PostgreSQL is een geweldig project en het evolueert in een verbazingwekkend tempo. We zullen ons concentreren op de evolutie van fouttolerantiemogelijkheden in PostgreSQL in alle versies met een reeks blogposts. Dit is het vierde bericht van de serie en we zullen het hebben over synchrone commit en de effecten ervan op fouttolerantie en betrouwbaarheid van PostgreSQL.
Als je vanaf het begin getuige wilt zijn van de evolutie van de evolutie, bekijk dan de eerste drie blogposts van de serie hieronder. Elke post is onafhankelijk, dus je hoeft de ene niet te lezen om de andere te begrijpen.
- Evolutie van fouttolerantie in PostgreSQL
- Evolutie van fouttolerantie in PostgreSQL:replicatiefase
- Evolutie van fouttolerantie in PostgreSQL:tijdreizen
Synchroon commitment
PostgreSQL implementeert standaard asynchrone replicatie, waarbij gegevens worden gestreamd wanneer de server dit uitkomt. Dit kan leiden tot gegevensverlies bij een failover. Het is mogelijk om Postgres te vragen om een (of meer) standbys te vereisen om de replicatie van de gegevens te bevestigen voorafgaand aan het vastleggen, dit wordt synchrone replicatie (synchrone vastlegging) genoemd. ) .
Bij synchrone replicatie wordt de replicatie direct heeft invloed op de verstreken tijd van transacties op de master. Met asynchrone replicatie kan de master op volle snelheid doorgaan.
Synchrone replicatie garandeert dat gegevens naar ten minste . worden geschreven twee knooppunten voordat de gebruiker of toepassing wordt verteld dat een transactie is uitgevoerd.
De gebruiker kan de vastleggingsmodus van elke transactie selecteren , zodat het mogelijk is om zowel synchrone als asynchrone commit-transacties gelijktijdig te laten lopen.
Dit maakt flexibele afwegingen mogelijk tussen prestaties en zekerheid van transactieduurzaamheid.
Synchroon vastleggen configureren
Voor het instellen van synchrone replicatie in Postgres moeten we synchronous_commit . configureren parameter in postgresql.conf.
De parameter geeft aan of de transactie-commit wacht tot WAL-records naar de schijf zijn geschreven voordat de opdracht een succes retourneert indicatie aan de opdrachtgever. Geldige waarden zijn aan , remote_apply , remote_write , lokaal , en uit . We zullen bespreken hoe dingen werken in termen van synchrone replicatie wanneer we synchronous_commit instellen parameter met elk van de gedefinieerde waarden.
Laten we beginnen met Postgres-documentatie (9.6):
Hier begrijpen we het concept van synchrone commit, zoals we beschreven in het inleidende gedeelte van de post, je bent vrij om synchrone replicatie in te stellen, maar als je dat niet doet, is er altijd een risico op gegevensverlies. Maar zonder risico op inconsistentie in de database, in tegenstelling tot het uitschakelen van fsync off - maar dat is een onderwerp voor een andere post -. Ten slotte concluderen we dat als we geen gegevens willen verliezen tussen replicatievertragingen en er zeker van willen zijn dat de gegevens naar ten minste twee knooppunten worden geschreven voordat de gebruiker/toepassing wordt geïnformeerd dat de transactie is gepleegd , we moeten accepteren dat er wat prestatieverlies is.
Laten we eens kijken hoe verschillende instellingen werken voor verschillende synchronisatieniveaus. Voordat we beginnen, laten we het hebben over hoe commit wordt verwerkt door PostgreSQL-replicatie. Client voert query's uit op het hoofdknooppunt, de wijzigingen worden geschreven naar een transactielogboek (WAL) en via het netwerk gekopieerd naar WAL op het stand-byknooppunt. Het herstelproces op het standby-knooppunt leest vervolgens de wijzigingen van WAL en past ze toe op de gegevensbestanden, net als tijdens crashherstel. Als de stand-by in hot stand-by staat modus kunnen clients alleen-lezen query's op het knooppunt uitvoeren terwijl dit gebeurt. Voor meer details over hoe replicatie werkt, kun je de replicatieblogpost in deze serie bekijken.
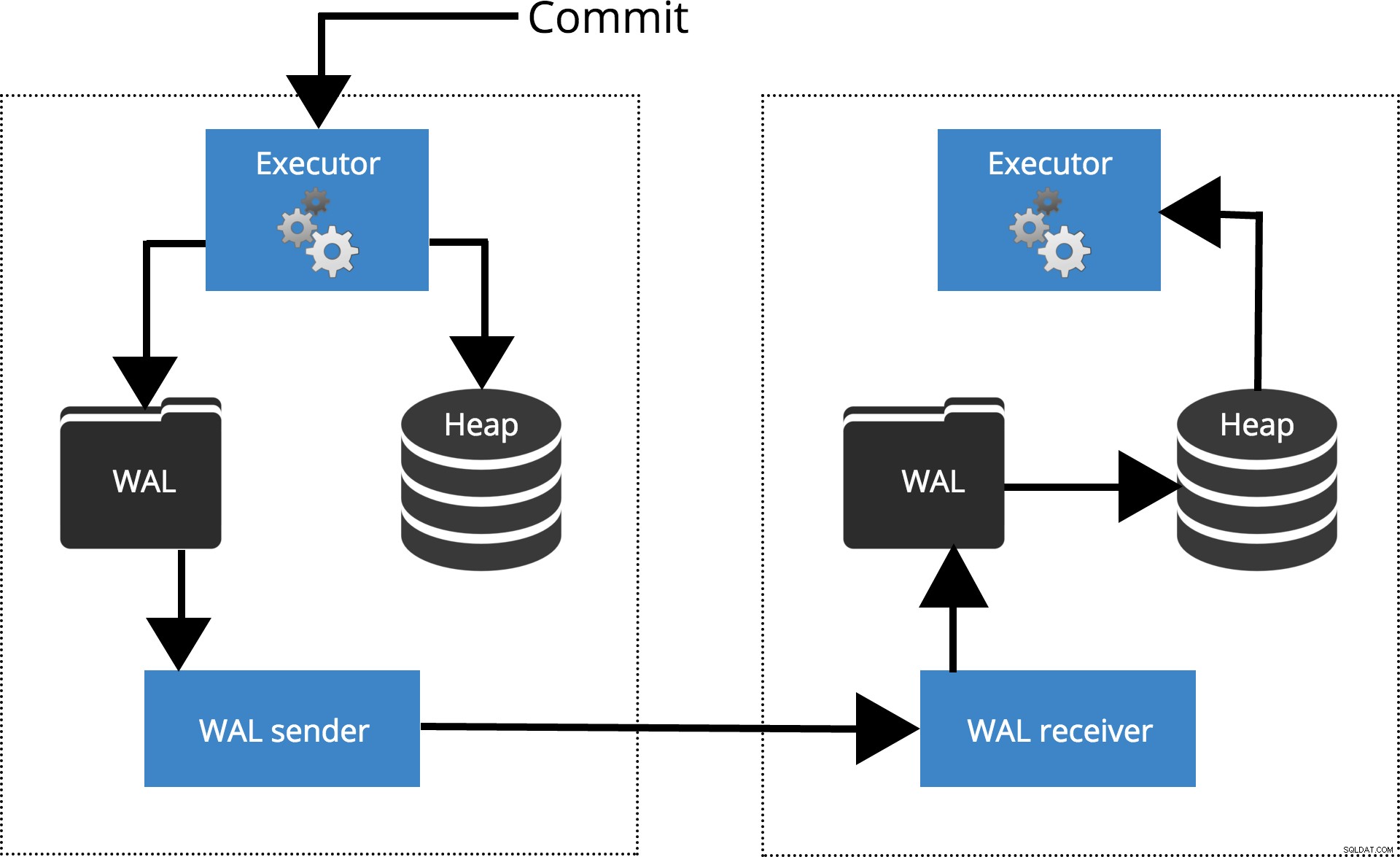
Fig.1 Hoe replicatie werkt
synchronous_commit =uit
Wanneer we sychronous_commit = off, de COMMIT wacht niet tot het transactierecord naar de schijf is gewist. Dit wordt gemarkeerd in Fig.2 hieronder.
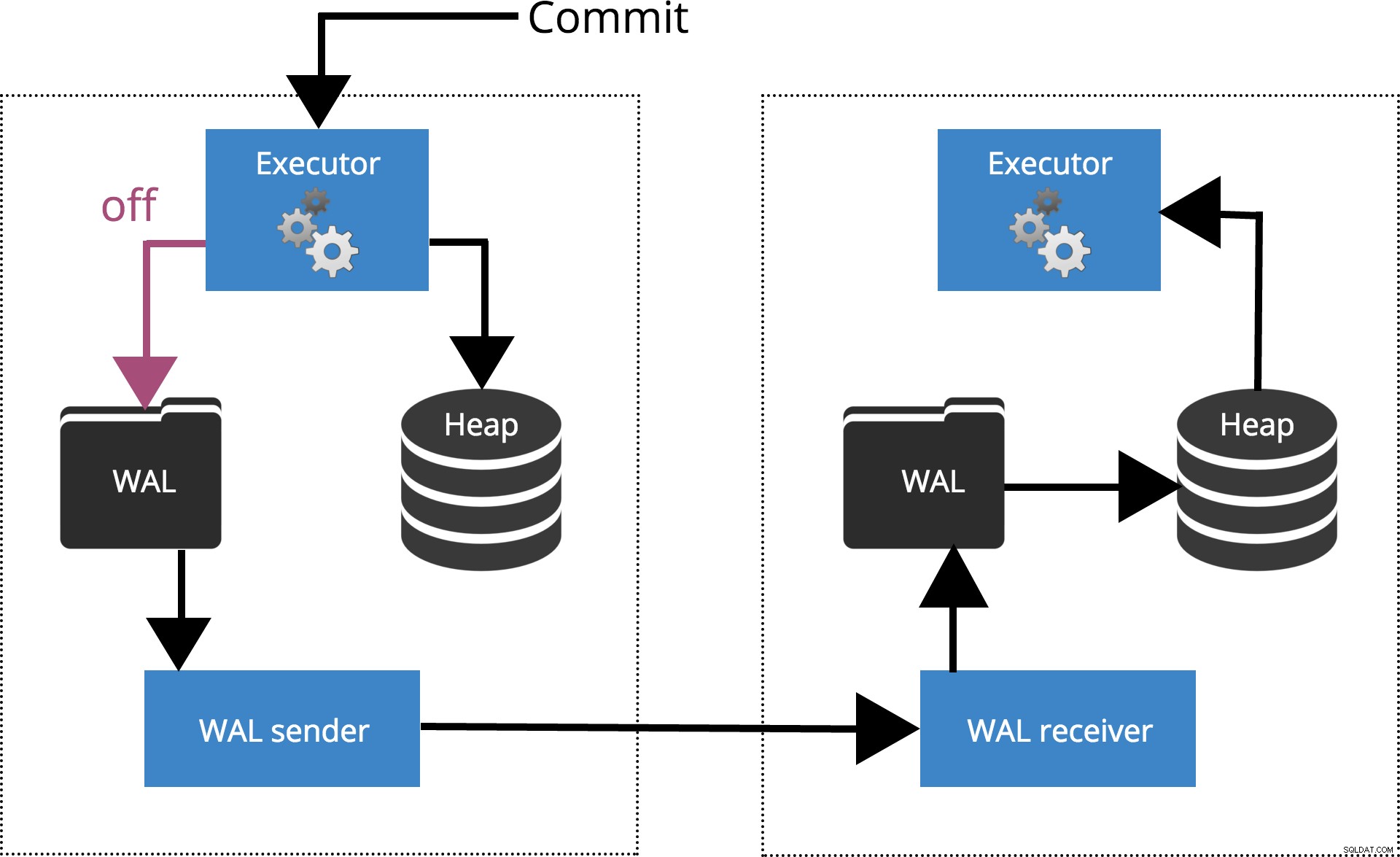
Fig.2 synchronous_commit =uit
synchronous_commit =lokaal
Wanneer we synchronous_commit = local, de COMMIT wacht totdat het transactierecord naar de lokale schijf is gewist. Dit wordt gemarkeerd in Fig.3 hieronder.
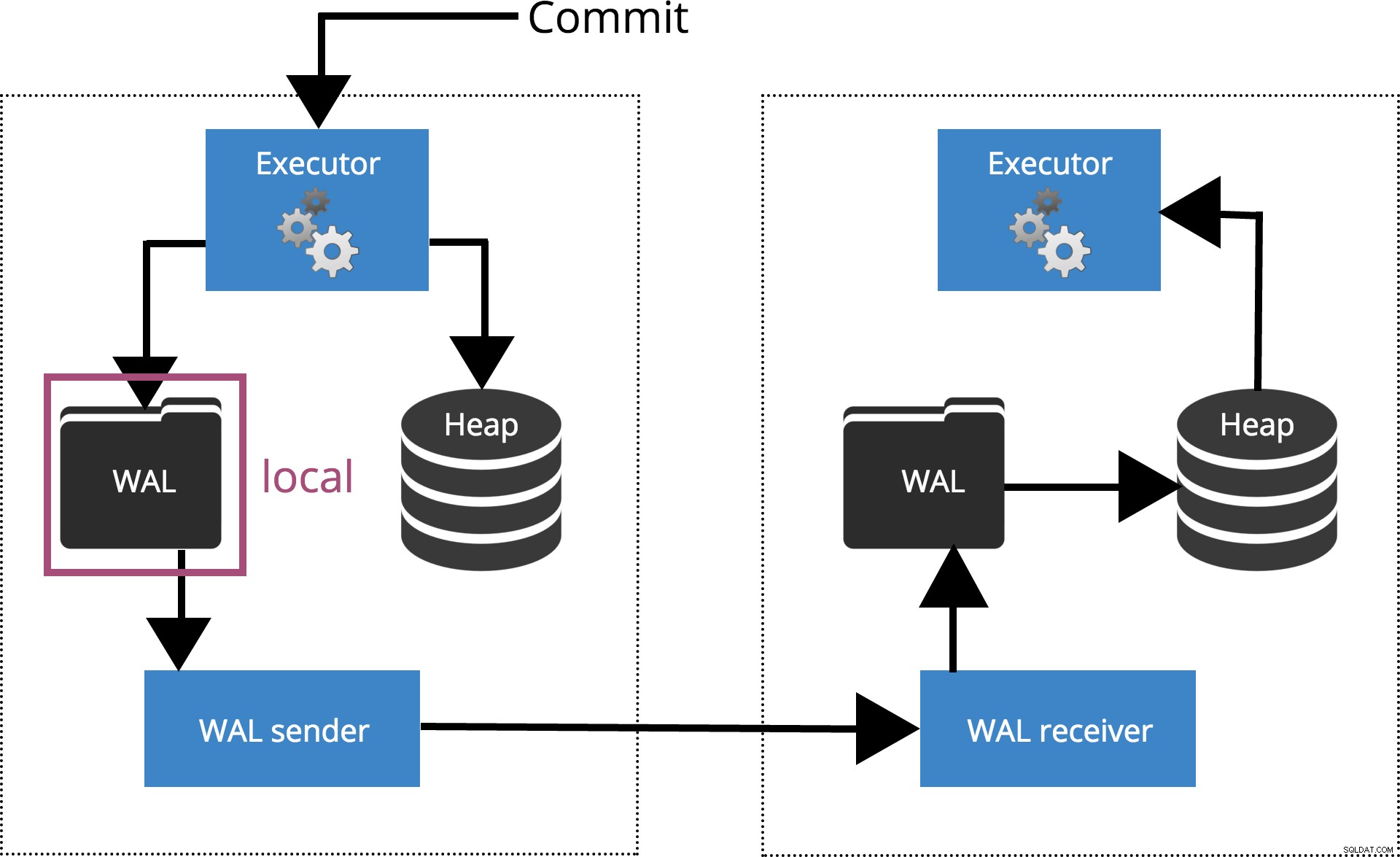
Fig.3 synchronous_commit =local
synchronous_commit =aan (standaard)
Wanneer we synchronous_commit = on, de COMMIT zal wachten tot de server(s) gespecificeerd door sychronous_standby_names bevestigen dat het transactierecord veilig naar de schijf is geschreven. Dit wordt gemarkeerd in Fig.4 hieronder.
Opmerking: Wanneer sychronous_standby_names leeg is, gedraagt deze instelling zich hetzelfde als synchronous_commit = local .
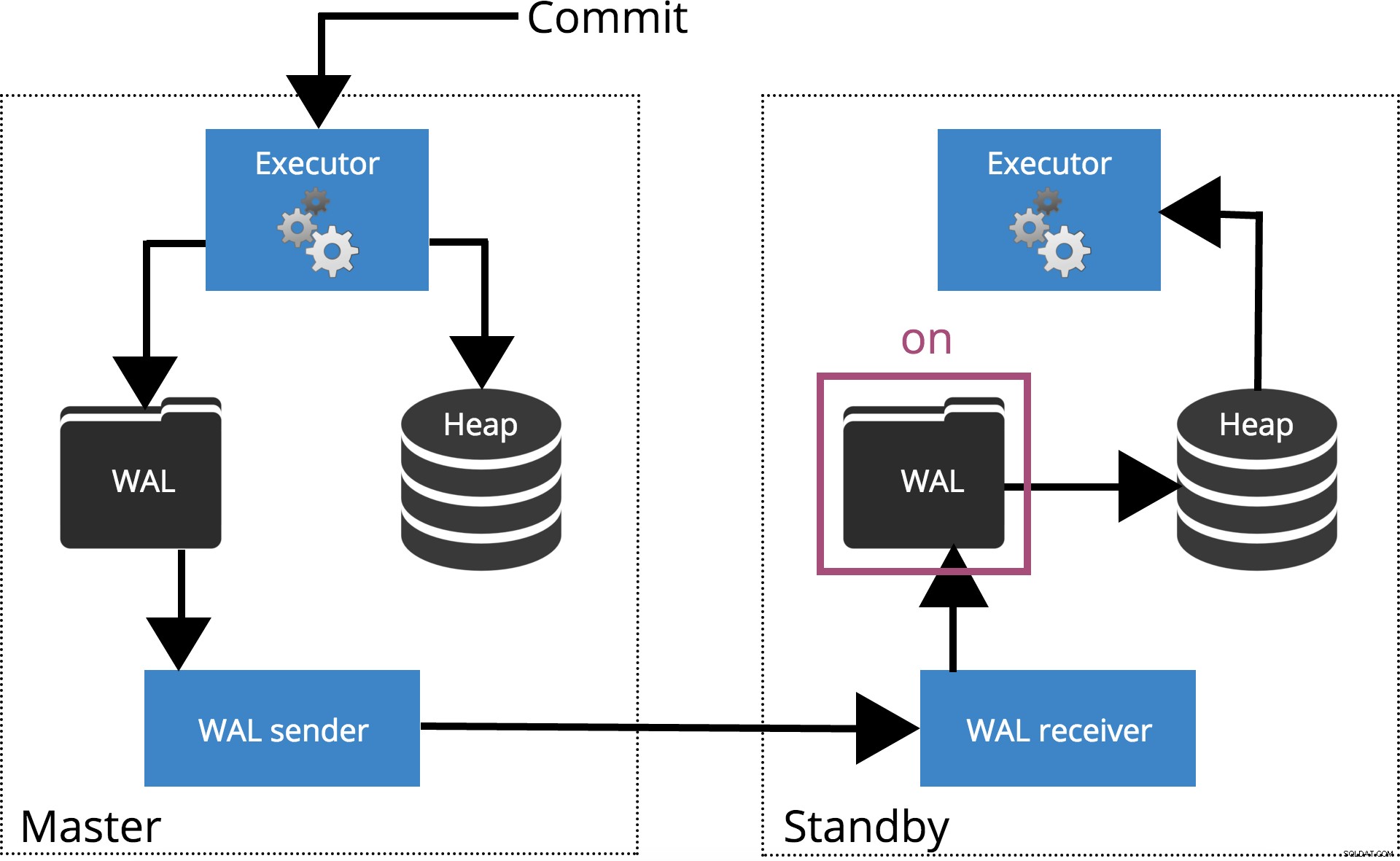
Fig.4 synchronous_commit =aan
synchronous_commit =remote_write
Wanneer we synchronous_commit = remote_write, de COMMIT zal wachten tot de server(s) gespecificeerd door sychronous_standby_names bevestig het schrijven van het transactierecord naar het besturingssysteem, maar heeft de schijf niet noodzakelijkerwijs bereikt. Dit wordt gemarkeerd in Fig.5 hieronder.
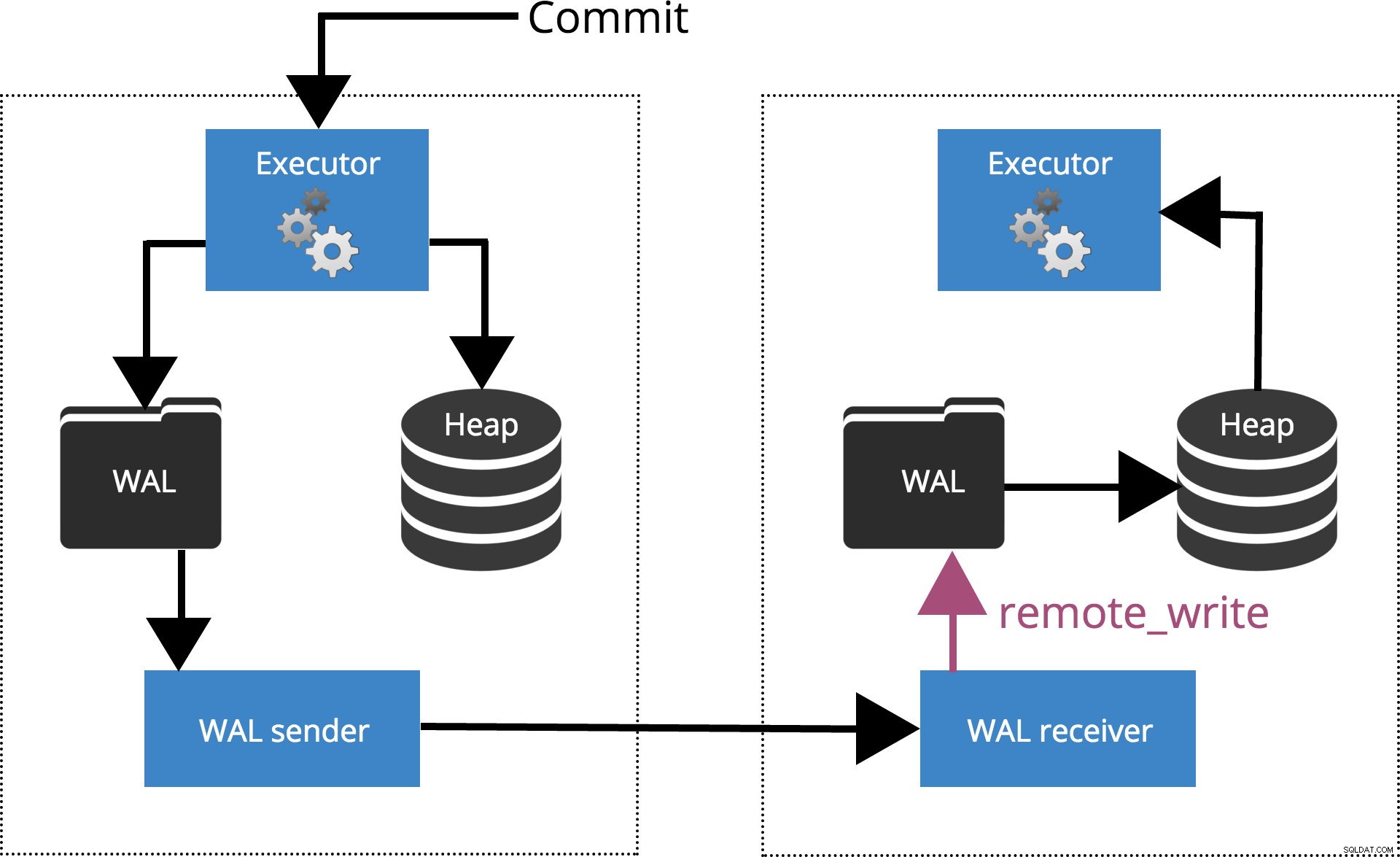
Fig.5 synchronous_commit =remote_write
synchronous_commit =remote_apply
Wanneer we synchronous_commit = remote_apply, de COMMIT zal wachten tot de server(s) gespecificeerd door sychronous_standby_names bevestig dat het transactierecord is toegepast op de database. Dit wordt gemarkeerd in Fig.6 hieronder.
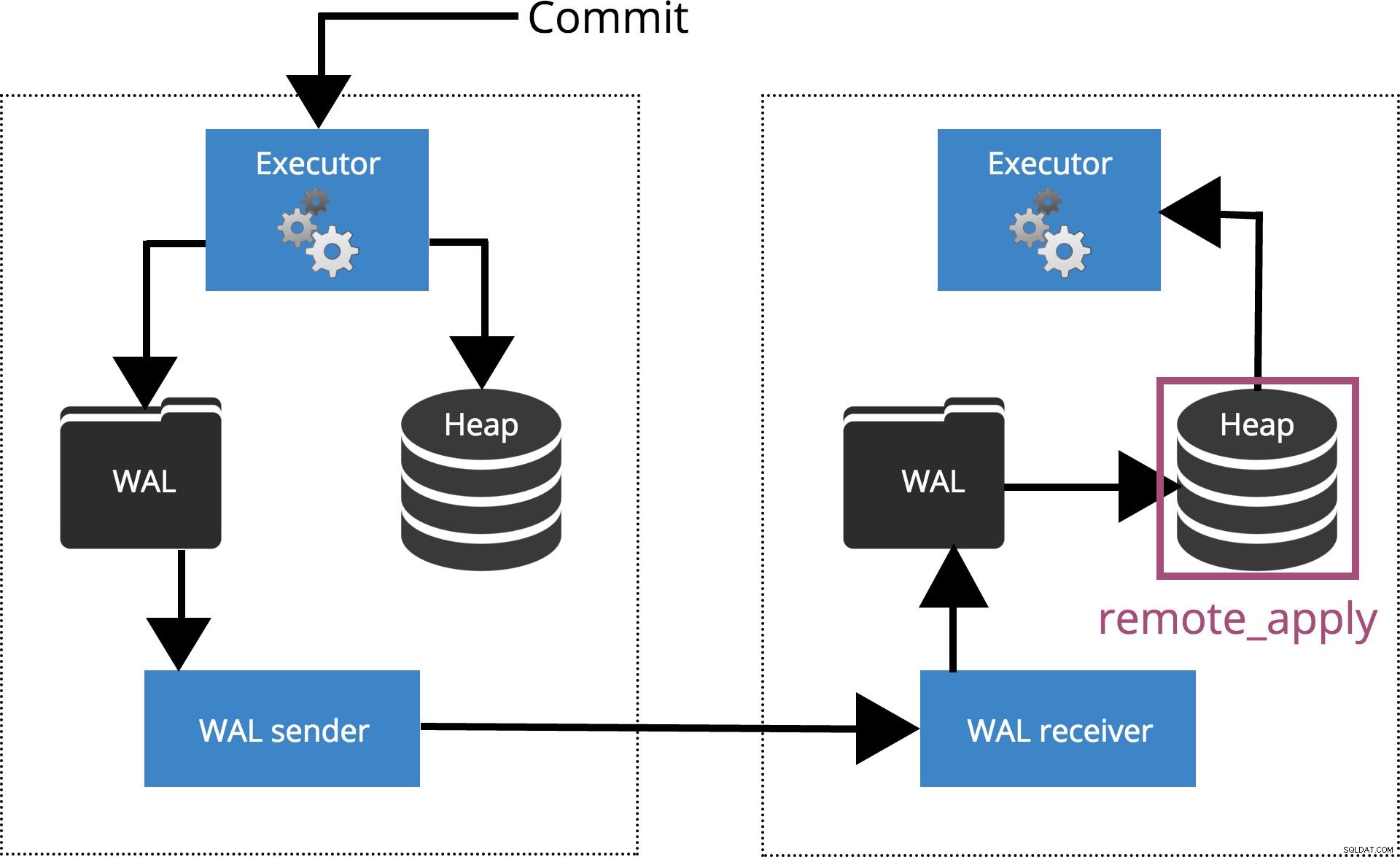
Fig.6 synchronous_commit =remote_apply
Laten we nu eens kijken naar sychronous_standby_names parameter in details, waarnaar hierboven wordt verwezen bij het instellen van synchronous_commit als on , remote_apply of remote_write .
synchronous_standby_names =‘standby_name [, …]’
De synchrone commit wacht op antwoord van een van de standbys die in de volgorde van prioriteit worden vermeld. Dit betekent dat als de eerste standby is aangesloten en streamt, de synchrone commit altijd zal wachten op een antwoord, zelfs als de tweede standby al heeft geantwoord. De speciale waarde van * kan worden gebruikt als stanby_name die overeenkomt met elke aangesloten stand-by.
synchronous_standby_names ='num (standby_name [, …])'
De synchrone commit wacht op antwoord van ten minste num aantal standbys in volgorde van prioriteit. Dezelfde regels als hierboven zijn van toepassing. Dus bijvoorbeeld het instellen van synchronous_standby_names = '2 (*)' zal synchrone commit laten wachten op antwoord van 2 willekeurige standby-servers.
synchronous_standby_names is leeg
Als deze parameter leeg is, zoals weergegeven, verandert het gedrag van de instelling synchronous_commit naar on , remote_write of remote_apply hetzelfde gedragen als local (dwz de COMMIT wacht alleen op het doorspoelen naar de lokale schijf).
Conclusie
In deze blogpost hebben we synchrone replicatie besproken en verschillende beveiligingsniveaus beschreven die beschikbaar zijn in Postgres. We gaan verder met logische replicatie in de volgende blogpost.
Referenties
Speciale dank aan mijn collega Petr Jelinek voor het idee voor illustraties.
PostgreSQL-documentatie
PostgreSQL 9 Administration Cookbook – Tweede editie