Tegenwoordig is het gebruikelijk om een grote hoeveelheid gegevens in de database van een bedrijf te zien, maar afhankelijk van de grootte kan het moeilijk te beheren zijn en kunnen de prestaties worden beïnvloed tijdens veel verkeer als we deze niet op de juiste manier configureren of implementeren . In het algemeen, als we een enorme database hebben en we willen een lage responstijd hebben, zullen we deze willen schalen. PostgreSQL is op dit punt geen uitzondering. Er zijn veel benaderingen beschikbaar om PostgreSQL te schalen, maar laten we eerst eens kijken wat schalen is.
Schaalbaarheid is de eigenschap van een systeem/database om een groeiend aantal eisen aan te kunnen door resources toe te voegen.
De redenen voor dit aantal eisen kunnen tijdelijk zijn, bijvoorbeeld als we een korting lanceren op een uitverkoop, of permanent, voor een toename van klanten of medewerkers. In ieder geval zouden we middelen moeten kunnen toevoegen of verwijderen om deze wijzigingen te beheren op basis van de vraag of de toename van het verkeer.
In deze blog bekijken we hoe we onze PostgreSQL-database kunnen schalen en wanneer dat nodig is.
Horizontaal schalen versus verticaal schalen
Er zijn twee manieren om onze database te schalen...
- Horizontaal schalen (uitschalen):het wordt uitgevoerd door meer databaseknooppunten toe te voegen die een databasecluster maken of vergroten.
- Verticaal schalen (opschalen):het wordt uitgevoerd door meer hardwarebronnen (CPU, geheugen, schijf) toe te voegen aan een bestaand databaseknooppunt.
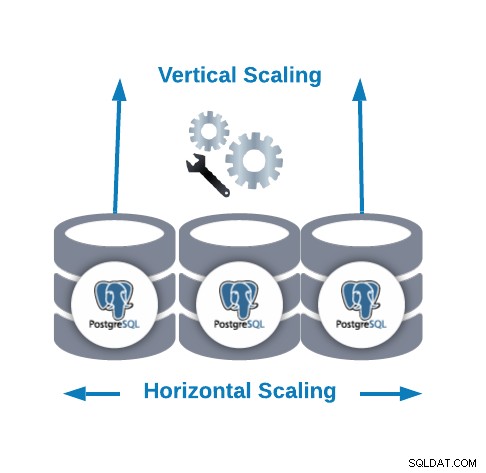
Voor Horizontal Scaling kunnen we meer databaseknooppunten als slave-knooppunten toevoegen. Het kan ons helpen de leesprestaties te verbeteren door het verkeer tussen de knooppunten in evenwicht te brengen. In dit geval moeten we een load balancer toevoegen om het verkeer naar het juiste knooppunt te distribueren, afhankelijk van het beleid en de knooppuntstatus.
Om een enkel storingspunt te vermijden door slechts één load balancer toe te voegen, moeten we overwegen om twee of meer load balancer-knooppunten toe te voegen en een tool zoals "Keepalived" te gebruiken om de beschikbaarheid te garanderen.
Aangezien PostgreSQL geen native ondersteuning voor meerdere masters heeft, moeten we voor deze taak een externe tool gebruiken als we het willen implementeren om de schrijfprestaties te verbeteren.
Voor Vertical Scaling kan het nodig zijn om een configuratieparameter te wijzigen zodat PostgreSQL een nieuwe of betere hardwarebron kan gebruiken. Laten we enkele van deze parameters bekijken in de PostgreSQL-documentatie.
- work_mem:specificeert de hoeveelheid geheugen die moet worden gebruikt door interne sorteerbewerkingen en hashtabellen voordat naar tijdelijke schijfbestanden wordt geschreven. Meerdere actieve sessies kunnen dergelijke bewerkingen tegelijkertijd uitvoeren, dus het totale gebruikte geheugen kan vele malen groter zijn dan de waarde van work_mem.
- maintenance_work_mem:specificeert de maximale hoeveelheid geheugen die moet worden gebruikt door onderhoudsbewerkingen, zoals VACUUM, CREATE INDEX en ALTER TABLE ADD FOREIGN KEY. Grotere instellingen kunnen de prestaties verbeteren voor het opzuigen en voor het herstellen van databasedumps.
- autovacuum_work_mem:specificeert de maximale hoeveelheid geheugen die door elk autovacuum-werkproces moet worden gebruikt.
- autovacuum_max_workers:specificeert het maximum aantal autovacuumprocessen dat tegelijkertijd kan worden uitgevoerd.
- max_worker_processes:Stelt het maximum aantal achtergrondprocessen in dat het systeem kan ondersteunen. Specificeer de limiet van het proces, zoals stofzuigen, controlepunten en meer onderhoudstaken.
- max_parallel_workers:Stelt het maximum aantal werkers in dat het systeem kan ondersteunen voor parallelle bewerkingen. Parallelle werkers worden gehaald uit de pool van werkprocessen die zijn ingesteld door de vorige parameter.
- max_parallel_maintenance_workers:Stelt het maximum aantal parallelle worker's in dat kan worden gestart door een enkel hulpprogramma-commando. Momenteel is CREATE INDEX de enige parallelle hulpprogramma-opdracht die het gebruik van parallelle worker ondersteunt, en alleen bij het bouwen van een B-tree-index.
- Effective_cache_size:Stelt de aanname van de planner in over de effectieve grootte van de schijfcache die beschikbaar is voor een enkele query. Hiermee wordt rekening gehouden bij schattingen van de kosten van het gebruik van een index; een hogere waarde maakt het waarschijnlijker dat indexscans worden gebruikt, een lagere waarde maakt het waarschijnlijker dat opeenvolgende scans worden gebruikt.
- shared_buffers:Stelt de hoeveelheid geheugen in die de databaseserver gebruikt voor gedeelde geheugenbuffers. Instellingen die aanzienlijk hoger zijn dan het minimum zijn meestal nodig voor goede prestaties.
- temp_buffers:Stelt het maximum aantal tijdelijke buffers in dat door elke databasesessie wordt gebruikt. Dit zijn sessie-lokale buffers die alleen worden gebruikt voor toegang tot tijdelijke tabellen.
- Effective_io_concurrency:Stelt het aantal gelijktijdige schijf-I/O-bewerkingen in waarvan PostgreSQL verwacht dat ze tegelijkertijd kunnen worden uitgevoerd. Als u deze waarde verhoogt, neemt het aantal I/O-bewerkingen toe dat elke afzonderlijke PostgreSQL-sessie parallel probeert te starten. Momenteel is deze instelling alleen van invloed op bitmap-heapscans.
- max_connections:bepaalt het maximum aantal gelijktijdige verbindingen met de databaseserver. Door deze parameter te verhogen, kan PostgreSQL meer backend-processen tegelijkertijd uitvoeren.
Op dit punt is er een vraag die we moeten stellen. Hoe weten we of we onze database moeten schalen en hoe weten we hoe we dit het beste kunnen doen?
Bewaking
Het schalen van onze PostgreSQL-database is een complex proces, dus we moeten enkele statistieken controleren om de beste strategie te kunnen bepalen om het te schalen.
We kunnen het CPU-, geheugen- en schijfgebruik controleren om te bepalen of er een configuratieprobleem is of dat we onze database eigenlijk moeten schalen. Als we bijvoorbeeld een hoge serverbelasting zien, maar de database-activiteit is laag, is het waarschijnlijk niet nodig om deze te schalen, we hoeven alleen de configuratieparameters te controleren om deze overeen te laten komen met onze hardwarebronnen.
Het controleren van de schijfruimte die door het PostgreSQL-knooppunt per database wordt gebruikt, kan ons helpen te bevestigen of we meer schijf of zelfs een tabelpartitionering nodig hebben. Om de schijfruimte te controleren die door een database/tabel wordt gebruikt, kunnen we een PostgreSQL-functie gebruiken, zoals pg_database_size of pg_table_size.
Aan de databasekant moeten we controleren
- Aantal verbinding
- Zoekopdrachten uitvoeren
- Indexgebruik
- Bloat
- Replicatievertraging
Dit kunnen duidelijke statistieken zijn om te bevestigen of het schalen van onze database nodig is.
ClusterControl als schaal- en controlesysteem
ClusterControl kan ons helpen om te gaan met beide schaalmethoden die we eerder zagen en om alle benodigde meetwaarden te bewaken om de schaalvereiste te bevestigen. Laten we eens kijken hoe...
Als u ClusterControl nog niet gebruikt, kunt u het installeren en uw huidige PostgreSQL-database implementeren of importeren door de optie "Importeren" te selecteren en de stappen te volgen om te profiteren van alle ClusterControl-functies zoals back-ups, automatische failover, waarschuwingen, monitoring, en meer.
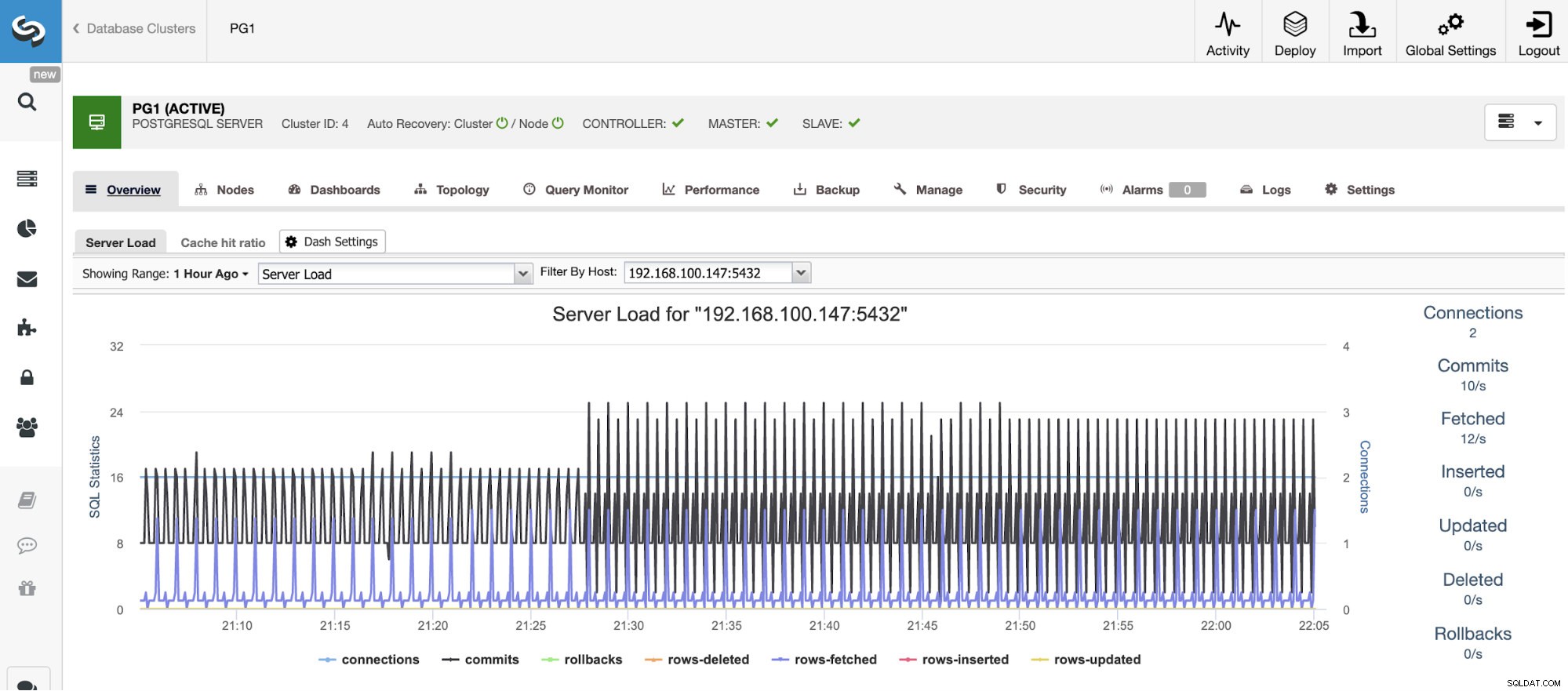
Horizontaal schalen
Als we voor horizontale schaling naar clusteracties gaan en "Replicatieslave toevoegen" selecteren, kunnen we een nieuwe replica maken of een bestaande PostgreSQL-database als replica toevoegen.
Laten we eens kijken hoe het toevoegen van een nieuwe replicatieslave een heel gemakkelijke taak kan zijn.
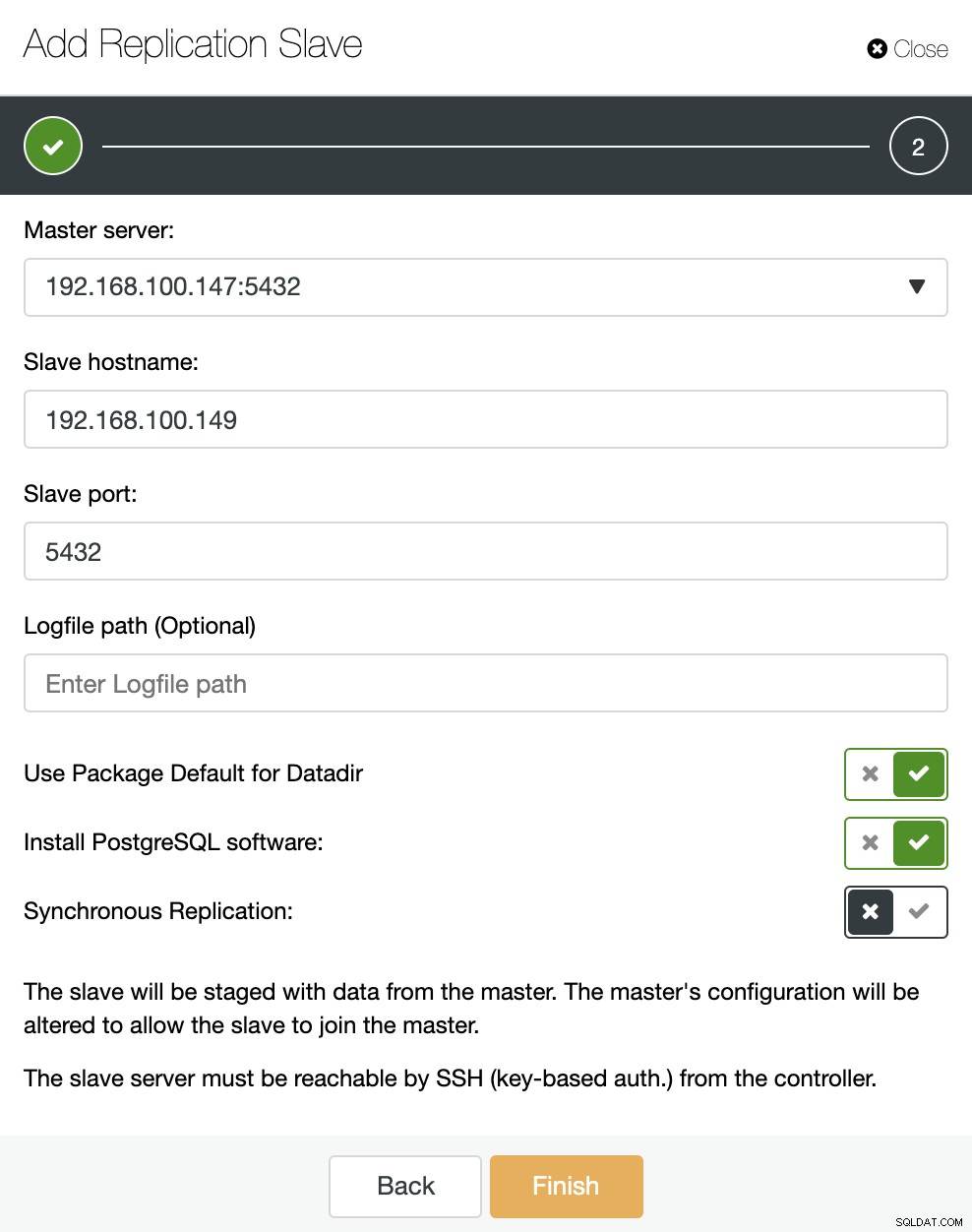
Zoals je in de afbeelding kunt zien, hoeven we alleen onze Master-server te kiezen, het IP-adres voor onze nieuwe slave-server en de databasepoort in te voeren. Vervolgens kunnen we kiezen of we willen dat ClusterControl de software voor ons installeert en of de replicatieslave Synchroon of Asynchroon moet zijn.
Op deze manier kunnen we zoveel replica's toevoegen als we willen en het leesverkeer ertussen spreiden met behulp van een load balancer, die we ook kunnen implementeren met ClusterControl.
Als we nu naar clusteracties gaan en "Load Balancer toevoegen" selecteren, kunnen we een nieuwe HAProxy Load Balancer implementeren of een bestaande toevoegen.
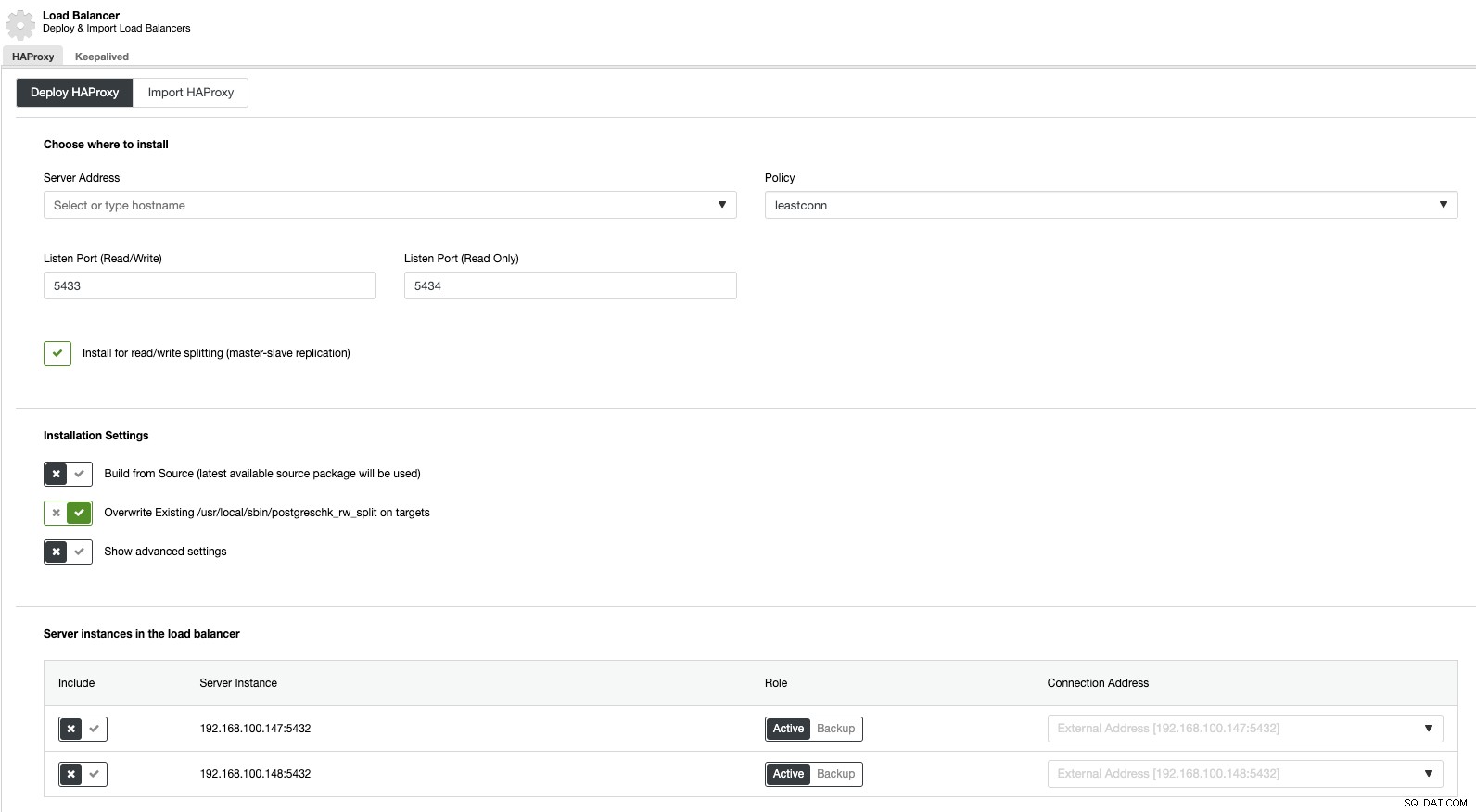
En dan kunnen we in dezelfde sectie over load balancer een Keepalive-service toevoegen die draait op de load balancer-knooppunten om onze omgeving met hoge beschikbaarheid te verbeteren.
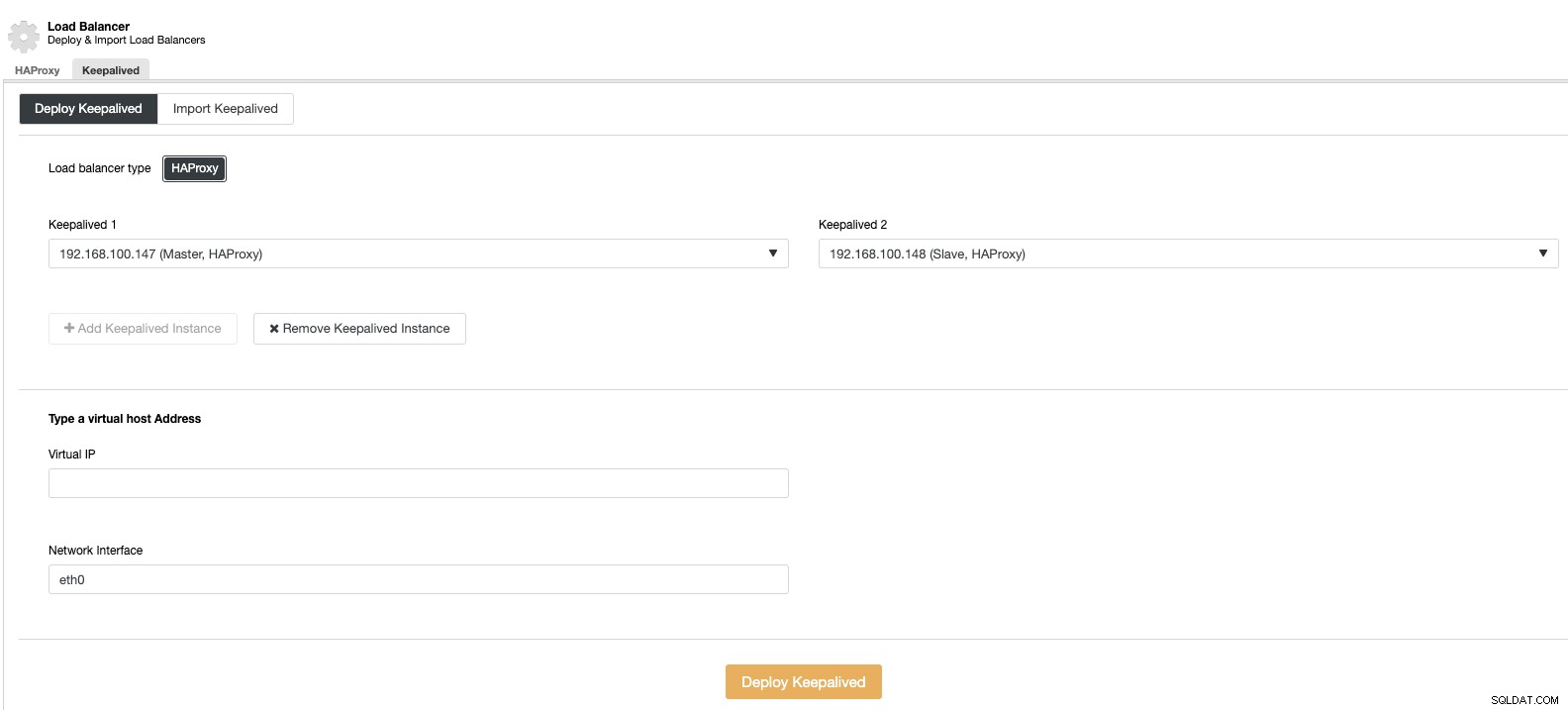
Verticale schaal
Voor verticale schaling kunnen we met ClusterControl onze databaseknooppunten monitoren vanaf zowel het besturingssysteem als de database. We kunnen enkele statistieken controleren, zoals CPU-gebruik, geheugen, verbindingen, topquery's, lopende query's en zelfs meer. We kunnen ook het gedeelte Dashboard inschakelen, waardoor we de statistieken gedetailleerder en op een vriendelijkere manier kunnen bekijken.
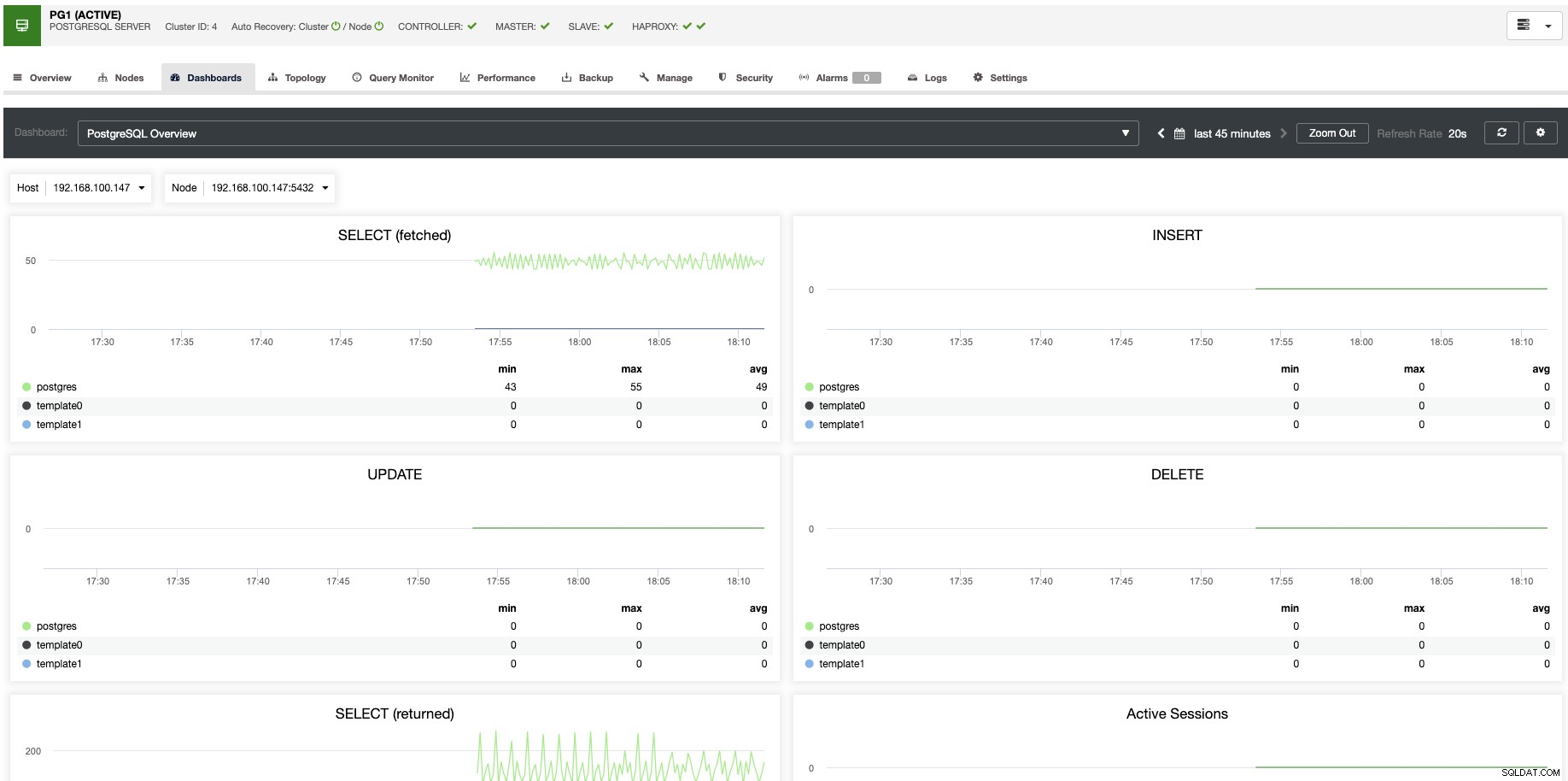
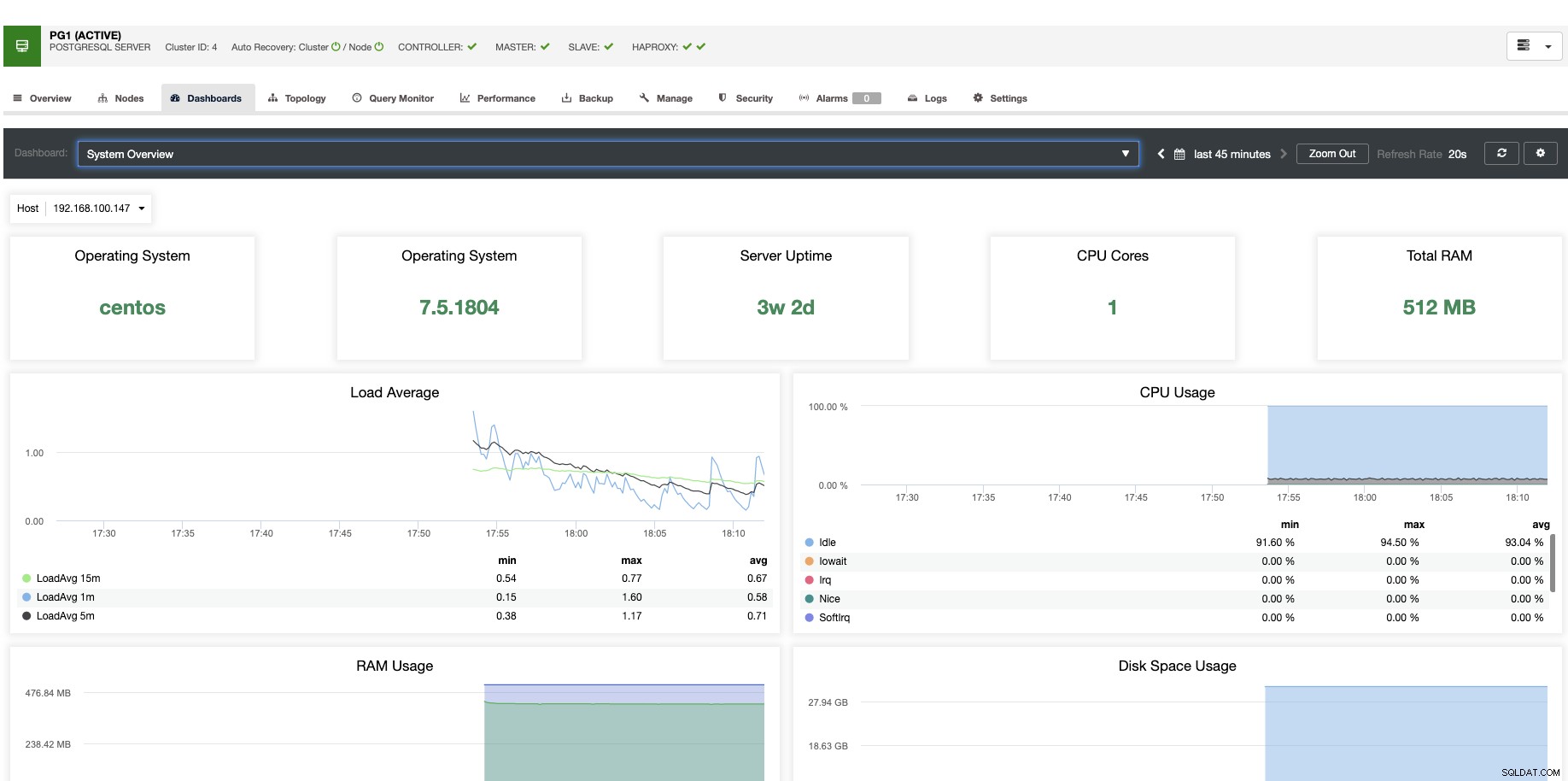
Vanuit ClusterControl kunt u met één klik ook verschillende beheertaken uitvoeren, zoals Reboot Host, Rebuild Replication Slave of Promote Slave.
Conclusie
Het uitschalen van PostgreSQL-databases kan een tijdrovende taak zijn. We moeten weten wat we moeten schalen en hoe we dat het beste kunnen doen. Uiteindelijk wordt het handmatig beheren en schalen van clusters behoorlijk omslachtig voorbij een bepaald punt, dus de meeste wenden zich tot tools zoals de onze.
Als je de handmatige route kiest, bekijk dan wanneer je kunt overwegen een extra node aan je cluster toe te voegen. Wil je het gedoe vermijden? Evalueer ClusterControl gratis gedurende 30 dagen om te zien hoe de functies ervan het omgaan met grootschalige, open source eenvoudig en efficiënt maken.
Hoe u uw databases ook wilt beheren en schalen, volg ons op Twitter of LinkedIn, of abonneer u op onze nieuwsbrief voor het laatste nieuws en best practices bij het beheren van op open source gebaseerde database-infrastructuur, en we zien u snel!