Het implementeren van een gebruiksvriendelijke zoekopdracht kan lastig zijn, maar kan ook heel efficiënt. Hoe weet ik dit? Nog niet zo lang geleden moest ik een zoekmachine op een mobiele app implementeren. De app is gebouwd op het Ionic-framework en zou verbinding maken met een CakePHP 2-backend. Het idee was om resultaten weer te geven terwijl de gebruiker aan het typen was. Hiervoor waren verschillende opties, maar ze voldeden niet allemaal aan de eisen van mijn project.
Laten we, om te illustreren wat dit soort taken inhouden, eens kijken naar nummers en hun mogelijke relaties (zoals artiesten, albums, enz.).
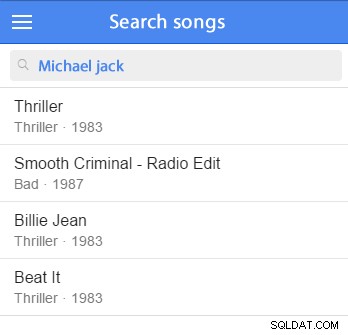
De records zouden moeten worden gesorteerd op relevantie, wat ervan afhangt of het zoekwoord overeenkomt met velden uit het record zelf of uit andere kolommen in gerelateerde tabellen. Ook moet de zoekopdracht ten minste een basiswoord-stam implementeren. (Stemming wordt gebruikt om de stamvorm van een woord te krijgen. "Stengels", "stemmer", "stemming" en "gesteeld" hebben allemaal dezelfde wortel:"stam".)
De hier gepresenteerde aanpak is getest met enkele honderdduizenden records en was in staat om nuttige resultaten op te halen terwijl de gebruiker aan het typen was.
Te overwegen producten voor het zoeken in volledige tekst
Er zijn verschillende manieren waarop we dit soort zoekopdrachten kunnen implementeren. Ons project had enkele beperkingen met betrekking tot tijd en serverbronnen, dus we moesten de oplossing zo eenvoudig mogelijk houden. Uiteindelijk kwamen er een paar kanshebbers naar voren:
Elastisch zoeken
Elasticsearch biedt full-text zoekopdrachten in een documentgerichte service. Het is ontworpen om enorme hoeveelheden belasting op een gedistribueerde manier te beheren:het kan resultaten rangschikken op relevantie, aggregaties uitvoeren en werken met woordstammen en synoniemen. Deze tool is bedoeld voor realtime zoekopdrachten. Van hun website:
Elasticsearch bouwt gedistribueerde mogelijkheden bovenop Apache Lucene om de krachtigste full-text zoekmogelijkheden te bieden die er zijn. Krachtige, ontwikkelaarvriendelijke query-API ondersteunt meertalig zoeken, geolocatie, contextuele bedoelde-je-mee-suggesties, automatisch aanvullen en resultaatfragmenten.
Elasticsearch kan werken als een REST-service, reagerend op http-verzoeken, en het kan zeer snel worden opgezet. Om de engine als een service te starten, moet u echter enkele toegangsrechten voor de server hebben. En als uw hostingprovider Elasticsearch niet standaard ondersteunt, moet u enkele pakketten installeren.
Het komt erop neer dat dit product een geweldige optie is als u een solide zoekoplossing wilt. (Opmerking:je hebt misschien een VPS of een dedicated server nodig omdat de hardwarevereisten behoorlijk veeleisend zijn.)
Sfinx
Net als Elasticsearch biedt Sphinx ook een zeer solide full-text zoekproduct:Craigslist bedient er meer dan 300.000.000 zoekopdrachten per dag mee. Sphinx biedt geen native RESTful-interface. Het is geïmplementeerd in C, met een kleinere hardwarevoetafdruk dan Elasticsearch (dat is geïmplementeerd in Java en kan draaien op elk besturingssysteem met een jvm). Je hebt ook root-toegang tot de server nodig met wat speciale RAM/CPU om Sphinx correct te laten werken.
MySQL zoeken in volledige tekst
Historisch gezien werden zoekopdrachten in volledige tekst ondersteund in MyISAM-engines. Na versie 5.6 ondersteunde MySQL ook full-text zoekopdrachten in InnoDB storage-engines. Dit was geweldig nieuws, omdat het ontwikkelaars in staat stelt te profiteren van de referentiële integriteit van InnoDB, het vermogen om transacties uit te voeren en vergrendelingen op rijniveau.
Er zijn in principe twee benaderingen voor zoekopdrachten in volledige tekst in MySQL:natuurlijke taal en booleaanse modus. (Een derde optie breidt de zoekopdracht in natuurlijke taal uit met een tweede uitbreidingsquery.)
Het belangrijkste verschil tussen de natuurlijke en de booleaanse modus is dat de boolean bepaalde operators toestaat als onderdeel van de zoekopdracht. Booleaanse operatoren kunnen bijvoorbeeld worden gebruikt als een woord een grotere relevantie heeft dan andere in de zoekopdracht of als een specifiek woord aanwezig moet zijn in de resultaten, enz. Het is de moeite waard om op te merken dat in beide gevallen de resultaten kunnen worden gesorteerd op de relevantie berekend door MySQL tijdens het zoeken.
Beslissingen nemen
De beste oplossing voor ons probleem was het gebruik van InnoDb full-text zoekopdrachten in booleaanse modus. Waarom?
- We hadden weinig tijd om de zoekfunctie te implementeren.
- Op dit moment hadden we geen big data om te kraken, noch een enorme belasting om iets als Elasticsearch of Sphinx te vereisen.
- We gebruikten shared hosting die Elasticsearch of Sphinx niet ondersteunt en de hardware was in dit stadium vrij beperkt.
- Hoewel we een woord wilden dat stamt uit onze zoekfunctie, was het geen dealbreaker:we konden het (binnen beperkingen) implementeren door middel van een simpele PHP-codering en denormalisatie van gegevens
- Zoeken met volledige tekst in de booleaanse modus kunnen woorden zoeken met jokertekens (voor het woord stam) en de resultaten sorteren op relevantie.
Zoeken in volledige tekst in Booleaanse modus
Zoals eerder vermeld, is zoeken in natuurlijke taal de eenvoudigste benadering:zoek gewoon naar een woordgroep of een woord in de kolommen waar u een volledige tekstindex hebt ingesteld en u krijgt de resultaten gesorteerd op relevantie.
In het genormaliseerde Vertabelo-model
Laten we eens kijken hoe een eenvoudige zoekopdracht zou werken. We maken eerst een voorbeeldtabel:
-- Created by Vertabelo (https://vertabelo.com) -- Last modification date: 2016-04-25 15:01:22.153 -- tables -- Table: artists CREATE TABLE artists ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artists_pk PRIMARY KEY (id) ) ENGINE InnoDB; CREATE FULLTEXT INDEX artists_idx_1 ON artists (name); -- End of file.
In natuurlijke taalmodus
U kunt enkele voorbeeldgegevens invoegen en beginnen met testen. (Het zou goed zijn om het toe te voegen aan uw voorbeelddataset.) We zullen bijvoorbeeld proberen te zoeken naar Michael Jackson:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN NATURAL LANGUAGE MODE)
Deze zoekopdracht vindt records die overeenkomen met de zoektermen en sorteert overeenkomende records op relevantie; hoe beter de match, hoe relevanter deze is en hoe hoger het resultaat in de lijst zal verschijnen.
In booleaanse modus
We kunnen dezelfde zoekopdracht uitvoeren in de booleaanse modus. Als we geen operatoren toepassen op onze zoekopdracht, is het enige verschil dat de resultaten niet zijn gesorteerd op relevantie:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN BOOLEAN MODE)
De wildcard-operator in booleaanse modus
Omdat we willen zoeken naar gesteelde en gedeeltelijke woorden, hebben we de jokertekenoperator (*) nodig. Deze operator kan worden gebruikt bij zoekopdrachten in de booleaanse modus, daarom hebben we die modus gekozen.
Laten we dus de kracht van booleaans zoeken ontketenen en proberen een deel van de naam van de artiest te zoeken. We gebruiken de wildcard-operator om elke artiest te zoeken wiens naam begint met 'Mich':
SELECT
*
FROM
artists
WHERE
MATCH (name) AGAINST ('Mich*' IN BOOLEAN MODE)
Sorteren op relevantie in booleaanse modus
Laten we nu eens kijken naar de berekende relevantie voor de zoekopdracht. Dit zal ons helpen de sortering te begrijpen die we later met Cake zullen doen:
SELECT
*, MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE) AS rank
FROM
artists
WHERE
MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE)
ORDER BY rank DESC
Deze zoekopdracht haalt zoekovereenkomsten op en de relevantiewaarde die MySQL voor elke record berekent. De engine-optimizer zal detecteren dat we de relevantie selecteren, dus het zal niet de moeite nemen om de rangorde opnieuw te berekenen.
Woordstamming bij zoeken in volledige tekst
Wanneer we woordstammen in een zoekopdracht opnemen, wordt de zoekopdracht gebruiksvriendelijker. Zelfs als het resultaat geen woord op zich is, proberen algoritmen dezelfde wortel te genereren voor afgeleide woorden. De stam "argu" is bijvoorbeeld geen Engels woord, maar kan worden gebruikt als stam voor "argue", "argued", "argues", "arguing","Argus" en andere woorden.
Stemming verbetert de resultaten, omdat de gebruiker een woord kan invoeren dat geen exacte overeenkomst heeft, maar de "stam" wel. Hoewel PHP stemmer of Snowball's Python stemmer een optie zou kunnen zijn (als je root SSH toegang hebt tot je server), zullen we de PorterStemmer.php klasse gebruiken.
Deze klasse implementeert het door Martin Porter voorgestelde algoritme om woorden in het Engels te stammen. Zoals de auteur op zijn website vermeldt, is het gratis te gebruiken voor elk doel. Plaats het bestand in uw Vendors-map in CakePHP, neem de bibliotheek op in uw model en roep de statische methode aan om een woord te stammen:
//include the library (should be called PorterStemmer.php) within CakePHP’s Vendors folder
App::import('Vendor', 'PorterStemmer');
//stem a word (words must be stemmed one by one)
echo PorterStemmer::Stem(‘stemming’);
//output will be ‘stem’
Ons doel is om zoeken snel en efficiënt te maken en om resultaten te kunnen sorteren op relevantie voor de volledige tekst. Om dit te doen, moeten we woordstammen op twee manieren gebruiken:
- De woorden ingevoerd door de gebruiker
- Liedgerelateerde gegevens (die we in kolommen opslaan en sorteren op resultaten op basis van relevantie)
Het eerste type woordstam kan als volgt worden bereikt:
App::import('Vendor', 'PorterStemmer');
$search = trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));//remove undesired characters
$words = explode(" ", trim($search));
$stemmedSearch = "";
$unstemmedSearch = "";
foreach ($words as $word) {
$stemmedSearch .= PorterStemmer::Stem($word) . "* ";//we add the wildcard after each word
$unstemmedSearch = $word . "* " ;//to search the artist column which is not stemmed
}
$stemmedSearch = trim($stemmedSearch);
$unstemmedSearch = trim($unstemmedSearch);
if ($stemmedSearch == "*" || $unstemmedSearch=="*") {
//otherwise mySql will complain, as you cannot use the wildcard alone
$stemmedSearch = "";
$unstemmedSearch = "";
}
We hebben twee tekenreeksen gemaakt:een om te zoeken naar de artiestennaam (zonder stem) en een om in de andere kolommen met stammen te zoeken. Dit zal ons helpen om later onze 'tegen' . te bouwen onderdeel van de volledige tekstquery. Laten we nu eens kijken hoe we de gegevens van het nummer kunnen stammen en sorteren.
Denormaliseren van songdata
Onze sorteercriteria zijn gebaseerd op het eerst overeenkomen met de artiest van het nummer (zonder stemming). Vervolgens komen de naam, het album en de gerelateerde categorieën van het nummer. Stemming wordt gebruikt voor alle secundaire zoekcriteria.
Om dit te illustreren, stel dat ik zoek naar 'nirvana' en er is een nummer genaamd 'Nirvana Games' van 'XYZ', en een ander nummer genaamd 'Polly' van de artiest 'Nirvana'. De resultaten moeten als eerste 'Polly' vermelden, omdat de overeenkomst op de naam van de artiest belangrijker is dan een overeenkomst op de naam van het nummer (op basis van de criteria).
Om dit te doen, heb ik 4 velden toegevoegd in de songs tabel, één voor elk van de zoek-/sorteercriteria die we willen:
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL AFTER`denorm_trackname`, ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
Ons volledige databasemodel zou er als volgt uitzien:
Telkens wanneer u een nummer opslaat met behulp van toevoegen/bewerken in CakePHP, hoeft u alleen de naam van de artiest op te slaan in de kolom denorm_artist zonder het af te leiden. Voeg vervolgens de gestemde tracknaam toe in de denorm_trackname veld (vergelijkbaar met wat we deden in de gezochte tekst) en sla de naam van het gestemde album op in het denorm_album kolom. Sla ten slotte de gestemde categorieset voor het nummer op in de denorm_categories veld, voeg de woorden samen en voeg een spatie toe tussen elke categorienaam met een stam.
Zoeken in volledige tekst en sorteren op relevantie in CakePHP
We gaan verder met het voorbeeld van het zoeken naar 'Nirvana', laten we eens kijken wat een soortgelijke zoekopdracht kan bereiken:
SELECT
trackname,
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank1,
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank2,
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank3,
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank4
FROM songs
WHERE
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE)
ORDER BY rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC
We zouden de volgende output krijgen:
| tracknaam | rang1 | rang2 | rang3 | rang4 |
| Polly | 0.0906190574169159 | 0 | 0 | 0 |
| nirvana-spellen | 0 | 0.0906190574169159 | 0 | 0 |
Om dit in CakePHP te doen, moet de zoek methode moet worden aangeroepen met behulp van een combinatie van 'fields', 'conditions' en 'order'-parameters. Doorgaan met de voormalige PHP-voorbeeldcode:
//within Song.php model file
$fields = array(
"Song.trackname",
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE) as `rank1`",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank2`",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank3`",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank4`"
);
$order = "`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";
$conditions = array(
"OR" => array(
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)"
)
);
$results = $this->find(‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order);
$resultaten wordt de reeks nummers gesorteerd met de criteria die we eerder hebben gedefinieerd.
Deze oplossing kan worden gebruikt om zoekopdrachten te genereren die betekenisvol zijn voor de gebruiker - zonder dat de ontwikkelaars al te veel tijd nodig hebben of de code veel ingewikkelder maken.
CakePHP-zoekopdrachten nog beter maken
Het is vermeldenswaard dat het "kruiden" van de gedenormaliseerde kolommen met meer gegevens tot betere resultaten kan leiden.
Met 'kruiden' bedoel ik dat je in de gedenormaliseerde kolommen meer gegevens kunt opnemen uit aanvullende kolommen die je nuttig acht met als doel de resultaten relevanter te maken, bijvoorbeeld als je wist dat het land van een artiest in de zoektermen zou kunnen voorkomen, zou het land kunnen toevoegen samen met de naam van de artiest in de denorm_artist kolom. Dit zou de kwaliteit van de zoekresultaten verbeteren.
Vanuit mijn ervaring (afhankelijk van de feitelijke gegevens die u gebruikt en de kolommen die u denormaliseert) zijn de bovenste resultaten meestal erg nauwkeurig. Dit is geweldig voor mobiele apps, aangezien het voor de gebruiker frustrerend kan zijn om door een lange lijst te scrollen.
Ten slotte, als je meer gegevens wilt halen uit de tabellen waarop het nummer betrekking heeft, kun je altijd een join maken en de artiest, categorieën, albums, songcommentaar, enz. krijgen. Als je de beheersbare gedragsfilter van CakePHP gebruikt, stel voor om de EagerLoader-plug-in toe te voegen om de joins efficiënt uit te voeren.
Als u uw eigen benadering heeft voor het implementeren van zoeken in volledige tekst, deel deze dan in de onderstaande opmerkingen. We kunnen allemaal leren van elkaars ervaring.