Het beheren van verkeer naar de database kan steeds moeilijker worden naarmate het in aantal toeneemt en de database daadwerkelijk over meerdere servers wordt verdeeld. PostgreSQL-clients praten meestal met een enkel eindpunt. Wanneer een primair knooppunt uitvalt, blijven de databaseclients hetzelfde IP-adres opnieuw proberen. Als u een failover naar een secundair knooppunt hebt uitgevoerd, moet de toepassing worden bijgewerkt met het nieuwe eindpunt. Dit is waar u een load balancer tussen de toepassingen en de database-instanties zou willen plaatsen. Het kan toepassingen naar beschikbare/gezonde databaseknooppunten en indien nodig een failover sturen. Een ander voordeel zou zijn om de leesprestaties te verbeteren door replica's effectief te gebruiken. Het is mogelijk om een alleen-lezen poort te maken die leesbewerkingen over replica's verdeelt. In deze blog gaan we het hebben over HAProxy. We zullen zien wat het is, hoe het werkt en hoe het te implementeren voor PostgreSQL.
Wat is HAProxy?
HAProxy is een open source proxy die kan worden gebruikt voor het implementeren van hoge beschikbaarheid, taakverdeling en proxying voor op TCP en HTTP gebaseerde applicaties.
Als load balancer distribueert HAProxy verkeer van de ene oorsprong naar een of meer bestemmingen en kan voor deze taak specifieke regels en/of protocollen definiëren. Als een van de bestemmingen niet meer reageert, wordt deze gemarkeerd als offline en wordt het verkeer naar de overige beschikbare bestemmingen gestuurd.
HAProxy handmatig installeren en configureren
Om HAProxy op Linux te installeren kun je de volgende commando's gebruiken:
Op Ubuntu/Debian OS:
$ apt-get install haproxy -yOp CentOS/RedHat OS:
$ yum install haproxy -yEn dan moeten we het volgende configuratiebestand bewerken om onze HAProxy-configuratie te beheren:
$ /etc/haproxy/haproxy.cfgHet configureren van onze HAProxy is niet ingewikkeld, maar we moeten wel weten wat we doen. We moeten verschillende parameters configureren, afhankelijk van hoe we willen dat HAProxy werkt. Voor meer informatie kunnen we de documentatie over de HAProxy-configuratie volgen.
Laten we eens kijken naar een basisconfiguratievoorbeeld. Stel dat u de volgende databasetopologie heeft:
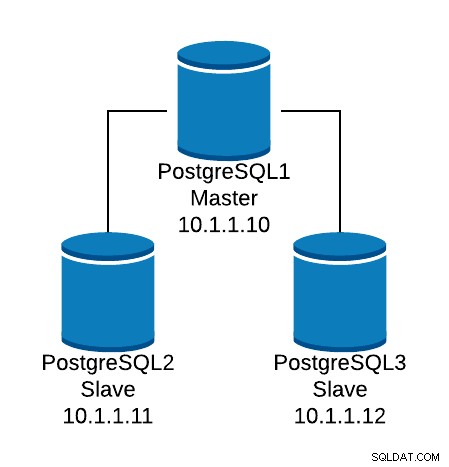 Voorbeeld van databasetopologie
Voorbeeld van databasetopologie We willen een HAProxy-listener maken om het leesverkeer tussen de drie knooppunten te verdelen.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkZoals we eerder vermeldden, zijn er verschillende parameters om hier te configureren, en deze configuratie hangt af van wat we willen doen. Bijvoorbeeld:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkHoe HAProxy werkt op ClusterControl
Voor PostgreSQL wordt HAProxy door ClusterControl geconfigureerd met standaard twee verschillende poorten, een lezen-schrijven en een alleen-lezen.
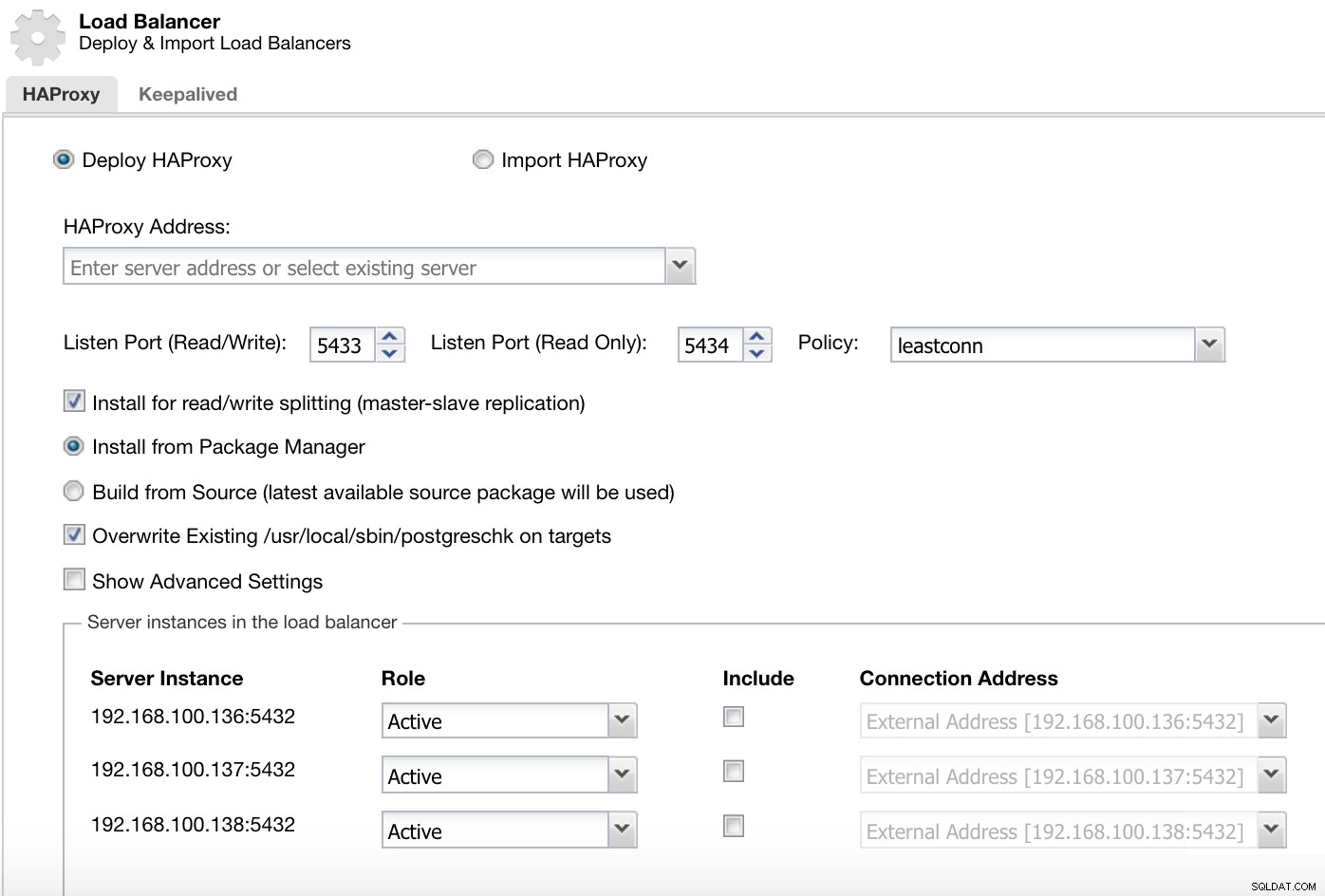 ClusterControl Load Balancer-implementatie-informatie 1
ClusterControl Load Balancer-implementatie-informatie 1 In onze read-write-poort hebben we onze masterserver als online en de rest van onze nodes als offline, en in de read-only-poort hebben we zowel de master als de slaves online.
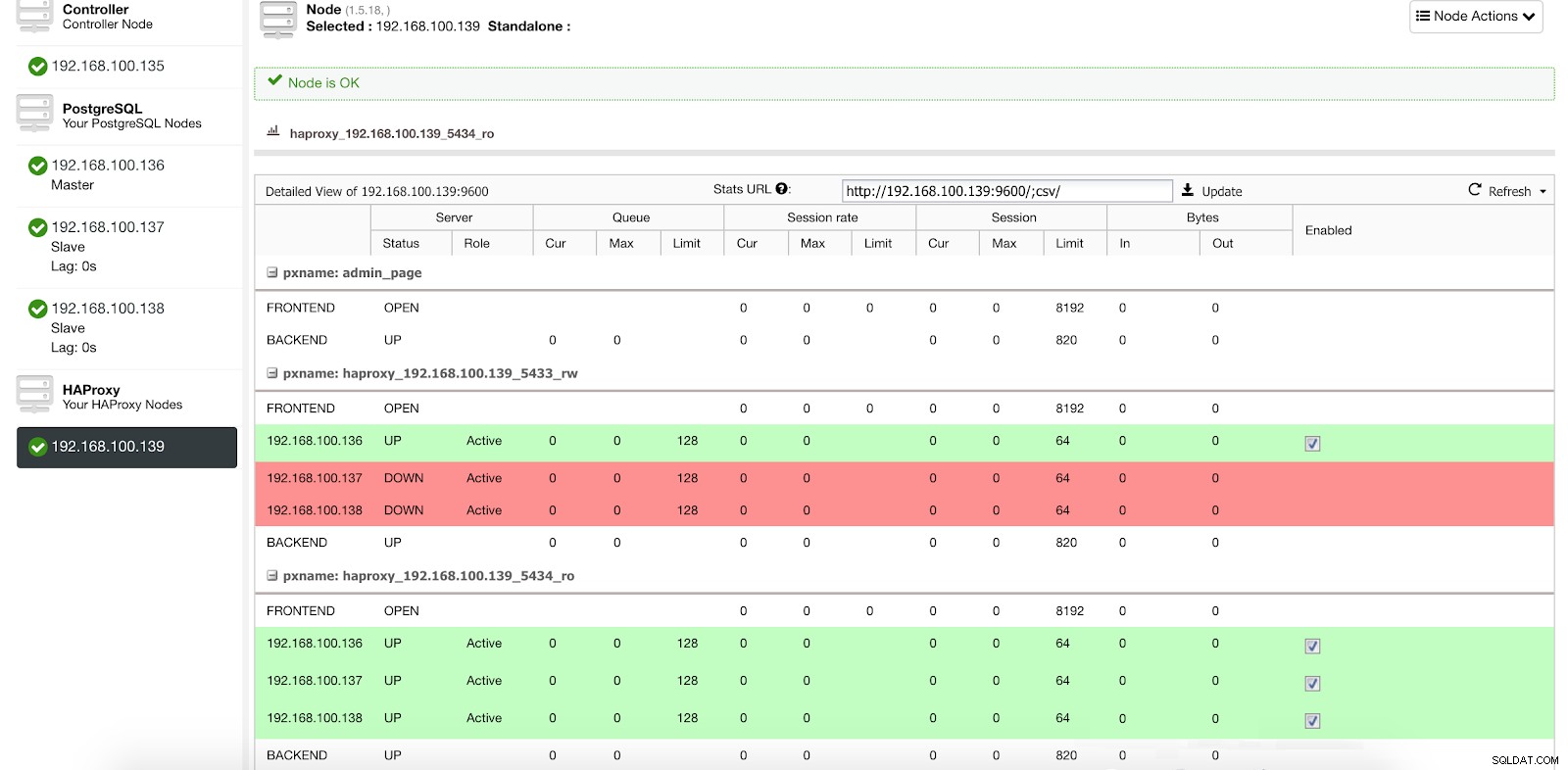 ClusterControl Load Balancer-statistieken 1
ClusterControl Load Balancer-statistieken 1 Wanneer HAProxy detecteert dat een van onze nodes, master of slave, niet toegankelijk is, markeert het deze automatisch als offline en houdt er geen rekening mee bij het verzenden van verkeer. Detectie wordt gedaan door healthcheck-scripts die zijn geconfigureerd door ClusterControl op het moment van implementatie. Deze controleren of de instanties actief zijn, of ze worden hersteld of alleen-lezen zijn.
Wanneer ClusterControl een slave tot master promoveert, markeert onze HAProxy de oude master als offline (voor beide poorten) en zet de gepromote node online (in de lees-schrijfpoort).
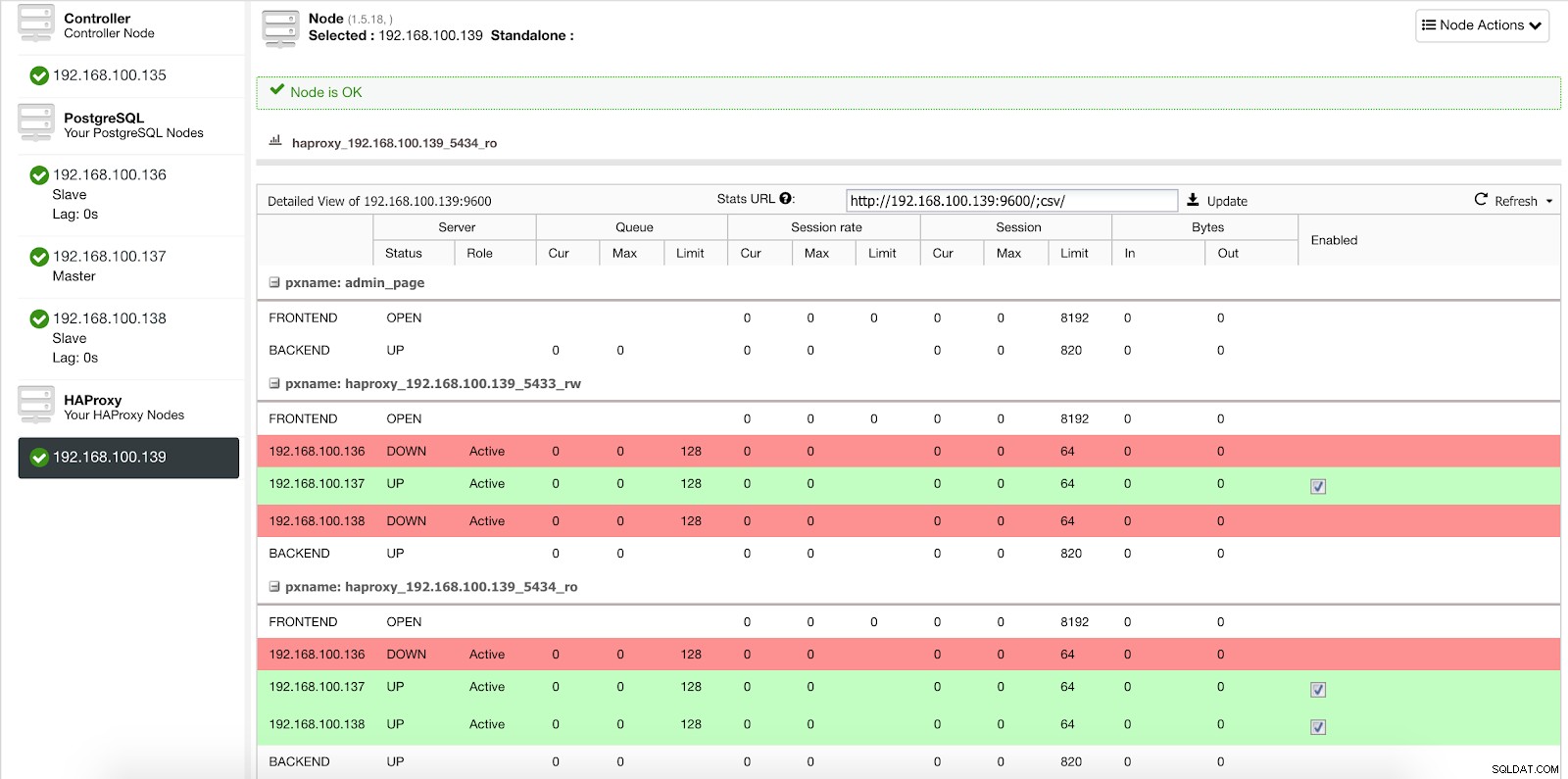 ClusterControl Load Balancer-statistieken 2
ClusterControl Load Balancer-statistieken 2 Op deze manier blijven onze systemen normaal en zonder onze tussenkomst werken.
HAProxy implementeren met ClusterControl
In ons voorbeeld hebben we een omgeving gemaakt met 1 master en 2 slaves - zie een screenshot van de Topology View in ClusterControl. We voegen nu onze HAProxy-load balancer toe.
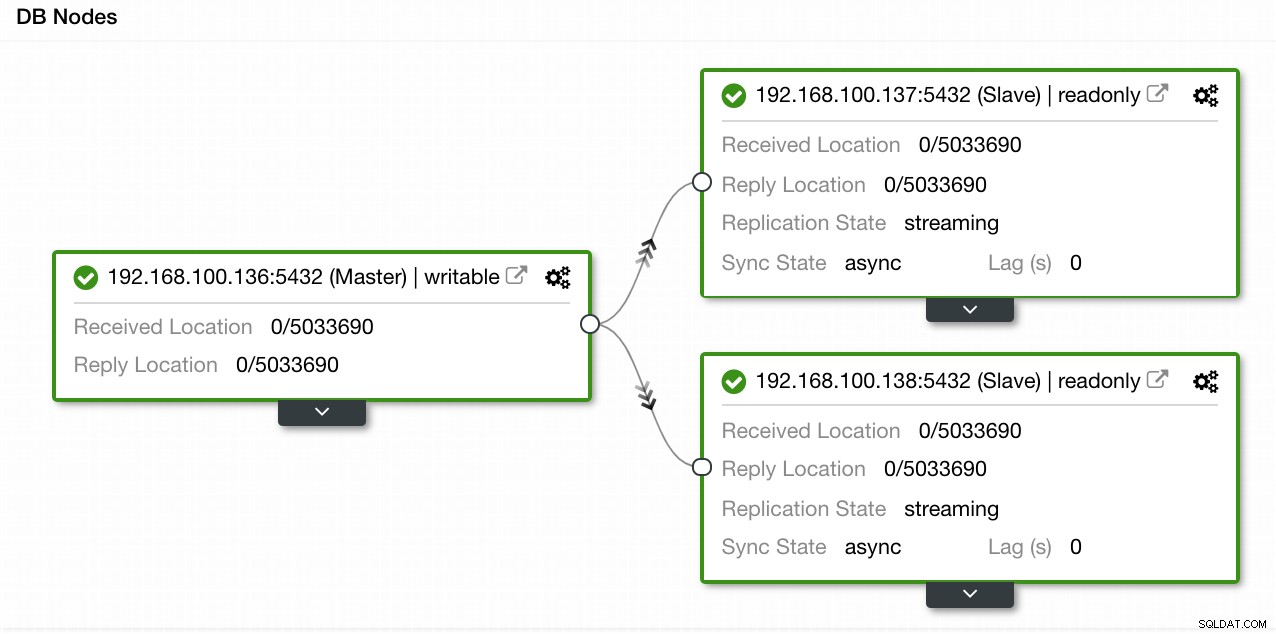 ClusterControl-topologieweergave 1
ClusterControl-topologieweergave 1 Voor deze taak moeten we naar ClusterControl -> PostgreSQL Cluster Actions -> Load Balancer toevoegen
 ClusterControl-menu Clusteracties
ClusterControl-menu Clusteracties Hier moeten we de informatie toevoegen die ClusterControl zal gebruiken om onze HAProxy load balancer te installeren en configureren.
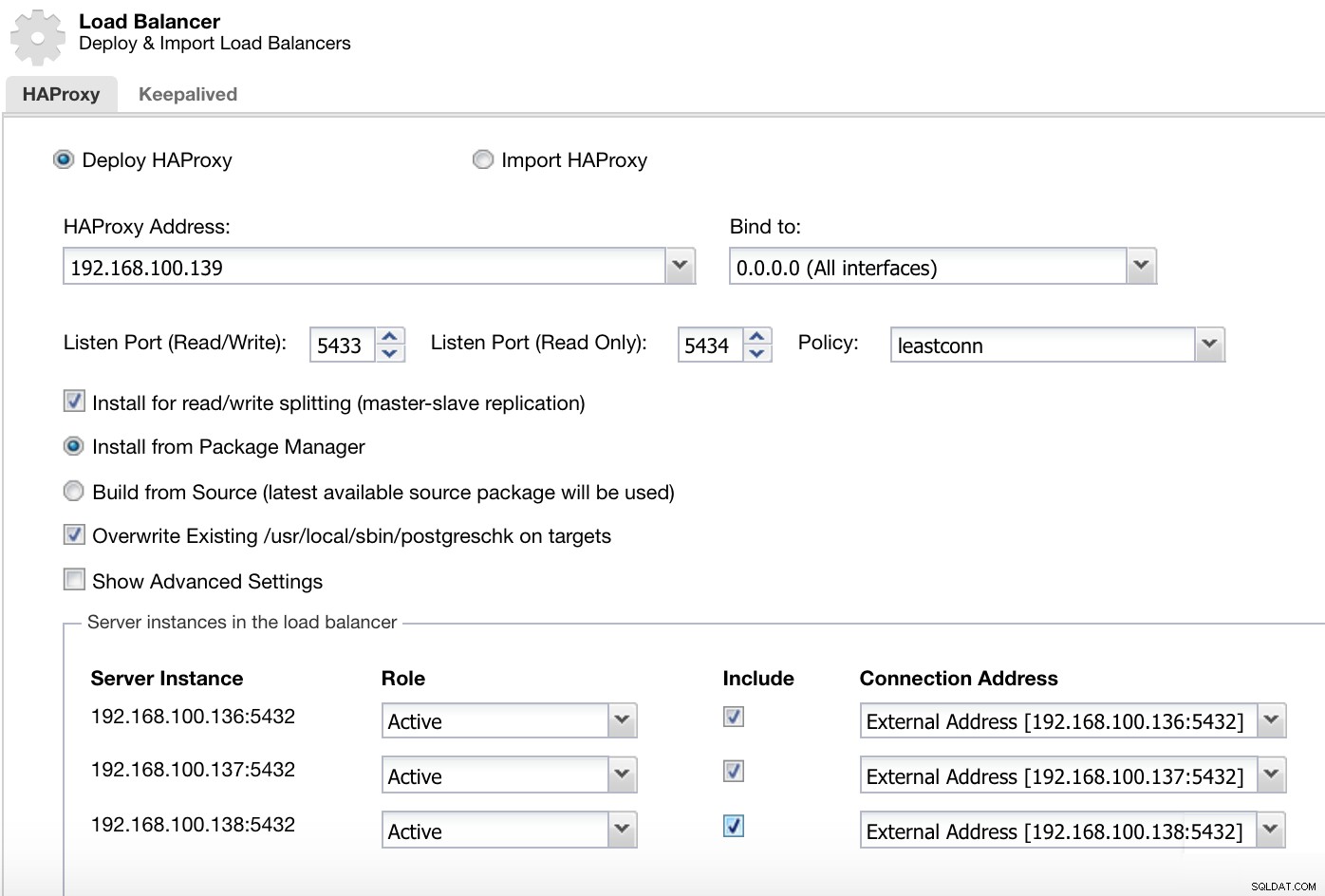 ClusterControl Load Balancer-implementatie-informatie 2
ClusterControl Load Balancer-implementatie-informatie 2 De informatie die we moeten introduceren is:
Actie:implementeren of importeren.
HAProxy-adres:IP-adres voor onze HAProxy-server.
Binden aan:Interface of IP-adres waar HAProxy naar luistert.
Luisterpoort (lezen/schrijven):Poort voor lees-/schrijfmodus.
Luisterpoort (alleen-lezen):poort voor alleen-lezen modus.
Beleid:het kan zijn:
- leastconn:de server met het laagste aantal verbindingen ontvangt de verbinding.
- roundrobin:elke server wordt om de beurt gebruikt, op basis van hun gewicht.
- bron:het bron-IP-adres wordt gehasht en gedeeld door het totale gewicht van de actieve servers om aan te geven welke server het verzoek zal ontvangen.
Installeren voor splitsen van lezen/schrijven:voor master-slave-replicatie.
Bron:we kunnen kiezen voor Installeren vanuit een pakketbeheerder of bouwen vanaf de bron.
Overschrijf bestaande postgreschk op doelen.
En we moeten selecteren welke servers u wilt toevoegen aan de HAProxy-configuratie en wat aanvullende informatie zoals:
Rol:het kan actief of back-up zijn.
Opnemen:Ja of Nee.
Informatie over verbindingsadres.
We kunnen ook geavanceerde instellingen configureren, zoals Admin User, Backend Name, Time-outs en meer.
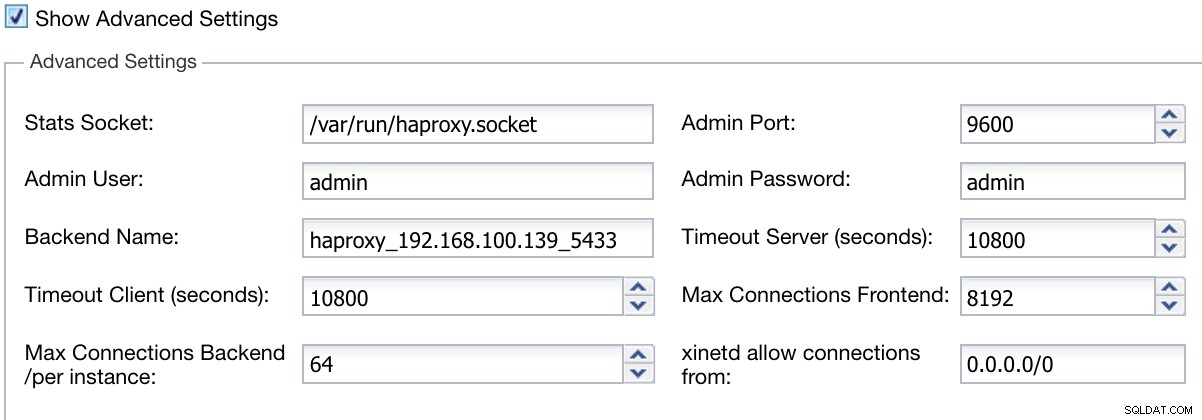 ClusterControl Load Balancer-informatie implementeren Geavanceerd
ClusterControl Load Balancer-informatie implementeren Geavanceerd Wanneer u de configuratie voltooit en de implementatie bevestigt, kunnen we de voortgang volgen in het gedeelte Activiteit in de gebruikersinterface van ClusterControl.
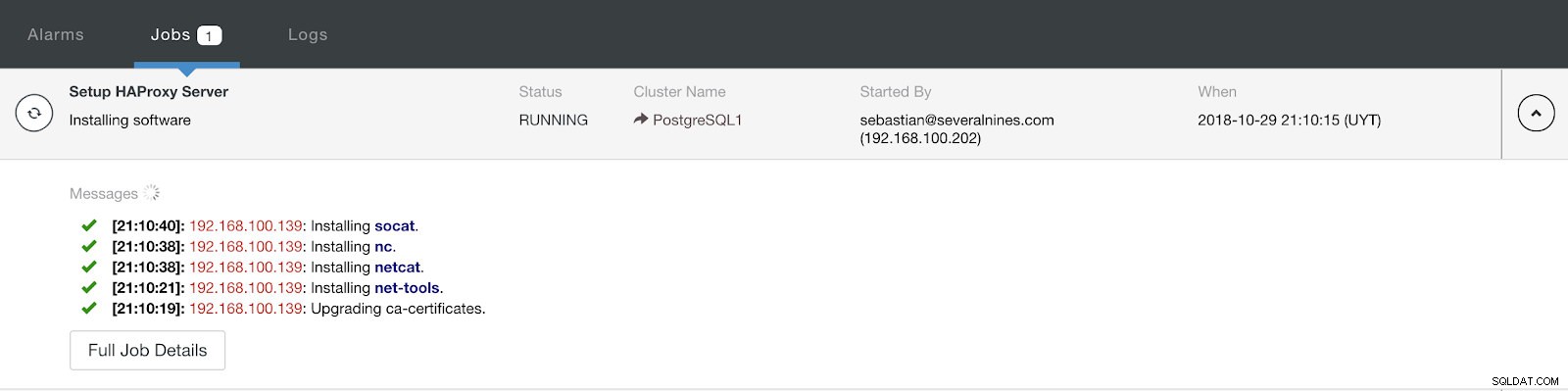 ClusterControl-activiteitengedeelte
ClusterControl-activiteitengedeelte Als het klaar is, zouden we de volgende topologie moeten hebben:
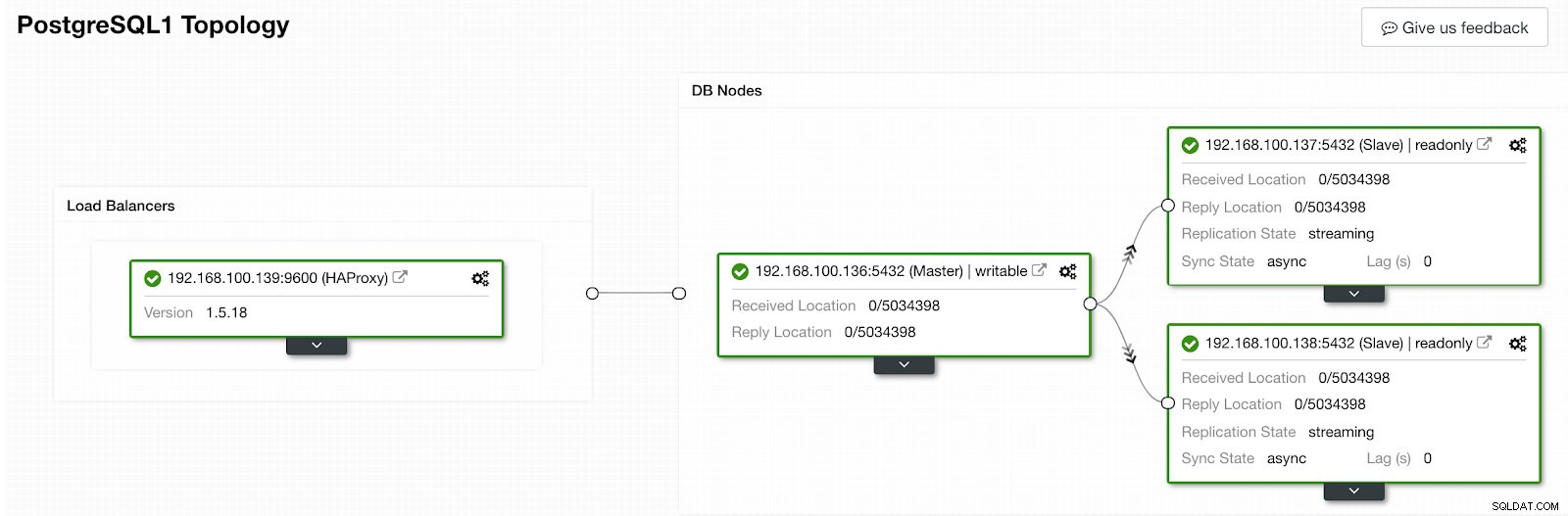 ClusterControl-topologieweergave 2
ClusterControl-topologieweergave 2 We kunnen ons HA-ontwerp verbeteren door een nieuw HAProxy-knooppunt toe te voegen en de Keepalive-service tussen beide te configureren. Dit alles kan door ClusterControl worden uitgevoerd. Voor meer informatie kun je onze vorige blog over PostgreSQL en HA bekijken.
ClusterControl CLI gebruiken om een HAProxy Load Balancer toe te voegen
Dit optionele pakket, ook bekend als s9s-tools, werd geïntroduceerd in ClusterControl-versie 1.4.1, dat een binair bestand met de naam s9s bevat. Het is een opdrachtregeltool voor interactie, controle en beheer van uw database-infrastructuur met behulp van ClusterControl. Het s9s-opdrachtregelproject is open source en is te vinden op GitHub.
Vanaf versie 1.4.1 zal het installatiescript het pakket (s9s-tools) automatisch installeren op het ClusterControl-knooppunt.
ClusterControl CLI opent een nieuwe deur voor clusterautomatisering, waar u het eenvoudig kunt integreren met bestaande automatiseringstools voor implementatie, zoals Ansible, Puppet, Chef of Salt.
Laten we eens kijken naar een voorbeeld van het maken van een HAProxy-load balancer met IP-adres 192.168.100.142 op cluster-ID 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.En dan kunnen we al onze knooppunten controleren vanaf de opdrachtregel:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Voor meer informatie over s9s en het gebruik ervan, kun je de officiële documentatie of deze how to blog over dit onderwerp raadplegen.
Conclusie
In deze blog hebben we bekeken hoe HAProxy ons kan helpen om het verkeer dat van de applicatie naar onze PostgreSQL-database komt te beheren. We hebben gekeken hoe het handmatig kan worden ingezet en geconfigureerd en hebben vervolgens gezien hoe het kan worden geautomatiseerd met ClusterControl. Om te voorkomen dat HAProxy een single point of failure (SPOF) wordt, moet u ervoor zorgen dat u ten minste twee HAProxy-instanties implementeert en daarbovenop iets als Keepalive en Virtual IP implementeert.