Met Disaster Recovery willen we systemen opzetten om alles aan te pakken dat fout zou kunnen gaan met onze database. Wat gebeurt er als de database crasht? Wat als een ontwikkelaar per ongeluk een tabel afkapt? Wat als we erachter komen dat sommige gegevens vorige week zijn verwijderd, maar we hebben het pas vandaag opgemerkt? Deze dingen gebeuren, en met een solide plan en systeem zal de DBA eruitzien als een held wanneer de harten van alle anderen al zijn gestopt wanneer een ramp zijn lelijke kop opsteekt.
Elke database die enige waarde heeft, moet een manier hebben om een of meer Disaster Recovery-opties te implementeren. PostgreSQL heeft een zeer solide ingebouwd replicatiesysteem en is flexibel genoeg om in veel configuraties te worden opgezet om te helpen bij Disaster Recovery, mocht er iets misgaan. We concentreren ons op scenario's zoals hierboven besproken, hoe onze Disaster Recovery-opties in te stellen en de voordelen van elke oplossing.
Hoge beschikbaarheid
Met streamingreplicatie in PostgreSQL is High Availability eenvoudig in te stellen en te onderhouden. Het doel is om een failover-site te bieden die kan worden gepromoveerd tot master als de hoofddatabase om welke reden dan ook uitvalt, zoals hardwarestoringen, softwarestoringen of zelfs netwerkstoringen. Een replica hosten op een andere host is geweldig, maar deze in een ander datacenter hosten is nog beter.
Voor meer informatie over het instellen van streaming-replicatie, heeft Multiplenines hier een gedetailleerde diepe duik beschikbaar. De officiële PostgreSQL-documentatie voor streamingreplicatie bevat gedetailleerde informatie over het streamingreplicatieprotocol en hoe het allemaal werkt.
Een standaardconfiguratie ziet er als volgt uit:een hoofddatabase die lees-/schrijfverbindingen accepteert, met een replicadatabase die alle WAL-activiteiten in bijna realtime ontvangt en alle gegevenswijzigingsactiviteiten lokaal afspeelt.
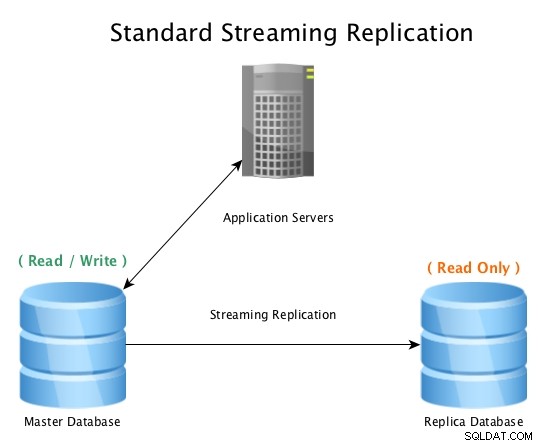 Standaard streaming-replicatie met PostgreSQL
Standaard streaming-replicatie met PostgreSQL Wanneer de masterdatabase onbruikbaar wordt, wordt een failover-procedure gestart om deze offline te brengen en de replicadatabase tot master te promoveren, waarna alle verbindingen naar de nieuw gepromoveerde host worden verwezen. Dit kan worden gedaan door een load balancer, applicatieconfiguratie, IP-aliassen of andere slimme manieren om het verkeer om te leiden opnieuw te configureren.
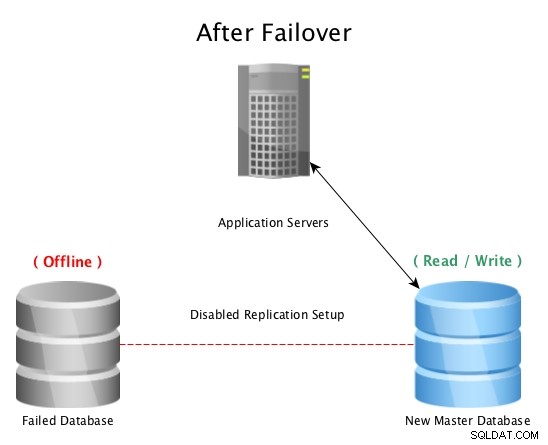 Na een failover met PostgreSQL-streamingreplicatie
Na een failover met PostgreSQL-streamingreplicatie Wanneer een ramp een masterdatabase treft (zoals een harde schijfstoring, stroomuitval of iets anders waardoor de master niet werkt zoals bedoeld), is het overschakelen naar een hot standby de snelste manier om online te blijven en vragen aan applicaties of klanten te beantwoorden zonder serieuze uitvaltijd. De race is dan begonnen om ofwel de defecte database-host te repareren, of een nieuwe replica online te brengen om het vangnet te behouden dat er een stand-by gereed is voor gebruik. Het hebben van meerdere standbys zorgt ervoor dat het venster na een rampzalige storing ook klaar is voor een secundaire storing, hoe onwaarschijnlijk het ook lijkt.
Opmerking:als je faalt naar een streaming-replica, gaat deze verder waar de vorige master was gebleven, dus dit helpt om de database online te houden, maar niet om per ongeluk verloren gegevens te herstellen.
Tijdsherstel
Een andere Disaster Recovery-optie is Point in TIME Recovery (PITR). Met PITR kan een kopie van de database worden teruggehaald op elk gewenst moment, zolang we een basisback-up hebben van voor die tijd en alle WAL-segmenten die tot die tijd nodig waren.
Een Point In Time Recovery-optie wordt niet zo snel online gebracht als een Hot Standby, maar het belangrijkste voordeel is dat u een database-snapshot kunt herstellen vóór een grote gebeurtenis, zoals een verwijderde tabel, slechte gegevens die worden ingevoegd of zelfs onverklaarbare gegevenscorruptie . Alles dat gegevens op zo'n manier zou vernietigen dat we een kopie zouden willen hebben voor die vernietiging, PITR redt de dag.
Point in Time Recovery werkt door periodieke snapshots van de database te maken, meestal met behulp van het programma pg_basebackup, en gearchiveerde kopieën te bewaren van alle WAL-bestanden die door de master zijn gegenereerd
Instelling voor herstel op tijd
Setup vereist een paar configuratie-opties die op de master zijn ingesteld, waarvan sommige goed passen bij de standaardwaarden van de huidige nieuwste versie, PostgreSQL 11. In dit voorbeeld zullen we het 16 MB-bestand rechtstreeks naar onze externe PITR-host kopiëren met rsync , en ze aan de andere kant comprimeren met een cronjob.
WAL-archivering
Master postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'OPMERKING: De instelling archive_command kan van alles zijn, het algemene doel is om alle gearchiveerde WAL-bestanden om veiligheidsredenen naar een andere host te sturen. Als we WAL-bestanden verliezen, wordt PITR voorbij het verloren WAL-bestand onmogelijk. Laat je programmeercreativiteit de vrije loop, maar zorg ervoor dat het betrouwbaar is.
[Optioneel] Comprimeer de gearchiveerde WAL-bestanden:
Elke setup zal enigszins variëren, maar tenzij de database in kwestie erg licht is in gegevensupdates, zal de opbouw van 16 MB-bestanden vrij snel schijfruimte opvullen. Een eenvoudig compressiescript, opgezet via cron, zou er als volgt uit kunnen zien.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]OPMERKING: Tijdens elke herstelmethode moeten gecomprimeerde bestanden later worden gedecomprimeerd. Sommige beheerders kiezen ervoor om bestanden pas te comprimeren als ze X dagen oud zijn, waardoor de totale ruimte laag blijft, maar ook om recentere WAL-bestanden klaar te houden voor herstel zonder extra werk. Kies de beste optie voor de betreffende databases om uw herstelsnelheid te maximaliseren.
Basisback-ups
Een van de belangrijkste componenten van een PITR-back-up is de basisback-up en de frequentie van de basisback-ups. Deze kunnen elk uur, dagelijks, wekelijks, maandelijks zijn, maar kozen de beste optie op basis van herstelbehoeften en het verkeer van de databasegegevensverloop. Als we elke zondag wekelijkse back-ups hebben en we moeten herstellen tot zaterdagmiddag, dan brengen we de basisback-up van de vorige zondag online met alle WAL-bestanden tussen die back-up en zaterdagmiddag. Als dit herstelproces 10 uur duurt om te verwerken, is dit waarschijnlijk ongewenst te lang. Dagelijkse basisback-ups zullen die hersteltijd verkorten, aangezien de basisback-up vanaf die ochtend zou zijn, maar ook de hoeveelheid werk op de host voor de basisback-up vergroten zelf.
Als een week lang herstel van WAL-bestanden slechts een paar minuten duurt, omdat de database weinig verloop heeft, dan zijn wekelijkse back-ups prima. Dezelfde gegevens zullen uiteindelijk bestaan, maar hoe snel je er toegang toe hebt, is de sleutel.
In ons voorbeeld zullen we een wekelijkse basisback-up opzetten en aangezien we Streaming Replication gebruiken voor hoge beschikbaarheid, en de belasting van de master verminderen, zullen we de basisback-up maken op basis van de replicadatabase.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zOPMERKING: Het pg_basebackup-commando gaat ervan uit dat deze host is ingesteld voor wachtwoordloze toegang voor gebruiker 'replicatie' op de master, wat kan worden gedaan door 'vertrouwen' in pg_hba voor deze PITR-back-uphost, wachtwoord in het .pgpass-bestand of andere veiligere manieren . Houd de beveiliging in gedachten bij het instellen van back-ups.
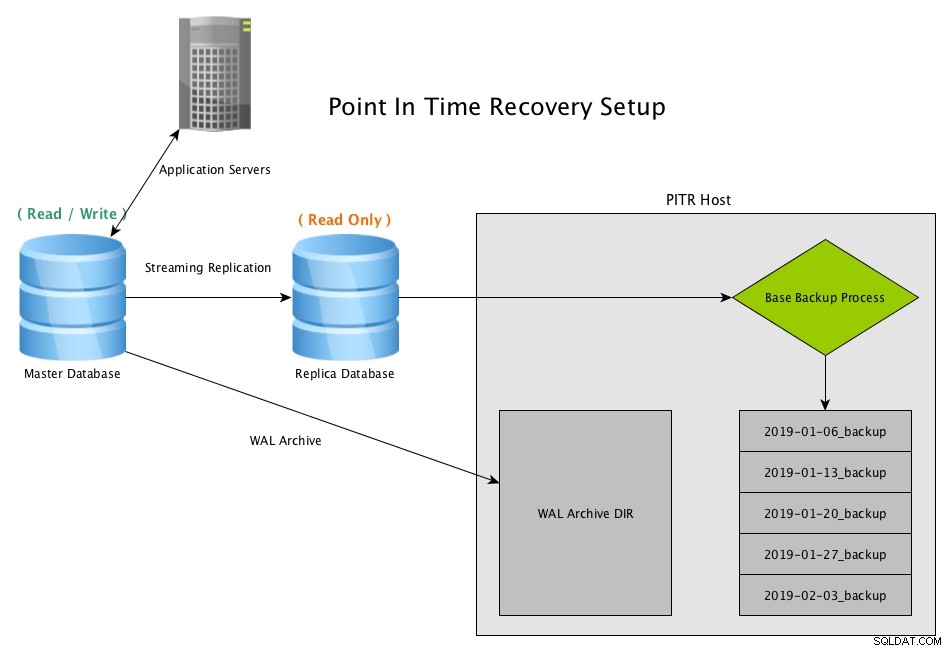 Point In Time Recovery (PITR) van een streamingreplica met PostgreSQLDownload vandaag de whitepaper PostgreSQL-beheer en -automatisering met ClusterControlMeer informatie over wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaper
Point In Time Recovery (PITR) van een streamingreplica met PostgreSQLDownload vandaag de whitepaper PostgreSQL-beheer en -automatisering met ClusterControlMeer informatie over wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaper PITR-herstelscenario
Het opzetten van Point In Time Recovery is slechts een deel van het werk, het moeten herstellen van gegevens is het andere deel. Met een beetje geluk hoeft dit misschien nooit te gebeuren, maar het wordt ten zeerste aangeraden om periodiek een PITR-back-up te herstellen om te valideren dat het systeem werkt en om ervoor te zorgen dat het proces bekend is / correct is gescript.
In ons testscenario kiezen we een tijdstip om te herstellen en het herstelproces te starten. Bijvoorbeeld:vrijdagochtend pusht een ontwikkelaar een nieuwe codewijziging naar productie zonder een codebeoordeling te ondergaan, en het vernietigt een heleboel belangrijke klantgegevens. Omdat onze Hot Standby altijd synchroon loopt met de master, zou het niet oplossen van iets niets oplossen, omdat het dezelfde gegevens zouden zijn. PITR-back-ups is wat ons zal redden.
De code push ging om 11 uur 's ochtends binnen, dus we moeten de database herstellen naar net voor die tijd, 10:59 uur besluiten we, en gelukkig doen we dagelijks back-ups zodat we een back-up hebben vanaf middernacht vanmorgen. Omdat we niet weten wat er allemaal is vernietigd, besluiten we ook om deze database volledig te herstellen op onze PITR-host en deze online te brengen als de master, omdat deze dezelfde hardwarespecificaties heeft als de master, voor het geval dit scenario is gebeurd.
Shutdown The Master
Aangezien we besloten hebben om volledig te herstellen vanaf een back-up en deze te promoveren naar master, is het niet nodig om deze online te houden. We sluiten het af, maar bewaren het voor het geval we er later iets uit moeten halen, voor het geval dat.
Basisback-up instellen voor herstel
Vervolgens halen we op onze PITR-host onze meest recente basisback-up op van vóór het evenement, namelijk back-up '2018-12-21_backup'.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Hiermee zijn de basisback-up, evenals de WAL-bestanden die door pg_basebackup worden geleverd, klaar voor gebruik, als we deze nu online brengen, zal deze herstellen tot het punt waarop de back-up plaatsvond, maar we willen alle WAL-transacties herstellen tussen middernacht en 11:59 uur, dus we hebben ons recovery.conf-bestand opgezet.
Recovery.conf maken
Aangezien deze back-up feitelijk afkomstig is van een streaming-replica, is er waarschijnlijk al een recovery.conf-bestand met replica-instellingen. We zullen het overschrijven met nieuwe instellingen. Een gedetailleerde informatielijst voor alle verschillende opties is hier beschikbaar in de documentatie van PostgreSQL.
Wees voorzichtig met de WAL-bestanden, de restore-opdracht kopieert de gecomprimeerde bestanden die nodig zijn naar de herstelmap, decomprimeert ze en gaat vervolgens naar de plaats waar PostgreSQL ze nodig heeft voor herstel. De originele WAL-bestanden blijven waar ze zijn voor het geval dat om andere redenen nodig is.
Nieuwe recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Start het herstelproces
Nu alles is ingesteld, starten we het herstelproces. Wanneer dit gebeurt, is het een goed idee om het databaselogboek te volgen om er zeker van te zijn dat het herstelt zoals bedoeld.
Start de database:
pg_ctl -D /var/lib/pgsql/11/data startLaat de logs achter:
Er zullen veel log-items zijn die laten zien dat de database herstelt van archiefbestanden, en op een bepaald moment zal het een regel tonen met de tekst "herstel stoppen voordat transactie wordt vastgelegd ..."
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07Op dit moment heeft het herstelproces alle WAL-bestanden opgenomen, maar het moet ook worden beoordeeld voordat het als master online komt. In dit voorbeeld merkt het logboek op dat de volgende transactie na de hersteldoeltijd van 11:59:00 11:59:01 was en niet werd hersteld. Om te verifiëren, logt u in op de database en kijkt u eens, de actieve database zou een momentopname moeten zijn vanaf 11:59 precies.
Als alles er goed uitziet, tijd om het herstel als een meester te promoten.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Nu is de database online, hersteld tot het punt dat we hadden besloten en accepteert lees-/schrijfverbindingen als een hoofdknooppunt. Zorg ervoor dat alle configuratieparameters correct zijn en klaar voor productie.
De database is online, maar het herstelproces is nog niet klaar! Nu deze PITR-back-up online is als de master, moet een nieuwe standby- en PITR-configuratie worden ingesteld, tot die tijd kan deze nieuwe master online zijn en applicaties bedienen, maar het is niet veilig voor een nieuwe ramp totdat dat allemaal weer is ingesteld.
Andere herstelscenario's op een bepaald moment
Het terugbrengen van een PITR-back-up voor een hele database is een extreem geval, maar er zijn andere scenario's waarin slechts een subset van gegevens ontbreekt, beschadigd is of slecht is. In deze gevallen kunnen we creatief zijn met onze herstelopties. Zonder de master offline te halen en te vervangen door een back-up, kunnen we een PITR-back-up online zetten op het exacte tijdstip dat we willen op een andere host (of een andere poort als ruimte geen probleem is), en de herstelde gegevens direct van de back-up exporteren in de hoofddatabase. Dit kan worden gebruikt om een handvol rijen, een handvol tabellen of elke gewenste configuratie van gegevens te herstellen.
Met streamingreplicatie en Point In Time Recovery geeft PostgreSQL ons een grote flexibiliteit om ervoor te zorgen dat we alle gegevens die we nodig hebben kunnen herstellen, zolang we standby-hosts hebben die als master kunnen worden gebruikt, of back-ups die klaar zijn om te herstellen. Een goede Disaster Recovery-optie kan verder worden uitgebreid met andere back-upopties, meer replicanodes, meerdere back-upsites over verschillende datacenters en continenten, periodieke pg_dumps op een andere replica, enz.
Deze opties kunnen oplopen, maar de echte vraag is 'hoe waardevol zijn de gegevens en hoeveel bent u bereid te besteden om deze terug te krijgen?'. In veel gevallen is het verlies van gegevens het einde van een bedrijf, dus er moeten goede noodherstelopties zijn om te voorkomen dat het ergste gebeurt.