Databases moeten optimaal draaien, maar dat is niet zo'n gemakkelijke taak. De INFORMATION SCHEMA-database kan uw geheime wapen zijn in de oorlog van database-optimalisatie.
We zijn gewend om databases te maken met behulp van een grafische interface of een reeks SQL-opdrachten. Dat is helemaal prima, maar het is ook goed om een beetje te begrijpen wat er op de achtergrond gebeurt. Dit is belangrijk voor het maken, onderhouden en optimaliseren van een database, en het is ook een goede manier om veranderingen die 'achter de schermen' plaatsvinden bij te houden.
In dit artikel zullen we een handvol SQL-query's bekijken die u kunnen helpen om in de werking van een MySQL-database te kijken.
De INFORMATION_SCHEMA-database
We hebben de INFORMATION_SCHEMA . al besproken databank in dit artikel. Als je het nog niet hebt gelezen, raad ik je zeker aan dat te doen voordat je verder gaat.
Als je een opfriscursus nodig hebt over de INFORMATION_SCHEMA database – of als u besluit het eerste artikel niet te lezen – hier zijn enkele basisfeiten die u moet weten:
- De
INFORMATION_SCHEMAdatabase maakt deel uit van de ANSI-standaard. We werken met MySQL, maar andere RDBMS'en hebben hun varianten. U kunt versies vinden voor H2 Database, HSQLDB, MariaDB, Microsoft SQL Server en PostgreSQL. - Dit is de database die alle andere databases op de server bijhoudt; we vinden hier beschrijvingen van alle objecten.
- Net als elke andere database, is de
INFORMATION_SCHEMAdatabase bevat een aantal gerelateerde tabellen en informatie over verschillende objecten. - Je kunt deze database doorzoeken met SQL en de resultaten gebruiken om:
- Bewaak de databasestatus en prestaties, en
- Automatisch code genereren op basis van zoekopdrachtresultaten.
Laten we nu verder gaan met het doorzoeken van de INFORMATION_SCHEMA-database. We beginnen met te kijken naar het datamodel dat we gaan gebruiken.
Het gegevensmodel
Het model dat we in dit artikel zullen gebruiken, wordt hieronder weergegeven.
Dit is een vereenvoudigd model waarmee we informatie over klassen, docenten, studenten en andere gerelateerde details kunnen opslaan. Laten we de tabellen kort doornemen.
We slaan de lijst met instructeurs op in de lecturer tafel. Voor elke docent nemen we een first_name op en een last_name .
De class tabel bevat alle klassen die we op onze school hebben. Voor elk record in deze tabel slaan we de class_name . op , de docent-ID, een geplande start_date en end_date , en eventuele aanvullende class_details . Voor de eenvoud ga ik ervan uit dat we maar één docent per klas hebben.
De lessen worden meestal georganiseerd als een reeks lezingen. Ze vereisen over het algemeen een of meer examens. We slaan lijsten met gerelateerde colleges en examens op in de lecture en exam tafels. Beide hebben de ID van de gerelateerde klasse en de verwachte start_time en end_time .
Nu hebben we studenten nodig voor onze lessen. Een lijst van alle studenten wordt opgeslagen in de student tafel. Nogmaals, we slaan alleen de first_name . op en de last_name van elke leerling.
Het laatste dat we moeten doen, is de activiteiten van studenten volgen. We slaan een lijst op van elke klas waarvoor een student zich heeft ingeschreven, de aanwezigheidsregistratie van de student en hun examenresultaten. Elk van de overige drie tafels – on_class , on_lecture en on_exam – heeft een verwijzing naar de student en een verwijzing naar de betreffende tabel. Alleen de on_exam tabel heeft een extra waarde:cijfer.
Ja, dit model is heel eenvoudig. We zouden nog veel meer details over studenten, docenten en klassen kunnen toevoegen. We kunnen historische waarden opslaan wanneer records worden bijgewerkt of verwijderd. Toch is dit model voldoende voor de doeleinden van dit artikel.
Een database maken
We zijn klaar om een database op onze lokale server te maken en te onderzoeken wat er binnen gebeurt. We exporteren het model (in Vertabelo) met behulp van het "Generate SQL script " knop.
Vervolgens maken we een database op de MySQL Server-instantie. Ik noemde mijn database "classes_and_students ”.
Het volgende dat we moeten doen, is een eerder gegenereerd SQL-script uitvoeren.
Nu hebben we de database met al zijn objecten (tabellen, primaire en externe sleutels, alternatieve sleutels).
Databasegrootte
Nadat het script is uitgevoerd, worden gegevens over de "classes and students ” database wordt opgeslagen in de INFORMATION_SCHEMA databank. Deze gegevens staan in veel verschillende tabellen. Ik zal ze hier niet allemaal opnieuw opsommen; dat hebben we in het vorige artikel gedaan.
Laten we eens kijken hoe we standaard SQL op deze database kunnen gebruiken. Ik zal beginnen met een zeer belangrijke vraag:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
We vragen alleen de INFORMATION_SCHEMA.TABLES tafel hier. Deze tabel zou ons meer dan genoeg details moeten geven over alle tabellen op de server. Houd er rekening mee dat ik alleen tabellen heb gefilterd uit de "classes_and_students " database met behulp van de SET variabele in de eerste regel en later met deze waarde in de query. De meeste tabellen bevatten de kolommen TABLE_NAME en TABLE_SCHEMA , die de tabel en het schema/database aangeven waartoe deze gegevens behoren.
Deze query retourneert de huidige grootte van onze database en de vrije ruimte die is gereserveerd voor onze database. Hier is het werkelijke resultaat:

Zoals verwacht is de grootte van onze lege database minder dan 1 MB, en de gereserveerde vrije ruimte is veel groter.
Tabelformaten en eigenschappen
Het volgende interessante dat u kunt doen, is kijken naar de afmetingen van de tabellen in onze database. Om dit te doen, gebruiken we de volgende zoekopdracht:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
De zoekopdracht is bijna identiek aan de vorige, met één uitzondering:het resultaat is gegroepeerd op tabelniveau.
Hier is een afbeelding van het resultaat van deze zoekopdracht:
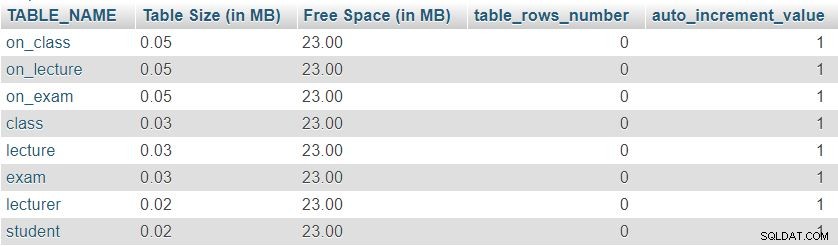
Ten eerste kunnen we zien dat alle acht tabellen een minimale “Tabelgrootte” . hebben gereserveerd voor tabeldefinitie, inclusief de kolommen, primaire sleutel en index. De “Vrije ruimte” is gelijk verdeeld over alle tafels.
We kunnen ook het aantal rijen zien dat momenteel in elke tabel staat en de huidige waarde van de auto_increment eigenschap voor elke tafel. Omdat alle tabellen volledig leeg zijn, hebben we geen gegevens en auto_increment is ingesteld op 1 (een waarde die wordt toegewezen aan de volgende ingevoegde rij).
Primaire toetsen
Elke tabel moet een primaire sleutelwaarde hebben gedefinieerd, dus het is verstandig om te controleren of dit waar is voor onze database. Een manier om dit te doen is door een lijst met alle tabellen samen te voegen met een lijst met beperkingen. Dit zou ons de informatie moeten geven die we nodig hebben.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
We hebben ook de INFORMATION_SCHEMA.COLUMNS tabel in deze query. Terwijl het eerste deel van de query simpelweg alle tabellen in de database retourneert, zal het tweede deel (na LEFT JOIN ) telt het aantal PRI's in deze tabellen. We gebruikten LEFT JOIN omdat we willen zien of een tabel 0 PRI heeft in de COLUMNS tafel.
Zoals verwacht bevat elke tabel in onze database precies één primaire sleutel (PRI)-kolom.
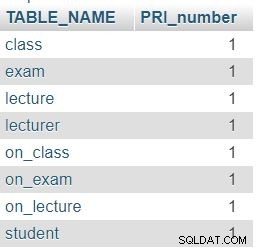
'Eilanden'?
“Eilanden” zijn tabellen die volledig gescheiden zijn van de rest van het model. Ze gebeuren wanneer een tabel geen externe sleutels bevat en er in geen enkele andere tabel naar wordt verwezen. Dit zou eigenlijk niet moeten gebeuren, tenzij er een heel goede reden is, b.v. wanneer tabellen parameters bevatten of resultaten of rapporten in het model opslaan.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Wat is het idee achter deze zoekopdracht? Welnu, we gebruiken de INFORMATION_SCHEMA.KEY_COLUMN_USAGE tabel om te testen of een kolom in de tabel een verwijzing is naar een andere tabel of dat een kolom wordt gebruikt als verwijzing in een andere tabel. Het eerste deel van de query selecteert alle tabellen. Na de eerste LEFT JOIN tellen we het aantal keren dat een kolom uit deze tabel als referentie is gebruikt. Na de tweede LEFT JOIN tellen we het aantal keren dat een kolom uit deze tabel naar een andere tabel verwijst.
Het geretourneerde resultaat is:
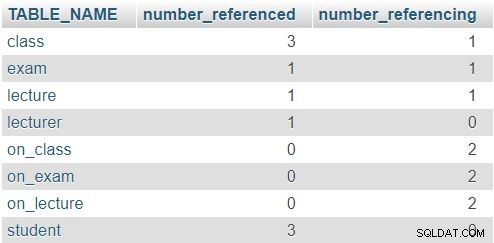
In de rij voor de class tabel, geven de nummers 3 en 1 aan dat er drie keer naar deze tabel is verwezen (in de lecture , exam , en on_class tabellen) en dat het één attribuut bevat dat verwijst naar een andere tabel (lecturer_id ). De andere tabellen volgen een soortgelijk patroon, hoewel de werkelijke aantallen natuurlijk anders zullen zijn. De regel hier is dat geen enkele rij een 0 in beide kolommen mag hebben.
Rijen toevoegen
Tot nu toe is alles verlopen zoals verwacht. We hebben ons datamodel met succes geïmporteerd van Vertabelo naar de lokale MySQL-server. Alle tabellen bevatten sleutels, precies zoals we ze willen, en alle tabellen zijn aan elkaar gerelateerd - er zijn geen "eilanden" in ons model.
Nu zullen we enkele rijen in onze tabellen invoegen en de eerder gedemonstreerde zoekopdrachten gebruiken om de wijzigingen in onze database bij te houden.
Nadat we 1.000 rijen hebben toegevoegd aan de docententabel, zullen we de query opnieuw uitvoeren vanuit de "Table Sizes and Properties " sectie. Het geeft het volgende resultaat:
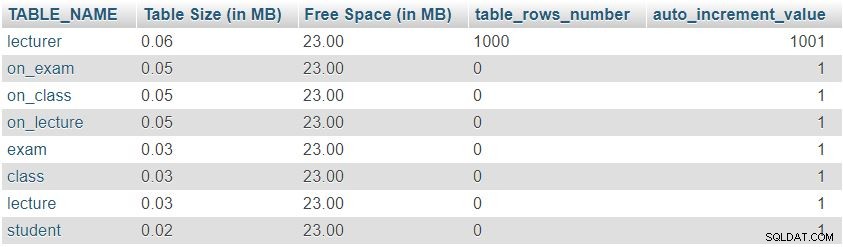
We kunnen gemakkelijk zien dat het aantal rijen en auto_increment-waarden zijn gewijzigd zoals verwacht, maar er was geen significante verandering in de tabelgrootte.
Dit was slechts een testvoorbeeld; in echte situaties zouden we significante veranderingen opmerken. Het aantal rijen zal drastisch veranderen in tabellen die worden gevuld door gebruikers of geautomatiseerde processen (d.w.z. tabellen die geen woordenboeken zijn). Het controleren van de grootte van en waarden in dergelijke tabellen is een zeer goede manier om snel ongewenst gedrag te vinden en te corrigeren.
Wil je delen?
Werken met databases is een constant streven naar optimale prestaties. Om in dat streven meer succes te hebben, moet u elk beschikbaar hulpmiddel gebruiken. Vandaag hebben we een paar vragen gezien die nuttig zijn in onze strijd voor betere prestaties. Heb je nog iets nuttigs gevonden? Heb je gespeeld met de INFORMATION_SCHEMA databank voor? Deel uw ervaring in de opmerkingen hieronder.