artikel over interne SQL Server-transactiereplicatie.
Aanbevolen werkwijzen voor distributiedatabase
Aangezien de distributiedatabase essentieel is voor de replicatiefunctionaliteit, moeten we de volgende werkwijzen implementeren:
- Verplaats de distributiedatabasegegevens en logbestanden naar de schijf met goede IOPS om problemen met de distributieprestaties te voorkomen.
- Configureer de eigenschappen Initial File Size en Autogrowth van de distributiedatabase naar een betere waarde om fragmentatieproblemen te voorkomen.
- Distributiedatabase toevoegen aan de database Volledige back-uponderhoudstaken.
- Voeg distributiedatabases toe aan de Index Maintenance-taken om fragmentatie en prestatieproblemen te voorkomen.
In mijn artikel over interne onderdelen van SQL Server Transactionele Replicatie vindt u ook aanbevelingen over andere efficiënte werkwijzen.
Conclusie
Bedankt voor het doornemen van weer een krachtig artikel!
Ik hoop dat het u heeft geholpen om de essentie en het doel van de SQL Server-systeemdatabases te verduidelijken en de beste werkwijzen te leren om prestatieproblemen met deze databases te voorkomen.