Wanneer u een analysesysteem voor een bedrijf moet implementeren, is er vaak de vraag waar de gegevens moeten worden opgeslagen. Er is niet altijd een perfecte optie voor alle vereisten en het hangt af van het budget, de hoeveelheid gegevens en de behoeften van het bedrijf.
PostgreSQL, als de meest geavanceerde open source-database, is zo flexibel dat het kan dienen als een eenvoudige relationele database, een tijdreeksgegevensdatabase en zelfs als een efficiënte, goedkope oplossing voor gegevensopslag. Je kunt het ook integreren met verschillende analysetools.
Als u op zoek bent naar een breed compatibel, goedkoop en performant datawarehouse, zou PostgreSQL de beste databaseoptie kunnen zijn, maar waarom? In deze blog zullen we zien wat een datawarehouse is, waarom het nodig is en waarom PostgreSQL hier de beste optie zou kunnen zijn.
Wat is een datawarehouse
Een datawarehouse is een gestandaardiseerd, consistent en geïntegreerd systeem dat actuele of historische gegevens uit een of meer bronnen bevat die worden gebruikt voor rapportage en gegevensanalyse. Het wordt beschouwd als een kerncomponent van business intelligence, de strategie en technologie die een bedrijf gebruikt om de commerciële context beter te begrijpen.
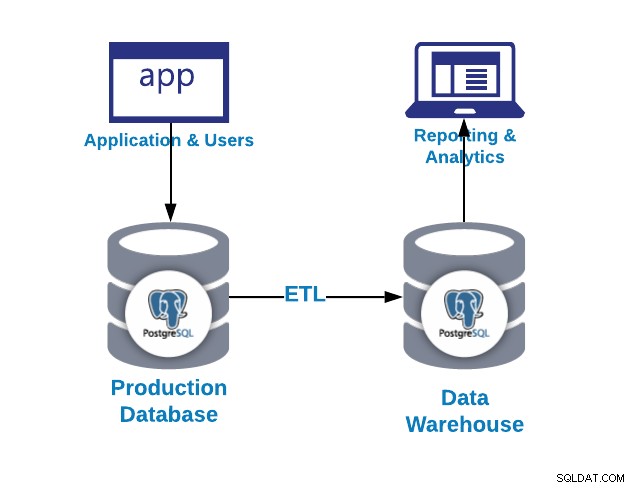
De eerste vraag die u zich wellicht stelt, is waarom ik een datawarehouse nodig heb?
- Integratie:integreer/centraliseer gegevens uit meerdere systemen/databases
- Standaardiseren:standaardiseer alle gegevens in hetzelfde formaat
- Analytics:analyseer gegevens in een historische context
Enkele voordelen van een datawarehouse kunnen zijn...
- Integreer gegevens uit meerdere bronnen in één database
- Vermijd productieblokkering of -lading vanwege langlopende zoekopdrachten
- Historische informatie opslaan
- Herstructureer de gegevens om aan de analysevereisten te voldoen
Zoals we in de vorige afbeelding konden zien, kunnen we PostgreSQL gebruiken voor zowel OLAP- als OLTP-voorstellen. Laten we eens kijken wat het verschil is.
- OLTP:online transactieverwerking. Over het algemeen heeft het een groot aantal korte online transacties (INSERT, UPDATE, DELETE) gegenereerd door gebruikersactiviteit. Deze systemen leggen de nadruk op een zeer snelle verwerking van query's en het handhaven van de gegevensintegriteit in omgevingen met meerdere toegangen. Hier wordt effectiviteit gemeten aan het aantal transacties per seconde. OLTP-databases bevatten gedetailleerde en actuele gegevens.
- OLAP:online analytische verwerking. Over het algemeen heeft het een laag volume aan complexe transacties die worden gegenereerd door grote rapporten. De responstijd is een effectiviteitsmaatstaf. Deze databases slaan geaggregeerde, historische gegevens op in multidimensionale schema's. OLAP-databases worden gebruikt om multidimensionale gegevens vanuit meerdere bronnen en perspectieven te analyseren.
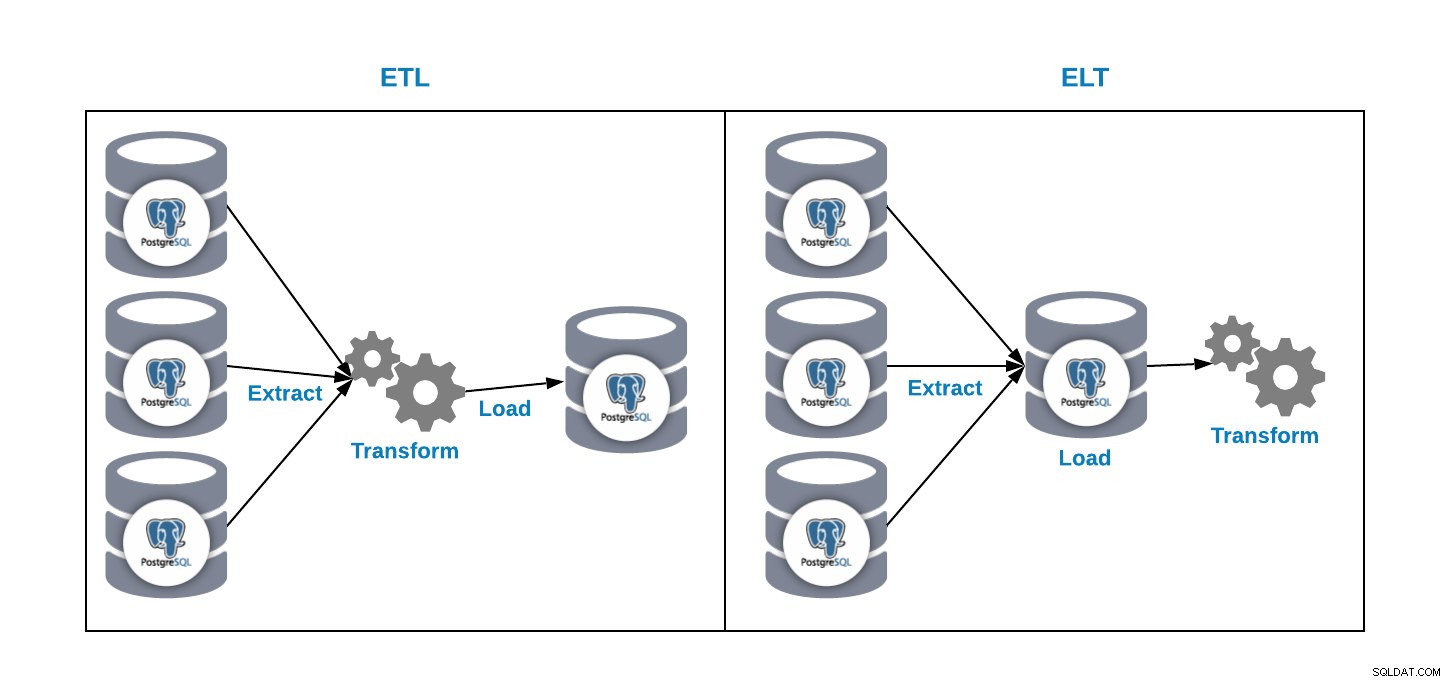
We hebben twee manieren om gegevens in onze analysedatabase te laden:
- ETL:extraheren, transformeren en laden. Dit is de manier om ons datawarehouse te genereren. Haal eerst de gegevens uit de productiedatabase, transformeer de gegevens volgens onze vereisten en laad de gegevens vervolgens in ons datawarehouse.
- ELT:extraheren, laden en transformeren. Haal eerst de gegevens uit de productiedatabase, laad deze in de database en transformeer de gegevens. Deze manier wordt Data Lake genoemd en het is een nieuw concept om onze big data te beheren.
En nu de tweede vraag:waarom zou ik PostgreSQL gebruiken voor mijn datawarehouse?
Voordelen van PostgreSQL als datawarehouse
Laten we eens kijken naar enkele voordelen van het gebruik van PostgreSQL als datawarehouse...
- Kosten:als u een on-premises omgeving gebruikt, zijn de kosten voor het product zelf $ 0, zelfs als u een product in de cloud gebruikt, zijn de kosten van een op PostgreSQL gebaseerd product waarschijnlijk minder dan de rest van de producten.
- Schaal:u kunt het lezen op een eenvoudige manier schalen door zoveel replicaknooppunten toe te voegen als u wilt.
- Prestaties:met een juiste configuratie levert PostgreSQL echt goede prestaties op verschillende escenario's.
- Compatibiliteit:u kunt PostgreSQL integreren met externe tools of toepassingen voor datamining, OLAP en rapportage.
- Uitbreidbaarheid:PostgreSQL heeft door de gebruiker gedefinieerde gegevenstypen en functies.
Er zijn ook enkele PostgreSQL-functies die ons kunnen helpen bij het beheren van onze datawarehouse-informatie...
- Tijdelijke tabellen:het is een tabel van korte duur die bestaat voor de duur van een databasesessie. PostgreSQL laat de tijdelijke tafels automatisch vallen aan het einde van een sessie of een transactie.
- Opgeslagen procedures:u kunt het gebruiken om procedures of functies in meerdere talen te maken (PL/pgSQL, PL/Perl, PL/Python, enz.).
- Partitionering:dit is erg handig voor database-onderhoud, query's met partitiesleutel en INSERT-prestaties.
- Gematerialiseerde weergave:de zoekopdrachtresultaten worden weergegeven als een tabel.
- Tabelruimten:u kunt de gegevenslocatie naar een andere schijf wijzigen. Op deze manier heb je parallelle schijftoegang.
- PITR-compatibel:u kunt back-ups maken die compatibel zijn met point-in-time-recovery, dus in geval van een storing kunt u de databasestatus binnen een bepaalde periode herstellen.
- Enorme community:en last but not least, PostgreSQL heeft een enorme community waar je ondersteuning kunt vinden bij veel verschillende problemen.
PostgreSQL configureren voor gebruik van datawarehouse
Er is geen beste configuratie om in alle gevallen en in alle databasetechnologieën te gebruiken. Het hangt van veel factoren af, zoals hardware, gebruik en systeemvereisten. Hieronder vindt u enkele tips om uw PostgreSQL-database op de juiste manier te configureren om als datawarehouse te werken.
Gebaseerd op geheugen
- max_connections:als datawarehouse-database heeft u niet veel verbindingen nodig omdat dit wordt gebruikt voor rapportage- en analysewerk, dus u kunt het maximale aantal verbindingen beperken met deze parameter.
- shared_buffers:Stelt de hoeveelheid geheugen in die de databaseserver gebruikt voor gedeelde geheugenbuffers. Een redelijke waarde kan 15% tot 25% van het RAM-geheugen zijn.
- Effective_cache_size:deze waarde wordt gebruikt door de queryplanner om rekening te houden met plannen die al dan niet in het geheugen passen. Bij de kostenramingen van het gebruik van een index wordt hiermee rekening gehouden; een hoge waarde maakt het waarschijnlijker dat indexscans worden gebruikt en een lage waarde maakt het waarschijnlijker dat sequentiële scans worden gebruikt. Een redelijke waarde zou ongeveer 75% van het RAM-geheugen zijn.
- werkgeheugen:specificeert de hoeveelheid geheugen die zal worden gebruikt door de interne bewerkingen van ORDER BY, DISTINCT, JOIN en hashtabellen voordat naar de tijdelijke bestanden op schijf wordt geschreven. Bij het configureren van deze waarde moeten we er rekening mee houden dat verschillende sessies deze bewerkingen tegelijkertijd uitvoeren en dat elke bewerking zoveel geheugen mag gebruiken als gespecificeerd door deze waarde voordat het begint met het schrijven van gegevens in tijdelijke bestanden. Een redelijke waarde kan ongeveer 2% van het RAM-geheugen zijn.
- maintenance_work_mem:specificeert de maximale hoeveelheid geheugen die onderhoudsbewerkingen zullen gebruiken, zoals VACUUM, CREATE INDEX en ALTER TABLE ADD FOREIGN KEY. Een redelijke waarde kan ongeveer 15% van het RAM-geheugen zijn.
CPU-gebaseerd
- Max_worker_processes:Stelt het maximum aantal achtergrondprocessen in dat het systeem kan ondersteunen. Een redelijke waarde kan het aantal CPU's zijn.
- Max_parallel_workers_per_gather:Stelt het maximum aantal werkers in dat kan worden gestart door een enkele Gather- of Gather Merge-node. Een redelijke waarde kan 50% van het aantal CPU's zijn.
- Max_parallel_workers:Stelt het maximum aantal werkers in dat het systeem kan ondersteunen voor parallelle query's. Een redelijke waarde kan het aantal CPU's zijn.
Omdat de gegevens die in ons datawarehouse worden geladen niet zouden moeten veranderen, kunnen we de Autovacuum ook uitschakelen om een extra belasting van uw PostgreSQL-database te voorkomen. De vacuüm- en analyseprocessen kunnen deel uitmaken van het batchlaadproces.
Conclusie
Als u op zoek bent naar breed compatibele, goedkope en krachtige datawarehouses, moet u PostgreSQL zeker overwegen als een optie voor uw datawarehouse-database. PostgreSQL heeft veel voordelen en functies die handig zijn om ons datawarehouse te beheren, zoals partitionering of opgeslagen procedures en zelfs meer.