MySQL-replicatie is de meest gebruikte en meest gebruikte oplossing voor hoge beschikbaarheid door grote organisaties zoals Github, Twitter en Facebook. Hoewel eenvoudig te installeren, zijn er uitdagingen bij het gebruik van deze oplossing van onderhoud, waaronder software-upgrades, gegevensdrift of gegevensinconsistentie over de replicaknooppunten, topologiewijzigingen, failover en herstel. Toen MySQL versie 5.6 uitbracht, bracht het een aantal belangrijke verbeteringen met zich mee, vooral voor replicatie, waaronder Global Transaction ID's (GTID's), event checksums, multi-threaded slaves en crash-safe slaves/masters. Replicatie werd nog beter met MySQL 5.7 en MySQL 8.0.
Replicatie maakt het mogelijk om gegevens van één MySQL-server (de primaire/master) te repliceren naar een of meer MySQL-servers (de replica/slaves). MySQL-replicatie is zeer eenvoudig in te stellen en wordt gebruikt om leesworkloads uit te schalen, hoge beschikbaarheid en geografische redundantie te bieden, en back-ups en analysetaken te ontlasten.
MySQL-replicatie in de natuur
Laten we een kort overzicht geven van hoe MySQL-replicatie in de natuur werkt. MySQL-replicatie is breed en er zijn meerdere manieren om het te configureren en te gebruiken. Standaard gebruikt het asynchrone replicatie, wat werkt als de transactie wordt voltooid in de lokale omgeving. Er is geen garantie dat een gebeurtenis ooit een slaaf zal bereiken. Het is een losjes gekoppelde meester-slaafrelatie, waarbij:
-
Primary wacht niet op een replica.
-
Replica bepaalt hoeveel te lezen en vanaf welk punt in het binaire logboek.
-
Replica kan willekeurig achterlopen bij het lezen of toepassen van wijzigingen.
Als de primaire crasht, zijn de transacties die deze heeft doorgevoerd mogelijk niet naar een replica verzonden. Bijgevolg kan een failover van de primaire naar de meest geavanceerde replica in dit geval resulteren in een failover naar de gewenste primaire die in feite transacties mist ten opzichte van de vorige server.
Asynchrone replicatie zorgt voor een lagere schrijflatentie omdat een schrijfbewerking lokaal wordt bevestigd door een master voordat deze naar slaves wordt geschreven. Het is geweldig voor leesschalen, omdat het toevoegen van meer replica's geen invloed heeft op de replicatielatentie. Goede use-cases voor asynchrone replicatie zijn onder meer de implementatie van leesreplica's voor leesschaling, live back-upkopieën voor noodherstel en analyse/rapportage.
MySQL semi-synchrone replicatie
MySQL ondersteunt ook semi-synchrone replicatie, waarbij de master transacties pas aan de client bevestigt als ten minste één slave de wijziging naar zijn relaislogboek heeft gekopieerd en naar schijf heeft gewist. Om semi-synchrone replicatie in te schakelen, zijn extra stappen voor de installatie van plug-ins vereist en moeten deze worden ingeschakeld op de aangewezen MySQL-master- en slave-knooppunten.
Semi-synchroon lijkt een goede en praktische oplossing voor veel gevallen waarin hoge beschikbaarheid en geen gegevensverlies belangrijk zijn. Maar u moet er rekening mee houden dat semi-synchroon een prestatie-impact heeft vanwege de extra retour en geen sterke garanties biedt tegen gegevensverlies. Wanneer een commit succesvol terugkeert, is het bekend dat de data op ten minste twee plaatsen bestaat (op de master en ten minste één slave). Als de master een commit doet maar er een crash optreedt terwijl de master wacht op bevestiging van een slave, is het mogelijk dat de transactie geen enkele slave heeft bereikt. Dit is niet zo'n groot probleem, aangezien de commit in dit geval niet wordt teruggestuurd naar de toepassing. Het is de taak van de applicatie om de transactie in de toekomst opnieuw te proberen. Wat essentieel is om in gedachten te houden is dat wanneer de master faalt en een slaaf is gepromoveerd, de oude master niet kan deelnemen aan de replicatieketen. Onder bepaalde omstandigheden kan dit leiden tot conflicten met gegevens op de slaves, d.w.z. wanneer de master crashte nadat de slave de binaire loggebeurtenis had ontvangen, maar voordat de master de bevestiging van de slave kreeg). De enige veilige manier is dus om de gegevens op de oude master te verwijderen en deze helemaal opnieuw in te richten met behulp van de gegevens van de nieuw gepromoveerde master.
Het replicatieformaat onjuist gebruiken
Sinds MySQL 5.7.7 gebruikt de standaard binaire log-indeling of binlog_format variabele ROW, wat STATEMENT was vóór 5.7.7. De verschillende replicatie-indelingen komen overeen met de methode die wordt gebruikt om de binaire logboekgebeurtenissen van de bron vast te leggen. Replicatie werkt omdat gebeurtenissen die naar het binaire logboek worden geschreven, van de bron worden gelezen en vervolgens op de replica worden verwerkt. De gebeurtenissen worden vastgelegd in het binaire logboek in verschillende replicatie-indelingen, afhankelijk van het type gebeurtenis. Als u niet zeker weet wat u moet gebruiken, kan dit een probleem zijn. MySQL heeft drie formaten van replicatiemethoden:STATEMENT, ROW en MIXED.
-
De op STATEMENT gebaseerde replicatie (SBR)-indeling is precies wat het is:een replicatiestroom van elke uitvoering van een instructie op de master die wordt afgespeeld op de slave-node. Standaard voert MySQL traditionele (asynchrone) replicatie de gerepliceerde transacties naar de slaven niet parallel uit. Dat betekent dat de volgorde van de instructies in de replicatiestroom mogelijk niet 100% hetzelfde is. Ook kan het opnieuw afspelen van een instructie andere resultaten opleveren wanneer deze niet op hetzelfde moment worden uitgevoerd als wanneer deze vanaf de bron worden uitgevoerd. Dit leidt tot een inconsistente toestand ten opzichte van de primaire en zijn replica('s). Dit was jarenlang geen probleem, omdat niet veel MySQL met veel gelijktijdige threads draaiden. Met moderne multi-CPU-architecturen is dit echter zeer waarschijnlijk geworden bij een normale dagelijkse werklast.
-
Het ROW-replicatieformaat biedt oplossingen die de SBR niet heeft. Bij gebruik van op rij gebaseerde replicatie (RBR) logboekindeling, schrijft de bron gebeurtenissen naar het binaire logboek die aangeven hoe afzonderlijke tabelrijen worden gewijzigd. Replicatie van de bron naar de replica werkt door de gebeurtenissen die de wijzigingen in de tabelrijen vertegenwoordigen naar de replica te kopiëren. Dit betekent dat er meer gegevens kunnen worden gegenereerd, wat van invloed is op de schijfruimte in de replica en op het netwerkverkeer en de schijf-I/O. Overweeg of een instructie veel rijen verandert, laten we zeggen met een UPDATE-instructie, RBR schrijft meer gegevens naar het binaire logboek, zelfs voor instructies die worden teruggedraaid. Het uitvoeren van momentopnames kan ook meer tijd in beslag nemen. Er kunnen gelijktijdigheidsproblemen optreden gezien de vergrendelingstijden die nodig zijn om grote hoeveelheden gegevens naar het binaire logboek te schrijven.
-
Dan is er een methode tussen deze twee; mixed-mode replicatie. Dit type replicatie repliceert altijd instructies, behalve wanneer de query de UUID()-functie, triggers, opgeslagen procedures, UDF's en enkele andere uitzonderingen bevat. Gemengde modus lost het probleem van gegevensdrift niet op en moet, samen met op verklaringen gebaseerde replicatie, worden vermeden.
Van plan om een Multi-Master setup te hebben?
Circulaire replicatie (ook bekend als ringtopologie) is een bekende en veelgebruikte configuratie voor MySQL-replicatie. Het wordt gebruikt voor het draaien van een multi-master setup (zie onderstaande afbeelding) en is vaak nodig als je een multi-datacenter omgeving hebt. Omdat de applicatie niet kan wachten tot de master in het andere datacenter de schrijfbewerkingen bevestigt, heeft een lokale master de voorkeur. Normaal gesproken wordt de auto-increment offset gebruikt om dataconflicten tussen de masters te voorkomen. Twee masters op deze manier naar elkaar laten schrijven is een breed geaccepteerde oplossing.
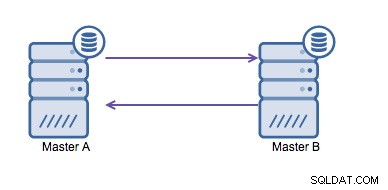
Als u echter in meerdere datacenters naar dezelfde database moet schrijven , krijg je meerdere masters die hun gegevens naar elkaar moeten schrijven. Vóór MySQL 5.7.6 was er geen methode om een mesh-type replicatie uit te voeren, dus het alternatief zou zijn om in plaats daarvan een circulaire ringreplicatie te gebruiken.
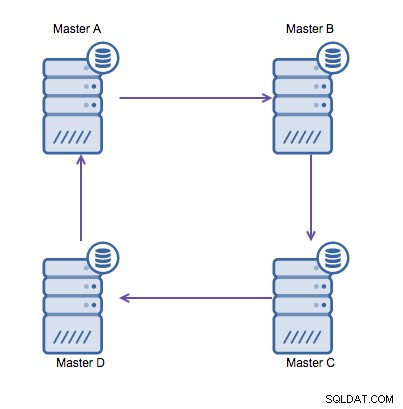
Ringreplicatie in MySQL is om de volgende redenen problematisch:latentie, hoge beschikbaarheid , en gegevensdrift. Het schrijven van sommige gegevens naar server A zou drie hops vergen om op server D te eindigen (via server B en C). Aangezien (traditionele) MySQL-replicatie single-threaded is, kan elke langlopende query in de replicatie de hele ring blokkeren. Als een van de servers uitvalt, zou de ring worden verbroken en momenteel kan geen enkele failover-software ringstructuren repareren. Dan kan er data drift optreden wanneer data naar server A wordt geschreven en tegelijkertijd op server C of D wordt gewijzigd.
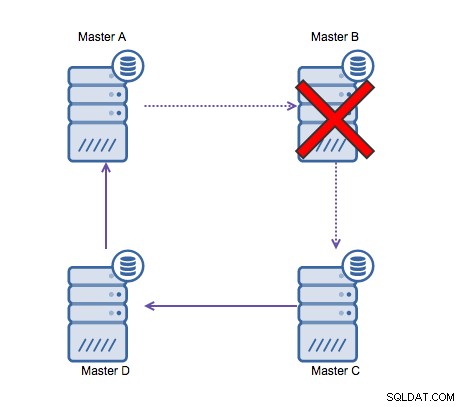
Over het algemeen past circulaire replicatie niet goed bij MySQL en zou koste wat het kost vermeden. Omdat het met dat in gedachten is ontworpen, zou Galera Cluster een goed alternatief zijn voor schrijven in meerdere datacenters.
Uw replicatie stoppen met grote updates
Verschillende huishoudelijke batchtaken voeren vaak verschillende taken uit, variërend van het opschonen van oude gegevens tot het berekenen van gemiddelden van 'vind-ik-leuks' opgehaald uit een andere bron. Dit betekent dat een taak met vaste tussenpozen veel database-activiteit zal creëren en, hoogstwaarschijnlijk, veel gegevens terug zal schrijven naar de database. Dit betekent natuurlijk dat de activiteit binnen de replicatiestroom gelijk zal toenemen.
Replicatie op basis van een statement repliceert de exacte query's die in de batchtaken worden gebruikt, dus als de query een half uur zou duren om te verwerken op de master, zou de slave-thread worden geblokkeerd voor ten minste hetzelfde aantal tijd. Dit betekent dat er geen andere gegevens kunnen worden gerepliceerd en dat de slave-knooppunten achterblijven bij de master. Als dit de drempelwaarde van uw failover-tool of proxy overschrijdt, kunnen deze slave-knooppunten worden verwijderd van de beschikbare servers in het cluster. Als u replicatie op basis van instructies gebruikt, kunt u dit voorkomen door de gegevens voor uw taak in kleinere batches te verwerken.
Je denkt misschien dat op rijen gebaseerde replicatie hierdoor niet wordt beïnvloed, omdat het de rij-informatie repliceert in plaats van de query. Dit is gedeeltelijk waar, omdat voor DDL-wijzigingen de replicatie terugkeert naar een op instructies gebaseerd formaat. Ook zullen grote aantallen CRUD-bewerkingen (Create, Read, Update, Delete) de replicatiestroom beïnvloeden. In de meeste gevallen is dit nog steeds een single-thread-bewerking, en dus wacht elke transactie tot de vorige opnieuw wordt afgespeeld via replicatie. Dit betekent dat als u een hoge mate van gelijktijdigheid met de master hebt, de slave tijdens de replicatie kan vastlopen op de overbelasting van transacties.
Om dit te omzeilen, bieden zowel MariaDB als MySQL parallelle replicatie. De implementatie kan per leverancier en versie verschillen. MySQL 5.6 biedt parallelle replicatie zolang de query's worden gescheiden door het schema. MariaDB 10.0 en MySQL 5.7 kunnen beide parallelle replicatie over schema's heen aan, maar hebben andere grenzen. Het uitvoeren van query's via parallelle slave-threads kan uw replicatiestroom versnellen als u zwaar schrijft. Anders zou het beter zijn om vast te houden aan de traditionele single-thread replicatie.
Uw schemawijziging of DDL's afhandelen
Sinds de release van 5.7 is het beheer van de schemawijziging of DDL-wijziging (Data Definition Language) in MySQL aanzienlijk verbeterd. Tot MySQL 8.0 zijn de ondersteunde DDL-wijzigingsalgoritmen COPY en INPLACE.
-
KOPIE:Dit algoritme maakt een nieuwe tijdelijke tabel met het gewijzigde schema. Zodra de gegevens volledig naar de nieuwe tijdelijke tabel zijn gemigreerd, wordt de oude tabel verwisseld en verwijderd.
-
INPLACE:Dit algoritme voert bewerkingen uit op de originele tabel en vermijdt het kopiëren en opnieuw opbouwen van de tabel waar mogelijk.
-
INSTANT:dit algoritme is geïntroduceerd sinds MySQL 8.0, maar heeft nog steeds beperkingen.
In MySQL 8.0 is het algoritme INSTANT geïntroduceerd, waardoor onmiddellijke en in-place tabelwijzigingen worden aangebracht voor het toevoegen van kolommen en gelijktijdige DML mogelijk is met verbeterde responsiviteit en beschikbaarheid in drukke productieomgevingen. Dit helpt enorme vertragingen en haperingen in de replica te voorkomen, wat meestal grote problemen waren in het applicatieperspectief, waardoor verouderde gegevens werden opgehaald omdat de uitlezingen in de slave nog niet zijn bijgewerkt vanwege vertraging.
Hoewel dat een veelbelovende verbetering is, zijn er nog steeds beperkingen aan en soms is het niet mogelijk om die INSTANT- en INPLACE-algoritmen toe te passen. Voor bijvoorbeeld INSTANT- en INPLACE-algoritmen is het wijzigen van het gegevenstype van een kolom ook een gebruikelijke DBA-taak, vooral in het perspectief van applicatieontwikkeling als gevolg van gegevensverandering. Deze gelegenheden zijn onvermijdelijk; je kunt dus niet doorgaan met het COPY-algoritme, omdat dit de tafel vergrendelt, wat vertragingen in de slave veroorzaakt. Het heeft ook invloed op de primaire/masterserver tijdens deze uitvoering, omdat het inkomende transacties opstapelt die ook verwijzen naar de betreffende tabel. U kunt geen directe ALTER- of schemawijziging uitvoeren op een drukke server, omdat dit gepaard gaat met downtime of mogelijk uw database corrumpeert als u uw geduld verliest, vooral als de doeltabel enorm is.
Het is waar dat het uitvoeren van schemawijzigingen op een draaiende productie-installatie altijd een uitdagende taak is. Een veelgebruikte oplossing is om de schemawijziging eerst op de slave-knooppunten toe te passen. Dit werkt prima voor replicatie op basis van instructies, maar dit kan slechts tot op zekere hoogte werken voor replicatie op basis van rijen. Op rijen gebaseerde replicatie zorgt ervoor dat er extra kolommen aan het einde van de tabel kunnen staan, dus zolang het de eerste kolommen kan schrijven, komt het goed. Pas eerst de wijziging toe op alle slaven, pas vervolgens de wijziging toe op een van de slaven en pas vervolgens de wijziging toe op de master en koppel die als een slave. Als uw wijziging betrekking heeft op het invoegen van een kolom in het midden of het verwijderen van een kolom, werkt dit met op rijen gebaseerde replicatie.
Er zijn tools beschikbaar waarmee online schemawijzigingen betrouwbaarder kunnen worden uitgevoerd. De Percona Online Schema Change (ook bekend als pt-osc) en gh-ost van Schlomi Noach worden vaak gebruikt door DBA's. Deze tools gaan effectief om met schemawijzigingen door de betrokken rijen in chunks te groeperen, en deze chunks kunnen dienovereenkomstig worden geconfigureerd, afhankelijk van het aantal dat u wilt groeperen.
Als je met pt-osc gaat springen, zal deze tool een schaduwtabel maken met de nieuwe tabelstructuur, nieuwe gegevens invoegen via triggers en gegevens aanvullen op de achtergrond. Zodra het klaar is met het maken van de nieuwe tafel, zal het gewoon de oude voor de nieuwe tafel verwisselen binnen een transactie. Dit werkt niet in alle gevallen, vooral als je bestaande tafel al triggers heeft.
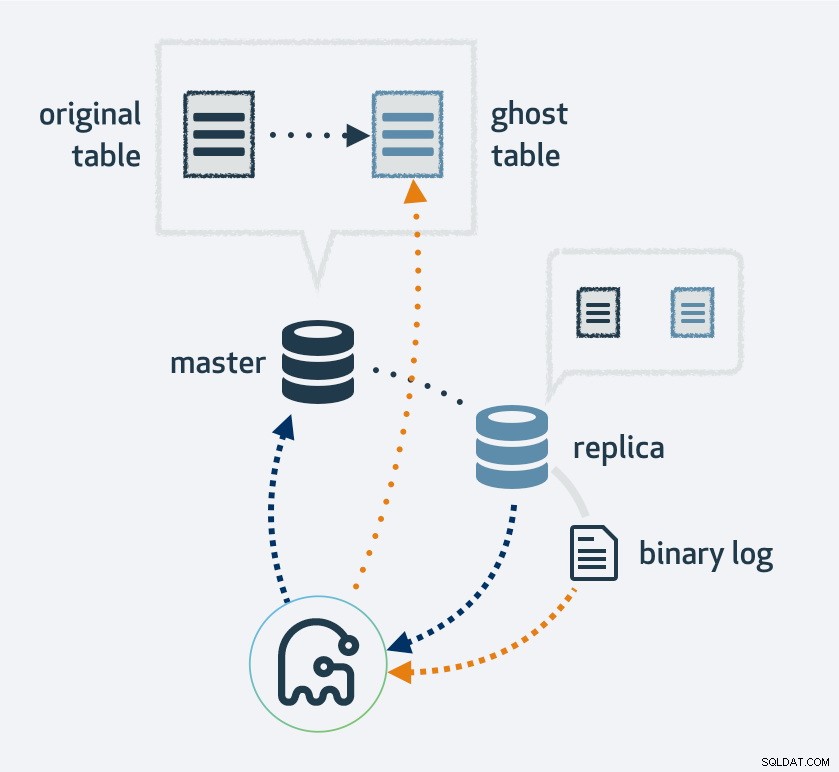
Als u gh-ost gebruikt, wordt er eerst een kopie gemaakt van uw bestaande tabellay-out, verander de tabel naar de nieuwe lay-out en sluit het proces vervolgens aan als een MySQL-replica. Het gebruikt de replicatiestroom om nieuwe rijen te vinden die in de oorspronkelijke tabel zijn ingevoegd en vult tegelijkertijd de tabel aan. Zodra het aanvullen is voltooid, wisselen de originele en nieuwe tabellen. Uiteraard komen alle bewerkingen naar de nieuwe tabel in de replicatiestroom terecht; dus op elke replica vindt de migratie gelijktijdig plaats.
Geheugentabellen en replicatie
Terwijl we het over DDL's hebben, is een veelvoorkomend probleem het maken van geheugentabellen. Geheugentabellen zijn niet-permanente tabellen, hun tabelstructuur blijft behouden, maar ze verliezen hun gegevens na een herstart van MySQL. Bij het maken van een nieuwe geheugentabel op zowel een master als een slave, hebben ze een lege tabel, wat prima zal werken. Zodra een van beide opnieuw is opgestart, wordt de tafel geleegd en treden er replicatiefouten op.
Replicatie op basis van rijen wordt afgebroken zodra de gegevens in de slave-node andere resultaten opleveren, en replicatie op basis van instructies wordt verbroken zodra wordt geprobeerd gegevens in te voegen die al bestaan. Voor geheugentabellen is dit een frequente replicatiebreker. De oplossing is eenvoudig:maak een nieuwe kopie van de gegevens, verander de engine in InnoDB en het zou nu replicatieveilig moeten zijn.
De read_only={True|1}
instellenDit is natuurlijk een mogelijk geval wanneer u een ringtopologie gebruikt, en we raden het gebruik van ringtopologie indien mogelijk af. We hebben eerder beschreven dat het niet hebben van dezelfde gegevens in de slave-knooppunten de replicatie kan verbreken. Vaak wordt dit veroorzaakt doordat iets (of iemand) de gegevens op het slaveknooppunt wijzigt, maar niet op het masterknooppunt. Zodra de gegevens van het masterknooppunt zijn gewijzigd, wordt dit gerepliceerd naar de slave waar het de wijziging niet kan toepassen, waardoor de replicatie wordt verbroken. Dit kan ook leiden tot datacorruptie op clusterniveau, vooral als de slave is gepromoveerd of is mislukt vanwege een crash. Dat kan een ramp zijn.
Een gemakkelijke manier om dit te voorkomen is ervoor te zorgen dat alleen-lezen en super_lezen_alleen (alleen op> 5.6) zijn ingesteld op AAN of 1. Je hebt misschien begrepen hoe deze twee variabelen verschillen en hoe dit van invloed is op het in- of uitschakelen hen. Met super_read_only (sinds MySQL 5.7.8) uitgeschakeld, kan de rootgebruiker eventuele wijzigingen in het doel of de replica voorkomen. Dus als beide zijn uitgeschakeld, kan niemand wijzigingen in de gegevens aanbrengen, behalve de replicatie. De meeste failovermanagers, zoals ClusterControl, stellen deze vlag automatisch in om te voorkomen dat gebruikers tijdens de failover naar de gebruikte master schrijven. Sommigen van hen behouden dit zelfs na de failover.
GTID inschakelen
In MySQL-replicatie is het essentieel om de slave vanaf de juiste positie in de binaire logs te starten. Het verkrijgen van deze positie kan worden gedaan wanneer u een back-up maakt (xtrabackup en mysqldump ondersteunen dit) of wanneer u bent gestopt met zwoegen op een node waarvan u een kopie maakt. Het starten van de replicatie met de opdracht CHANGE MASTER TO ziet er als volgt uit:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Het starten van replicatie op de verkeerde plek kan rampzalige gevolgen hebben:gegevens kunnen dubbel worden geschreven of niet worden bijgewerkt. Dit veroorzaakt data drift tussen de master en de slave node.
Als je een master niet naar een slave overzet, moet je de juiste positie vinden en de master wijzigen in de juiste host. MySQL bewaart de binaire logs en posities van zijn master niet, maar creëert in plaats daarvan zijn eigen binaire logs en posities. Dit kan een serieus probleem worden bij het opnieuw uitlijnen van een slave-knooppunt op de nieuwe master. De exacte positie van de master bij failover moet worden gevonden op de nieuwe master, en dan kunnen alle slaves opnieuw worden uitgelijnd.
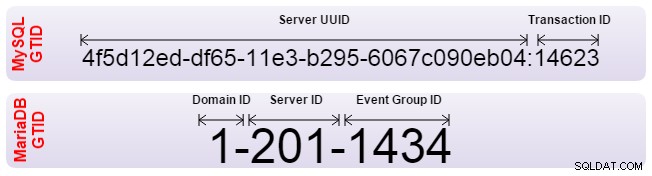
Zowel Oracle MySQL als MariaDB hebben de Global Transaction Identifier (GTID) geïmplementeerd om dit probleem oplossen. Met GTID's kunnen slaves automatisch worden uitgelijnd en de server bepaalt zelf wat de juiste positie is. Beide hebben de GTID echter anders geïmplementeerd en zijn daarom incompatibel. Als u replicatie van de ene naar de andere moet instellen, moet de replicatie worden ingesteld met traditionele binaire logpositionering. Uw failover-software moet er ook op worden gewezen dat er geen GTID's worden gebruikt.
Crash-veilige slaaf
Crash safe betekent dat zelfs als een slave MySQL/OS crasht, je de slave kunt herstellen en doorgaan met replicatie zonder MySQL-databases op de slave te herstellen. Om een crash-veilige slaaf te laten werken, hoeft u alleen de InnoDB-opslagengine te gebruiken, en in 5.6 moet u relay_log_info_repository=TABLE en relay_log_recovery=1 instellen.
Conclusie
Oefening baart kunst, maar zonder de juiste training en kennis van deze essentiële technieken kan dit lastig zijn of tot een ramp leiden. Deze praktijken worden vaak gevolgd door experts in MySQL en worden door grote industrieën aangepast als onderdeel van hun dagelijkse routinetaak bij het beheren van de MySQL-replicatie in de productiedatabaseservers.
Als je meer wilt lezen over MySQL-replicatie, bekijk dan deze tutorial over MySQL-replicatie voor hoge beschikbaarheid.
Volg ons op Twitter en LinkedIn en abonneer u op onze nieuwsbrief voor meer updates over databasebeheeroplossingen en best practices voor uw open-sourcedatabases.