Python is tegenwoordig erg populair. Omdat Python een programmeertaal voor algemene doeleinden is, kan het ook worden gebruikt om het proces Extract, Transform, Load (ETL) uit te voeren. Er zijn verschillende ETL-modules beschikbaar, maar vandaag houden we het bij de combinatie van Python en MySQL. We gebruiken Python om opgeslagen procedures op te roepen en SQL-instructies voor te bereiden en uit te voeren.
We zullen twee vergelijkbare, maar verschillende benaderingen gebruiken. Eerst zullen we opgeslagen procedures aanroepen die het hele werk zullen doen, en daarna zullen we analyseren hoe we hetzelfde proces zouden kunnen doen zonder opgeslagen procedures door MySQL-code in Python te gebruiken.
Klaar? Laten we, voordat we dieper ingaan, eens kijken naar het datamodel – of datamodellen, want er zijn er twee in dit artikel.
De gegevensmodellen
We hebben twee gegevensmodellen nodig, één om onze operationele gegevens op te slaan en de andere om onze rapportagegegevens op te slaan.
Het eerste model wordt getoond in de afbeelding hierboven. Dit model wordt gebruikt om operationele (live) gegevens op te slaan voor een op abonnementen gebaseerd bedrijf. Voor meer inzicht in dit model verwijzen wij u naar ons vorige artikel, Een DWH maken, deel één:een bedrijfsgegevensmodel voor abonnementen.
Het scheiden van operationele en rapportagegegevens is meestal een zeer verstandige beslissing. Om die scheiding te realiseren, moeten we een datawarehouse (DWH) creëren. Dat hebben we al gedaan; u kunt het model in de afbeelding hierboven zien. Dit model wordt ook in detail beschreven in de post Een DWH maken, deel twee:een bedrijfsgegevensmodel voor abonnementen.
Ten slotte moeten we gegevens uit de live database extraheren, transformeren en in onze DWH laden. We hebben dit al gedaan met behulp van opgeslagen SQL-procedures. Een beschrijving van wat we willen bereiken, samen met enkele codevoorbeelden, vindt u in Een datawarehouse maken, deel 3:een bedrijfsgegevensmodel voor abonnementen.
Als u aanvullende informatie over DWH's nodig heeft, raden we u aan deze artikelen te lezen:
- Het sterrenschema
- Het sneeuwvlokschema
- Sterschema vs. Sneeuwvlokschema.
Onze taak vandaag is om de opgeslagen SQL-procedures te vervangen door Python-code. We zijn klaar om wat Python-magie te maken. Laten we beginnen met het gebruik van alleen opgeslagen procedures in Python.
Methode 1:ETL met behulp van opgeslagen procedures
Voordat we beginnen met het beschrijven van het proces, is het belangrijk om te vermelden dat we twee databases op onze server hebben.
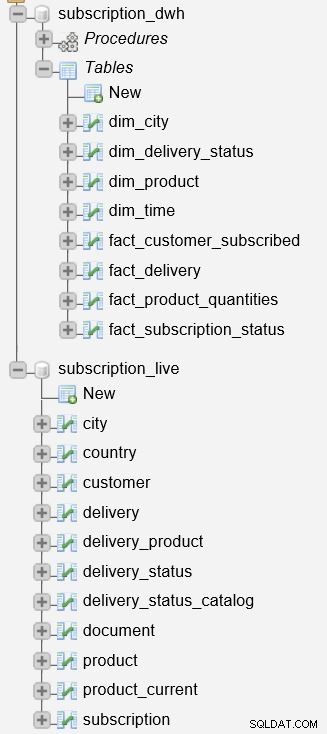
De subscription_live database wordt gebruikt om transactie-/livegegevens op te slaan, terwijl de subscription_dwh is onze rapportagedatabase (DWH).
We hebben de opgeslagen procedures al beschreven die worden gebruikt om dimensie- en feitentabellen bij te werken. Ze lezen gegevens van de subscription_live database, combineer deze met gegevens in de subscription_dwh database en voeg nieuwe gegevens toe aan de subscription_dwh databank. Deze twee procedures zijn:
p_update_dimensions– Werkt de dimensietabellen bijdim_timeendim_city.p_update_facts– Werkt twee feitentabellen bij,fact_customer_subscribedenfact_subscription_status.
Als u de volledige code voor deze procedures wilt zien, lees dan Een datawarehouse maken, deel 3:een bedrijfsgegevensmodel voor abonnementen.
Nu zijn we klaar om een eenvoudig Python-script te schrijven dat verbinding maakt met de server en het ETL-proces uitvoert. Laten we eerst het hele script bekijken (etl_procedures.py ). Daarna leggen we de belangrijkste onderdelen uit.
# import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor() # I update dimensions cursor.callproc('subscription_dwh.p_update_dimensions') print('Dimension tables updated.') # II update facts cursor.callproc('subscription_dwh.p_update_facts') print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_procedures.py
Modules importeren en verbinding maken met de database
Python gebruikt modules om definities en instructies op te slaan. U kunt een bestaande module gebruiken of uw eigen module schrijven. Het gebruik van bestaande modules zal je leven vereenvoudigen omdat je vooraf geschreven code gebruikt, maar het schrijven van je eigen module is ook erg handig. Wanneer u de Python-interpreter afsluit en opnieuw uitvoert, verliest u functies en variabelen die u eerder hebt gedefinieerd. U wilt natuurlijk niet steeds dezelfde code typen. Om dat te voorkomen, kunt u uw definities in een module opslaan en in Python importeren.
Terug naar etl_procedures.py . In ons programma beginnen we met het importeren van MySQL Connector:
# import MySQL connector import mysql.connector
MySQL Connector for Python wordt gebruikt als een gestandaardiseerd stuurprogramma dat verbinding maakt met een MySQL-server/database. Je moet het downloaden en installeren als je dat nog niet eerder hebt gedaan. Naast het verbinden met de database biedt het een aantal methoden en eigenschappen om met een database te werken. We zullen er enkele gebruiken, maar je kunt de volledige documentatie hier raadplegen.
Vervolgens moeten we verbinding maken met onze database:
# connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor()
De eerste regel maakt verbinding met een server (in dit geval maak ik verbinding met mijn lokale computer) met uw inloggegevens (vervang
connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Ik heb met opzet alleen verbinding gemaakt met een server en niet met een specifieke database, omdat ik twee databases op dezelfde server ga gebruiken.
Het volgende commando – print - is hier slechts een melding dat we succesvol zijn verbonden. Hoewel het geen programmeerwaarde heeft, kan het worden gebruikt om de code te debuggen als er iets misgaat in het script.
De laatste regel in dit deel is:
cursor =verbinding.cursor()
Cursors are the handler structure used to work with the data. We’ll use them for retrieving data from the database (SELECT), but also to modify the data (INSERT, UPDATE, DELETE). Before using a cursor, we need to create it. And that is what this line does.
Belprocedures
Het vorige deel was algemeen en kon gebruikt worden voor andere database-gerelateerde taken. Het volgende deel van de code is specifiek voor ETL:onze opgeslagen procedures aanroepen met de cursor.callproc opdracht. Het ziet er zo uit:
# 1. update dimensions
cursor.callproc('subscription_dwh.p_update_dimensions')
print('Dimension tables updated.')
# 2. update facts
cursor.callproc('subscription_dwh.p_update_facts')
print('Fact tables updated.')
Aanroepprocedures spreken voor zich. Na elke oproep werd een printopdracht toegevoegd. Nogmaals, dit geeft ons alleen een melding dat alles goed is gegaan.
Bevestigen en sluiten
Het laatste deel van het script legt de databasewijzigingen vast en sluit alle gebruikte objecten:
# commit & close connection
cursor.close()
connection.commit()
connection.close()
print('Disconnected from database.')
Aanroepprocedures spreken voor zich. Na elke oproep werd een printopdracht toegevoegd. Nogmaals, dit geeft ons alleen een melding dat alles goed is gegaan.
Commitment is hierbij essentieel; zonder dit zijn er geen wijzigingen in de database, zelfs niet als u een procedure hebt aangeroepen of een SQL-statement hebt uitgevoerd.
Het script uitvoeren
Het laatste wat we moeten doen is ons script uitvoeren. We gebruiken de volgende commando's in de Python Shell om dat te bereiken:
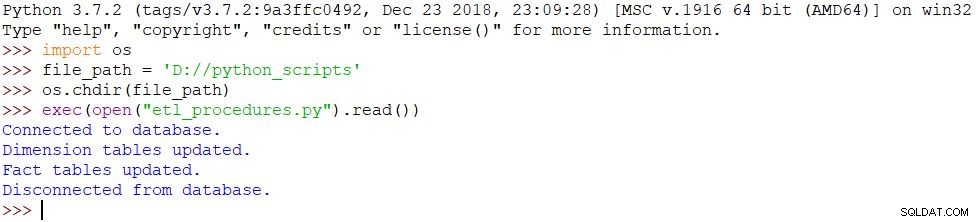
import osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())Het script wordt uitgevoerd en alle wijzigingen worden dienovereenkomstig in de database aangebracht. Het resultaat is te zien in de onderstaande afbeelding.
Methode 2:ETL met Python en MySQL
De hierboven gepresenteerde aanpak verschilt niet veel van de aanpak om opgeslagen procedures rechtstreeks in MySQL aan te roepen. Het enige verschil is dat we nu een script hebben dat het hele werk voor ons doet.
We zouden een andere benadering kunnen gebruiken:alles in het Python-script plaatsen. We zullen Python-statements opnemen, maar we zullen ook SQL-query's voorbereiden en uitvoeren op de database. De brondatabase (live) en de doeldatabase (DWH) zijn hetzelfde als in het voorbeeld met opgeslagen procedures.
Laten we, voordat we hier dieper op ingaan, eens kijken naar het volledige script (etl_queries.py ):
from datetime import date # import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') # 1. update dimensions # 1.1 update dim_time # date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"' # test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) result = cursor.fetchall() yesterday_subscription_count = int(result[0][0]) if yesterday_subscription_count == 0: yesterday_year = 'YEAR("' + str(yesterday) + '")' yesterday_month = 'MONTH("' + str(yesterday) + '")' yesterday_week = 'WEEK("' + str(yesterday) + '")' yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")' query = ( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())") cursor.execute(query) # 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query) print('Dimension tables updated.') # 2. update facts # 2.1 update customers subscribed # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_customer_subscribed`.* " "FROM subscription_dwh.`fact_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN customer_live.active = 1 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active = 0 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) # 2.2 update subscription statuses # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active = 1 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active = 0 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id = customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_queries.py
Modules importeren en verbinding maken met de database
Nogmaals, we moeten MySQL importeren met de volgende code:
import mysql.connector
We importeren ook de datetime-module, zoals hieronder weergegeven. We hebben dit nodig voor datumgerelateerde bewerkingen in Python:
from datetime import date
Het proces om verbinding te maken met de database is hetzelfde als in het vorige voorbeeld.
De dim_time-dimensie bijwerken
De dim_time tabel, moeten we controleren of de waarde (voor gisteren) al in de tabel staat. We zullen de datumfuncties van Python (in plaats van SQL) moeten gebruiken om dit te doen:
# date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"'
De eerste regel code retourneert de datum van gisteren in de datumvariabele, terwijl de tweede regel deze waarde als een tekenreeks opslaat. We hebben dit als een tekenreeks nodig omdat we het samenvoegen met een andere tekenreeks wanneer we de SQL-query bouwen.
Vervolgens moeten we testen of deze datum al in de dim_time tafel. Na het declareren van een cursor, bereiden we de SQL-query voor. Om de query uit te voeren, gebruiken we de cursor.execute commando:
# test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) '"'
We slaan het zoekresultaat op in het resultaat variabel. Het resultaat heeft 0 of 1 rij, dus we kunnen de eerste kolom van de eerste rij testen. Het zal een 0 of een 1 bevatten. (Vergeet niet dat we dezelfde datum maar één keer in een dimensietabel kunnen hebben.)
Als de datum nog niet in de tabel staat, bereiden we de strings voor die deel zullen uitmaken van de SQL-query:
result = cursor.fetchall()
yesterday_subscription_count = int(result[0][0])
if yesterday_subscription_count == 0:
yesterday_year = 'YEAR("' + str(yesterday) + '")'
yesterday_month = 'MONTH("' + str(yesterday) + '")'
yesterday_week = 'WEEK("' + str(yesterday) + '")'
yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")'
Ten slotte gaan we een query maken en deze uitvoeren. Hiermee wordt de dim_time tafel nadat het is gepleegd. Houd er rekening mee dat ik het volledige pad naar de tabel heb gebruikt, inclusief de databasenaam (subscription_dwh ).
query = (
"INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) "
" VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())")
cursor.execute(query)
De dim_city-dimensie bijwerken
De dim_city tabel is nog eenvoudiger omdat we niets hoeven te testen voor de invoeging. We zullen die test daadwerkelijk in de SQL-query opnemen.
# 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query)
Hier bereiden we een uitvoering van de SQL-query voor. Merk op dat ik opnieuw de volledige paden naar tabellen heb gebruikt, inclusief de namen van beide databases (subscription_live en subscription_dwh ).
De feitentabellen bijwerken
Het laatste wat we moeten doen is onze feitentabellen bijwerken. Het proces is bijna hetzelfde als het bijwerken van dimensietabellen:we bereiden query's voor en voeren ze uit. Deze query's zijn veel complexer, maar ze zijn dezelfde als de query's die worden gebruikt in de opgeslagen procedures.
We hebben één verbetering toegevoegd ten opzichte van de opgeslagen procedures:het verwijderen van de bestaande gegevens voor dezelfde datum in de feitentabel. Hierdoor kunnen we een script meerdere keren uitvoeren voor dezelfde datum. Aan het einde moeten we de transactie uitvoeren en alle objecten en de verbinding sluiten.
Het script uitvoeren
We hebben een kleine wijziging in dit deel, dat een ander script aanroept:
- import os
- file_path = 'D://python_scripts'
- os.chdir(file_path)
- exec(open("etl_queries.py").read())
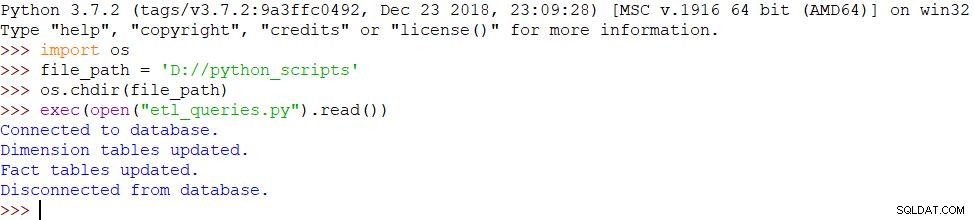
Omdat we dezelfde berichten hebben gebruikt en het script met succes is voltooid, is het resultaat hetzelfde:
Hoe zou u Python in ETL gebruiken?
Vandaag zagen we een voorbeeld van het uitvoeren van het ETL-proces met een Python-script. Er zijn andere manieren om dit te doen, b.v. een aantal open-sourceoplossingen die Python-bibliotheken gebruiken om met databases te werken en het ETL-proces uit te voeren. In het volgende artikel zullen we met een van hen spelen. Deel in de tussentijd gerust uw ervaringen met Python en ETL.