Monitoring is een van de fundamentele taken in elk systeem. Het kan ons helpen om problemen op te sporen en actie te ondernemen, of gewoon om de huidige staat van onze systemen te kennen. Het gebruik van visuele displays kan ons effectiever maken omdat we prestatieproblemen gemakkelijker kunnen detecteren.
In deze blog zullen we zien hoe we SCUMM kunnen gebruiken om onze PostgreSQL-databases te monitoren en welke statistieken we voor deze taak kunnen gebruiken. We zullen ook de beschikbare dashboards doornemen, zodat u gemakkelijk kunt achterhalen wat er werkelijk gebeurt met uw PostgreSQL-instanties.
Wat is SCUMM?
Laten we eerst eens kijken wat SCUMM (Severalnines ClusterControl Unified Monitoring and Management) is.
Het is een nieuwe, op agenten gebaseerde oplossing waarbij agenten op de databaseknooppunten zijn geïnstalleerd.
De SCUMM-agenten zijn Prometheus-exporteurs die statistieken exporteren van services zoals PostgreSQL als Prometheus-statistieken.
Een Prometheus-server wordt gebruikt om tijdreeksgegevens van de SCUMM-agenten te schrapen en op te slaan.
Prometheus is een open-source toolkit voor systeemmonitoring en -waarschuwing die oorspronkelijk bij SoundCloud is gebouwd. Het is nu een op zichzelf staand open source-project en wordt onafhankelijk onderhouden.
Prometheus is ontworpen voor betrouwbaarheid, om het systeem te zijn waar u naar toe gaat tijdens een storing, zodat u snel problemen kunt diagnosticeren.
Hoe SCUMM gebruiken?
Wanneer we ClusterControl gebruiken, kunnen we bij het selecteren van een cluster een overzicht van onze databases zien, evenals enkele basisstatistieken die kunnen worden gebruikt om een probleem te identificeren. In het onderstaande dashboard zien we een master-slave-opstelling met één master en 2 slaves, met HAProxy en Keepalive.
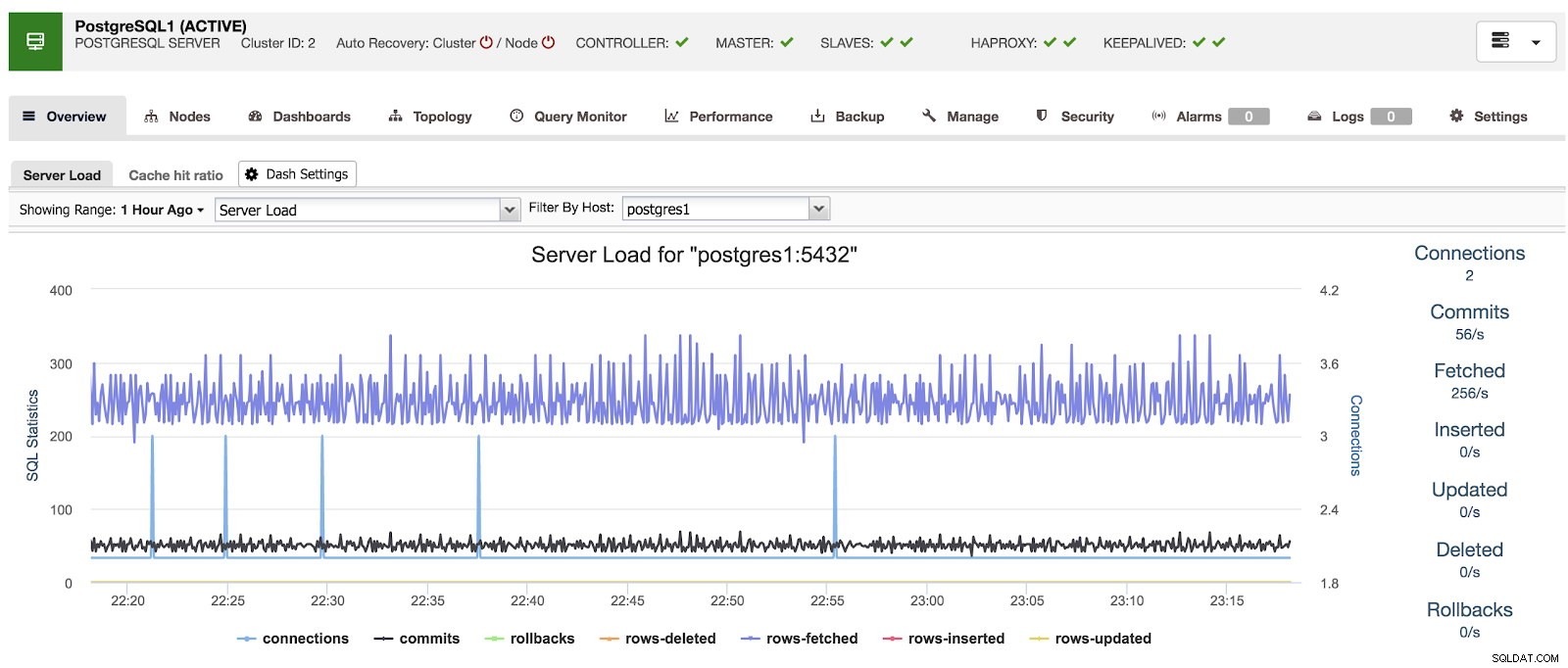 ClusterControl-overzicht
ClusterControl-overzicht Als we naar de optie "Dashboards" gaan, zien we een bericht zoals het volgende.
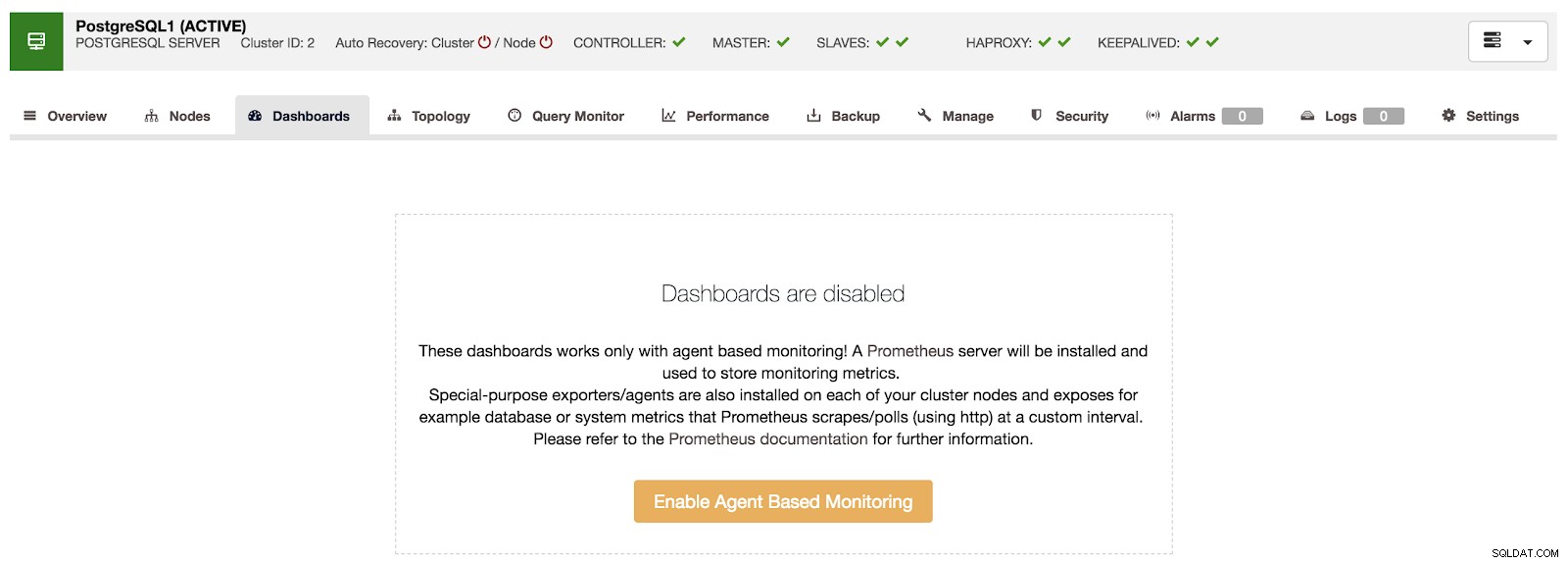 ClusterControl-dashboards uitgeschakeld
ClusterControl-dashboards uitgeschakeld Om deze functie te gebruiken, moeten we de bovengenoemde agent inschakelen. Hiervoor hoeven we in deze sectie alleen op de knop "Agent-gebaseerde bewaking inschakelen" te drukken.
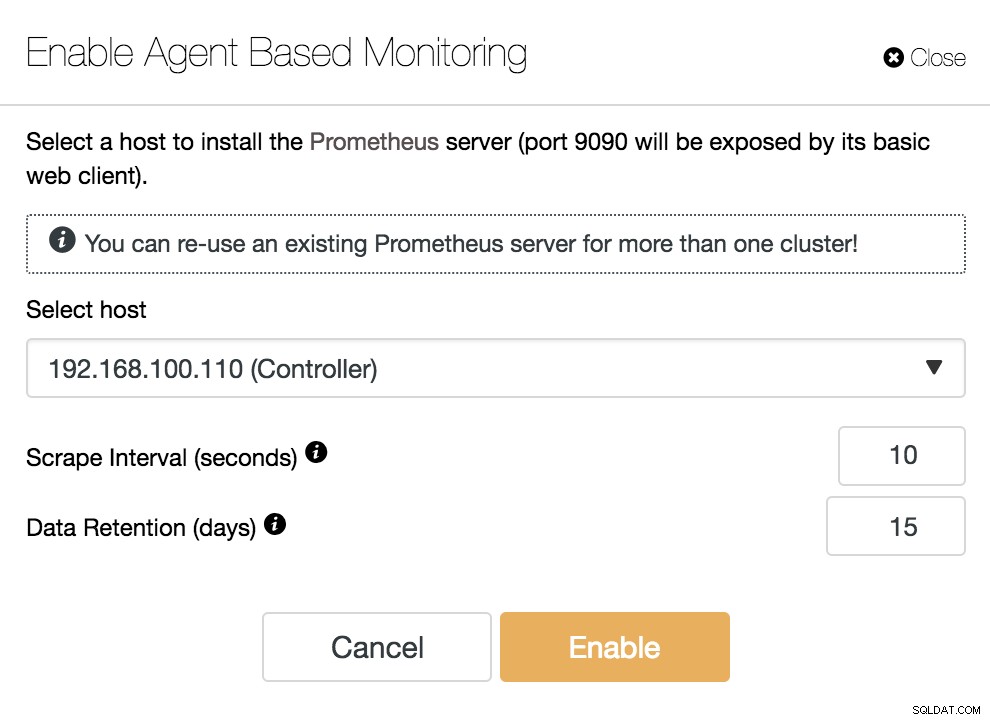 ClusterControl Agent-gebaseerde bewaking inschakelen
ClusterControl Agent-gebaseerde bewaking inschakelen Om onze agent in te schakelen, moeten we de host specificeren waar we onze Prometheus-server zullen installeren, wat, zoals we in het voorbeeld kunnen zien, onze ClusterControl-server kan zijn.
We moeten ook specificeren:
- Scrape-interval (seconden):stel in hoe vaak de nodes worden gescrapt voor statistieken. Standaard is 10 seconden.
- Gegevensretentie (dagen):stel in hoe lang de statistieken worden bewaard voordat ze worden verwijderd. Standaard is 15 dagen.
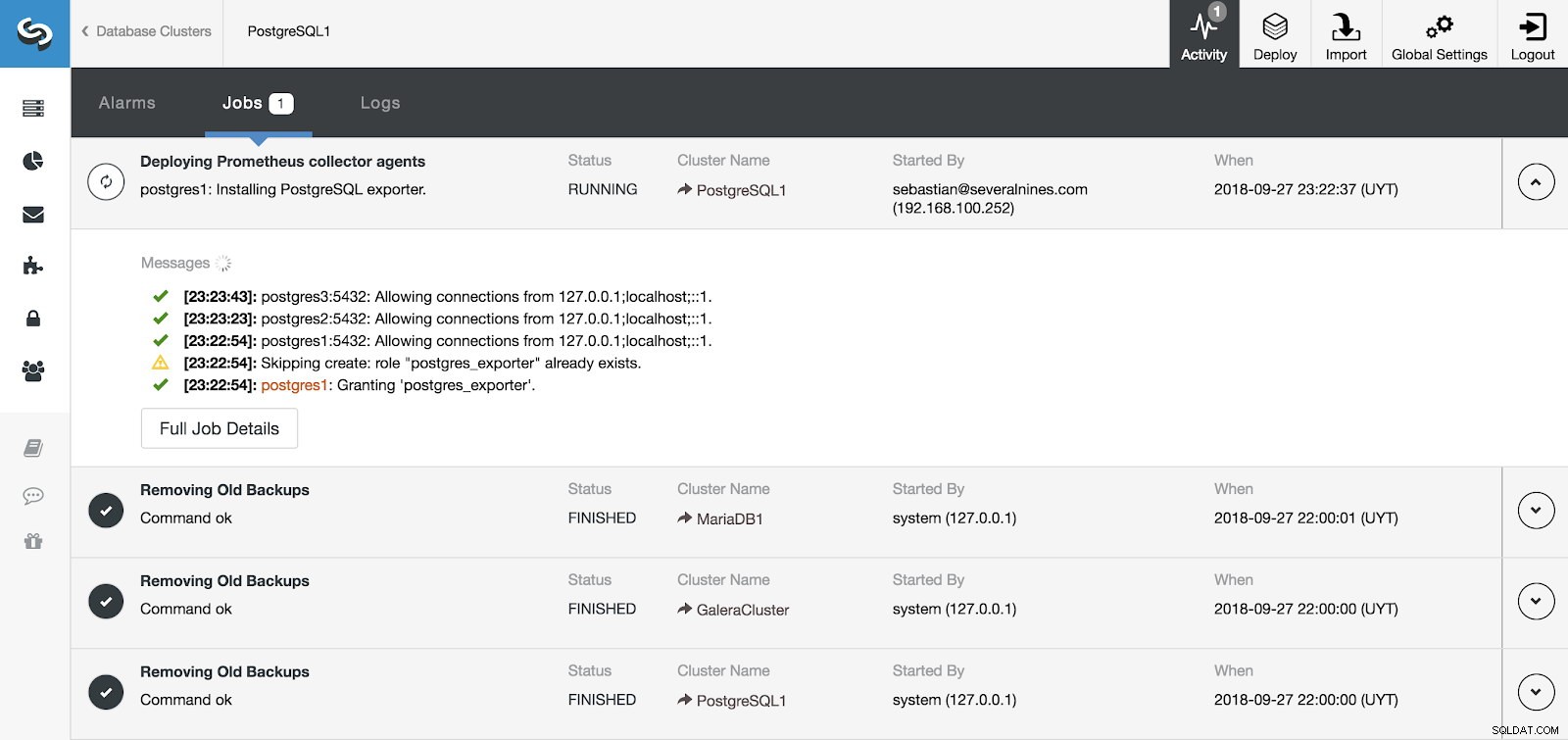 ClusterControl-activiteitengedeelte
ClusterControl-activiteitengedeelte We kunnen de installatie van onze server en agents volgen vanuit het gedeelte Activiteit in ClusterControl en als het klaar is, kunnen we ons cluster zien met de agents ingeschakeld in het hoofdscherm van ClusterControl.
 ClusterControl-agenten ingeschakeld
ClusterControl-agenten ingeschakeld Dashboards
Als onze agenten zijn ingeschakeld en we naar het gedeelte Dashboards gaan, zien we zoiets als dit:
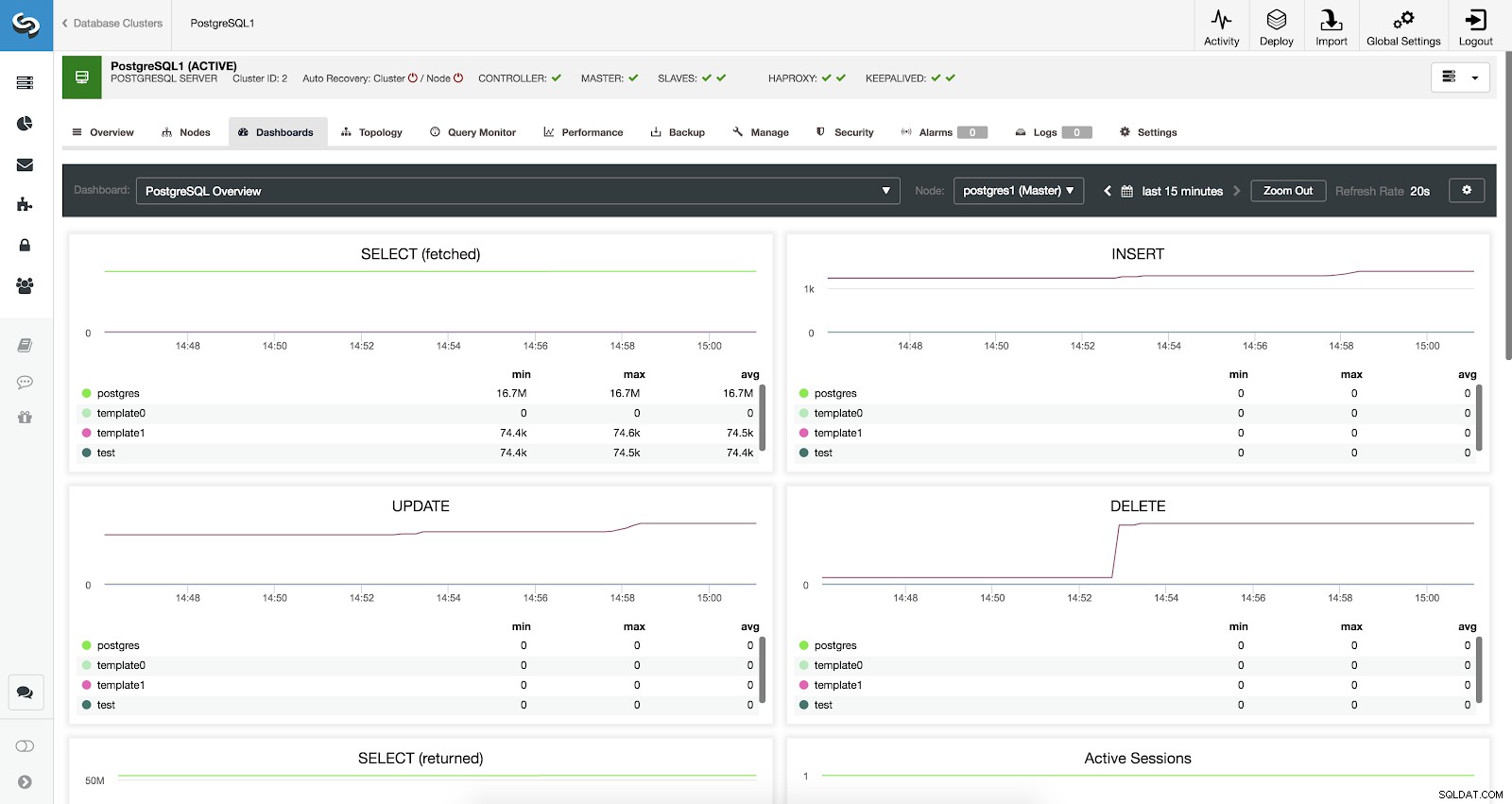 ClusterControl-dashboards ingeschakeld
ClusterControl-dashboards ingeschakeld We hebben drie verschillende soorten dashboards beschikbaar:Systeemoverzicht, Cross Server-grafieken en PostgreSQL-overzicht. De laatste is wat we standaard zien bij het betreden van deze sectie.
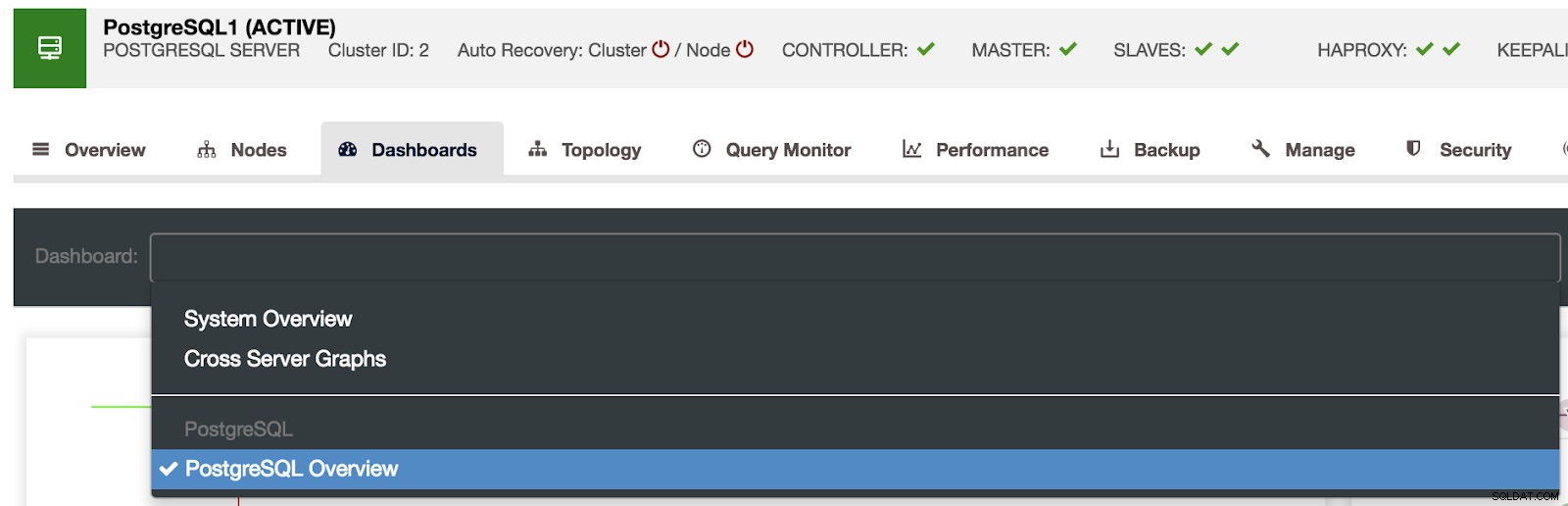 ClusterControl Dashboards-selectie
ClusterControl Dashboards-selectie Hier kunnen we ook specificeren welk knooppunt moet worden gecontroleerd, het tijdsbereik en de verversingssnelheid.
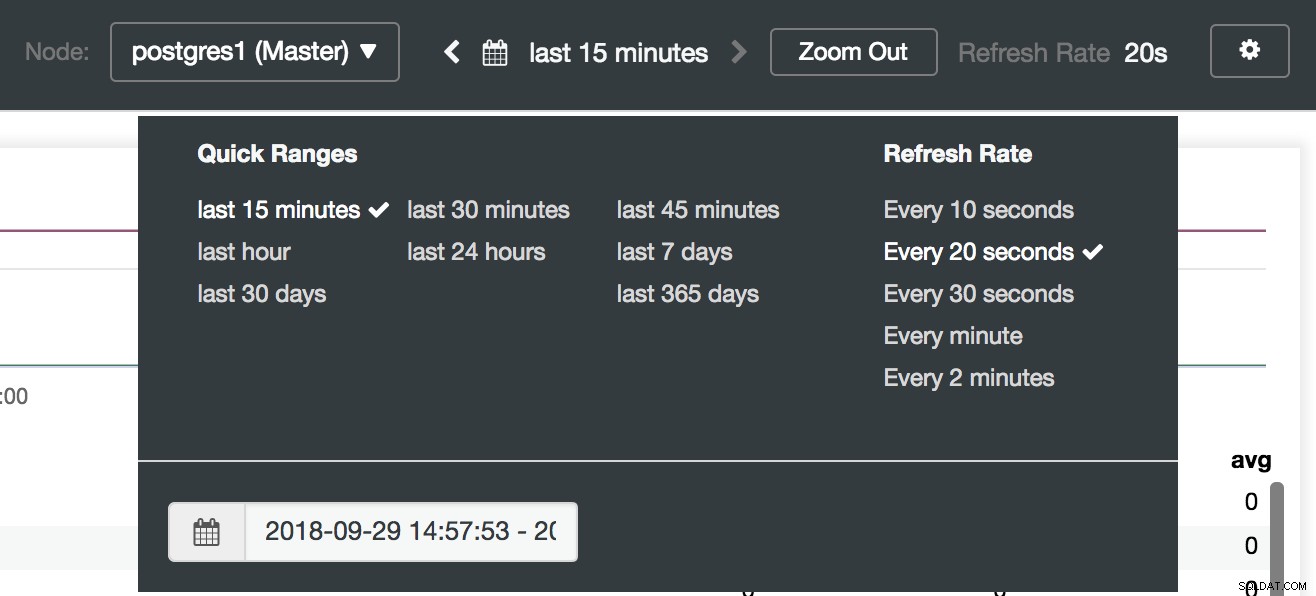 ClusterControl-dashboardopties
ClusterControl-dashboardopties In het configuratiegedeelte kunnen we onze agenten (Exporters) in- of uitschakelen, de status van de agenten controleren en de versie van onze Prometheus-server verifiëren.
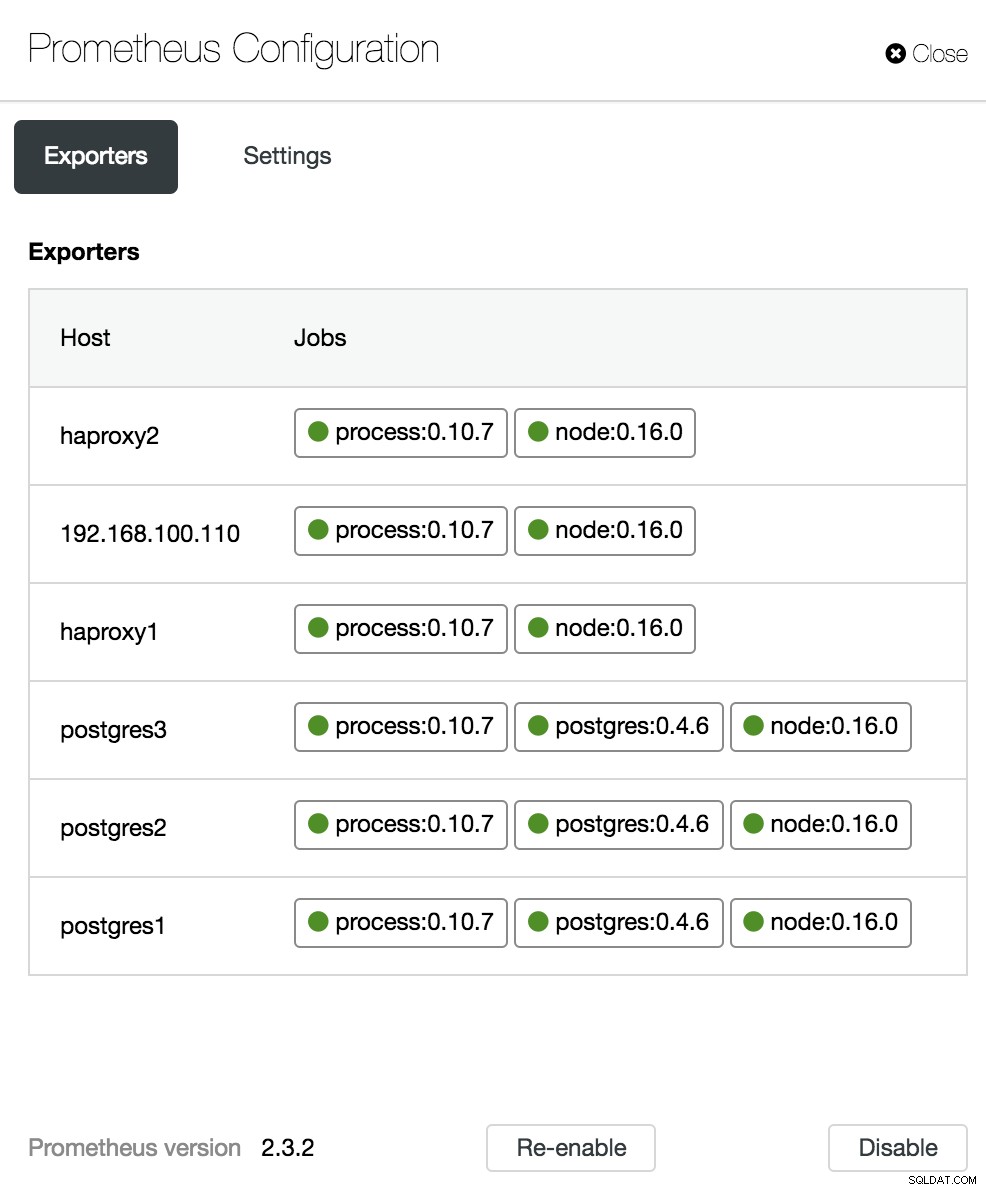 ClusterControl-dashboardconfiguratie
ClusterControl-dashboardconfiguratie PostgreSQL-overzichtsstatistieken
Laten we nu eens kijken welke statistieken we beschikbaar hebben voor elk van onze PostgreSQL-databases (allemaal voor het geselecteerde knooppunt).
- SELECT (opgehaald):aantal rijen geselecteerd (opgehaald) voor elke database. De opgehaalde rijen verwijzen naar live rijen die uit de tabel zijn opgehaald.
- SELECT (geretourneerd):aantal geselecteerde (geretourneerde) rijen voor elke database. De geretourneerde rijen verwijzen naar alle rijen die uit de tabel zijn gelezen, inclusief dode rijen en nog niet vastgelegde rijen (in tegenstelling tot de opgehaalde rijen die alleen de actieve tupels tellen).
- INSERT:Aantal rijen ingevoegd voor elke database.
- UPDATE:aantal rijen bijgewerkt voor elke database.
- VERWIJDEREN:aantal verwijderde rijen voor elke database.
- Actieve sessies:aantal actieve sessies (min, max en gemiddeld) voor elke database.
- Inactieve sessies:aantal inactieve sessies (min, max en gemiddeld) voor elke database.
- Vergrendeltabellen:aantal vergrendelingen (min, max en gemiddeld) gescheiden op type voor elke database.
- Disk IO-gebruik:Server disk IO-gebruik.
- Schijfgebruik:percentage serverschijfgebruik (min, max en gemiddeld).
- Schijflatentie:serverschijflatentie.
ClusterControl PostgreSQL-overzichtsstatistieken Systeemoverzichtsstatistieken
Om ons systeem te bewaken, hebben we voor elke server de volgende statistieken beschikbaar (allemaal voor het geselecteerde knooppunt):
- Uptime van het systeem:tijd sinds de server actief is.
- CPU's:aantal CPU's.
- RAM:hoeveelheid RAM-geheugen.
- Beschikbaar geheugen:percentage van het beschikbare RAM-geheugen.
- Gemiddelde belasting:min, max en gemiddelde serverbelasting.
- Geheugen:beschikbaar, totaal en gebruikt servergeheugen.
- CPU-gebruik:informatie over min, max en gemiddeld server-CPU-gebruik.
- Geheugendistributie:geheugendistributie (buffer, cache, gratis en gebruikt) op het geselecteerde knooppunt.
- Verzadigingsstatistieken:min, max en gemiddelde van IO-belasting en CPU-belasting op het geselecteerde knooppunt.
- Geheugen Geavanceerde details:details over geheugengebruik, zoals pagina's, buffer en meer, op het geselecteerde knooppunt.
- Forks:aantal vorkprocessen. Fork is een bewerking waarbij een proces een kopie van zichzelf maakt. Het is meestal een systeemaanroep, geïmplementeerd in de kernel.
- Processen:het aantal processen dat wordt uitgevoerd of wacht op het besturingssysteem.
- Context-switches:een context-switch is de actie waarbij de status van een proces of een thread wordt opgeslagen.
- Interrupts:aantal interrupts. Een interrupt is een gebeurtenis die de normale uitvoeringsstroom van een programma verandert en kan worden gegenereerd door hardwareapparaten of zelfs door de CPU zelf.
- Netwerkverkeer:inkomend en uitgaand netwerkverkeer in KBytes per seconde op het geselecteerde knooppunt.
- Netwerkgebruik per uur:verkeer dat de afgelopen dag is verzonden en ontvangen.
- Swap:Ruil gebruik (gratis en gebruikt) op het geselecteerde knooppunt.
- Swap-activiteit:leest en schrijft gegevens over swap.
- I/O-activiteit:Page in en page out op IO.
- Bestandsbeschrijvingen:toegewezen en beperk bestandsbeschrijvingen.
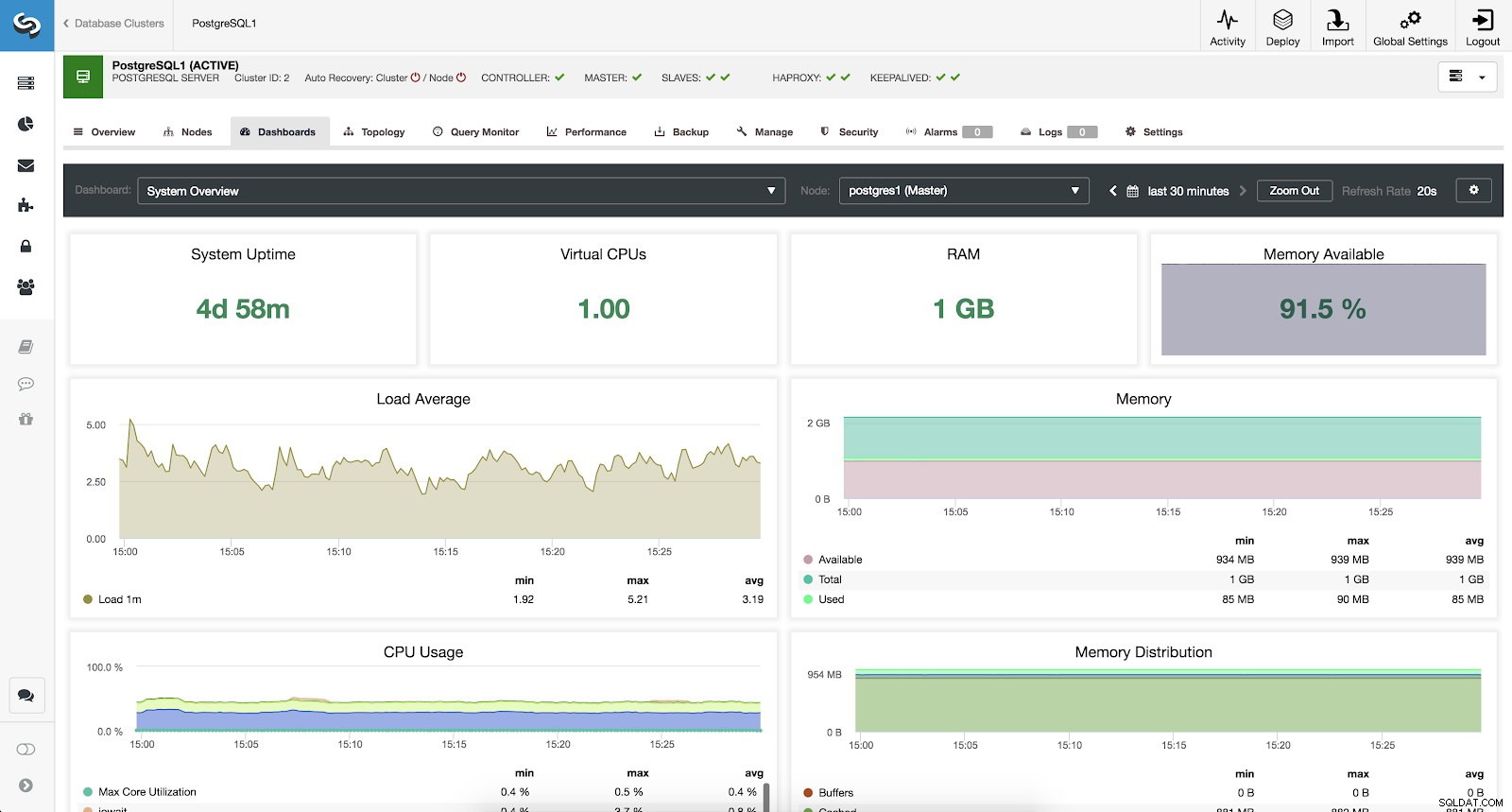 ClusterControl-systeemoverzicht Metrieken
ClusterControl-systeemoverzicht Metrieken Cross-server grafieken statistieken
Als we de algemene status van al onze servers willen zien, kunnen we dit dashboard gebruiken met de volgende statistieken:
- Gemiddelde belasting:servers worden gemiddeld voor elke server geladen.
- Geheugengebruik:percentage van het geheugengebruik voor elke server.
- Netwerkverkeer:min, max en gemiddeld kByte netwerkverkeer per seconde.
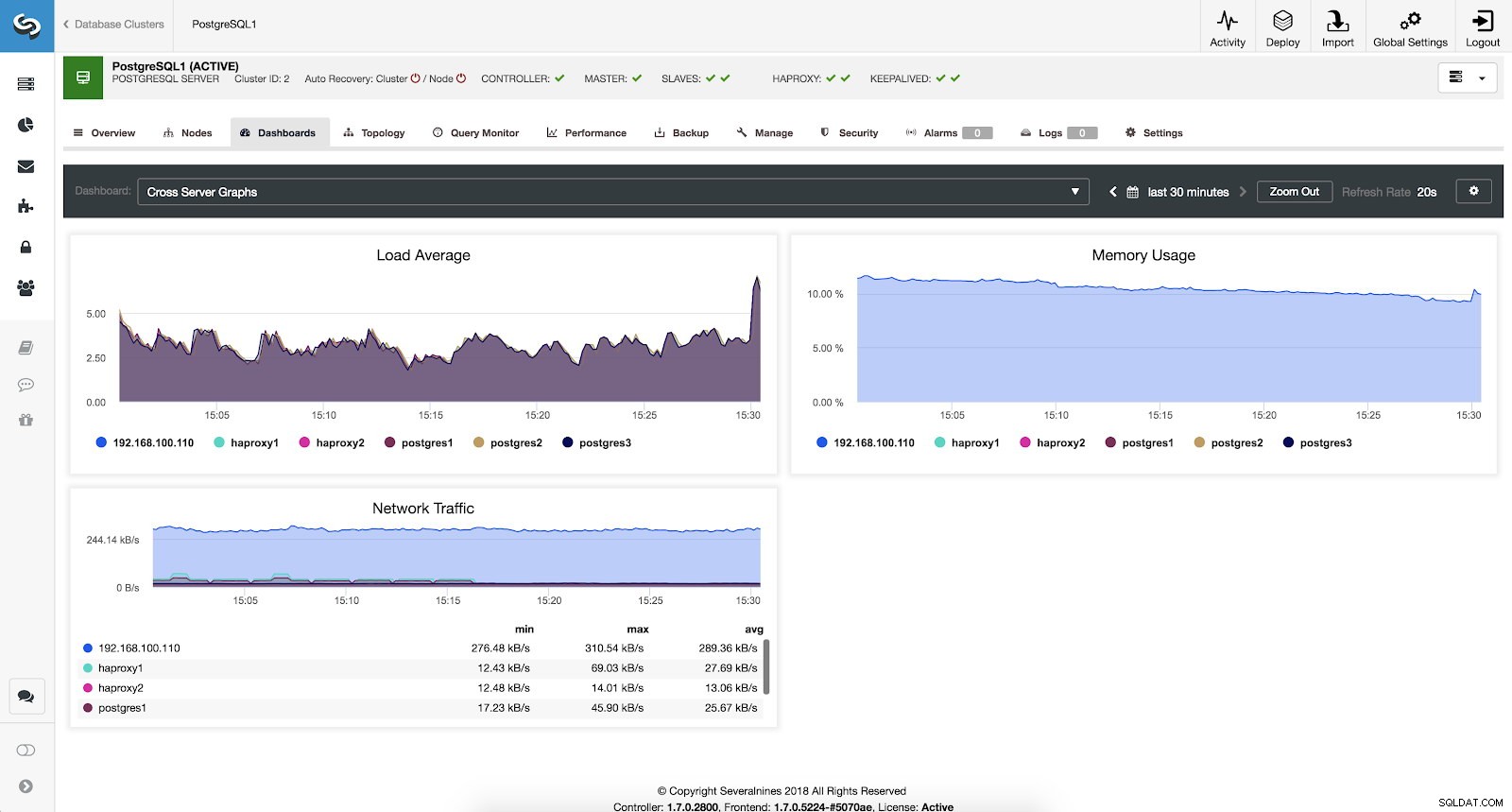 ClusterControl Cross Server-grafiekenstatistieken
ClusterControl Cross Server-grafiekenstatistieken Conclusie
Er zijn meerdere manieren om PostgreSQL te controleren. ClusterControl biedt zowel agentless als nu agent-based monitoring via Prometheus. Het biedt monitoringgegevens met een hogere resolutie en verschillende dashboards om inzicht te krijgen in de databaseprestaties. ClusterControl kan ook worden geïntegreerd met externe tools zoals Slack of PagerDuty voor waarschuwingen.