In een noodherstelplan is uw Recovery Point Objective (RPO) een belangrijke herstelparameter die bepaalt hoeveel gegevens u zich kunt veroorloven te verliezen. RPO wordt weergegeven in tijd, van seconden tot dagen. In feite is RPO direct afhankelijk van uw back-upsysteem. Het markeert de ouderdom van uw back-upgegevens die u moet herstellen om de normale werking te hervatten.
Als u een nachtelijke back-up maakt om 22.00 uur. en uw databasesysteem crasht onherstelbaar om 15.00 uur. de volgende dag verlies je alles wat is gewijzigd sinds je laatste back-up. Uw RPO in deze specifieke context is de back-up van de vorige dag, wat betekent dat u het zich kunt veroorloven één dag aan wijzigingen te verliezen.
Het onderstaande diagram uit onze Whitepaper over Disaster Recovery illustreert het concept.
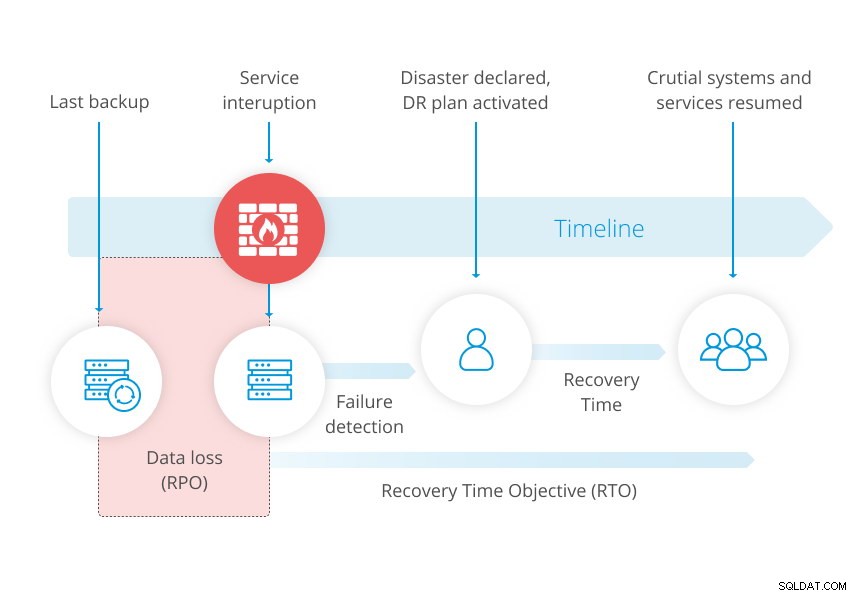
Voor een strakkere RPO is een back-up misschien niet genoeg. Bij het maken van een back-up van uw database maakt u eigenlijk een momentopname van de gegevens op een bepaald moment. Dus wanneer u een back-up herstelt, mist u de wijzigingen die zijn aangebracht tussen de laatste back-up en de mislukking.
Dit is waar het concept van Point In Time Recovery (PITR) om de hoek komt kijken.
Wat is PITR?
Point In Time Recovery (PITR), zoals de naam al zegt, houdt in dat de database op een bepaald moment in het verleden wordt hersteld. Om dit te kunnen doen, moeten we een back-up terugzetten en vervolgens alle wijzigingen toepassen die na de back-up zijn aangebracht tot vlak voor de fout.
Voor PostgreSQL worden de wijzigingen opgeslagen in de WAL-logboeken (voor meer details over WAL's en de gegevens die ze opslaan, kunt u deze blog raadplegen).
Er zijn dus twee dingen waar we voor moeten zorgen om een PITR uit te kunnen voeren:de back-ups en de WAL's (we moeten er continue archivering voor instellen).
Voor het uitvoeren van de PITR moeten we de back-up herstellen en vervolgens de WAL's toepassen.
Wanneer kan het nuttig zijn?
U kunt deze strategie gebruiken wanneer u herstelt van een probleem waardoor de gegevens beschadigd zijn geraakt. U moet er rekening mee houden dat u het gegevensverlies probeert te minimaliseren, maar er zijn enkele problemen die ertoe kunnen leiden dat de gegevens daarna niet meer bruikbaar zijn.
Enkele voorbeelden hiervan zijn ongeplande gegevenswijzigingen (DML's of DDL's), mediastoringen of databaseonderhoud (zoals upgrades) die leiden tot gegevensbeschadiging. U kunt de gegevenswijzigingen die na het probleem zijn opgetreden niet herstellen.
Stel dat een gebruiker ten onrechte een DML heeft uitgevoerd, waardoor de gegevens van een hele tabel ten onrechte zijn gewijzigd of verwijderd. U kunt een PITR van de database op een aparte locatie uitvoeren en vervolgens de inhoud van de tabel exporteren. U kunt die tabel vervolgens terugzetten in de bestaande database, waardoor u in feite teruggaat naar een kopie van hoe de tabel was voordat het probleem zich voordeed.
Het is natuurlijk niet altijd mogelijk om slechts een deel van de database op deze manier te herstellen, dus in dat geval moet u de hele database naar een bepaald punt herstellen en heeft u een minimaal maar onvermijdelijk gegevensverlies (u mist eventuele wijzigingen die zijn aangebracht nadat het probleem zich voordeed).
Hoe te gebruiken met ClusterControl?
In een vorige blog konden we zien hoe we PITR handmatig kunnen implementeren, laten we nu kijken hoe we ClusterControl kunnen gebruiken om deze taak uit te voeren.
Tijdsherstel inschakelen
Om de PITR-functie in te schakelen, moeten we de WAL-archivering hebben ingeschakeld. Hiervoor kunnen we naar ClusterControl -> Selecteer PostgreSQL-cluster -> Knooppuntacties -> WAL-archivering inschakelen, of ga gewoon naar ClusterControl -> Selecteer PostgreSQL-cluster -> Back-up -> Instellingen en schakel de optie "Enable Point-In-Time Recovery in (WAL-archivering)” zoals we zullen zien in de volgende afbeelding.
We moeten er rekening mee houden dat we onze database opnieuw moeten opstarten om WAL-archivering mogelijk te maken. ClusterControl kan dit ook voor ons doen.
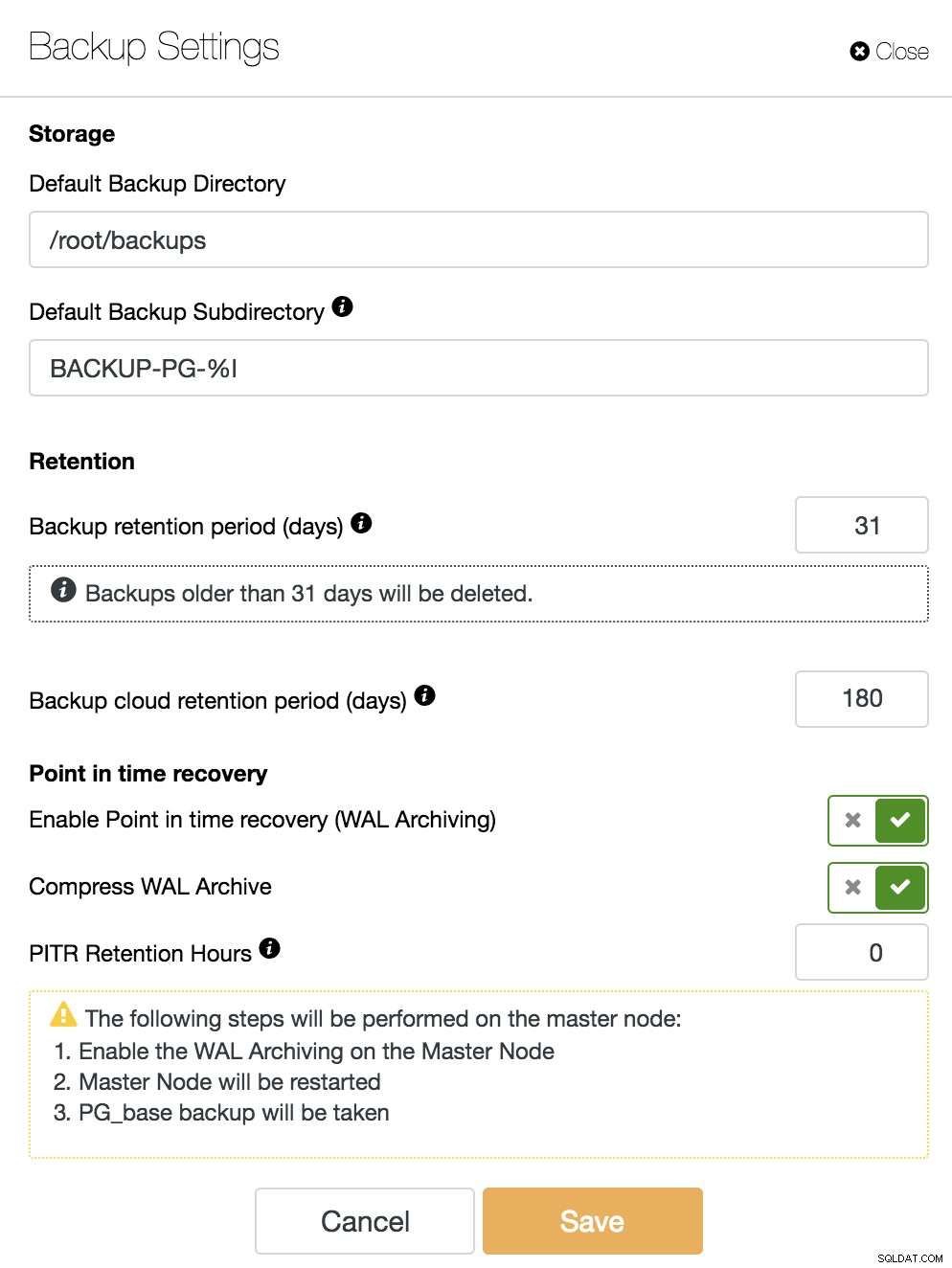
Naast de opties die voor alle back-ups gelden, zoals de "Backup Directory" en de "Back-up Retentieperiode", kunnen we hier ook de WAL-Retentieperiode specificeren. Standaard is 0, wat voor altijd betekent.
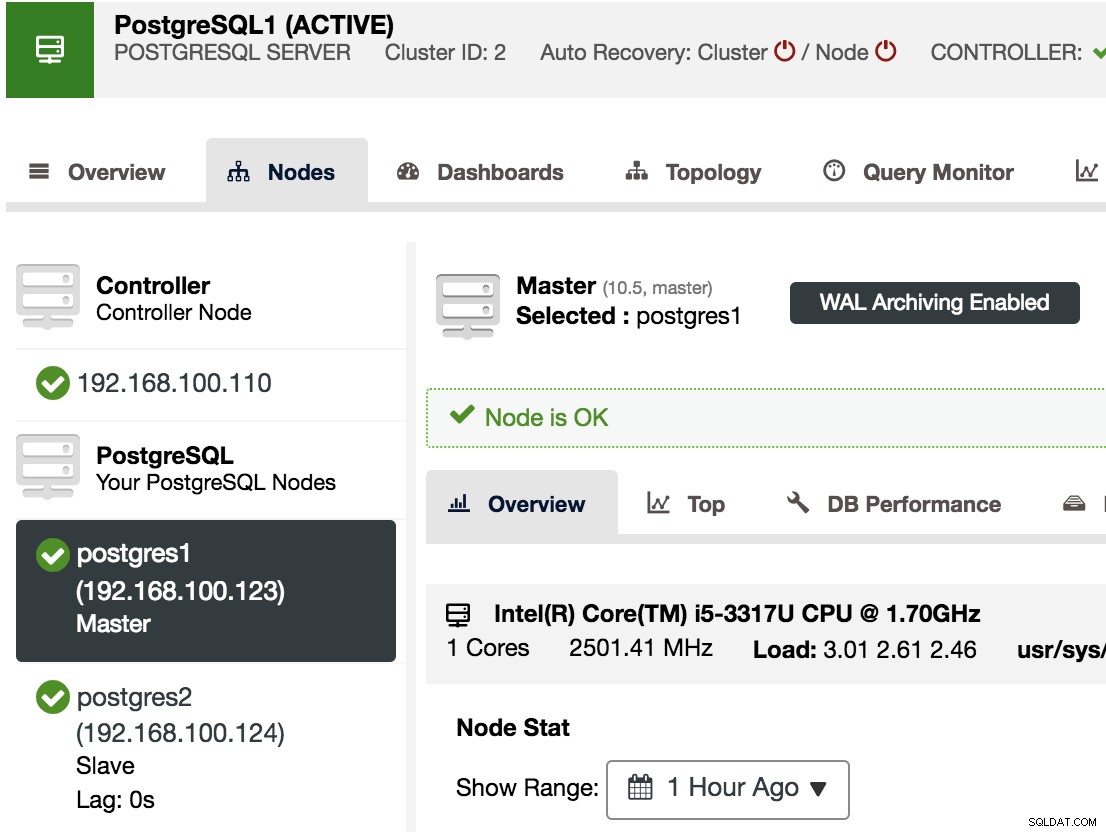
Om te bevestigen dat we WAL-archivering hebben ingeschakeld, kunnen we ons hoofdknooppunt selecteren in ClusterControl -> Selecteer PostgreSQL-cluster -> Nodes, en we zouden het bericht WAL-archivering ingeschakeld moeten zien, zoals we kunnen zien in de volgende afbeelding.
Een back-up maken die compatibel is met Point In Time Recovery
Als WAL-archivering is ingeschakeld, zoals we in de vorige stap hebben gezien, kunnen we onze back-up maken die compatibel is met PITR. Ga hiervoor naar ClusterControl -> Selecteer PostgreSQL Cluster -> Back-up -> Back-up maken.
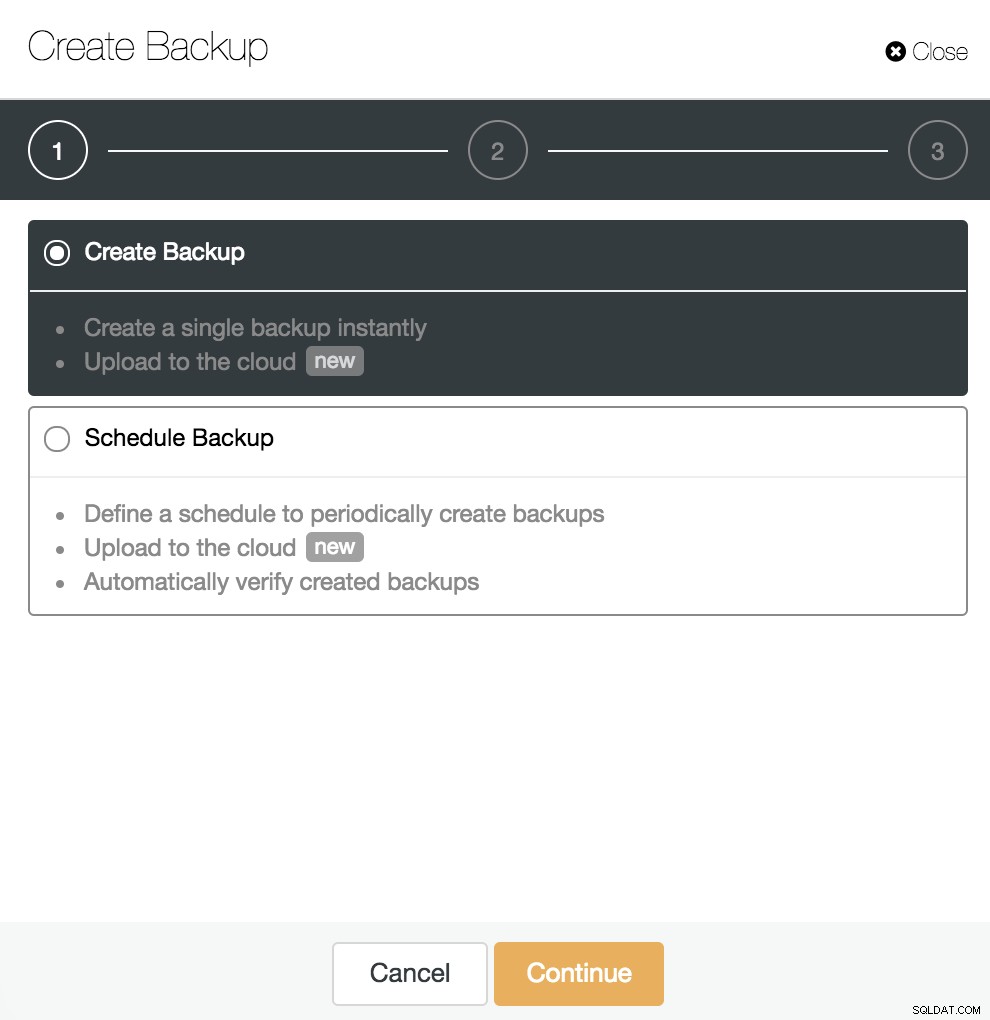
We kunnen een nieuwe back-up maken of een geplande back-up configureren. Voor ons voorbeeld zullen we direct een enkele back-up maken.
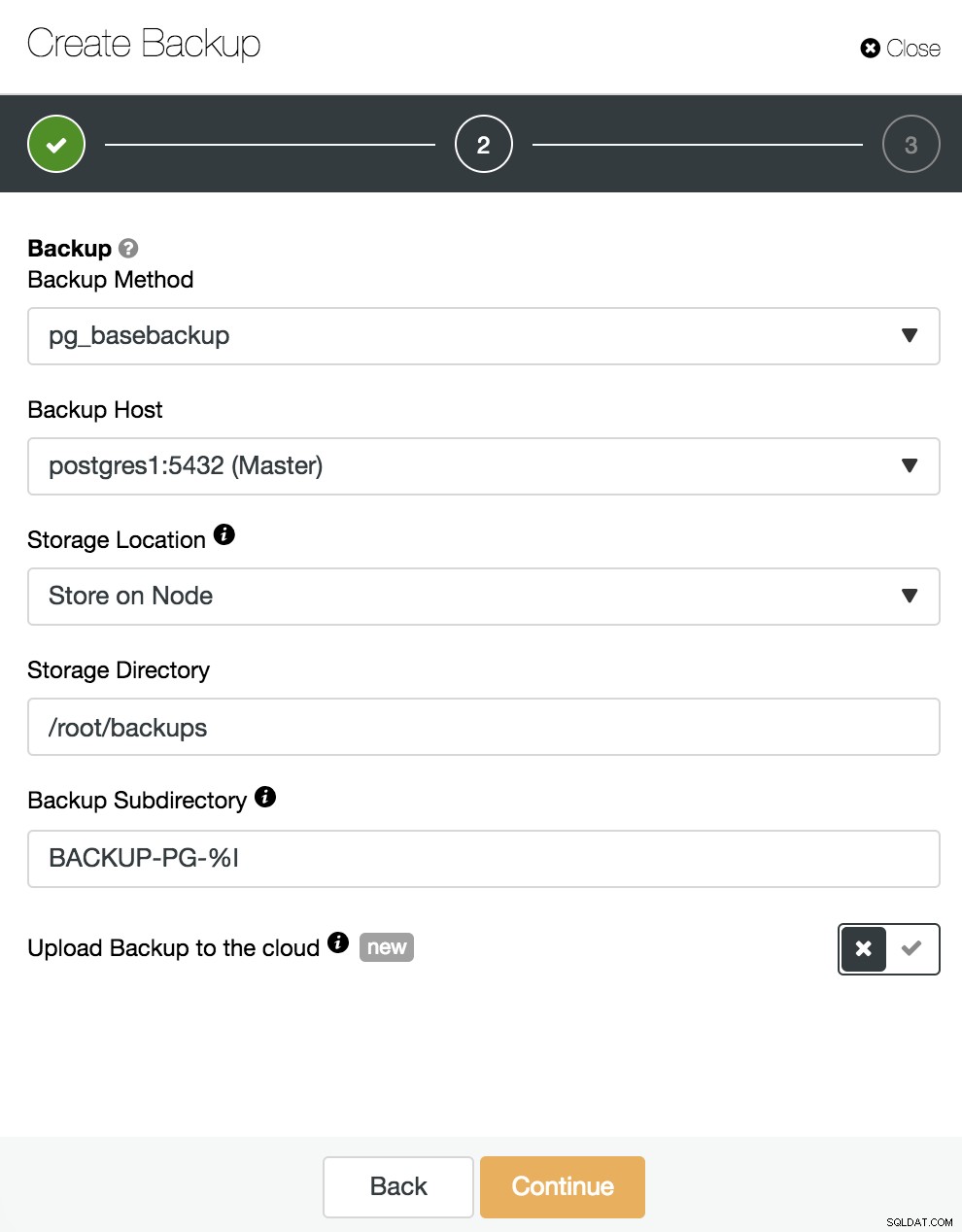
Hier moeten we de methode "pg_basebackup" kiezen, compatibel met PITR, de server waarvan de back-up zal worden genomen (om compatibel te zijn met PITR, moet dit de master zijn), en waar we de back-up willen opslaan. We kunnen onze back-up ook uploaden naar de cloud (AWS, Google of Azure) door de bijbehorende knop in te schakelen.
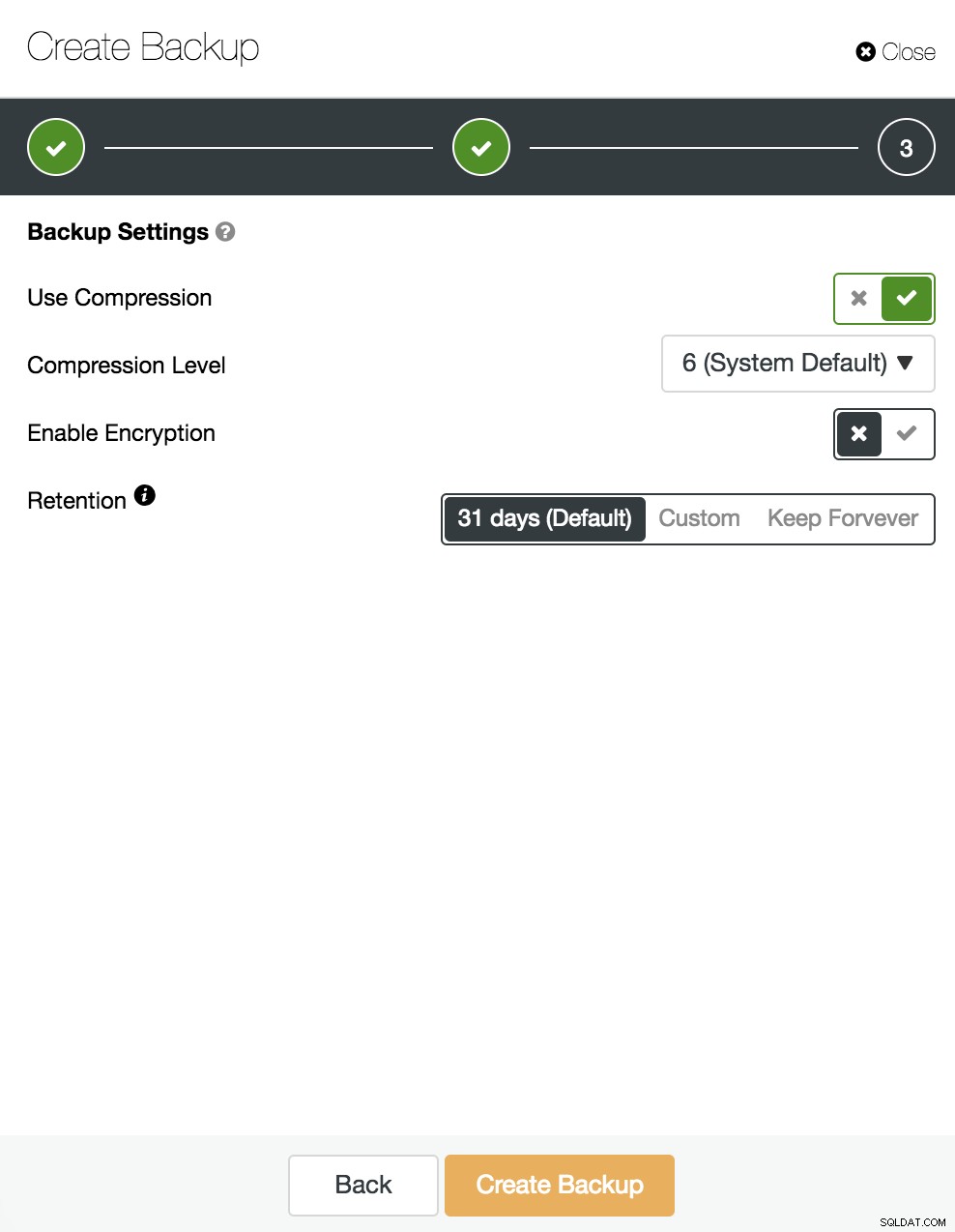
Vervolgens specificeren we het gebruik van compressie, encryptie en het bewaren van onze back-up.
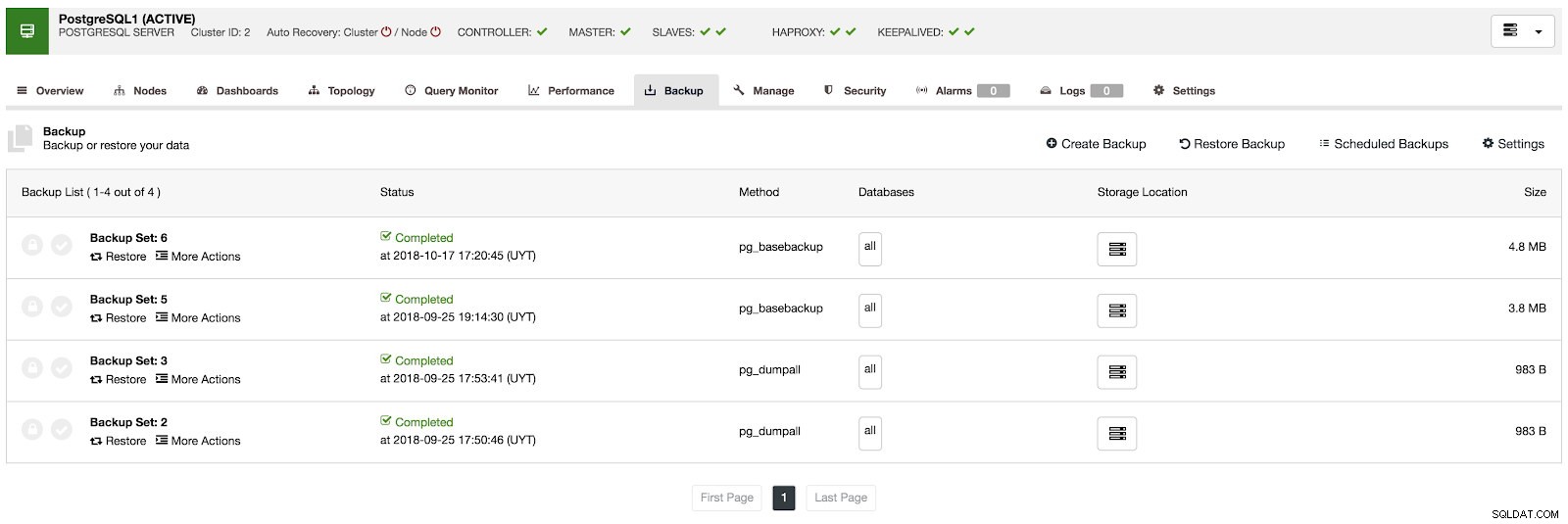
In het back-upgedeelte kunnen we de voortgang van de back-up zien en informatie zoals de methode, grootte, locatie en meer.
Point In Time Recovery vanaf een back-up
Zodra de back-up is voltooid, kunnen we deze herstellen met behulp van de ClusterControl PITR-functie. Hiervoor kunnen we in onze back-upsectie (ClusterControl -> Selecteer PostgreSQL-cluster -> Back-up) "Back-up herstellen" selecteren of direct "Herstellen" op de back-up die we willen herstellen.
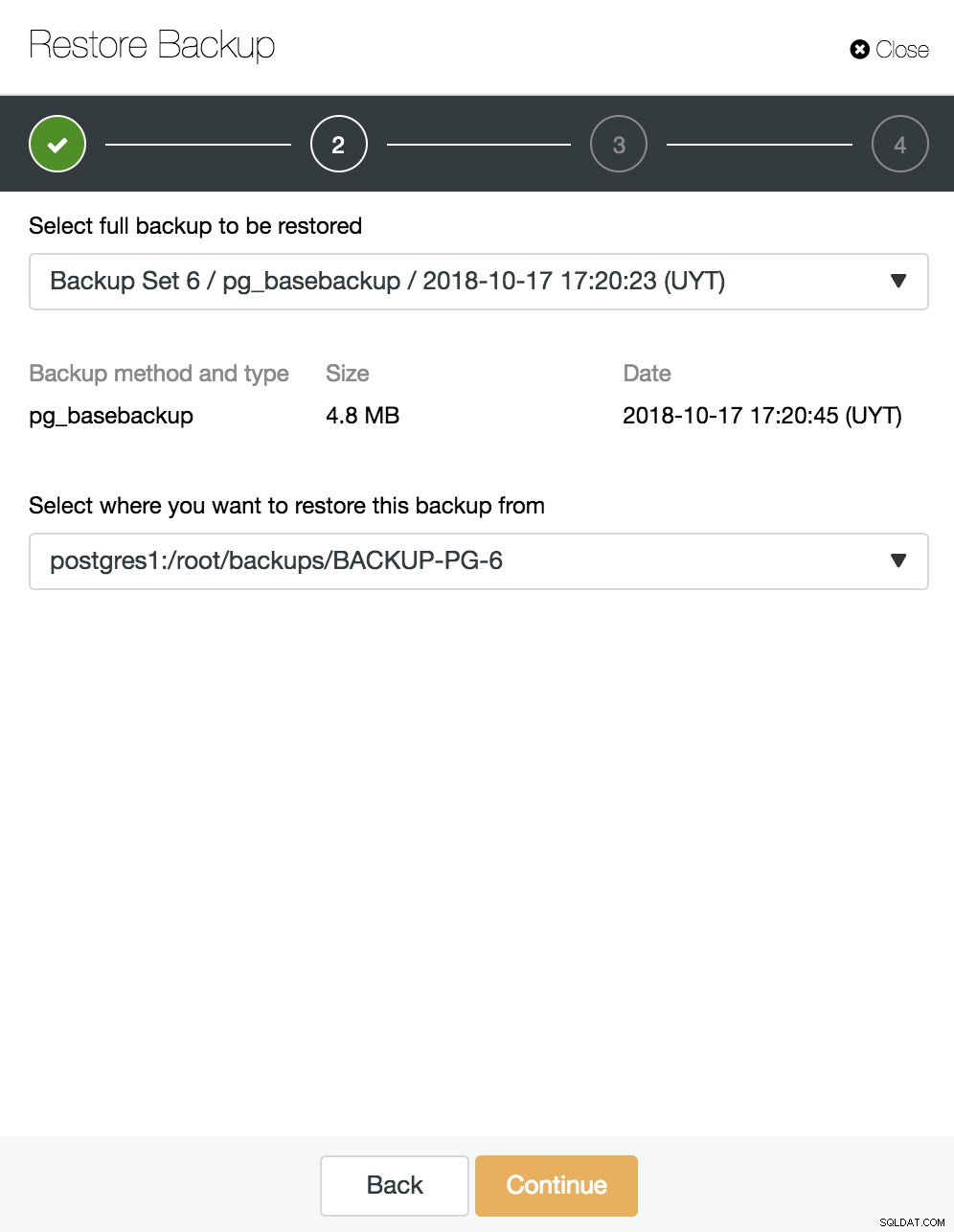
Hier kiezen we welke back-up we willen herstellen en uit welke map.
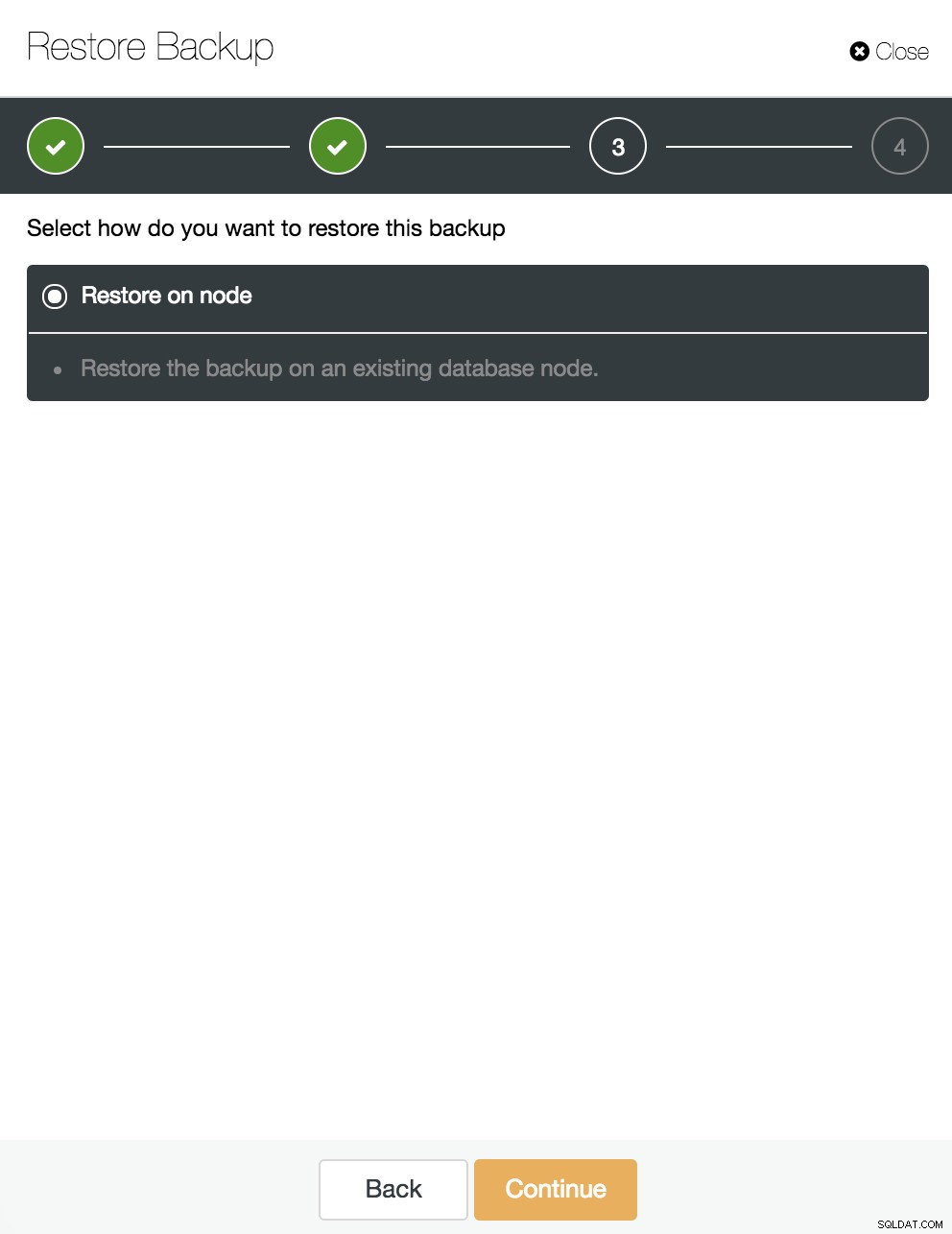
We laten de optie "Herstellen op knooppunt" geselecteerd en gaan verder.
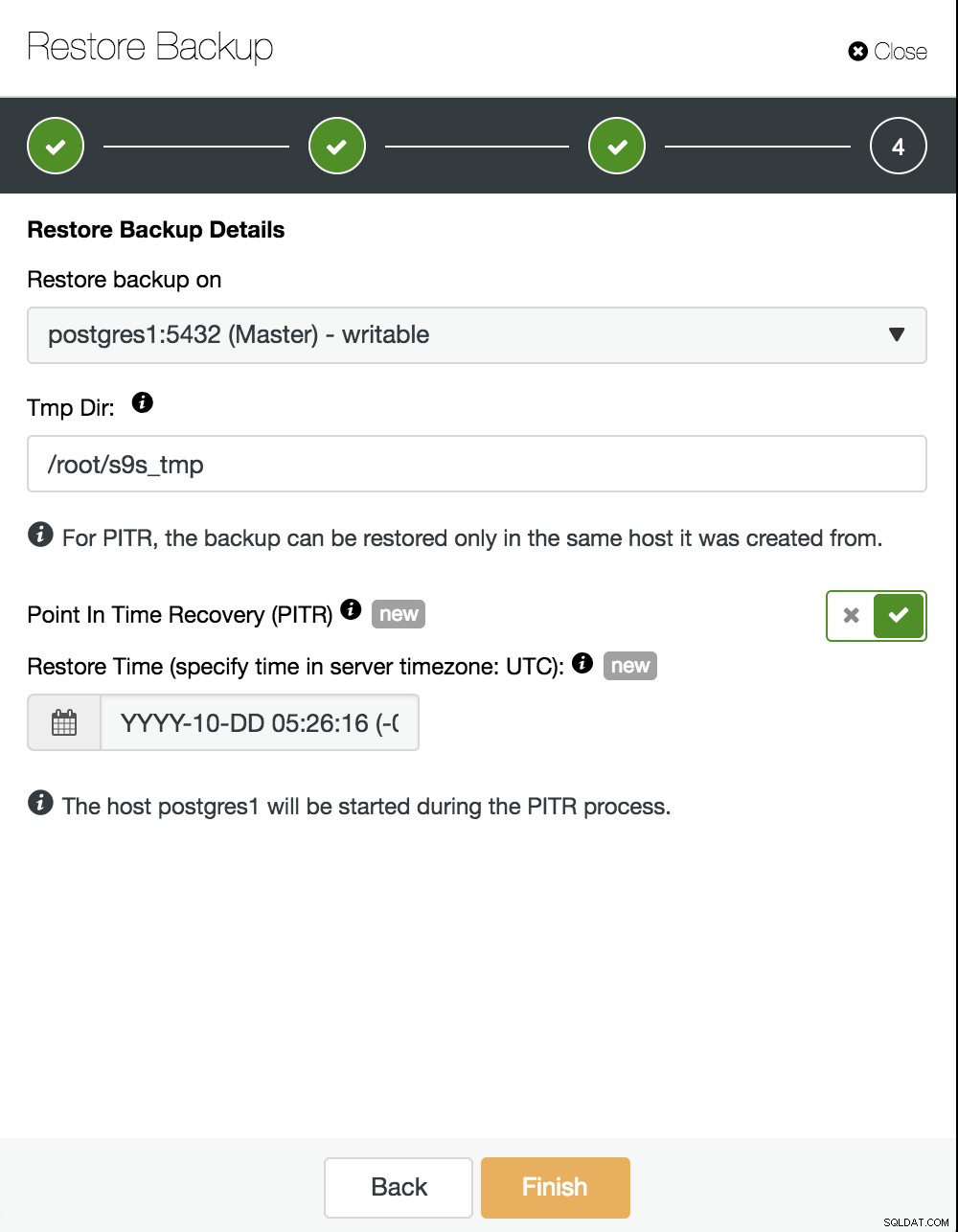
Nu moeten we kiezen waar we onze back-up willen herstellen en de PITR-optie inschakelen. Door de tijd op te geven, is dit de tijd tot wanneer we zullen herstellen. Houd er rekening mee dat de UTC-tijdzone wordt gebruikt en dat onze PostgreSQL-service in de master opnieuw wordt gestart.
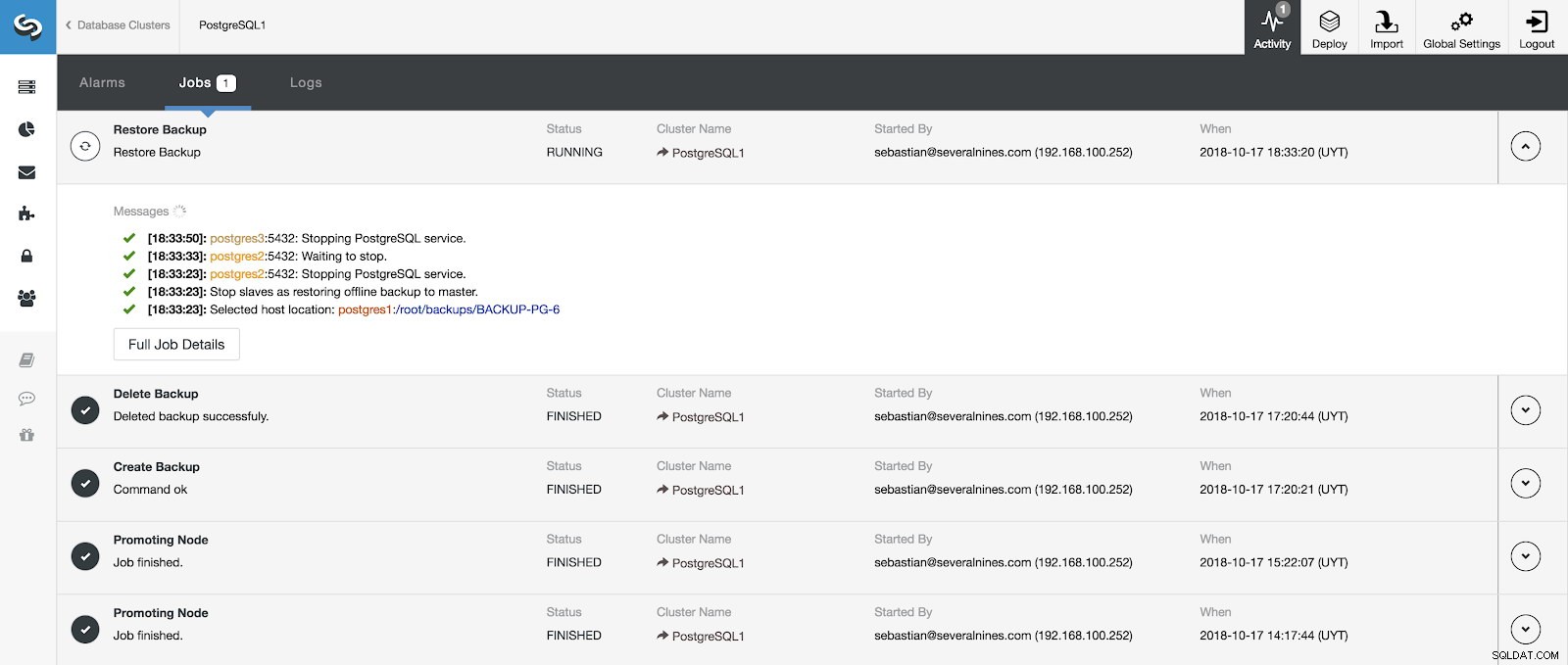
We kunnen de voortgang van ons herstel volgen vanuit het gedeelte Activiteit in onze ClusterControl.
Conclusie
PITR is een noodzakelijke functie om aan een strakke RPO te voldoen. We moeten het correct instellen om te zorgen voor een correct noodherstelplan. ClusterControl biedt een eenvoudig te gebruiken interface om u te helpen bij het implementeren van PITR voor uw PostgreSQL-databases.