De noodzaak om hoge beschikbaarheid van de database te bereiken is een vrij algemene taak, en vaak een must. Als uw bedrijf een beperkt budget heeft, kan het duur zijn om een replicatieslave (of meer dan één) die op dezelfde cloudprovider draait (afwachten als het ooit nodig is) te onderhouden. Afhankelijk van het type applicatie zijn er enkele gevallen waarin een replicatieslave nodig is om de RTO (Recovery Time Objective) te verbeteren.
Er is echter nog een andere optie als uw bedrijf een korte vertraging kan accepteren om uw systemen weer online te krijgen.
Koude stand-by is een redundantiemethode waarbij u een stand-byknooppunt (als back-up) voor het primaire knooppunt hebt. Dit knooppunt wordt alleen gebruikt tijdens een masterfout. De rest van de tijd wordt het koude standby-knooppunt uitgeschakeld en wordt het alleen gebruikt om een back-up te laden wanneer dat nodig is.
Als u deze methode wilt gebruiken, moet u een vooraf gedefinieerd back-upbeleid (met redundantie) hebben volgens een acceptabele RPO (Recovery Point Objective) voor het bedrijf. Het kan zijn dat het verlies van 12 uur aan gegevens acceptabel is voor het bedrijf of dat het verliezen van slechts één uur een groot probleem kan zijn. Elk bedrijf en elke applicatie moet zijn eigen standaard bepalen.
In deze blog leert u hoe u een back-upbeleid maakt en hoe u dit terugzet naar een koude stand-byserver met behulp van ClusterControl en de integratie met Amazon AWS.
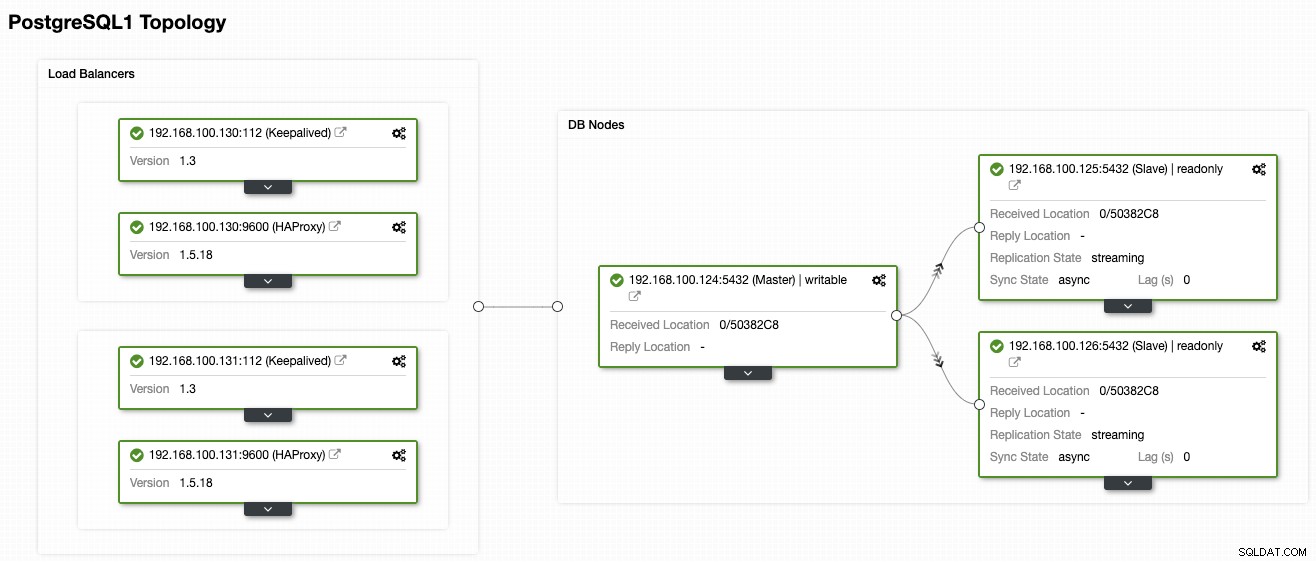
Voor deze blog gaan we ervan uit dat je al een AWS-account hebt en dat ClusterControl is geïnstalleerd. Hoewel we in dit voorbeeld AWS als cloudprovider gaan gebruiken, kunt u een andere gebruiken. We gebruiken de volgende PostgreSQL-topologie die is geïmplementeerd met ClusterControl:
- 1 PostgreSQL primair knooppunt
- 2 PostgreSQL Hot-Standby Nodes
- 2 Load Balancers (HAProxy + Keepalived)
Een acceptabel back-upbeleid maken
De beste werkwijze voor het maken van dit type beleid is om de back-upbestanden op drie verschillende plaatsen op te slaan, één lokaal op de databaseserver (voor sneller herstel), een andere op een gecentraliseerde back-upserver en de laatste in de cloud.
Je kunt dit verbeteren door ook volledige, incrementele en differentiële back-ups te gebruiken. Met ClusterControl kunt u alle bovenstaande best practices uitvoeren, allemaal vanuit hetzelfde systeem, met een gebruiksvriendelijke en gebruiksvriendelijke gebruikersinterface. Laten we beginnen met het maken van de AWS-integratie in ClusterControl.
De ClusterControl AWS-integratie configureren
Ga naar ClusterControl -> Integraties -> Cloudproviders -> Cloudreferenties toevoegen.
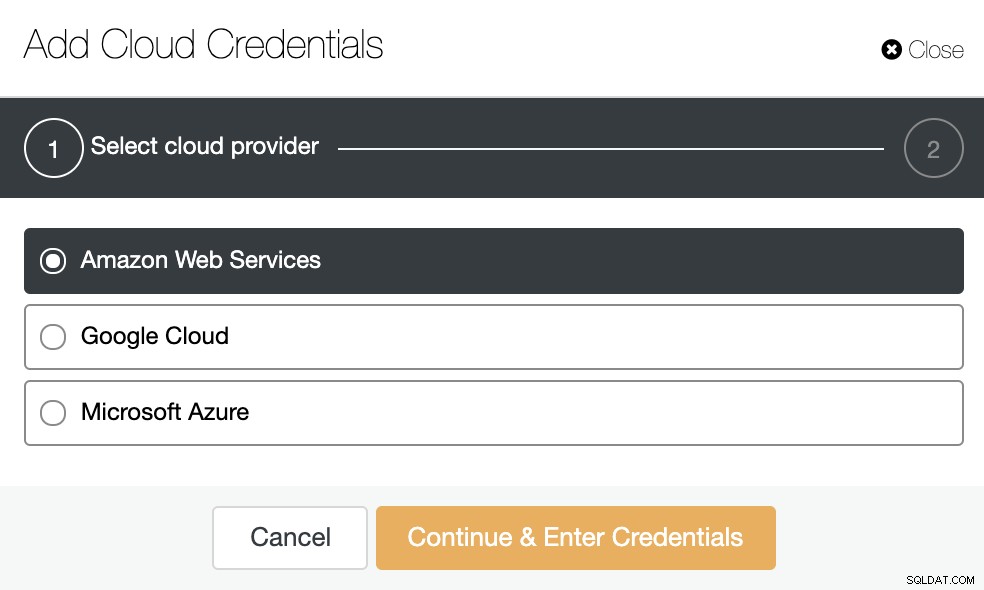
Kies een cloudprovider. Wij ondersteunen AWS, Google Cloud of Azure. Kies in dit geval AWS en ga verder.
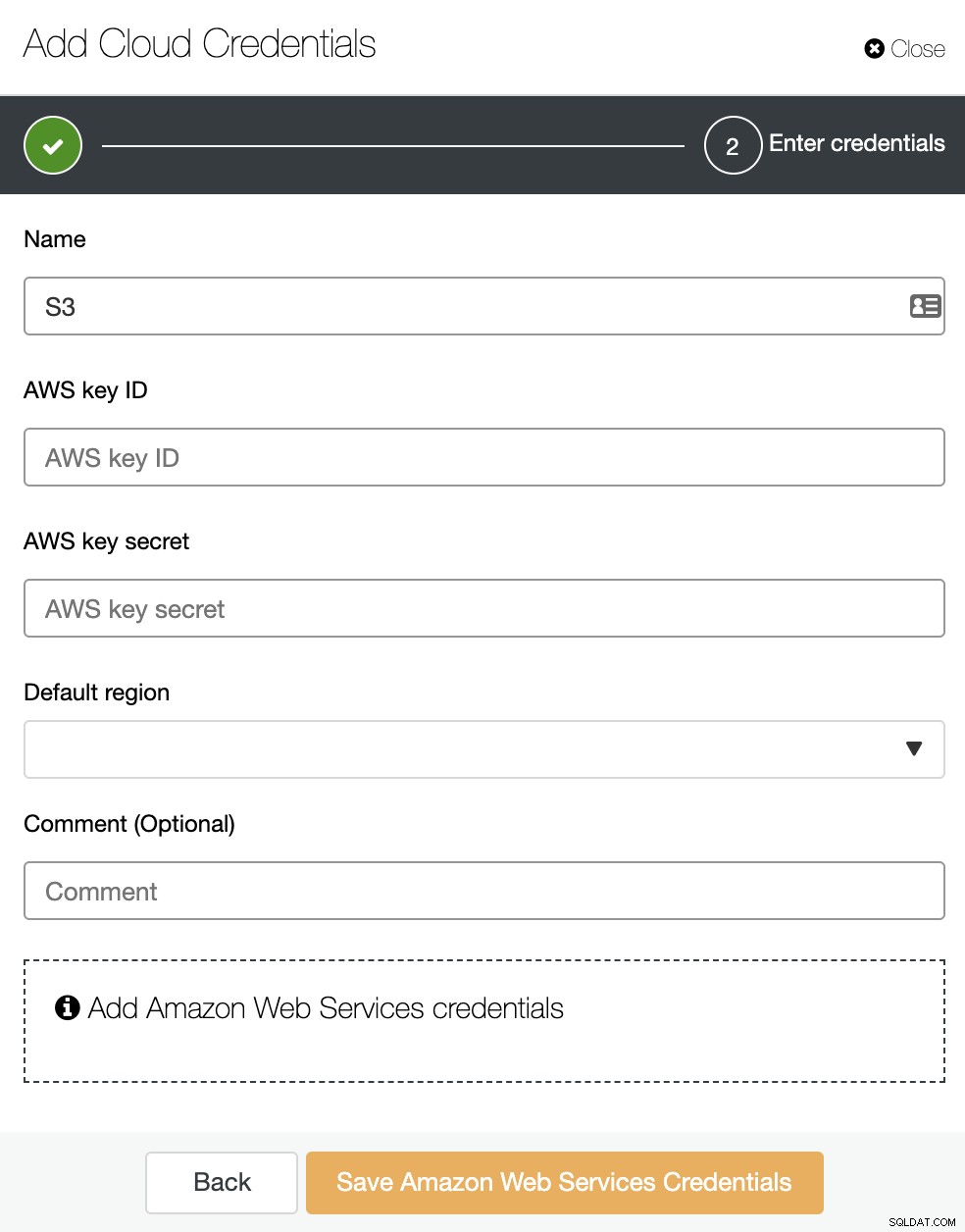
Hier moet u een naam, een standaardregio en een AWS toevoegen sleutel-ID en sleutelgeheim. Om deze laatste te krijgen of te maken, gaat u naar het gedeelte IAM (Identity and Access Management) op de AWS-beheerconsole. Voor meer informatie kunt u onze documentatie of AWS-documentatie raadplegen.
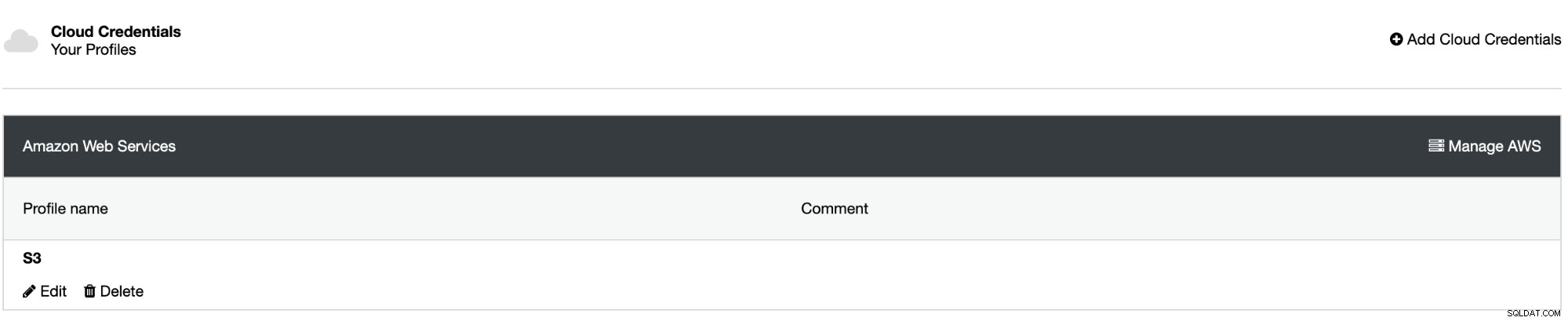
Nu je de integratie hebt gemaakt, gaan we de eerste back-up plannen met ClusterControl.
Een back-up plannen met ClusterControl
Ga naar ClusterControl -> Selecteer het PostgreSQL-cluster -> Back-up -> Back-up maken.
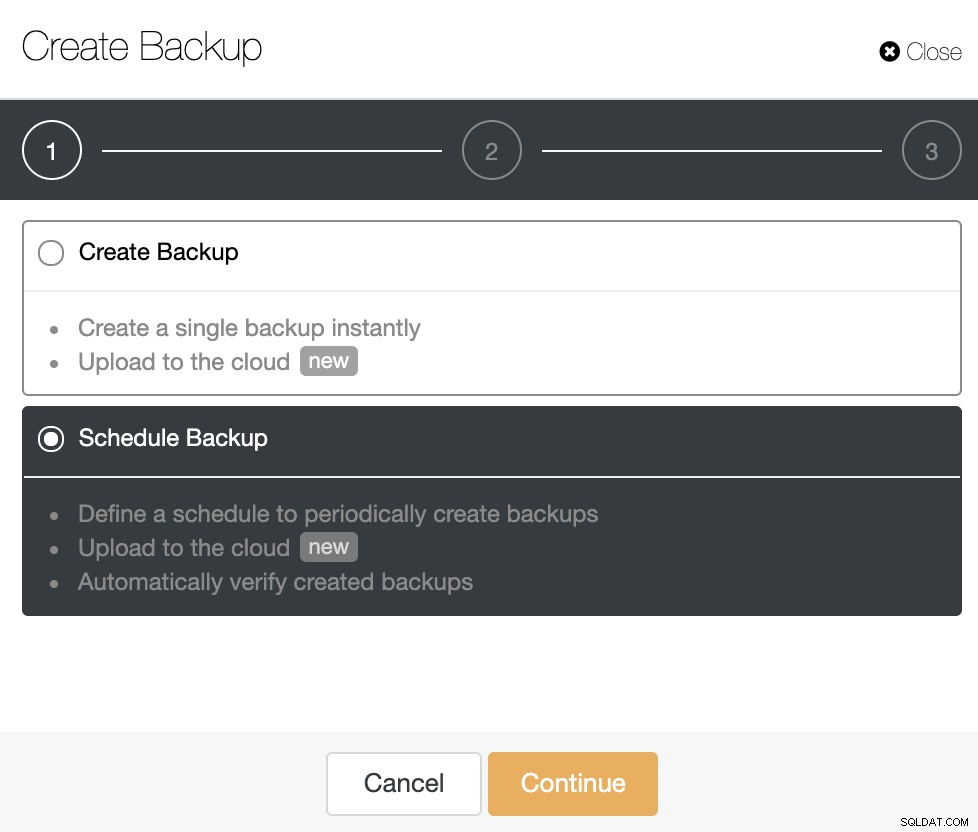
U kunt kiezen of u direct een enkele back-up wilt maken of een nieuwe back-up. Laten we dus de tweede optie kiezen en doorgaan.
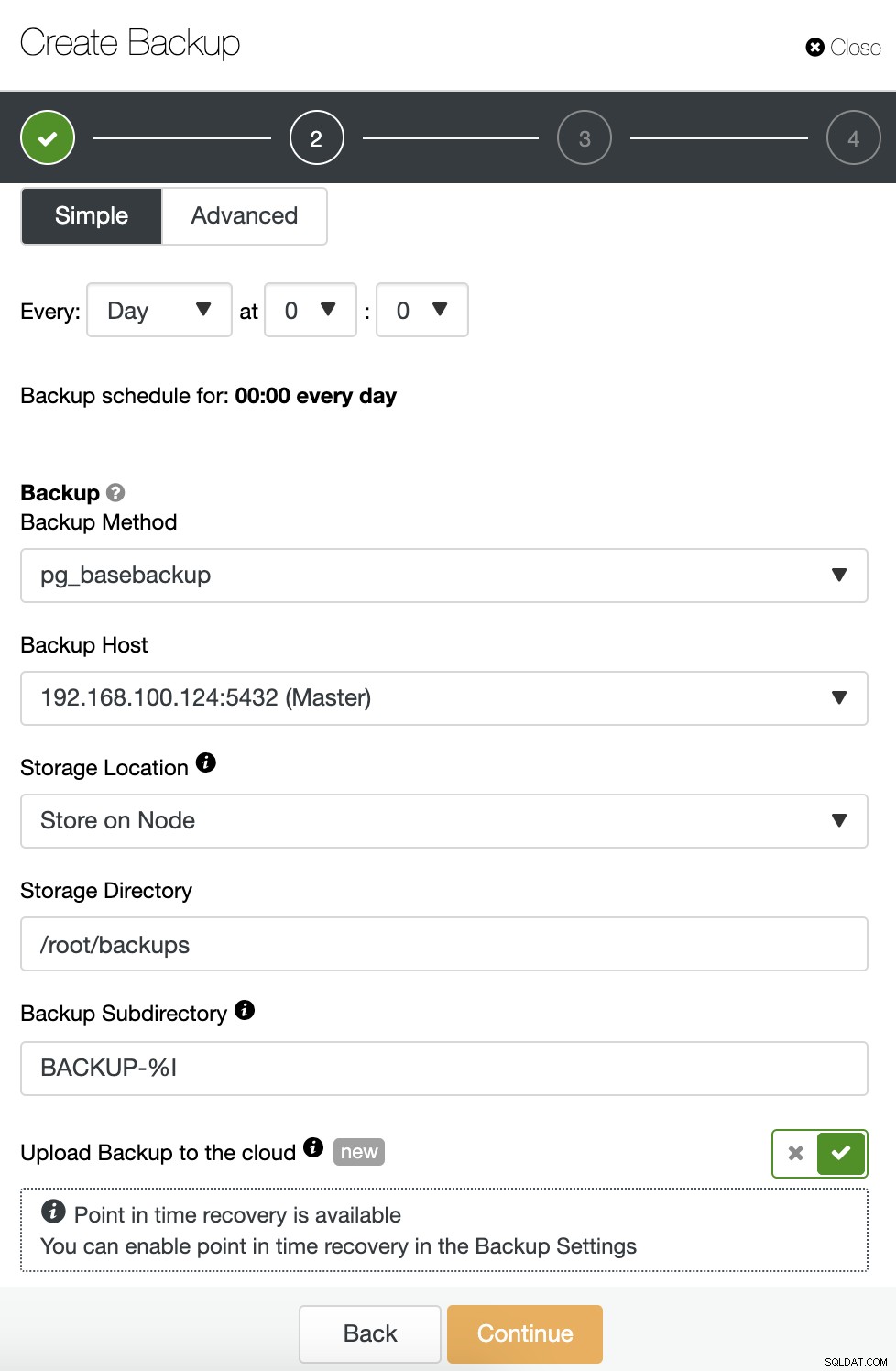
Als u een back-up plant, moet u eerst de planning opgeven /frequentie. Vervolgens moet u een back-upmethode kiezen (pg_dumpall, pg_basebackup, pgBackRest), de server waarvan de back-up wordt genomen en waar u de back-up wilt opslaan. U kunt onze back-up ook uploaden naar de cloud (AWS, Google of Azure) door de bijbehorende knop in te schakelen.
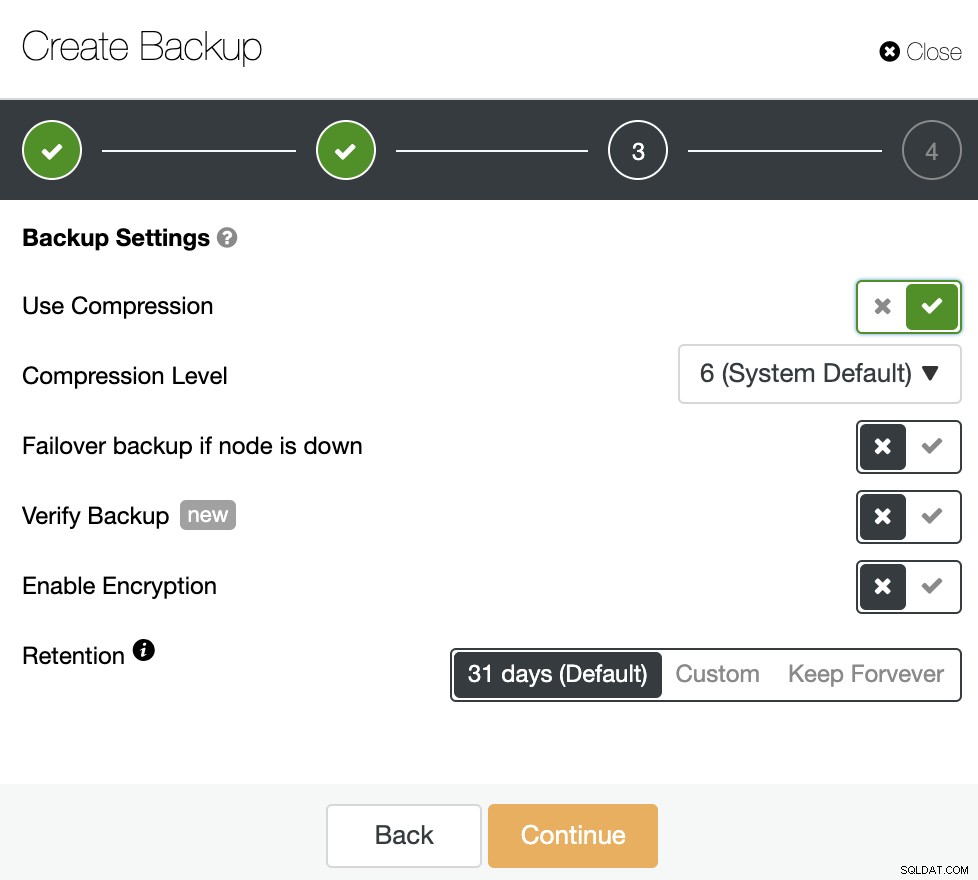
Geef vervolgens het gebruik van compressie, het compressieniveau, de codering en de bewaarperiode op voor uw back-up. Er is nog een functie genaamd "Back-up verifiëren" die u binnenkort in deze blogpost meer in detail zult zien.
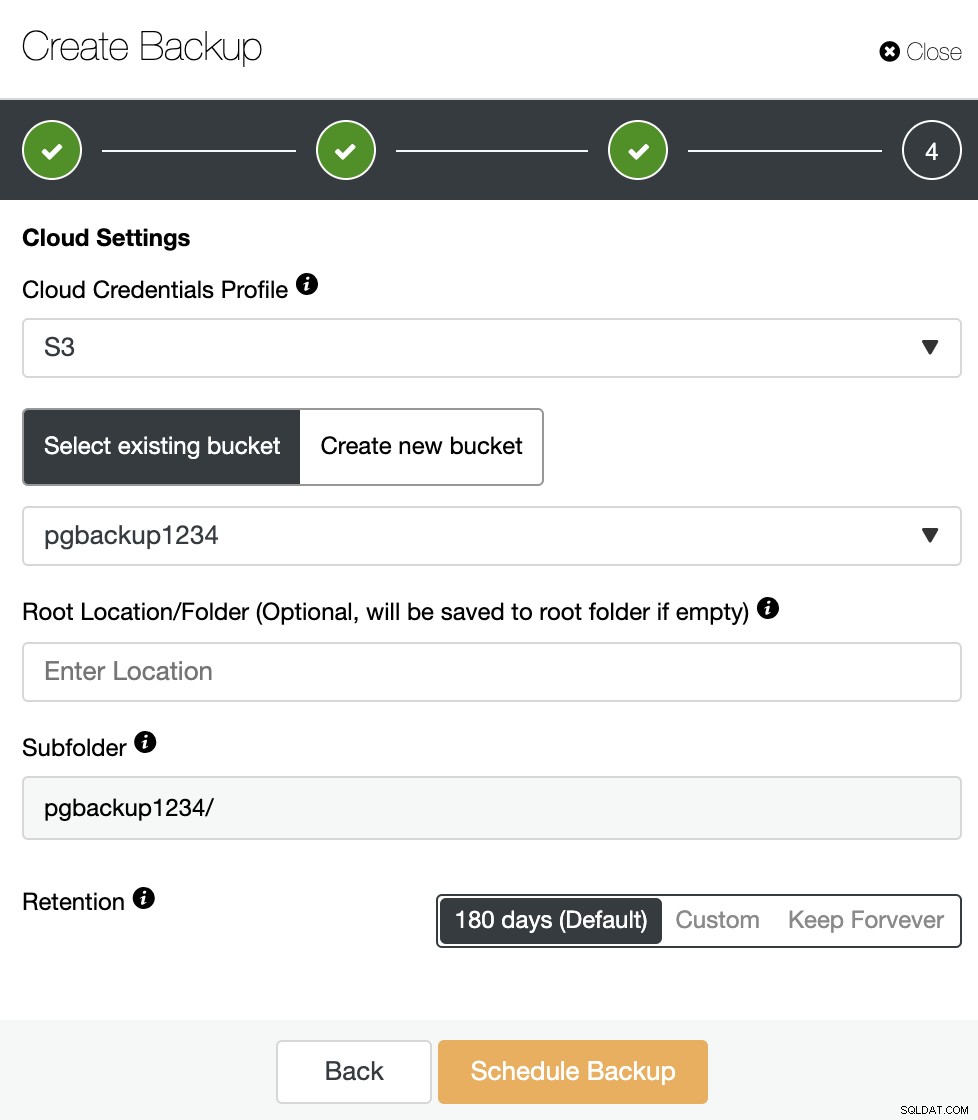
Als de optie "Back-up uploaden naar de cloud" was ingeschakeld, U ziet deze stap waarin u de cloudreferenties moet selecteren en een S3-bucket moet maken of selecteren waar u de back-up wilt opslaan. U moet ook de bewaarperiode specificeren.
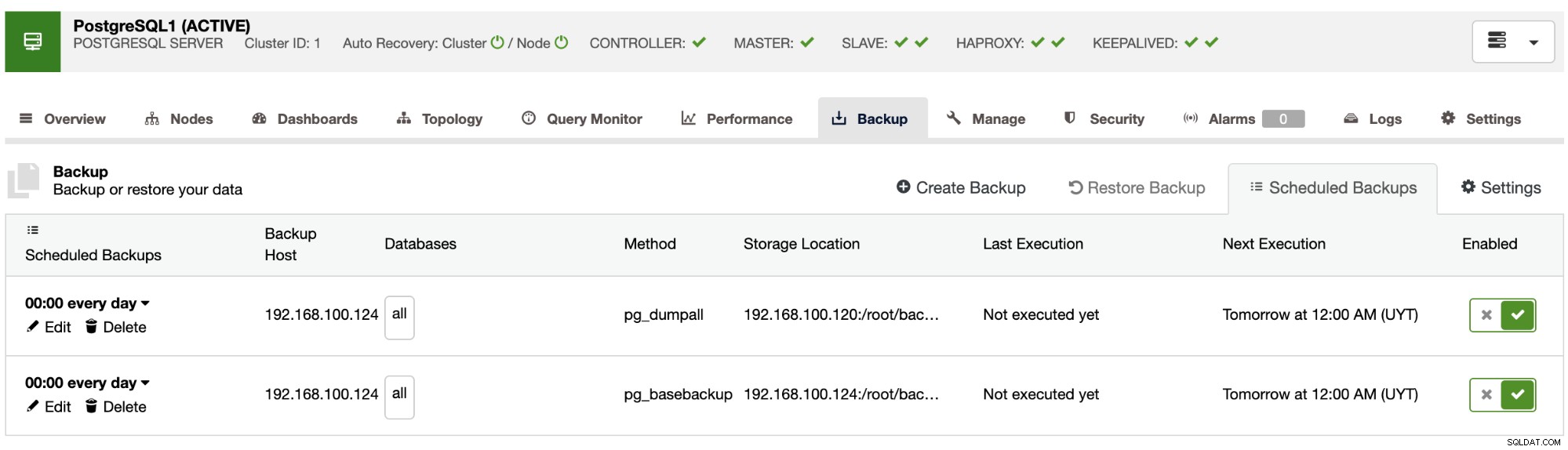
Nu heb je de geplande back-up in het gedeelte ClusterControl Schedule Backups. Om de eerder genoemde best practices te behandelen, kunt u een back-up plannen om deze op te slaan op een externe server (ClusterControl-server) en in de cloud, en vervolgens een andere back-up plannen om deze lokaal op te slaan in het databaseknooppunt voor een sneller herstel.
Een back-up herstellen op Amazon EC2
Zodra de back-up is voltooid, kunt u deze herstellen met ClusterControl in het gedeelte Back-up.
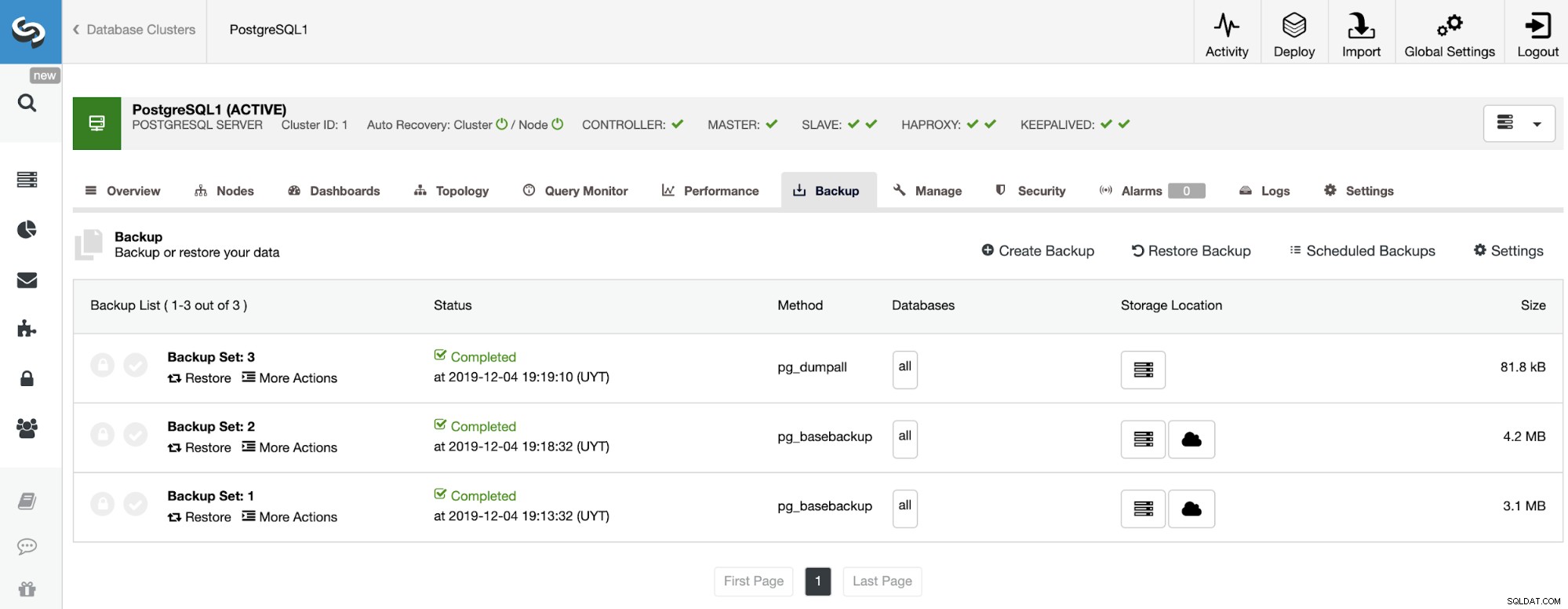
De Amazon EC2-instantie maken
Allereerst, om het te herstellen, heb je een plek nodig om het te doen, dus laten we een standaard Amazon EC2-instantie maken. Ga naar "Instance starten" in de AWS-beheerconsole in de EC2-sectie en configureer uw instantie.
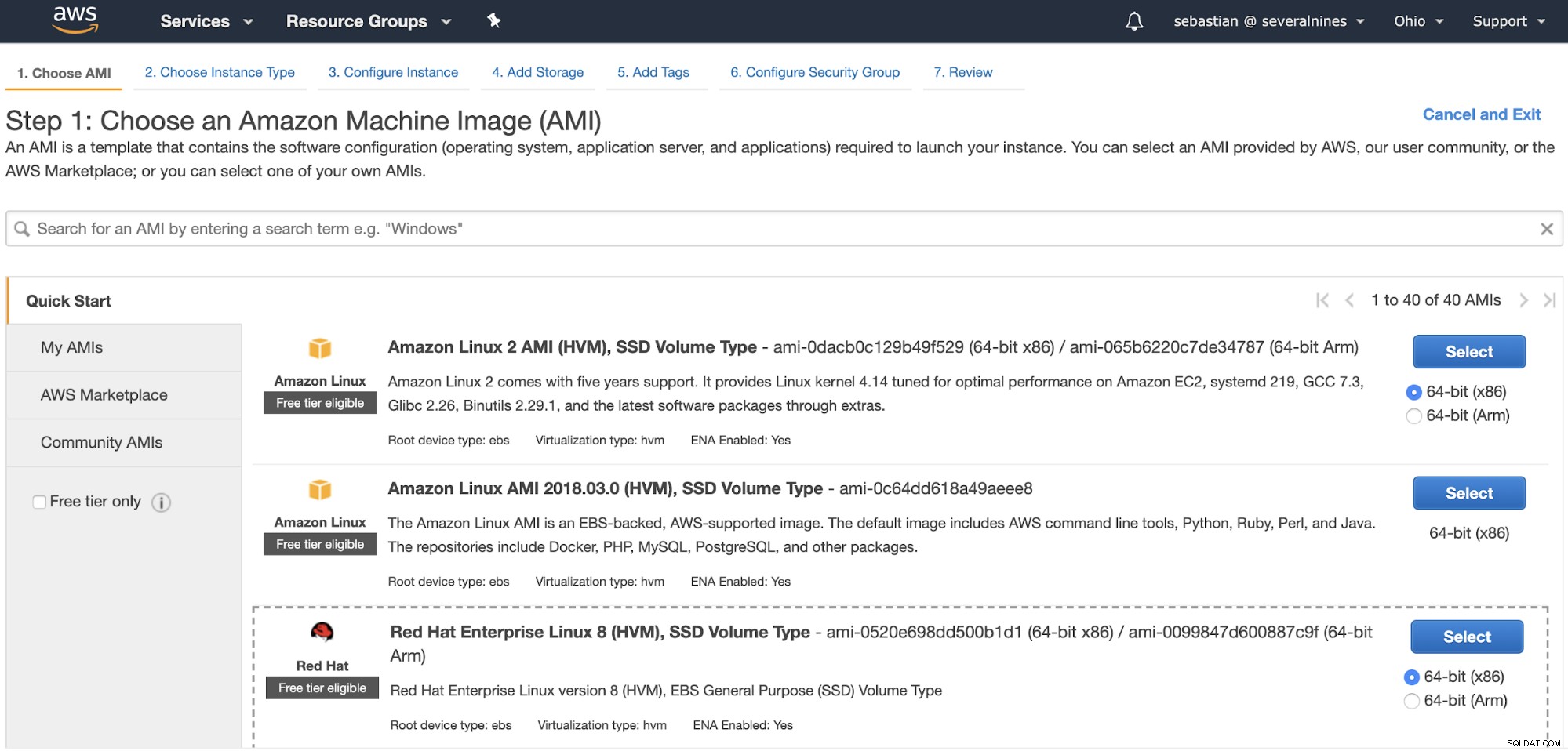
Wanneer uw instantie is gemaakt, moet u de openbare SSH kopiëren sleutel van de ClusterControl-server.
De back-up herstellen met ClusterControl
Je hebt nu de nieuwe EC2-instantie, laten we deze gebruiken om de back-up daar te herstellen. Ga hiervoor in uw ClusterControl naar het gedeelte back-up (ClusterControl -> Cluster selecteren -> Back-up), en daar kunt u "Back-up herstellen" selecteren, of direct "Herstellen" op de back-up die u wilt terugzetten.
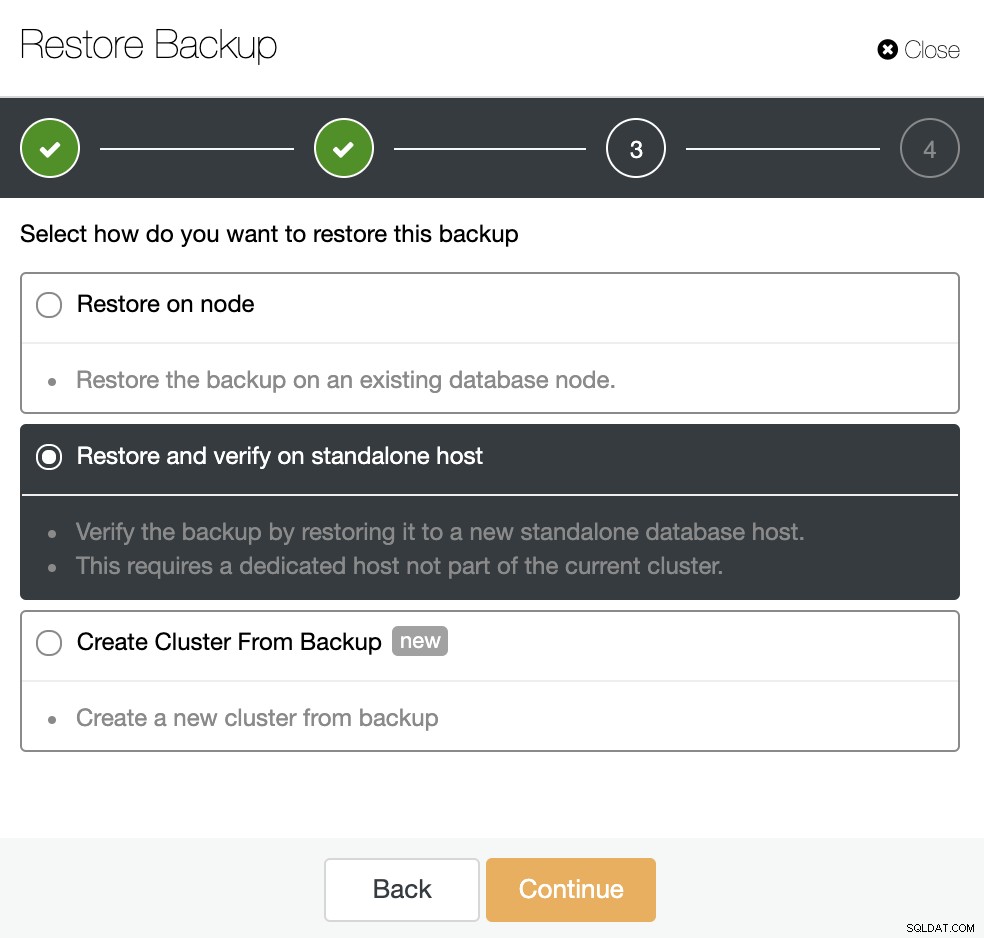
Je hebt drie opties om de back-up te herstellen. U kunt de back-up terugzetten in een bestaand databaseknooppunt, de back-up herstellen en verifiëren op een zelfstandige host of een nieuw cluster maken van de back-up. Omdat u een koude standby-node wilt maken, gebruiken we de tweede optie "Herstellen en verifiëren op zelfstandige host".
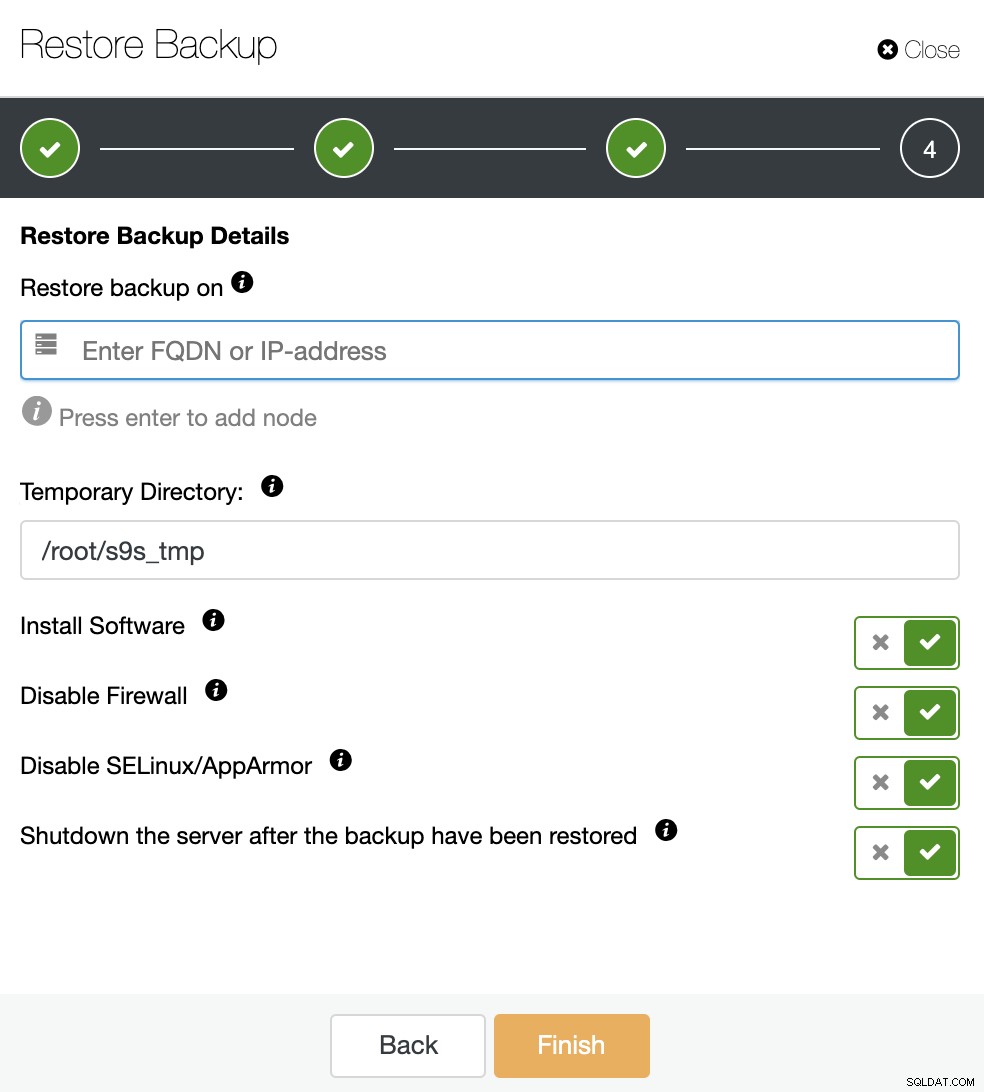
Je hebt een speciale host (of VM) nodig die geen deel uitmaakt van het cluster om de back-up te herstellen, dus laten we de EC2-instantie gebruiken die voor deze taak is gemaakt. ClusterControl installeert de software en herstelt de back-up in deze host.
Als de optie "Shutdown the server after the backup is restore" is ingeschakeld, stopt ClusterControl het databaseknooppunt na het voltooien van de hersteltaak, en dat is precies wat we nodig hebben voor deze koude stand-by-creatie.
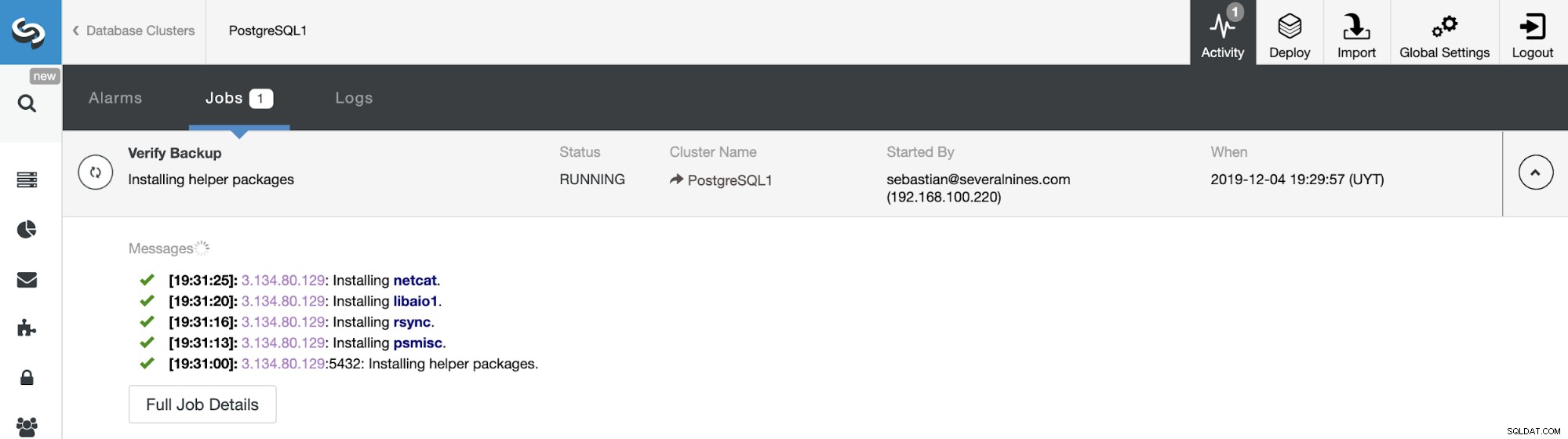
U kunt de voortgang van de back-up volgen in het gedeelte ClusterControl-activiteit.
De ClusterControl Verify-back-upfunctie gebruiken
Een back-up is geen back-up als deze niet kan worden hersteld. Zorg er dus voor dat de back-up werkt en herstel deze regelmatig in de koude standby-node.
Deze back-upfunctie van ClusterControl Verify Backup is een manier om het onderhoud van een koude stand-by-node te automatiseren door een recente back-up te herstellen om deze zo up-to-date mogelijk te houden, waarbij de handmatige herstelback-uptaak wordt vermeden. Laten we eens kijken hoe het werkt.
Als de taak "Herstellen en verifiëren op zelfstandige host", is een speciale host (of VM) vereist die geen deel uitmaakt van het cluster om de back-up te herstellen, dus laten we dezelfde EC2-instantie gebruiken hier.
De functie voor het automatisch verifiëren van back-ups is beschikbaar voor de geplande back-ups. Ga dus naar ClusterControl -> Selecteer het PostgreSQL-cluster -> Back-up -> Back-up maken en herhaal de stappen die u eerder zag om een nieuwe back-up te plannen.
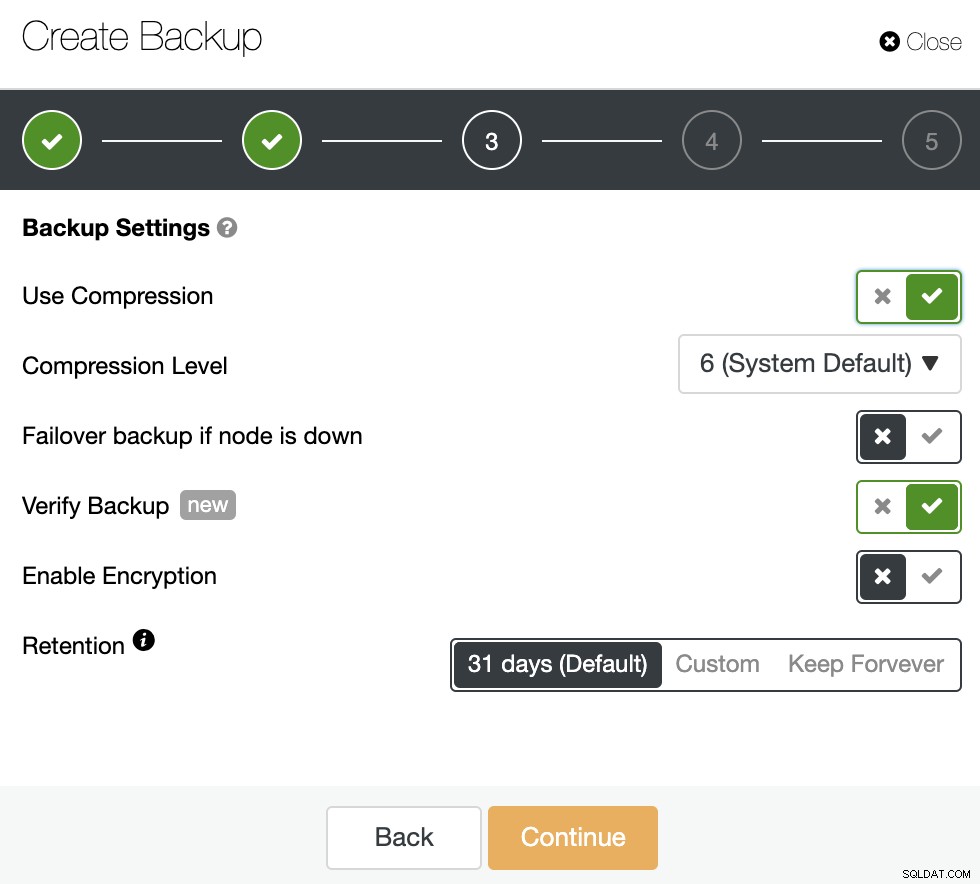
In de tweede stap heeft u de functie "Back-up verifiëren" beschikbaar om het in te schakelen.
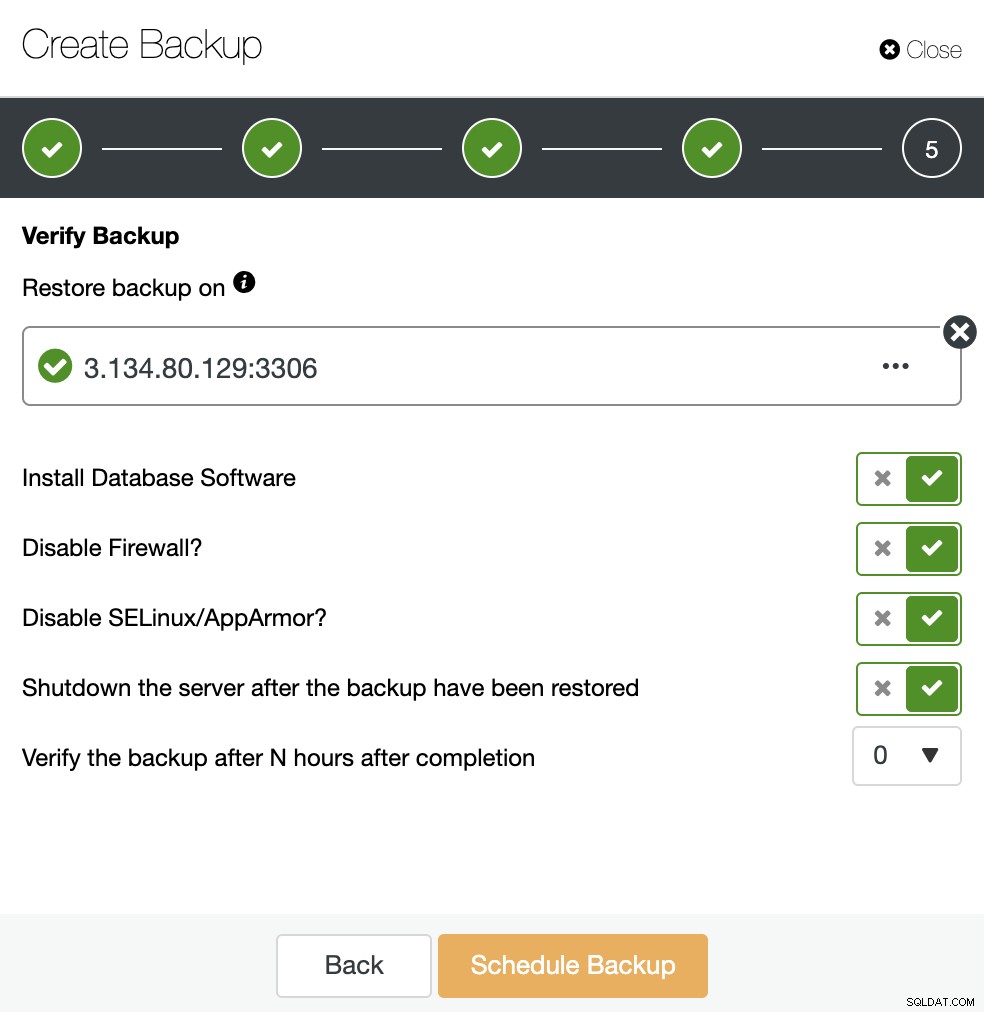
Met behulp van de bovenstaande opties zal ClusterControl de software installeren en de back-up herstellen op de gastheer. Als alles goed is gegaan nadat u het hebt hersteld, ziet u het verificatiepictogram in het gedeelte ClusterControl Backup.
Conclusie
Als u een beperkt budget heeft, maar hoge beschikbaarheid nodig heeft, kunt u een koude stand-by PostgreSQL-node gebruiken die wel of niet geldig kan zijn, afhankelijk van de RTO en RPO van het bedrijf. In deze blog hebben we je laten zien hoe je een back-up plant (volgens je bedrijfsbeleid) en hoe je deze handmatig terugzet. We hebben ook laten zien hoe je de back-up automatisch kunt herstellen in een Cold Standby Server met ClusterControl, Amazon S3 en Amazon EC2.