PostgreSQL is een geweldig project en het evolueert in een verbazingwekkend tempo. We zullen ons concentreren op de evolutie van fouttolerantiemogelijkheden in PostgreSQL in alle versies met een reeks blogposts. Dit is het derde bericht van de serie en we zullen het hebben over tijdlijnproblemen en hun effecten op fouttolerantie en betrouwbaarheid van PostgreSQL.
Als je vanaf het begin getuige wilt zijn van de evolutie van de evolutie, bekijk dan de eerste twee blogposts van de serie:
- Evolutie van fouttolerantie in PostgreSQL
- Evolutie van fouttolerantie in PostgreSQL:replicatiefase

Tijdlijnen
De mogelijkheid om de database te herstellen naar een eerder tijdstip zorgt voor een aantal complexiteiten die we in enkele gevallen zullen behandelen door failover uit te leggen. (Fig. 1), omschakeling (Fig. 2) en pg_rewind (Fig. 3) gevallen verderop in dit onderwerp.
Stel bijvoorbeeld dat u in de oorspronkelijke geschiedenis van de database op dinsdagavond om 17:15 uur een kritieke tabel liet vallen, maar uw fout pas op woensdagmiddag realiseerde. Onaangedaan, haalt u uw back-up tevoorschijn, herstelt u dinsdagavond 17:14 uur naar het punt in de tijd en bent u aan de slag. In deze geschiedenis van de database-universe heeft u de tabel nooit laten vallen. Maar stel dat je je later realiseert dat dit niet zo'n geweldig idee was, en zou willen terugkeren naar ergens woensdagochtend in de oorspronkelijke geschiedenis. U kunt dit niet doen als uw database, terwijl deze actief was, enkele van de WAL-segmentbestanden heeft overschreven die leidden tot het moment waarop u nu zou willen terugkeren.
Om dit te voorkomen, moet u de reeks WAL-records die zijn gegenereerd nadat u een herstel op een bepaald tijdstip heeft uitgevoerd, onderscheiden van de reeksen die zijn gegenereerd in de oorspronkelijke databasegeschiedenis.
Om dit probleem aan te pakken, heeft PostgreSQL een idee van tijdlijnen. Telkens wanneer een archiefherstel is voltooid, wordt een nieuwe tijdlijn gemaakt om de reeks WAL-records te identificeren die na dat herstel zijn gegenereerd. Het tijdlijn-ID-nummer maakt deel uit van de bestandsnamen van WAL-segmenten, dus een nieuwe tijdlijn overschrijft de WAL-gegevens die door eerdere tijdlijnen zijn gegenereerd niet. Het is namelijk mogelijk om veel verschillende tijdlijnen te archiveren.
Overweeg de situatie waarin u niet helemaal zeker weet naar welk tijdstip u moet herstellen, en dus met vallen en opstaan verschillende herstelacties op een bepaald tijdstip moet uitvoeren totdat u de beste plaats vindt om af te wijken van de oude geschiedenis. Zonder tijdlijnen zou dit proces al snel een onhandelbare puinhoop opleveren. Met tijdlijnen kun je herstellen naar elke eerdere status, inclusief statussen in tijdlijnvertakkingen die je eerder hebt verlaten.
Elke keer dat een nieuwe tijdlijn wordt gemaakt, maakt PostgreSQL een "tijdlijngeschiedenis" -bestand dat laat zien van welke tijdlijn het is afgetakt en wanneer. Deze geschiedenisbestanden zijn nodig om het systeem in staat te stellen de juiste WAL-segmentbestanden te kiezen bij het herstellen van een archief dat meerdere tijdlijnen bevat. Daarom worden ze net als WAL-segmentbestanden in het WAL-archiefgebied gearchiveerd. De geschiedenisbestanden zijn slechts kleine tekstbestanden, dus het is goedkoop en gepast om ze voor onbepaalde tijd te bewaren (in tegenstelling tot de segmentbestanden die groot zijn). Je kunt, als je wilt, opmerkingen toevoegen aan een geschiedenisbestand om je eigen aantekeningen te maken over hoe en waarom deze specifieke tijdlijn is gemaakt. Dergelijke opmerkingen zijn vooral waardevol als je als resultaat van experimenten een bos van verschillende tijdlijnen hebt.
Het standaardgedrag van herstel is om te herstellen langs dezelfde tijdlijn die actueel was toen de basisback-up werd gemaakt. Als u wilt herstellen naar een onderliggende tijdlijn (dat wil zeggen, u wilt terugkeren naar een staat die zelf is gegenereerd na een herstelpoging), moet u de doeltijdlijn-ID specificeren in recovery.conf. U kunt niet herstellen naar tijdlijnen die eerder zijn vertakt dan de basisback-up.
Voor het vereenvoudigen van het tijdlijnconcept in PostgreSQL, tijdlijngerelateerde problemen in het geval van failover , omschakeling en pg_rewind worden samengevat en uitgelegd met Fig.1, Fig.2 en Fig.3.
Failover-scenario:
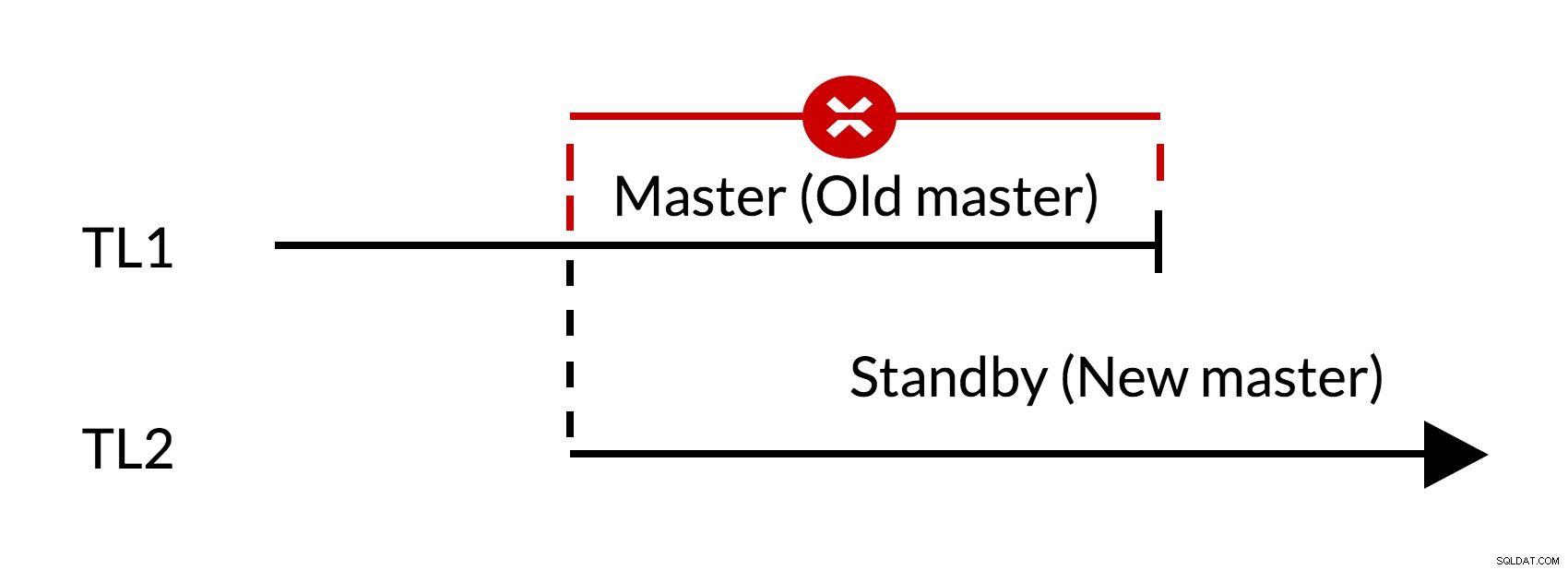
Afb.1 Failover
- Er zijn openstaande wijzigingen in de oude master (TL1)
- Verhoging van de tijdlijn vertegenwoordigt een nieuwe geschiedenis van wijzigingen (TL2)
- Wijzigingen van de oude tijdlijn kunnen niet worden afgespeeld op de servers die zijn overgeschakeld naar de nieuwe tijdlijn
- De oude meester kan de nieuwe meester niet volgen
Overschakelscenario:
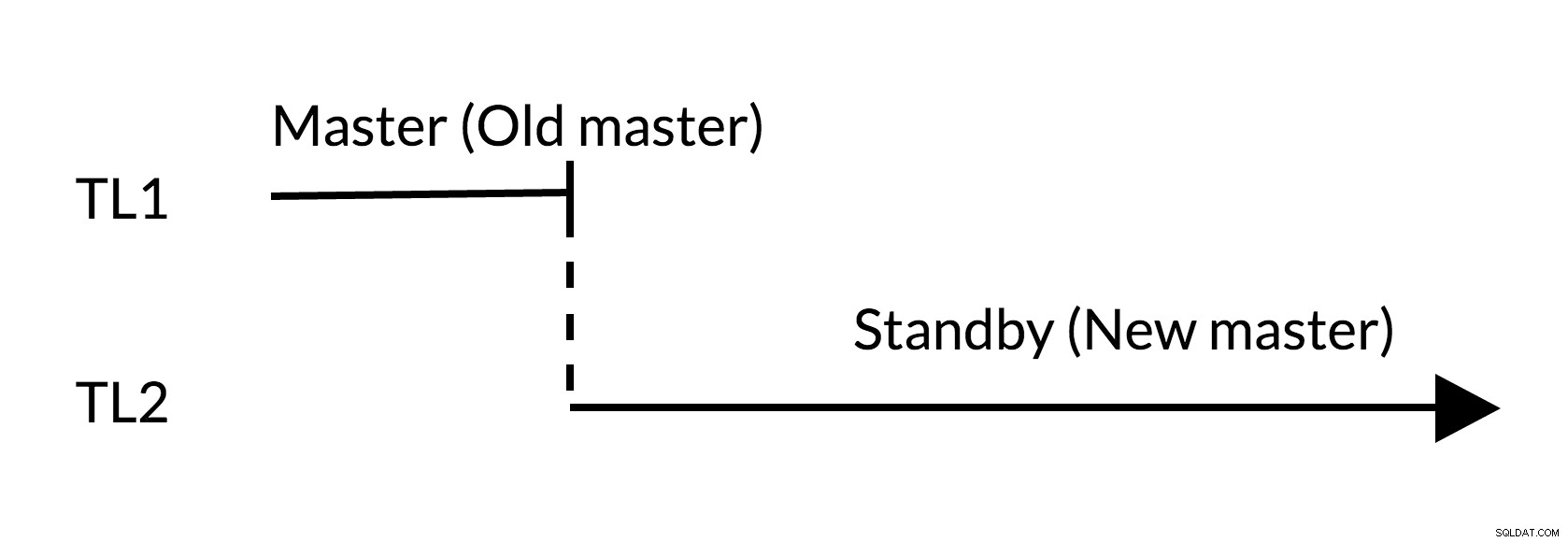 Afb.2 omschakeling
Afb.2 omschakeling
- Er zijn geen openstaande wijzigingen in de oude master (TL1)
- Tijdlijnverhoging vertegenwoordigt nieuwe geschiedenis van wijzigingen (TL2)
- De oude master kan stand-by worden voor de nieuwe master
pg_rewind scenario:
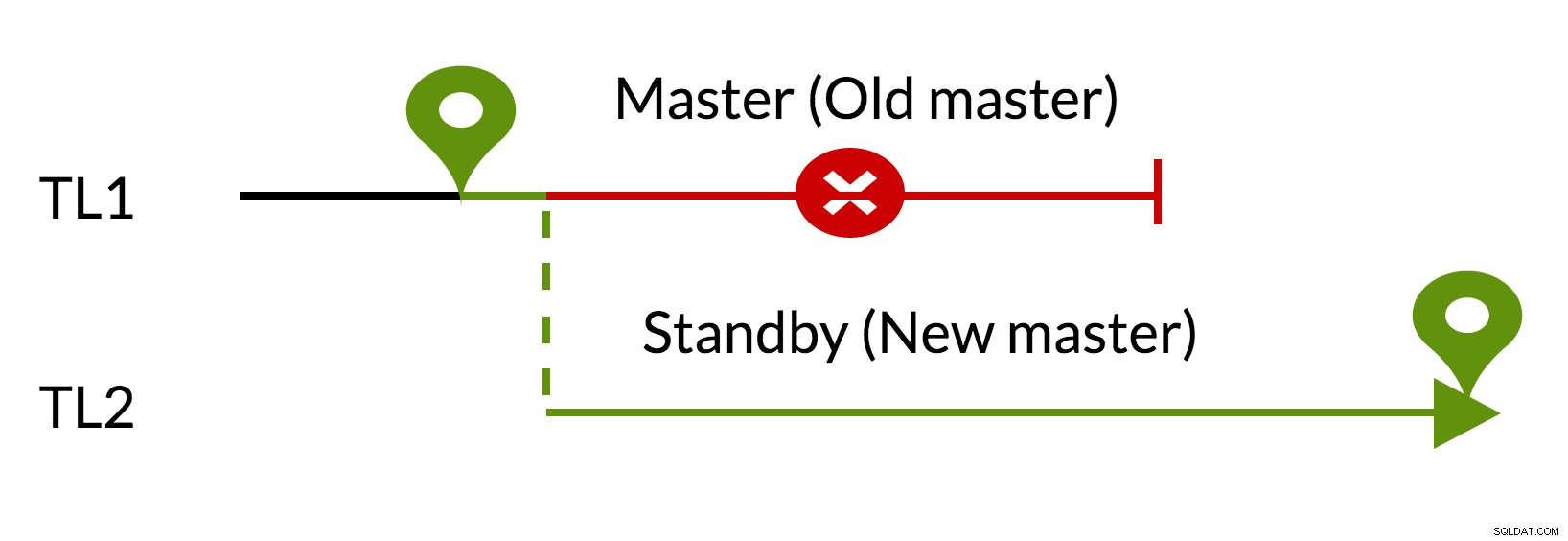 Fig.3 pg_rewind
Fig.3 pg_rewind
- Openstaande wijzigingen worden verwijderd met behulp van gegevens uit de nieuwe master (TL1)
- De oude master kan de nieuwe master volgen (TL2)
pg_rewind
pg_rewind is een tool voor het synchroniseren van een PostgreSQL-cluster met een andere kopie van hetzelfde cluster, nadat de tijdlijnen van de clusters zijn uiteengelopen. Een typisch scenario is om een oude masterserver na een failover weer online te brengen, als een stand-by die de nieuwe master volgt.
Het resultaat komt overeen met het vervangen van de doelgegevensmap door de bronmap. Alle bestanden worden gekopieerd, ook de configuratiebestanden. Het voordeel van pg_rewind ten opzichte van het nemen van een nieuwe basisback-up, of tools zoals rsync, is dat pg_rewind niet alle ongewijzigde bestanden in het cluster hoeft te lezen. Dat maakt het een stuk sneller als de database groot is en maar een klein deel ervan verschilt tussen de clusters.
Hoe het werkt?
Het basisidee is om alles van het nieuwe cluster naar het oude cluster te kopiëren, behalve de blokken waarvan we weten dat ze hetzelfde zijn.
- Scan het WAL-logboek van het oude cluster, beginnend bij het laatste controlepunt vóór het punt waar de tijdlijngeschiedenis van het nieuwe cluster is afgesplitst van het oude cluster. Noteer voor elk WAL-record de datablokken die zijn aangeraakt. Dit levert een lijst op van alle datablokken die zijn gewijzigd in het oude cluster, nadat het nieuwe cluster was afgesplitst.
- Kopieer al die gewijzigde blokken van het nieuwe cluster naar het oude cluster.
- Kopieer alle andere bestanden zoals klomp- en configuratiebestanden van het nieuwe cluster naar het oude cluster, alles behalve de relatiebestanden.
- Pas de WAL toe vanuit het nieuwe cluster, beginnend bij het controlepunt dat bij de failover is gemaakt. (Strikt genomen past pg_rewind de WAL niet toe, het maakt alleen een back-uplabelbestand aan dat aangeeft dat wanneer PostgreSQL wordt gestart, het opnieuw wordt afgespeeld vanaf dat controlepunt en alle vereiste WAL toepast.)
Opmerking: wal_log_hints moet worden ingesteld in postgresql.conf om pg_rewind te laten werken. Deze parameter kan alleen worden ingesteld bij het starten van de server. De standaardwaarde is uit .
Conclusie
In deze blogpost bespraken we tijdlijnen in Postgres en hoe we omgaan met failover- en omschakelingsgevallen. We hebben ook gesproken over hoe pg_rewind werkt en de voordelen ervan voor de fouttolerantie en betrouwbaarheid van Postgres. We gaan verder met synchrone commit in de volgende blogpost.
Referenties
PostgreSQL-documentatie
PostgreSQL 9 Administration Cookbook – Tweede editie
pg_rewind Nordic PGDay-presentatie door Heikki Linnakangas