SQLAlchemy helpt je bij het werken met databases in Python. In dit bericht vertellen we je alles wat je moet weten om met deze module aan de slag te gaan.
In het vorige artikel hebben we het gehad over het gebruik van Python in het ETL-proces. We hebben ons gericht op het klaren van de klus door het uitvoeren van opgeslagen procedures en SQL-query's. In dit artikel en het volgende zullen we een andere benadering gebruiken. In plaats van SQL-code te schrijven, gebruiken we de SQLAlchemy-toolkit. U kunt dit artikel ook afzonderlijk gebruiken, als een korte introductie over het installeren en gebruiken van SQLAlchemy.
Klaar? Laten we beginnen.
Wat is SQLAlchemy?
Python staat bekend om het aantal en de verscheidenheid aan modules. Deze modules verkorten onze codeertijd aanzienlijk omdat ze routines implementeren die nodig zijn om een specifieke taak uit te voeren. Er zijn een aantal modules beschikbaar die met data werken, waaronder SQLAlchemy.
Om SQLAlchemy te beschrijven, gebruik ik een citaat van SQLAlchemy.org:
SQLAlchemy is de Python SQL-toolkit en Object Relational Mapper die applicatieontwikkelaars de volledige kracht en flexibiliteit van SQL geeft.
Het biedt een volledige suite van bekende persistentie op ondernemingsniveau patronen, ontworpen voor efficiënte en goed presterende databasetoegang, aangepast in een eenvoudige en Pythonische domeintaal.
Het belangrijkste deel hier is het stukje over de ORM (object-relationele mapper), die ons helpt database-objecten te behandelen als Python-objecten in plaats van lijsten.
Voordat we verder gaan met SQLAlchemy, laten we even pauzeren en praten over ORM's.
De voor- en nadelen van het gebruik van ORM's
Vergeleken met onbewerkte SQL hebben ORM's hun voor- en nadelen - en de meeste hiervan zijn ook van toepassing op SQLAlchemy.
De goede dingen:
- Codedraagbaarheid. De ORM zorgt voor syntactische verschillen tussen databases.
- Slechts één taal is nodig om uw database te verwerken. Hoewel, om eerlijk te zijn, dit niet de belangrijkste motivatie zou moeten zijn om een ORM te gebruiken.
- ORM's vereenvoudigen uw code , bijv. ze zorgen voor relaties en behandelen ze als objecten, wat geweldig is als je gewend bent aan OOP.
- U kunt uw gegevens in het programma manipuleren .
Helaas heeft alles een prijs. De minder goede dingen over ORM's:
- In sommige gevallen kan een ORM langzaam zijn .
- Het schrijven van complexe zoekopdrachten kan nog ingewikkelder worden of kan leiden tot trage zoekopdrachten. Maar dit is niet het geval bij het gebruik van SQLAlchemy.
- Als u uw DBMS goed kent, is het tijdverspilling om te leren hoe u hetzelfde in een ORM kunt schrijven.
Nu we dat onderwerp hebben behandeld, gaan we terug naar SQLAlchemy.
Voordat we beginnen...
… laten we onszelf herinneren aan het doel van dit artikel. Als je alleen geïnteresseerd bent in het installeren van SQLAlchemy en een korte zelfstudie nodig hebt over het uitvoeren van eenvoudige opdrachten, dan zal dit artikel dat doen. De opdrachten in dit artikel zullen echter in het volgende artikel worden gebruikt om het ETL-proces uit te voeren en de SQL (opgeslagen procedures) en Python-code te vervangen die we in eerdere artikelen hebben gepresenteerd.
Oké, laten we nu meteen bij het begin beginnen:met het installeren van SQLAlchemy.
SQLAlchemy installeren
1. Controleer of de module al is geïnstalleerd
Om een Python-module te gebruiken, moet u deze installeren (als deze niet eerder was geïnstalleerd). Een manier om te controleren welke modules zijn geïnstalleerd, is door deze opdracht in Python Shell te gebruiken:
help('modules')
Als u wilt controleren of een specifieke module is geïnstalleerd, kunt u deze eenvoudig proberen te importeren. Gebruik deze commando's:
import sqlalchemy sqlalchemy.__version__
Als SQLAlchemy al is geïnstalleerd, wordt de eerste regel met succes uitgevoerd. import is een standaard Python-commando dat wordt gebruikt om modules te importeren. Als de module niet is geïnstalleerd, geeft Python een fout - eigenlijk een lijst met fouten, in rode tekst - die je niet mag missen :)
De tweede opdracht retourneert de huidige versie van SQLAlchemy. Het geretourneerde resultaat is hieronder afgebeeld:

We hebben ook nog een module nodig, en dat is PyMySQL . Dit is een pure Python lichtgewicht MySQL-clientbibliotheek. Deze module ondersteunt alles wat we nodig hebben om met een MySQL-database te werken, van het uitvoeren van eenvoudige query's tot complexere database-acties. We kunnen controleren of het bestaat met behulp van help('modules') , zoals eerder beschreven, of met behulp van de volgende twee verklaringen:
import pymysql pymysql.__version__
Natuurlijk zijn dit dezelfde commando's die we gebruikten om te testen of SQLAlchemy was geïnstalleerd.
Wat als SQLAlchemy of PyMySQL nog niet is geïnstalleerd?
Het importeren van eerder geïnstalleerde modules is niet moeilijk. Maar wat als de modules die je nodig hebt nog niet zijn geïnstalleerd?
Sommige modules hebben een installatiepakket, maar meestal gebruik je het pip-commando om ze te installeren. PIP is een Python-tool die wordt gebruikt om modules te installeren en te verwijderen. De eenvoudigste manier om een module te installeren (in Windows OS) is:
- Gebruik Opdrachtprompt -> Uitvoeren -> cmd .
- Positie in de Python-directory cd C:\...\Python\Python37\Scripts .
- Voer het commando pip
installuit (in ons geval gebruiken wepip install pyMySQLenpip install sqlAlchemy.
PIP kan ook worden gebruikt om de bestaande module te verwijderen. Om dat te doen, moet u pip uninstall . gebruiken .
2. Verbinding maken met de database
Hoewel het essentieel is om alles te installeren wat nodig is om SQLAlchemy te gebruiken, is het niet erg interessant. Het maakt ook niet echt deel uit van waar we in geïnteresseerd zijn. We hebben niet eens verbinding gemaakt met de databases die we willen gebruiken. Dat gaan we nu oplossen:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Met behulp van het bovenstaande script brengen we een verbinding tot stand met de database op onze lokale server, de subscription_live databank.
(Opmerking: Vervang
Laten we het script, opdracht voor opdracht, doornemen.
import sqlalchemy from sqlalchemy.engine import create_engine
Deze twee regels importeren onze module en de create_engine functie.
Vervolgens maken we een verbinding met de database op onze server.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
De functie create_engine maakt de engine en gebruikt .connect() , maakt verbinding met de database. De create_engine functie gebruikt deze parameters:
dialect+driver://username:password@host:port/database
In ons geval is het dialect mysql , het stuurprogramma is pymysql (eerder geïnstalleerd) en de overige variabelen zijn specifiek voor de server en database(s) waarmee we verbinding willen maken.
(Opmerking: Als je lokaal verbinding maakt, gebruik dan localhost in plaats van uw "lokale" IP-adres, 127.0.0.1 en de juiste poort :3306 .)

Het resultaat van het commando print(engine_live.table_names()) wordt weergegeven in de afbeelding hierboven. Zoals verwacht hebben we de lijst met alle tabellen uit onze operationele/live database.
3. SQL-opdrachten uitvoeren met SQLAlchemy
In deze sectie zullen we de belangrijkste SQL-opdrachten analyseren, de tabelstructuur onderzoeken en alle vier de DML-opdrachten uitvoeren:SELECT, INSERT, UPDATE en DELETE.
We zullen de uitspraken die in dit script worden gebruikt afzonderlijk bespreken. Houd er rekening mee dat we het verbindingsgedeelte van dit script al hebben doorgenomen en dat we al tabelnamen hebben vermeld. Er zijn kleine wijzigingen in deze regel:
from sqlalchemy import create_engine, select, MetaData, Table, asc
We hebben zojuist alles geïmporteerd wat we gaan gebruiken uit SQLAlchemy.
Tabellen en structuur
We zullen het script uitvoeren door de volgende opdracht in de Python Shell te typen:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Het resultaat is het uitgevoerde script. Laten we nu de rest van het script analyseren.
SQLAlchemy importeert informatie met betrekking tot tabellen, structuur en relaties. Om met die informatie te werken, kan het handig zijn om de lijst met tabellen (en hun kolommen) in de database te controleren:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Dit retourneert eenvoudig een lijst met alle tabellen uit de verbonden database.
Opmerking: De table_names() methode retourneert een lijst met tabelnamen voor de gegeven engine. Je kunt de hele lijst afdrukken of er doorheen lopen met een lus (zoals je met elke andere lijst zou kunnen doen).
Vervolgens retourneren we een lijst met alle attributen uit de geselecteerde tabel. Het relevante deel van het script en het resultaat worden hieronder weergegeven:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
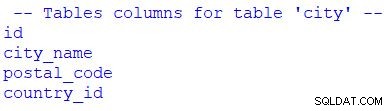
Je kunt zien dat ik for . heb gebruikt om door de resultatenset te bladeren. We zouden table_city.c kunnen vervangen met table_city.columns .
Opmerking: Het proces van het laden van de databasebeschrijving en het creëren van metadata in SQLAlchemy wordt reflectie genoemd.
Opmerking: MetaData is het object dat informatie over objecten in de database bijhoudt, dus tabellen in de database worden ook aan dit object gekoppeld. In het algemeen slaat dit object informatie op over hoe het databaseschema eruitziet. U gebruikt het als enig aanspreekpunt wanneer u wijzigingen wilt aanbrengen in of feiten wilt verkrijgen over het DB-schema.
Opmerking: De attributen autoload = True en autoload_with = engine_live moet worden gebruikt om ervoor te zorgen dat tabelkenmerken worden geüpload (als dat nog niet het geval is).
SELECTEER
Ik denk niet dat ik hoef uit te leggen hoe belangrijk het SELECT-statement is :) Laten we dus zeggen dat je SQLAlchemy kunt gebruiken om SELECT-statements te schrijven. Als je gewend bent aan de MySQL-syntaxis, zal het even duren om je aan te passen; toch is alles vrij logisch. Om het zo eenvoudig mogelijk te zeggen, zou ik zeggen dat de SELECT-instructie is opgedeeld en sommige delen zijn weggelaten, maar alles is nog steeds in dezelfde volgorde.
Laten we nu een paar SELECT-instructies proberen.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
De eerste is een eenvoudige SELECT-instructie het retourneren van alle waarden uit de gegeven tabel. De syntaxis van deze verklaring is heel eenvoudig:ik heb de naam van de tabel in de select() . Houd er rekening mee dat ik:
- De verklaring voorbereid -
stmt = select([table_city]. - De verklaring afgedrukt met
print(stmt), wat ons een goed idee geeft van de instructie die zojuist is uitgevoerd. Dit kan ook worden gebruikt voor foutopsporing. - Het resultaat afgedrukt met
print(connection_live.execute(stmt).fetchall()). - Doorloop het resultaat en printte elk afzonderlijk record.
Opmerking: Omdat we ook beperkingen voor primaire en refererende sleutels in SQLAlchemy hebben geladen, neemt de SELECT-instructie een lijst met tabelobjecten als argumenten en worden waar nodig automatisch relaties tot stand gebracht.
Het resultaat wordt weergegeven in de onderstaande afbeelding:

Python haalt alle attributen uit de tabel en slaat ze op in het object. Zoals getoond, kunnen we dit object gebruiken om extra bewerkingen uit te voeren. Het eindresultaat van onze verklaring is een lijst van alle steden uit de city tafel.
Nu zijn we klaar voor een complexere zoekopdracht. Ik heb zojuist een ORDER BY-clausule toegevoegd .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Opmerking: De asc() methode voert oplopende sortering uit op het bovenliggende object, waarbij gedefinieerde kolommen als parameters worden gebruikt.
De geretourneerde lijst is hetzelfde, maar is nu gesorteerd op de id-waarde, in oplopende volgorde. Het is belangrijk op te merken dat we simpelweg .order_by( hebben toegevoegd naar de vorige SELECT-query. De .order_by(...) methode stelt ons in staat om de volgorde van de geretourneerde resultatenset te wijzigen, op dezelfde manier als we zouden gebruiken in een SQL-query. Daarom moeten parameters de SQL-logica volgen, met kolomnamen of kolomvolgorde en ASC of DESC.
Vervolgens voegen we WAAR toe naar onze SELECT-instructie.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Opmerking: De .where() methode wordt gebruikt om een voorwaarde te testen die we als argument hebben gebruikt. We kunnen ook de .filter() . gebruiken methode, die beter is in het filteren van complexere omstandigheden.
Nogmaals, de .where deel is eenvoudig aaneengeschakeld naar onze SELECT-instructie. Merk op dat we de voorwaarde tussen haakjes hebben geplaatst. Welke voorwaarde ook tussen haakjes staat, wordt op dezelfde manier getest als in het WHERE-gedeelte van een SELECT-instructie. De gelijkheidsvoorwaarde wordt getest met ==in plaats van =.
Het laatste dat we met SELECT zullen proberen, is het samenvoegen van twee tabellen. Laten we eerst de code en het resultaat ervan bekijken.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Er zijn twee belangrijke delen in de bovenstaande verklaring:
select([table_city.columns.city_name, table_country.columns.country_name])bepaalt welke kolommen in ons resultaat worden geretourneerd..select_from(table_city.join(table_country))definieert de join-voorwaarde/tabel. Merk op dat we niet de volledige join-voorwaarde hoefden op te schrijven, inclusief de sleutels. Dit komt omdat SQLAlchemy "weet" hoe deze twee tabellen worden samengevoegd, aangezien regels voor primaire sleutels en externe sleutels op de achtergrond worden geïmporteerd.
INVOEREN / BIJWERKEN / VERWIJDEREN
Dit zijn de drie resterende DML-opdrachten die we in dit artikel zullen behandelen. Hoewel hun structuur erg complex kan worden, zijn deze commando's meestal veel eenvoudiger. De gebruikte code wordt hieronder weergegeven.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Hetzelfde patroon wordt gebruikt voor alle drie de verklaringen:de verklaring voorbereiden, afdrukken en uitvoeren, en het resultaat na elke verklaring afdrukken, zodat we kunnen zien wat er werkelijk in de database is gebeurd. Merk nogmaals op dat delen van het statement werden behandeld als objecten (.values(), .where()).

We zullen deze kennis in het komende artikel gebruiken om een volledig ETL-script te bouwen met SQLAlchemy.
Volgende:SQLAlchemy in het ETL-proces
Vandaag hebben we geanalyseerd hoe u SQLAlchemy instelt en hoe u eenvoudige DML-opdrachten uitvoert. In het volgende artikel zullen we deze kennis gebruiken om het volledige ETL-proces te schrijven met SQLAlchemy.
U kunt het volledige script, dat in dit artikel wordt gebruikt, hier downloaden.