
In een eerder artikel hebben we de vereisten voor SQL Server-indexen en prestatieoverwegingen onderzocht. Als het gaat om databaseprestaties, is het afstemmen van prestaties zonder twijfel een van de belangrijkste en meest complexe functies. Het bestaat uit veel verschillende gebieden, zoals SQL-queryoptimalisatie, indexafstemming en afstemming van systeembronnen, die allemaal correct moeten worden uitgevoerd om snel gegevens op te halen.
Er zijn verschillende belangrijke gebieden waarmee u rekening moet houden als het gaat om SQL Server-indexen, omdat deze een aanzienlijke invloed kunnen hebben op zowel uw prestatieafstemming als de algehele databaseprestaties. Hieronder vindt u enkele details over elk en de cruciale rollen die ze spelen.
SQL Server-index best practices
1. Begrijpen hoe databaseontwerp van invloed is op SQL Server-indexen
Indexeringsvereisten variëren tussen databases voor online transactieverwerking (OLTP) en online analytische verwerking (OLAP).
In een OLTP-database voeren gebruikers regelmatig lees-schrijfbewerkingen uit, waarbij nieuwe gegevens worden ingevoegd en bestaande gegevens worden gewijzigd. Ze gebruiken taalquery's voor gegevensmanipulatie (Invoegen, Bijwerken, Verwijderen) samen met Select-instructies voor het ophalen en wijzigen van gegevens. Voor OLTP-databases kunt u het beste indexen maken in de kolom Geselecteerd van een tabel. Meerdere indexen kunnen een negatieve invloed hebben op de prestaties en de systeembronnen onder druk zetten. In plaats daarvan wordt aanbevolen om het minimum aantal indexen te maken dat aan uw indexeringsvereisten kan voldoen. In OLAP-databases daarentegen gebruikt u meestal Select-statements om gegevens op te halen voor verdere analytische doeleinden. In dit geval kunt u meer indexen toevoegen met meerdere sleutelkolommen per index. U kunt ook gebruikmaken van columnstore-indexen voor sneller ophalen van gegevens in datawarehouse-query's
2. Maak indexen voor uw werklastvereisten
Voeg bij het maken van een nieuwe tabel in uw database niet blindelings indexen toe. Soms plaatsen ontwikkelaars er één geclusterde index en een paar niet-geclusterde indexen op zonder te zoeken naar de zoekopdrachten die deze indexen gebruiken. Er is mogelijk een index die niet voldoet aan de vereisten voor het optimaliseren van query's; daarom moet u uw werklast en SQL-query's (opgeslagen procedures, functies, views en ad-hocquery's) goed analyseren. U kunt de werklast vastleggen met behulp van SQL-profiler, uitgebreide gebeurtenissen en dynamische beheerweergaven, en vervolgens indexen maken om resource-intensieve zoekopdrachten te optimaliseren.
3. Maak indexen voor de meest gebruikte en meest gebruikte zoekopdrachten
Het is belangrijk om workloads te groeperen voor de meest gebruikte query's in uw systeem. Door de beste indexen voor deze zoekopdrachten te maken, wordt uw systeem zo min mogelijk belast.
4. Best practices toepassen op de kolom met SQL Server-indexsleutel
Aangezien u meerdere kolommen in een tabel kunt hebben, volgen hier enkele overwegingen voor indexsleutelkolommen.
- Kolommen met tekst, afbeelding, ntext, varchar(max), nvarchar(max) en varbinary(max) kunnen niet worden gebruikt in de indexsleutelkolommen.
- Het wordt aanbevolen om een integer gegevenstype te gebruiken in de indexsleutelkolom. Het heeft weinig ruimte nodig en werkt efficiënt. Daarom wil je de primaire sleutelkolom maken, meestal op een geheel getal gegevenstype.
- U kunt alleen XML-gegevenstype gebruiken in een XML-index.
- Overweeg om een primaire sleutel te maken voor de kolom met unieke waarden. Als een tabel geen kolommen met unieke waarden heeft, kunt u een identiteitskolom definiëren voor een gegevenstype met een geheel getal. Een primaire sleutel creëert ook een geclusterde index voor de rijverdeling.
- U kunt een kolom met de waarden Unique en Not NULL beschouwen als een nuttige kandidaat voor de indexsleutel.
- U moet een index bouwen op basis van de predikaten in de Where-clausule. U kunt bijvoorbeeld rekening houden met kolommen die worden gebruikt in de Where-clausule, SQL-joins, like, order by, group by predikaten, enzovoort.
- Je moet tabellen zo samenvoegen dat het aantal rijen voor de rest van de query wordt verminderd. Dit helpt Query Optimizer bij het opstellen van het uitvoeringsplan met minimale systeembronnen.
- Als u meerdere kolommen voor een indexsleutel gebruikt, is het ook essentieel om hun positie in de indexsleutel te overwegen.
- Overweeg ook om opgenomen kolommen in uw indexen te gebruiken.
5. Analyseer de gegevensdistributie van uw SQL Server-indexkolommen
U moet de gegevensdistributie onderzoeken in de kolommen van de SQL Server-indexsleutel. Een kolom met niet-unieke waarden kan een vertraging veroorzaken bij het ophalen van de gegevens en resulteren in een langlopende transactie. U kunt de gegevensdistributie analyseren met behulp van het histogram in statistieken.
6. Gegevenssorteervolgorde gebruiken
U moet ook rekening houden met de vereisten voor het sorteren van gegevens in uw query's en indexen. Standaard sorteert SQL Server gegevens in oplopende volgorde in een index. Stel dat u een index in oplopende volgorde maakt, maar dat uw zoekopdrachten de Order By-clausule gebruiken om gegevens in aflopende volgorde te sorteren.
Kijk bijvoorbeeld naar het daadwerkelijke uitvoeringsplan van de volgende query.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
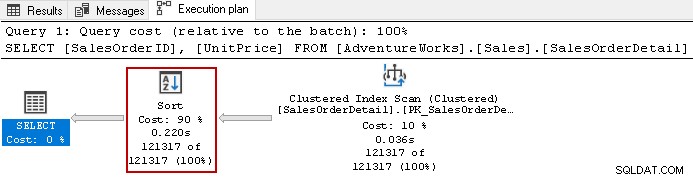
Het gebruikt de dure sorteeroperator met een totale kosten van 90% voor deze zoekopdracht. We hebben besloten om een niet-geclusterde index te bouwen op [UnitPrice] en [SalesOrderID]. Het gebruikt een standaard sorteervolgorde voor beide kolommen in de index.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
We hebben de Select-instructie opnieuw uitgevoerd en de query-optimizer gebruikt nog steeds de sort-operator. Het kan de niet-geclusterde index gebruiken, maar sorteert de gegevens om het resultaat voor te bereiden.
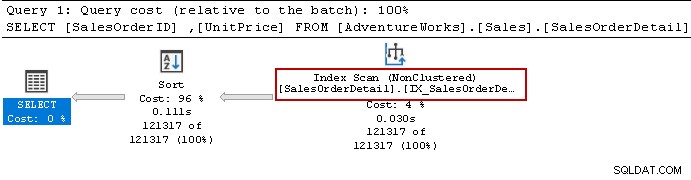
Laten we de index opnieuw maken met behulp van de volgende query. Deze keer sorteert het gegevens in aflopende volgorde voor [Eenheidsprijs] in de indexdefinitie.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
Het vereist nu geen sorteeroperator omdat de index voldoet aan de zoekvereisten.
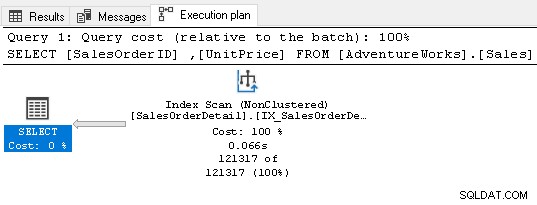
7. Gebruik externe sleutels voor uw SQL Server-index
U moet een index maken op de kolommen met externe sleutels. Het is raadzaam om een geclusterde index op de externe sleutel te maken om de queryprestaties te verbeteren.
8. Houd rekening met overwegingen voor SQL Server-indexopslag
Indexopslag is ook een nuttig aspect om te overwegen. SQL Server maakt alle indexen op dezelfde bestandsgroep van de tabel. U kunt een aparte bestandsgroep voor indexen overwegen en het fysieke bestand op een aparte schijf scheiden. Dit zal de IO-prestaties en doorvoer verhogen.
Op dezelfde manier kunt u tabelpartitionering gebruiken om gegevens over meerdere schijven en bestandsgroepen te scheiden. U kunt gepartitioneerde indexen ontwerpen voor deze tabelpartities om gelijktijdige gegevenstoegang te verbeteren.
Een andere optie is om de FILLFACTOR te definiëren tijdens het maken of opnieuw opbouwen van een index. Een FILLFACTOR definieert de vrije ruimte in de bladknooppuntgegevenspagina's. Het is handig voor verdere gegevensinvoegingen. Als uw gegevens statisch zijn en niet vaak veranderen, kunt u een hoge waarde van de FILLFACTOR overwegen. Aan de andere kant kunt u voor vaak veranderende gegevens voldoende ruimte overlaten voor nieuwe gegevensinvoegingen.
9. Vind ontbrekende indexen
Soms krijgt u informatie over een ontbrekende SQL Server-index in het uitvoeringsplan voor query's. U kunt ook de dynamische beheerweergaven uitvoeren om deze ontbrekende indexen te vinden. U moet deze indexen niet blindelings maken. Het is slechts een suggestie voor het optimaliseren van query's, maar het houdt geen rekening met de bestaande index of uw werkbelastingvereisten. Het kan ook meerdere kolommen in de indexdefinitie bevatten, dus bekijk deze suggesties voordat u het implementeert.
10. Maak altijd een geclusterde index vóór een niet-geclusterde index
Als algemene richtlijn moet u een geclusterde index maken voordat u niet-geclusterde indexen maakt. Als een tabel geen index heeft, bestaat een niet-geclusterde index uit rij-ID's. Nadat u een geclusterde index hebt gemaakt, moet SQL Server deze niet-geclusterde indexen opnieuw opbouwen, zodat ze kunnen verwijzen naar de geclusterde indexsleutel in plaats van de rij-ID's.
11. Indexonderhoud bijhouden en statistieken bijwerken
Hieronder vindt u verschillende onderhoudsgebieden die moeten worden gecontroleerd als het gaat om SQL Server-indexen.
- Verwijder indexfragmentatie :u moet regelmatig interne en externe fragmentaties bekijken, vooral voor de hoge transactietabellen. Uw query's kunnen traag reageren, zelfs als u de juiste indexen voor uw workloads hebt. Een sterk gefragmenteerde index kan de prestaties verslechteren omdat er extra IO voor nodig is. U kunt een reorganisatie uitvoeren of een index opnieuw opbouwen op basis van de fragmentatiewaarden. Gewoonlijk moet u de index opnieuw opbouwen als deze een fragmentatie van meer dan 30% heeft en reorganiseren als deze minder dan 30% fragmentatie heeft.
- Verwijder ongebruikte indexen: U moet altijd de ongebruikte (inactieve) indexen in uw database bekijken, omdat de query-optimizer ze voor elke query in overweging moet nemen. Een ongebruikte index verbruikt ook opslagruimte en verhoogt de onderhoudskosten.
- Statistieken bijwerken: U moet de statistieken regelmatig bijwerken, zelfs als u de statistieken voor automatisch bijwerken hebt ingesteld in uw databaseconfiguratie. De query-optimizer kan een slecht uitvoeringsplan opstellen als de indexstatistieken niet worden bijgewerkt. U kunt een agenttaak plannen om SQL Server-statistieken bij te werken met een volledige scan na kantooruren.
U kunt het onderhoud van de SQL-index raadplegen voor meer informatie over dit onderwerp.
Best practices voor SQL Server-index toepassen
Hoewel er niet altijd een eenvoudige manier is om een optimale SQL Server-index te ontwerpen, zal het toepassen van de aanbevelingen in dit bericht u helpen om te navigeren door de verschillende indexeringsvereisten die u tegenkomt bij elk databasetype en de bijbehorende workloads. Met deze praktische tips kunt u uw indexen optimaliseren om de databaseprestaties te verbeteren en te zorgen voor een soepeler afstemmingsproces van de prestaties.