Ik heb meerdere benchmarks gepubliceerd waarin verschillende PostgreSQL-versies worden vergeleken, zoals bijvoorbeeld de preek over prestatie-archeologie (evaluatie van PostgreSQL 7.4 tot 9.4), en al die benchmarks gingen uit van een vaste omgeving (hardware, kernel, ...). Dat is in veel gevallen prima (bijvoorbeeld bij het evalueren van de prestatie-impact van een patch), maar bij de productie veranderen die dingen in de loop van de tijd - je krijgt hardware-upgrades en van tijd tot tijd krijg je een update met een nieuwe kernelversie.
Voor hardware-upgrades (betere opslag, meer RAM, snellere CPU's, ...) is de impact meestal vrij eenvoudig te voorspellen, en bovendien realiseren mensen zich over het algemeen dat ze de impact moeten beoordelen door de knelpunten op de productie te analyseren en misschien zelfs eerst de nieuwe hardware te testen .
Maar hoe zit het met kernel-updates? Helaas doen we meestal niet veel benchmarking op dit gebied. De veronderstelling is meestal dat nieuwe kernels beter zijn dan oudere (sneller, efficiënter, schaalbaar naar meer CPU-cores). Maar is het echt waar? En hoe groot is het verschil? Wat als u bijvoorbeeld een kernel upgradet van 3.0 naar 4.7 - heeft dat invloed op de prestaties, en zo ja, zullen de prestaties verbeteren of niet?
Van tijd tot tijd krijgen we rapporten over ernstige regressies met een bepaalde kernelversie, of plotselinge verbetering tussen kernelversies. Het is dus duidelijk dat kernelversies de prestaties kunnen beïnvloeden.
Ik ken een enkele PostgreSQL-benchmark die verschillende kernelversies vergelijkt, gemaakt in 2014 door Sergey Konoplev als reactie op aanbevelingen om 3.0 - 3.8-kernels te vermijden. Maar die benchmark is vrij oud (de laatste beschikbare kernelversie ongeveer 18 maanden geleden was 3.13, terwijl we tegenwoordig 3.19 en 4.6 hebben), dus ik heb besloten om een aantal benchmarks uit te voeren met de huidige kernels (en PostgreSQL 9.6beta1).
PostgreSQL vs. kernelversies
Maar laat me eerst enkele significante verschillen bespreken tussen het beleid dat de toezeggingen in de twee projecten regelt. In PostgreSQL hebben we het concept van hoofd- en secundaire versies - hoofdversies (bijv. 9.5) worden ongeveer één keer per jaar uitgebracht en bevatten verschillende nieuwe functies. Kleinere versies (bijv. 9.5.2) bevatten alleen bugfixes en worden ongeveer elke drie maanden uitgebracht (of vaker, wanneer een ernstige bug wordt ontdekt). Er mogen dus geen grote prestatie- of gedragsveranderingen zijn tussen kleine versies, waardoor het redelijk veilig is om kleine versies te implementeren zonder uitgebreide tests.
Met kernelversies is de situatie veel minder duidelijk. Linux-kernel heeft ook vertakkingen (bijv. 2.6, 3.0 of 4.7), die in geen geval gelijk zijn aan "grote versies" van PostgreSQL, omdat ze nieuwe functies blijven ontvangen en niet alleen bugfixes. Ik beweer niet dat het PostgreSQL-versiebeleid op de een of andere manier automatisch superieur is, maar het gevolg is dat het updaten tussen kleine kernelversies gemakkelijk de prestaties aanzienlijk kan beïnvloeden of zelfs bugs kan introduceren (bijv. 3.18.37 heeft last van OOM-problemen als gevolg van een dergelijke niet-bugfix commit).
Natuurlijk realiseren distributies zich deze risico's, en vergrendelen vaak de kernelversie en doen verder testen om nieuwe bugs te verwijderen. Dit bericht gebruikt echter vanille-kernels voor de lange termijn, zoals beschikbaar op www.kernel.org.
Benchmark
Er zijn veel benchmarks die we kunnen gebruiken - dit bericht presenteert een reeks pgbench-tests, d.w.z. een vrij eenvoudige OLTP (TPC-B-achtige) benchmark. Ik ben van plan aanvullende tests uit te voeren met andere benchmarktypes (met name DWH/DSS-georiënteerd), en ik zal ze in de toekomst op deze blog presenteren.
Nu, terug naar de pgbench - als ik zeg "verzameling tests" bedoel ik combinaties van
- alleen-lezen versus lezen-schrijven
- grootte dataset – actieve set past (niet) in gedeelde buffers / RAM
- aantal klanten – enkele klant versus veel klanten (vergrendeling/planning)
De waarden zijn uiteraard afhankelijk van de gebruikte hardware, dus laten we eens kijken op welke hardware deze benchmarkronde draaide:
- CPU:Intel i5-2500k @ 3,3 GHz (3,7 GHz turbo)
- RAM:8 GB (DDR3 @ 1333 MHz)
- opslag:6x Intel SSD DC S3700 in RAID-10 (Linux sw raid)
- bestandssysteem:ext4 met standaard I/O-planner (cfq)
Het is dus dezelfde machine die ik heb gebruikt voor een aantal eerdere benchmarks - een vrij kleine machine, niet bepaald de nieuwste CPU enz. Maar ik geloof dat het nog steeds een redelijk "klein" systeem is.
De benchmarkparameters zijn:
- datasetschalen:30, 300 en 1500 (dus ongeveer 450 MB, 4,5 GB en 22,5 GB)
- clienttellingen:1, 4, 16 (de machine heeft 4 cores)
Voor elke combinatie waren er 3 alleen-lezen-runs (elk 15 minuten) en 3 lees-schrijf-runs (elk 30 minuten). Het eigenlijke script dat de benchmark aanstuurt, is hier beschikbaar (samen met resultaten en andere nuttige gegevens).
Opmerking :Als u aanzienlijk verschillende hardware heeft (bijv. roterende schijven), ziet u mogelijk heel verschillende resultaten. Als je een systeem hebt dat je wilt testen, laat het me weten en ik zal je daarbij helpen (ervan uitgaande dat ik de resultaten mag publiceren).
Kernelversies
Wat betreft kernelversies, ik heb de nieuwste versies getest in alle lange termijn branches sinds 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 en 4.7). Er draaien nog steeds veel systemen op 2.6.x-kernels, dus het is handig om te weten hoeveel prestaties u kunt winnen (of verliezen) door te upgraden naar een nieuwere kernel. Maar ik heb alle kernels zelf gecompileerd (d.w.z. met vanille-kernels, geen distributiespecifieke patches), en de configuratiebestanden staan in de git-repository.
Resultaten
Zoals gewoonlijk zijn alle gegevens beschikbaar op bitbucket, inclusief
- kernel .config-bestand
- benchmarkscript (run-pgbench.sh)
- PostgreSQL-configuratie (met wat basisafstemming voor de hardware)
- PostgreSQL-logboeken
- verschillende systeemlogboeken (dmesg, sysctl, mount, ...)
De volgende grafieken tonen de gemiddelde tps voor elk gebenchmarkt geval - de resultaten voor de drie runs zijn redelijk consistent, met ~2% verschil tussen min en max in de meeste gevallen.
alleen-lezen
Voor de kleinste dataset is er een duidelijke prestatiedaling tussen 3,4 en 3,10 voor alle klantenaantallen. De resultaten voor 16 clients (4x het aantal cores) zijn echter meer dan hersteld in 3.12.
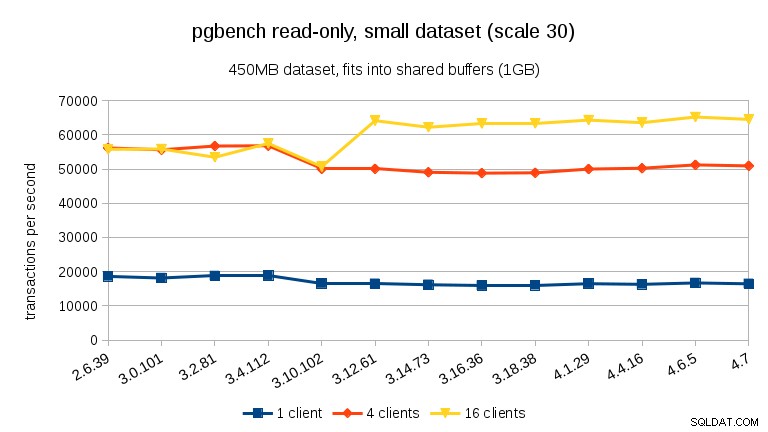
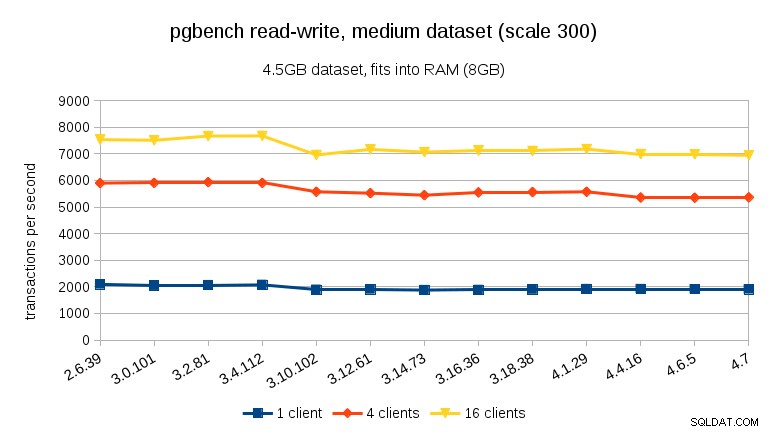
Voor de middelgrote dataset (past in RAM maar niet in gedeelde buffers), zien we dezelfde daling tussen 3.4 en 3.10, maar niet het herstel in 3.12.
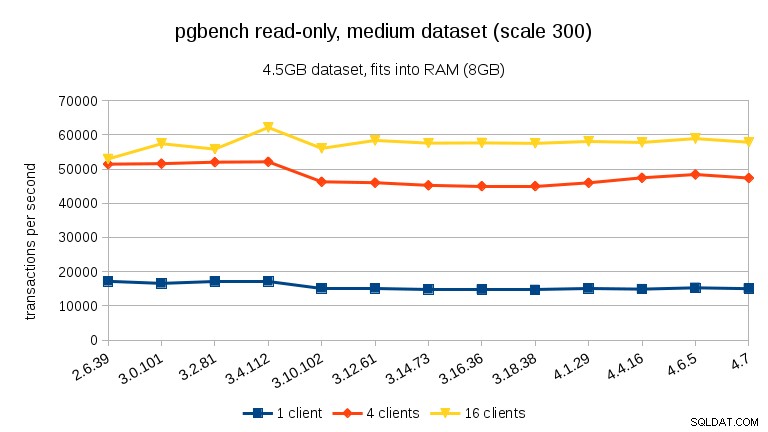
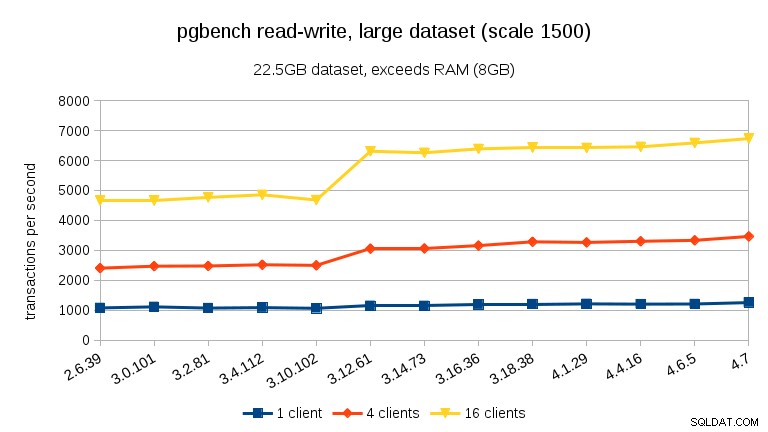
Voor grote datasets (meer dan RAM, dus zwaar I/O-gebonden), zijn de resultaten heel anders – ik weet niet zeker wat er gebeurde tussen 3.10 en 3.12, maar de prestatieverbetering (met name voor hogere aantallen klanten) is behoorlijk verbazingwekkend.
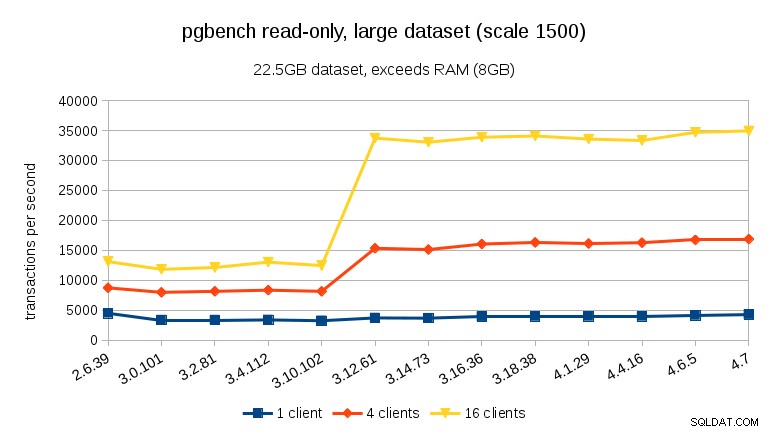
lezen-schrijven
Voor de lees-schrijfwerkbelasting zijn de resultaten redelijk vergelijkbaar. Voor de kleine en middelgrote datasets kunnen we dezelfde daling van ~10% waarnemen tussen 3,4 en 3,10, maar helaas geen herstel in 3,12.
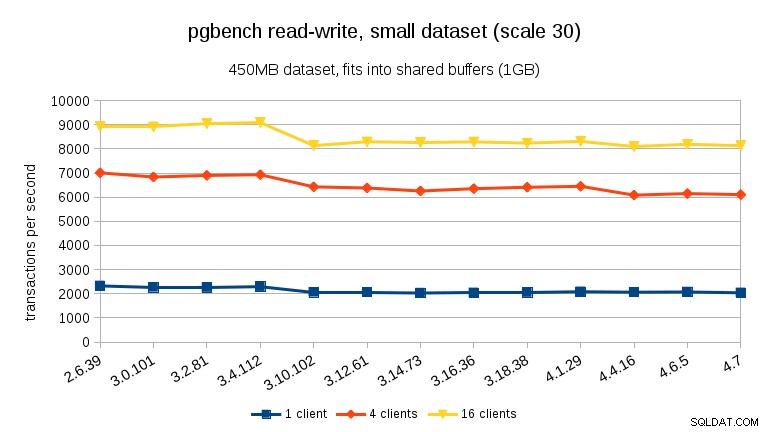
Voor de grote dataset (wederom significant I/O-gebonden) kunnen we een vergelijkbare verbetering zien in 3.12 (niet zo significant als voor de alleen-lezen werkbelasting, maar nog steeds significant):
Samenvatting
Ik durf geen conclusies te trekken uit een enkele benchmark op een enkele machine, maar ik denk dat het veilig is om te zeggen:
- De algehele prestatie is redelijk stabiel, maar we kunnen enkele significante prestatieveranderingen zien (in beide richtingen).
- Bij datasets die in het geheugen passen (ofwel in shared_buffers of op zijn minst in RAM) zien we een meetbare prestatiedaling tussen 3.4 en 3.10. Bij alleen-lezen-test herstelt dit gedeeltelijk in 3.12 (maar alleen voor veel klanten).
- Met datasets die het geheugen overschrijden, en dus voornamelijk I/O-gebonden, zien we geen prestatiedalingen, maar een significante verbetering in 3.12.
Wat betreft de redenen waarom die plotselinge veranderingen plaatsvinden, weet ik het niet helemaal zeker. Er zijn veel mogelijk relevante commits tussen de versies, maar ik weet niet zeker hoe ik de juiste kan identificeren zonder uitgebreide (en tijdrovende) tests. Als je andere ideeën hebt (bijvoorbeeld als je op de hoogte bent van dergelijke toezeggingen), laat het me dan weten.