Ik had het genoegen vorige week PGDay UK bij te wonen – een heel leuk evenement, hopelijk heb ik de kans om volgend jaar terug te komen. Er waren veel interessante gesprekken, maar degene die mijn aandacht trok was in het bijzonder Performace voor vragen met groepering door Alexey Bashtanov.
Ik heb in het verleden een behoorlijk aantal vergelijkbare prestatiegerichte lezingen gegeven, dus ik weet hoe moeilijk het is om benchmarkresultaten op een begrijpelijke en interessante manier te presenteren, en Alexey heeft het redelijk goed gedaan, denk ik. Dus als je te maken hebt met data-aggregatie (d.w.z. BI, analyse of vergelijkbare workloads), raad ik aan om de dia's door te nemen en als je de kans krijgt om de lezing op een andere conferentie bij te wonen, raad ik je ten zeerste aan dat te doen.
Maar er is een punt waarop ik het niet eens ben met het gesprek. Op een aantal plaatsen suggereerde de lezing dat je over het algemeen de voorkeur moet geven aan HashAggregate, omdat sorteringen traag zijn.
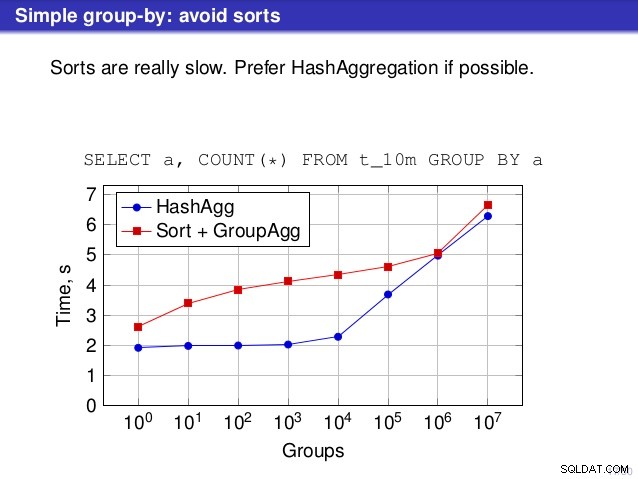
Ik vind dit een beetje misleidend, omdat een alternatief voor HashAggregate GroupAggregate is, niet Sort. Dus de aanbeveling gaat ervan uit dat elke GroupAggregate een geneste sortering heeft, maar dat is niet helemaal waar. GroupAggregate vereist gesorteerde invoer, en een expliciete Sortering is niet de enige manier om dat te doen – we hebben ook IndexScan- en IndexOnlyScan-knooppunten, die de sorteerkosten elimineren en de andere voordelen behouden die zijn gekoppeld aan gesorteerde paden (met name IndexOnlyScan).
Laat me demonstreren hoe (IndexOnlyScan+GroupAggregate) presteert in vergelijking met zowel HashAggregate als (Sort+GroupAggregate) - het script dat ik voor de metingen heb gebruikt, staat hier. Het bouwt vier eenvoudige tabellen, elk met 100 miljoen rijen en een verschillend aantal groepen in de kolom "branch_id" (die de grootte van de hashtabel bepaalt). De kleinste heeft 10.000 groepen
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
en drie extra tafels hebben groepen van 100k, 1M en 5M. Laten we deze eenvoudige query uitvoeren om de gegevens te verzamelen:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
en overtuig de database vervolgens om drie verschillende plannen te gebruiken:
1) HashAggregate
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) GroupAggregate (met een sortering)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAggregate (met een IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Resultaten
Na het meten van de timing voor elk plan op alle tafels, zien de resultaten er als volgt uit:
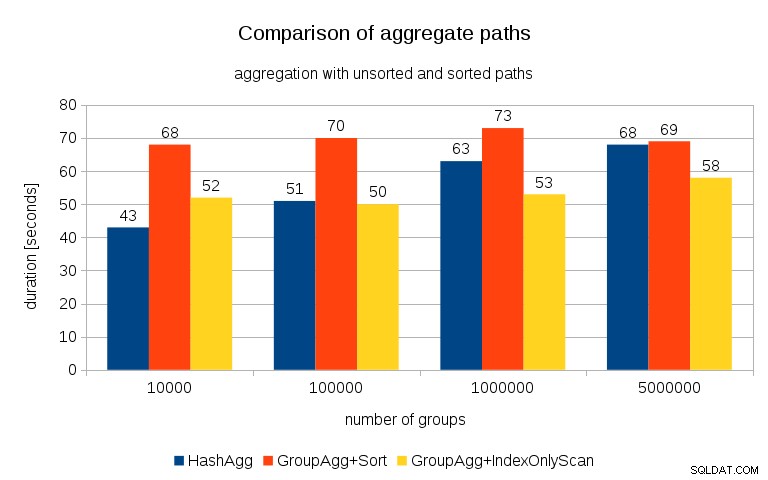
Voor kleine hashtabellen (passend in de L3-cache, die in dit geval 16 MB is), is het HashAggregate-pad duidelijk sneller dan beide gesorteerde paden. Maar al snel wordt GroupAgg+IndexOnlyScan net zo snel of zelfs sneller - dit komt door de cache-efficiëntie, het belangrijkste voordeel van GroupAggregate. Terwijl HashAggregate de hele hashtabel in één keer in het geheugen moet bewaren, hoeft GroupAggregate alleen de laatste groep te bewaren. En hoe minder geheugen je gebruikt, hoe groter de kans dat het in de L3-cache past, wat ongeveer een orde van grootte sneller is in vergelijking met gewoon RAM (voor de L1/L2-caches is het verschil zelfs nog groter).
Dus hoewel er een aanzienlijke overhead is verbonden aan IndexOnlyScan (voor het 10k-geval is het ongeveer 20% langzamer dan het HashAggregate-pad), naarmate de hashtabel groeit, daalt de L3-cache-hitverhouding snel en het verschil maakt de GroupAggregate uiteindelijk sneller. En uiteindelijk komt zelfs de GroupAggregate+Sort overeen met het HashAggregate-pad.
Je zou kunnen beweren dat je gegevens over het algemeen een vrij laag aantal groepen hebben, en dat de hashtabel dus altijd in de L3-cache past. Maar bedenk dat de L3-cache wordt gedeeld door alle processen die op de CPU worden uitgevoerd, en ook door alle delen van het queryplan. Dus hoewel we momenteel ongeveer 20 MB L3-cache per socket hebben, krijgt je query maar een deel daarvan, en dat bit wordt gedeeld door alle nodes in je (mogelijk vrij complexe) query.
Update 26/07/26 :Zoals opgemerkt in de opmerkingen van Peter Geoghegan, resulteert de manier waarop de gegevens zijn gegenereerd waarschijnlijk in correlatie - niet de waarden (of liever hashes van de waarden), maar geheugentoewijzingen. Ik heb de zoekopdrachten herhaald met correct gerandomiseerde gegevens, d.w.z.
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
in plaats van
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
en de resultaten zien er als volgt uit:
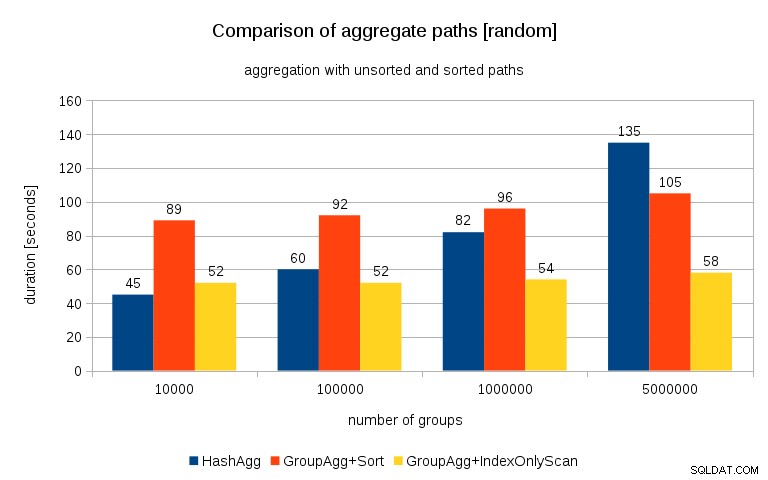
Als ik dit vergelijk met de vorige grafiek, denk ik dat het vrij duidelijk is dat de resultaten nog meer in het voordeel zijn van gesorteerde paden, vooral voor de dataset met 5M-groepen. De 5M-dataset laat ook zien dat GroupAgg met een expliciete sortering mogelijk sneller is dan HashAgg.
Samenvatting
Hoewel HashAggregate waarschijnlijk sneller is dan GroupAggregate met een expliciete sortering (ik durf niet te zeggen dat dit altijd het geval is), kan het sneller gebruiken van GroupAggregate met IndexOnlyScan het gemakkelijk veel sneller maken dan HashAggregate.
Natuurlijk kun je niet direct het exacte plan kiezen - de planner zou dat voor je moeten doen. Maar u beïnvloedt het selectieproces door (a) indexen te maken en (b) work_mem in te stellen . Daarom verlagen soms work_mem (en maintenance_work_mem ) waarden resulteren in betere prestaties.
Extra indexen zijn echter niet gratis - ze kosten zowel CPU-tijd (bij het invoegen van nieuwe gegevens) als schijfruimte. Voor IndexOnlyScans kunnen de schijfruimtevereisten behoorlijk groot zijn omdat de index alle kolommen moet bevatten waarnaar door de query wordt verwezen, en normale IndexScan zou u niet dezelfde prestaties geven omdat het veel willekeurige I/O tegen de tabel genereert (waardoor alle de potentiële winsten).
Een andere leuke functie is de stabiliteit van de uitvoering - merk op hoe de HashAggregate-timing afhankelijk is van het aantal groepen, terwijl de GroupAggregate-paden grotendeels hetzelfde presteren.