
SQL Server-indexen worden gebruikt om gegevens sneller op te halen en knelpunten die van invloed zijn op kritieke bronnen te verminderen. Indexen in een databasetabel dienen als techniek voor prestatieoptimalisatie. U vraagt zich misschien af:hoe verhogen indexen de queryprestaties? Bestaan er zoiets als goede en slechte indexen? Stel dat je een tabel hebt met 50 kolommen, is het dan een goed idee om indexen te maken op elk van de kolommen? Als we meerdere indexen maken, helpt dit dan om SQL-query's sneller te laten verlopen?
Allemaal geweldige vragen, maar voordat we erin duiken, is het essentieel om te weten waarom indexen überhaupt nodig zijn.
Stel je voor dat je een stadsbibliotheek bezoekt met een collectie van duizenden boeken. Je bent op zoek naar een specifiek boek, maar hoe vind je het? Als je door elk boek zou gaan, in elk rek, zou het dagen kunnen duren om het te vinden. Hetzelfde geldt voor een database wanneer u een record zoekt uit de miljoenen rijen die in een tabel zijn opgeslagen.
Een SQL Server-index heeft de vorm van een B-Tree-indeling die bestaat uit een hoofdknooppunt bovenaan en een bladknooppunt onderaan. Voor ons voorbeeld van bibliotheekboeken geeft een gebruiker een zoekopdracht uit om een boek met ID 391 te zoeken. In dit geval begint de query-engine te navigeren vanaf het hoofdknooppunt en gaat naar het bladknooppunt.
Hoofdknooppunt –> Tussenknooppunt –> Bladknooppunt.
De query-engine zoekt naar de referentiepagina op het tussenliggende niveau. In dit voorbeeld bestaat het eerste tussenknooppunt uit boek-ID's van 1-500 en het tweede tussenliggende knooppunt uit 501-1000.
Op basis van het tussenknooppunt doorloopt de query-engine de B-Tree om naar het bijbehorende tussenknooppunt en het bladknooppunt te zoeken. Dit bladknooppunt kan bestaan uit actuele gegevens of verwijzen naar de actuele gegevenspagina op basis van het indextype. In de onderstaande afbeelding zien we hoe u de index kunt doorkruisen om naar gegevens te zoeken met behulp van SQL Server-indexen. In dit geval hoeft SQL Server niet elke pagina te doorlopen, deze te lezen en te zoeken naar een specifieke boek-ID-inhoud.
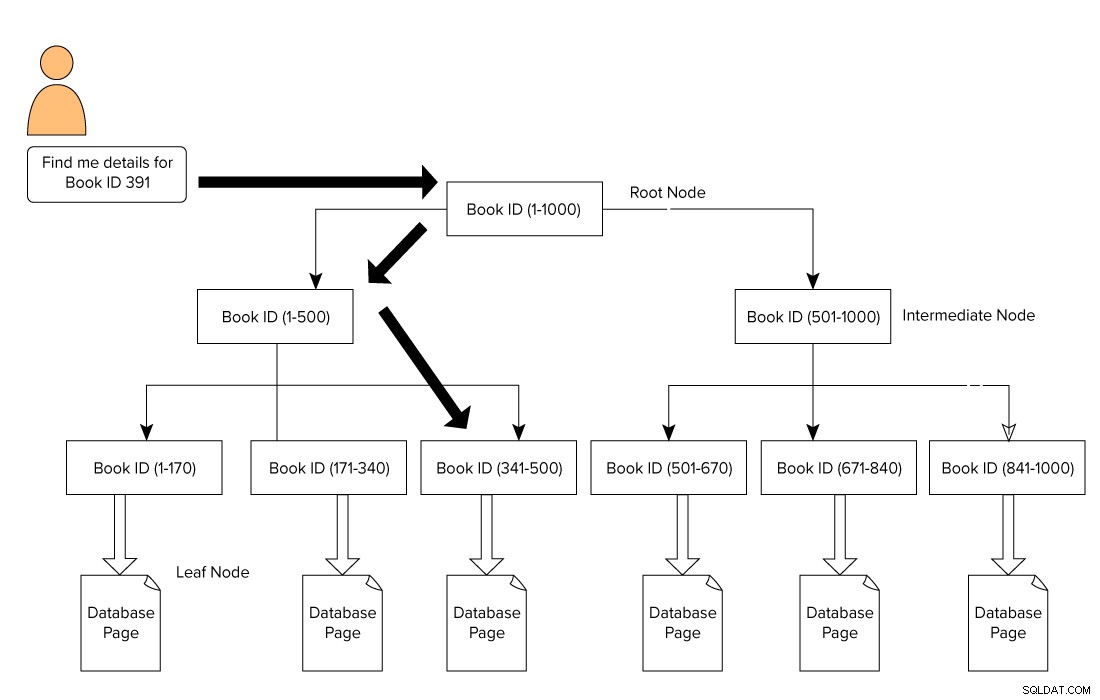
Invloeden van indexen op de prestaties van SQL Server
In het vorige bibliotheekvoorbeeld hebben we de mogelijke impact op de indexprestaties onderzocht. Laten we eens kijken naar de queryprestaties met en zonder index.
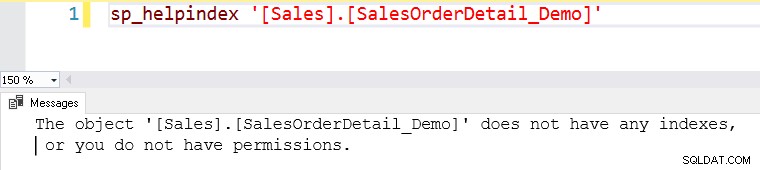
Stel dat we gegevens nodig hebben voor de [SalesOrderID] 56958 uit de [SalesOrderDetail_Demo]-tabel.
SELECTEER *
VAN [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
waar SalesOrderID=56958
Deze tabel heeft geen indexen. Een tabel zonder indexen wordt in SQL Server een heaptabel genoemd.
Vanaf hier wilt u de bovenstaande select-instructie uitvoeren en het daadwerkelijke uitvoeringsplan bekijken. Deze tabel bevat 121317 records. Het voert een tabelscan uit, wat betekent dat het alle rijen in een tabel leest om de specifieke [SalesOrderID] te vinden.
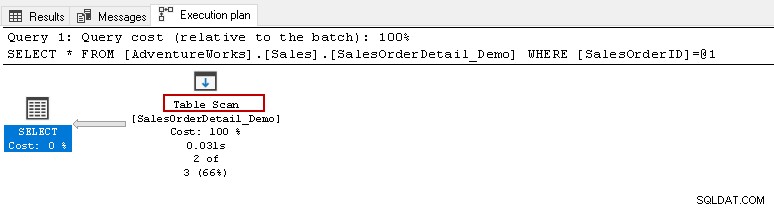
Als u met uw cursor over het pictogram Tabelscan beweegt, ziet u dat de werkelijke resultatenset 2 rijen bevat, maar voor dit doel worden alle rijen in die tabel gelezen.
- Aantal gelezen rijen:121317
- Het werkelijke aantal rijen voor de uitvoering:2
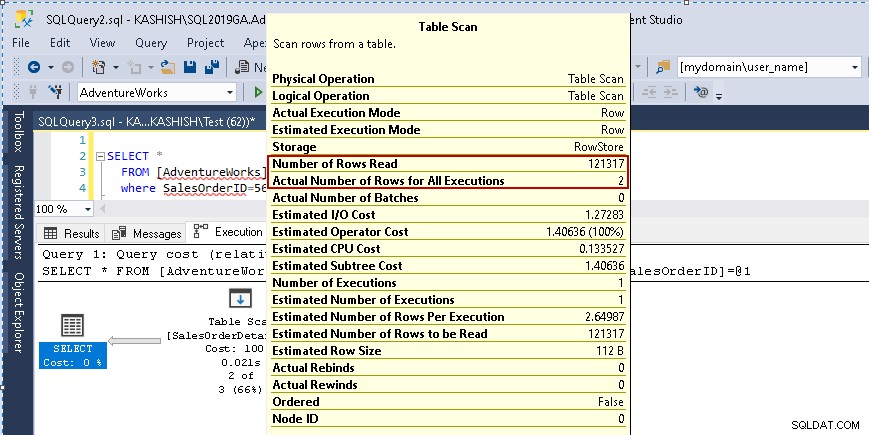
Denk nu aan een tabel met miljoenen of miljarden rijen. Het is geen goede gewoonte om alle records in de tabel te doorlopen om een paar rijen te filteren. In een uitgebreid databasesysteem voor online transactieverwerking (OLTP) gebruikt het serverbronnen (CPU, IO, geheugen) niet effectief, waardoor de gebruiker prestatieproblemen kan krijgen.
Laten we nu de bovenstaande select-instructie uitvoeren met de tabel met indexen. Deze tabel heeft een geclusterde primaire sleutelindex en twee niet-geclusterde indexen op de kolommen [ProductID] en [rowguid]. We zullen het later hebben over de verschillende soorten indexen in SQL Server.
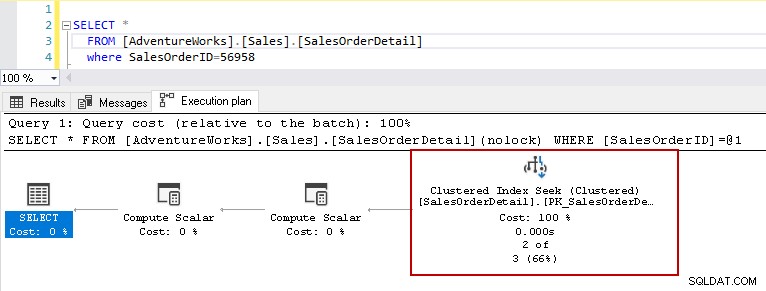
Als u nu de select-instructie met hetzelfde predikaat opnieuw uitvoert, toont het uitvoeringsplan het prestatieprobleem. Query-optimalisatie besluit om geclusterde indexzoekactie te gebruiken in plaats van een geclusterde indexscan.
In de zoekdetails van de geclusterde index laat het zien dat de query-optimizer precies de rijen leest die het in de uitvoer heeft gegeven.
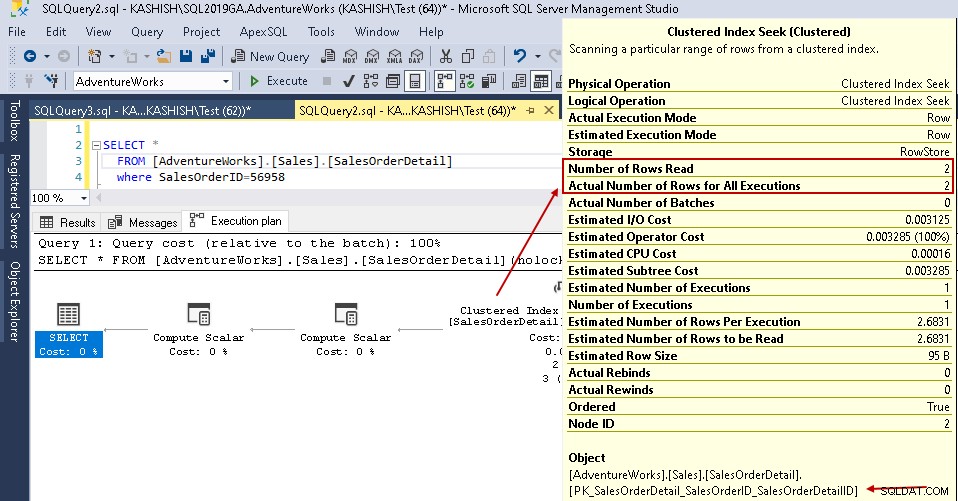
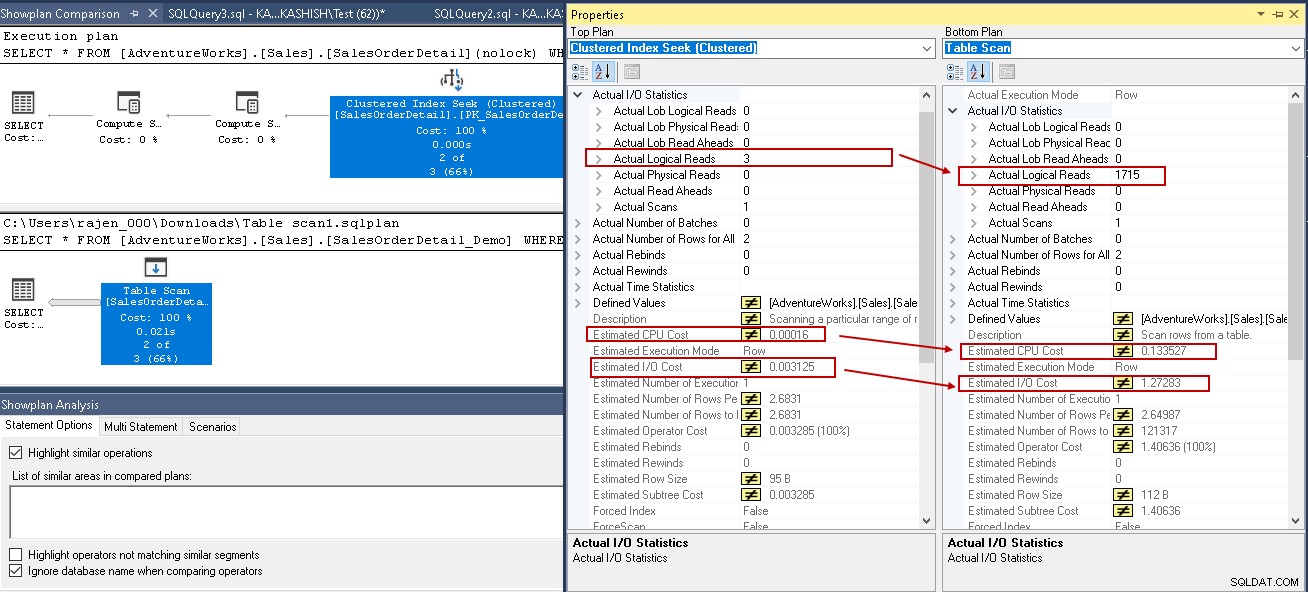
Om u een vergelijkende analyse te geven, vergelijken we het uitvoeringsplan met en zonder SQL Server-index. U kunt verwijzen naar het artikel How to Compare Query-uitvoeringsplannen van SQL Shack in het artikel SQL Server 2016 voor meer inzichten.
Kijk voor dit voorbeeld naar de gemarkeerde waarden in de geclusterde indexzoek- en tabelscan:
- Logische leesbewerkingen:SQL Server-database-engine leest een pagina uit de buffercache en veroorzaakt een logische leesbewerking. Hieronder zien we dat logische waarden worden teruggebracht van 1715 naar 3 zodra u de index hebt gemaakt.
- Geschatte CPU-kosten dalen ook van 0,133527 naar 0,00016
- Geschatte IO-kosten dalen van 1.27283 naar 0.003125
De onderstaande afbeelding laat het verschil zien tussen een tabelscan en een indexzoekopdracht.
Goede (nuttige) indexen en slechte indexen in SQL Server
Zoals de naam al doet vermoeden, verbetert een goede index de queryprestaties en minimaliseert het resourcegebruik. Kan een index de prestaties van query's in SQL Server verminderen? Soms creëren we de index op een specifieke kolom, maar deze wordt nooit gebruikt. Stel je hebt een index op een kolom en je voert veel invoegingen en updates voor die kolom uit. Voor elke update is ook de bijbehorende indexupdate vereist. Als uw werk belasting meer schrijfactiviteit heeft en u veel indexen op een kolom hebt, zou dit de algehele prestaties van uw query's vertragen. Een ongebruikte index kan ook leiden tot trage prestaties voor geselecteerde instructies. De query-optimizer gebruikt statistieken om een uitvoeringsplan op te stellen. Het leest alle indexen en hun gegevenssampling en op basis daarvan bouwt het een geoptimaliseerd plan voor het uitvoeren van query's. U kunt uw indexgebruik volgen met behulp van de dynamische beheerweergave sys.dm_db_index_usage_stats en de bronnen controleren, zoals gebruikersscan, de gebruikerszoekopdracht en gebruikerszoekopdrachten.
SQL Server-indextypen en overwegingen
SQL Server heeft twee hoofdindexen:geclusterde en niet-geclusterde indexen. Een geclusterde index slaat de feitelijke gegevens op in het bladknooppunt van de index. Het sorteert de gegevens fysiek binnen de gegevenspagina's op basis van de geclusterde indexsleutel. SQL Server staat één geclusterde index per tabel toe. U kunt meerdere kolommen samenvoegen om een geclusterde indexsleutel te bouwen. Een niet-geclusterde index is een logische index en heeft de indexsleutelkolom die verwijst naar de geclusterde indexsleutel.
We kunnen ook andere indexen in SQL Server hebben, zoals XML-index, column store-index, ruimtelijke index, full-text index, hash-index, enz.
U moet rekening houden met de volgende punten voordat u een index in SQL Server bouwt:
- Werklast
- De kolom waarop de index vereist is
- Tabelformaat
- Oplopende of aflopende volgorde van kolomgegevens
- Kolomvolgorde
- Indextype
- Vulfactor, padindex en TempDB-sorteervolgorde
SQL Server-indexvoordelen, implicaties en aanbevelingen
Indexen in een database kunnen een tweesnijdend zwaard zijn. Een handige SQL Server-index verbetert de query- en systeemprestaties zonder de andere query's te beïnvloeden. Aan de andere kant, als u een index maakt zonder enige voorbereiding of overweging, kan dit prestatieverlies veroorzaken, het ophalen van gegevens vertragen en meer kritieke bronnen zoals CPU, IO en geheugen verbruiken. Indexen vergroten ook uw database-onderhoudstaken. Met deze factoren in gedachten, is het altijd het beste om een geschikte index te testen in een pre-productieomgeving met de productie-equivalente werkbelasting, vervolgens de prestaties te analyseren en te beslissen of het het beste is om deze in een productiedatabase te implementeren. Er zijn nog veel meer aanbevelingen om rekening mee te houden. Bekijk mijn top 11 best practices voor de index voor meer inzicht.