In 2014 schreef ik een artikel met de titel Performance Tuning the Whole Query Plan. Er werd gekeken naar manieren om een relatief klein aantal verschillende waarden uit een redelijk grote dataset te vinden, en kwam tot de conclusie dat een recursieve oplossing optimaal zou kunnen zijn. In dit vervolgbericht wordt de vraag voor SQL Server 2019 opnieuw bekeken, met een groter aantal rijen.
Testomgeving
Ik zal de Stack Overflow 2013-database van 50 GB gebruiken, maar elke grote tabel met een laag aantal verschillende waarden zou voldoende zijn.
Ik ga op zoek naar verschillende waarden in de BountyAmount kolom van de dbo.Votes tabel, weergegeven in oplopende volgorde van het premiebedrag. De tabel Stemmen heeft iets minder dan 53 miljoen rijen (52.928.720 om precies te zijn). Er zijn slechts 19 verschillende premiebedragen, waaronder NULL .
De Stack Overflow 2013-database wordt geleverd zonder niet-geclusterde indexen om de downloadtijd te minimaliseren. Er is een geclusterde primaire sleutelindex op de Id kolom van de dbo.Votes tafel. Het is ingesteld op SQL Server 2008-compatibiliteit (niveau 100), maar we beginnen met een modernere instelling van SQL Server 2017 (niveau 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
De tests zijn uitgevoerd op mijn laptop met SQL Server 2019 CU 2. Deze machine heeft vier i7 CPU's (hyperthreaded naar 8) met een basissnelheid van 2,4 GHz. Het heeft 32 GB RAM, met 24 GB beschikbaar voor de SQL Server 2019-instantie. De kostendrempel voor parallellisme is ingesteld op 50.
Elk testresultaat vertegenwoordigt het beste van tien runs, met alle vereiste gegevens en indexpagina's in het geheugen.
1. Geclusterde index rij winkel
Om een basislijn in te stellen, is de eerste run een seriële query zonder enige nieuwe indexering (en onthoud dat dit is met de database ingesteld op compatibiliteitsniveau 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Dit scant de geclusterde index en gebruikt een rijmodus hash-aggregaat om de verschillende waarden van BountyAmount te vinden :
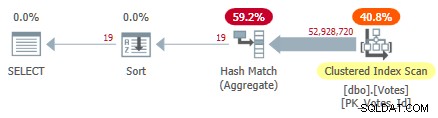 Seriële geclusterde indexplan
Seriële geclusterde indexplan
Dit duurt 10.500ms te voltooien, met dezelfde hoeveelheid CPU-tijd. Onthoud dat dit de beste tijd is voor meer dan tien runs met alle gegevens in het geheugen. Automatisch gemaakte voorbeeldstatistieken op het BountyAmount kolom zijn gemaakt bij de eerste run.
Ongeveer de helft van de verstreken tijd wordt besteed aan de Clustered Index Scan en ongeveer de helft aan het Hash Match Aggregate. De Sort heeft slechts 19 rijen om te verwerken, dus het verbruikt slechts 1 ms of zo. Alle operators in dit plan gebruiken uitvoering in rijmodus.
De MAXDOP 1 . verwijderen hint geeft een parallel plan:
 Parallel geclusterd indexplan
Parallel geclusterd indexplan
Dit is het plan dat de optimizer kiest zonder enige hints in mijn configuratie. Het retourneert resultaten in 4.200 ms met in totaal 32.800 ms CPU (bij DOP 8).
2. Niet-geclusterde index
Scan de hele tabel om alleen het BountyAmount te vinden lijkt inefficiënt, dus het is normaal om te proberen een niet-geclusterde index toe te voegen aan slechts de ene kolom die deze zoekopdracht nodig heeft:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Het duurt even voordat deze index is gemaakt (1m 40s). De MAXDOP 1 query gebruikt nu een Stream Aggregate omdat de optimizer de niet-geclusterde index kan gebruiken om rijen te presenteren in BountyAmount bestelling:
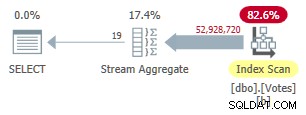 Seriële niet-geclusterde rijmodusplan
Seriële niet-geclusterde rijmodusplan
Dit duurt 9.300 ms (verbruikt dezelfde hoeveelheid CPU-tijd). Een nuttige verbetering ten opzichte van de oorspronkelijke 10.500ms, maar nauwelijks wereldschokkend.
De MAXDOP 1 . verwijderen hint geeft een parallel plan met lokale (per-thread) aggregatie:
 Parallel niet-geclusterd rijmodusplan
Parallel niet-geclusterd rijmodusplan
Dit wordt uitgevoerd in 3.400ms met 25.800 ms CPU-tijd. We kunnen misschien beter met rij- of paginacompressie op de nieuwe index, maar ik wil doorgaan naar meer interessante opties.
3. Batchmodus in rijopslag (BMOR)
Stel nu de database in op SQL Server 2019-compatibiliteitsmodus met:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Dit geeft de optimizer de vrijheid om de batchmodus in de rijopslag te kiezen als hij dit de moeite waard acht. Dit kan enkele voordelen bieden van uitvoering in batchmodus zonder dat een kolomarchiefindex nodig is. Zie voor diepgaande technische details en ongedocumenteerde opties het uitstekende artikel van Dmitry Pilugin over dit onderwerp.
Helaas kiest de optimizer nog steeds voor volledige uitvoering in rijmodus met behulp van stroomaggregaten voor zowel de seriële als parallelle testquery's. Om een batchmodus op het uitvoeringsplan voor rijopslag te krijgen, kunnen we een hint toevoegen om aggregatie aan te moedigen met behulp van hash-match (die in batchmodus kan worden uitgevoerd):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Dit geeft ons een plan met alle operators die in batchmodus werken:
 Seriële batchmodus op rijwinkelplan
Seriële batchmodus op rijwinkelplan
Resultaten worden geretourneerd in 2600 ms (alle CPU zoals gewoonlijk). Dit is al sneller dan de parallel rijmodusplan (3.400 ms verstreken) terwijl veel minder CPU wordt gebruikt (2.600 ms versus 25.800 ms).
De MAXDOP 1 . verwijderen hint (maar behoud HASH GROUP ) geeft een parallelle batchmodus op het rijwinkelplan:
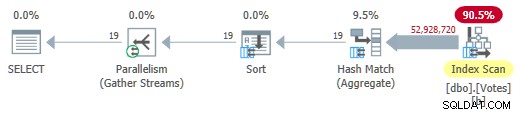 Parallelle batchmodus op rijwinkelplan
Parallelle batchmodus op rijwinkelplan
Dit loopt in slechts 725ms met een CPU van 5.700 ms.
4. Batchmodus in Column Store
Het resultaat van de parallelle batchmodus bij het opslaan van rijen is een indrukwekkende verbetering. We kunnen het nog beter doen door een kolomopslagrepresentatie van de gegevens te bieden. Om al het andere hetzelfde te houden, zal ik een niet-geclusterde . toevoegen column store index op alleen de kolom die we nodig hebben:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Dit wordt ingevuld vanuit de bestaande b-tree niet-geclusterde index en duurt slechts 15 seconden om te maken.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); De optimizer kiest een volledig batchmodusplan inclusief een kolomopslagindexscan:
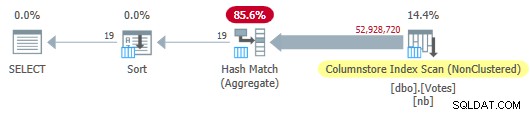 Seriële kolomopslagplan
Seriële kolomopslagplan
Dit loopt in 115 ms dezelfde hoeveelheid CPU-tijd gebruiken. De optimizer kiest dit plan zonder enige hints over mijn systeemconfiguratie, omdat de geschatte kosten van het plan lager zijn dan de kostendrempel voor parallellisme .
Om een parallel plan te krijgen, kunnen we ofwel de kostendrempel verlagen of een ongedocumenteerde hint gebruiken:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); Het parallelle plan is in ieder geval:
 Parallel winkelplan met kolommen
Parallel winkelplan met kolommen
Verstreken tijd voor zoekopdracht is nu teruggebracht tot 30ms , terwijl het 210 ms CPU verbruikt.
5. Batchmodus in Column Store met Push Down
De huidige beste uitvoeringstijd van 30 ms is indrukwekkend, vooral in vergelijking met de oorspronkelijke 10.500 ms. Toch is het een beetje jammer dat we bijna 53 miljoen rijen (in 58.868 batches) van de Scan naar het Hash Match Aggregate moeten doorgeven.
Het zou mooi zijn als SQL Server de aggregatie naar beneden in de scan zou kunnen duwen en alleen verschillende waarden rechtstreeks uit de kolomopslag zou kunnen retourneren. Je zou kunnen denken dat we de DISTINCT . moeten uitdrukken als een GROUP BY om Grouped Aggregate Pushdown te krijgen, maar dat is logischerwijs overbodig en in ieder geval niet het hele verhaal.
Met de huidige SQL Server-implementatie moeten we eigenlijk een aggregaat berekenen om aggregaat pushdown te activeren. Meer dan dat, we moeten gebruiken het totale resultaat op de een of andere manier, of de optimizer zal het gewoon als onnodig verwijderen.
Een manier om de query te schrijven om geaggregeerde pushdown te bereiken, is door een logisch redundante secundaire volgordevereiste toe te voegen:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Het serieplan is nu:
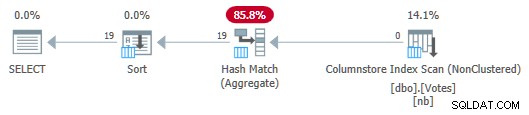 Seriële kolomopslagplan met geaggregeerde push-down
Seriële kolomopslagplan met geaggregeerde push-down
Merk op dat er geen rijen worden doorgegeven van de scan naar het aggregaat! Onder de dekens, gedeeltelijke aggregaten van het BountyAmount waarden en de bijbehorende rijtellingen worden doorgegeven aan het Hash Match Aggregate, dat de gedeeltelijke aggregaten optelt om het vereiste uiteindelijke (globale) aggregaat te vormen. Dit is zeer efficiënt, zoals wordt bevestigd door de verstreken tijd van 13ms (dit is allemaal CPU-tijd). Ter herinnering:het vorige seriële plan duurde 115 ms.
Om de set compleet te maken, kunnen we een parallelle versie krijgen op dezelfde manier als voorheen:
 Parallel winkelplan voor kolommen met geaggregeerde push-down
Parallel winkelplan voor kolommen met geaggregeerde push-down
Dit duurt 7ms met in totaal 40ms CPU.
Het is jammer dat we een aggregaat moeten berekenen en gebruiken dat we niet alleen nodig hebben om naar beneden te duwen. Misschien wordt dit in de toekomst verbeterd zodat DISTINCT en GROUP BY zonder aggregaten kan naar de scan worden geduwd.
6. Rijmodus Recursieve algemene tabeluitdrukking
In het begin beloofde ik de recursieve CTE-oplossing die werd gebruikt om een klein aantal duplicaten in een grote dataset te vinden, opnieuw te bekijken. Het implementeren van de huidige vereiste met behulp van die techniek is vrij eenvoudig, hoewel de code noodzakelijkerwijs langer is dan alles wat we tot nu toe hebben gezien:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Het idee vindt zijn oorsprong in een zogenaamde index-skip-scan:we vinden de laagste waarde van belang aan het begin van de oplopende geordende b-tree-index, en proberen vervolgens de volgende waarde in indexvolgorde te vinden, enzovoort. De structuur van een b-tree-index maakt het vinden van de volgende hoogste waarde zeer efficiënt — het is niet nodig om door de duplicaten te bladeren.
De enige echte truc hier is om de optimizer te overtuigen om ons toe te staan TOP te gebruiken in het 'recursieve' deel van de CTE om één kopie van elke afzonderlijke waarde te retourneren. Raadpleeg mijn vorige artikel als je een opfriscursus nodig hebt over de details.
Het uitvoeringsplan (hier in het algemeen uitgelegd door Craig Freedman) is:
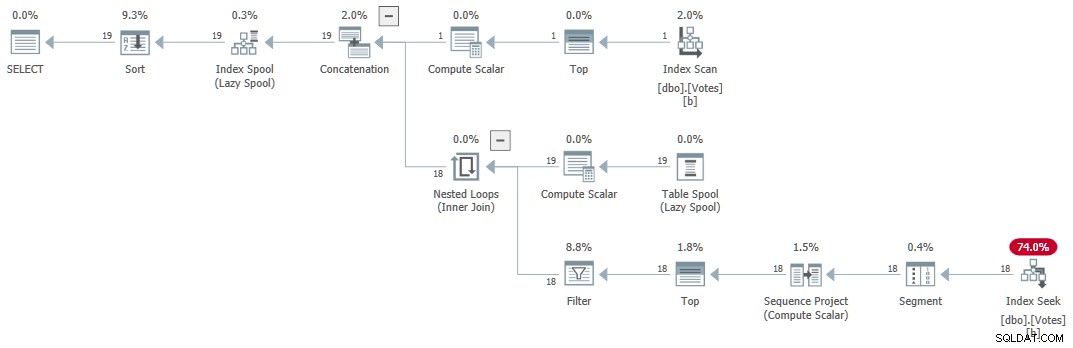 Seriële recursieve CTE
Seriële recursieve CTE
De zoekopdracht retourneert de juiste resultaten in 1ms gebruikmakend van 1 ms CPU, volgens Sentry One Plan Explorer.
7. Iteratieve T-SQL
Soortgelijke logica kan worden uitgedrukt met een WHILE lus. De code is mogelijk gemakkelijker te lezen en te begrijpen dan de recursieve CTE. Het voorkomt ook dat je trucjes moet gebruiken om de vele beperkingen op het recursieve deel van een CTE te omzeilen. De prestaties zijn concurrerend rond de 15ms. Deze code wordt verstrekt voor interesse en is niet opgenomen in de prestatieoverzichtstabel.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Overzichtstabel prestaties
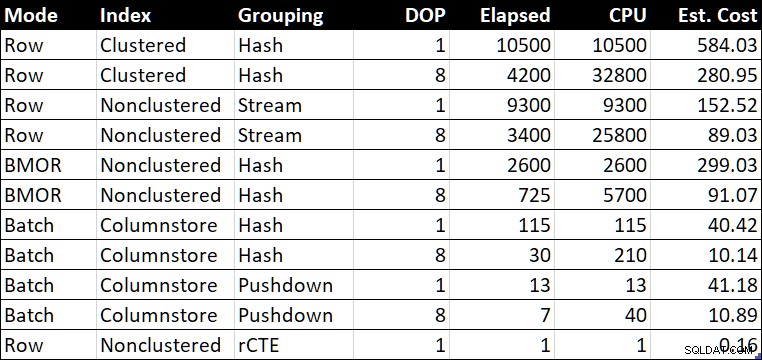 Overzichtstabel prestaties (duur / CPU in milliseconden)
Overzichtstabel prestaties (duur / CPU in milliseconden)
De "Est. Kosten” kolom toont de kostenraming van de optimizer voor elke zoekopdracht zoals gerapporteerd op het testsysteem.
Laatste gedachten
Het vinden van een klein aantal verschillende waarden lijkt misschien een vrij specifieke vereiste, maar ik ben het in de loop der jaren vrij vaak tegengekomen, meestal als onderdeel van het afstemmen van een grotere zoekopdracht.
De laatste paar voorbeelden waren vrij dicht bij de uitvoering. Veel mensen zouden blij zijn met de resultaten van minder dan een seconde, afhankelijk van de prioriteiten. Zelfs het resultaat van de seriële batchmodus bij het opslaan van rijen van 2.600 ms is goed te vergelijken met de beste parallel rijmodusplannen, wat een goed voorteken is voor aanzienlijke versnellingen door alleen te upgraden naar SQL Server 2019 en databasecompatibiliteitsniveau 150 in te schakelen. Niet iedereen zal snel naar kolomopslagopslag kunnen gaan, en het zal sowieso niet altijd de juiste oplossing zijn . Batchmodus in rijopslag biedt een handige manier om enkele van de mogelijke voordelen met kolomopslag te behalen, ervan uitgaande dat u de optimizer kunt overtuigen om ervoor te kiezen deze te gebruiken.
Het geaggregeerde resultaat van de parallelle kolomopslag van 57 miljoen rijen verwerkt in 7 ms (met 40 ms CPU) is opmerkelijk, vooral gezien de hardware. Het seriële totaal push-down resultaat van 13ms is even indrukwekkend. Het zou geweldig zijn als ik geen zinloos totaalresultaat had hoeven toevoegen om deze plannen te krijgen.
Voor degenen die de overstap naar SQL Server 2019 of kolomopslagopslag nog niet kunnen maken, is de recursieve CTE nog steeds een haalbare en efficiënte oplossing wanneer er een geschikte b-tree-index bestaat en het aantal vereiste afzonderlijke waarden gegarandeerd vrij klein is. Het zou mooi zijn als SQL Server toegang zou hebben tot een b-tree zoals deze zonder een recursieve CTE (of gelijkwaardige iteratieve looping T-SQL-code te hoeven schrijven met behulp van WHILE ).
Een andere mogelijke oplossing voor het probleem is het creëren van een geïndexeerde weergave. Dit zorgt voor duidelijke waarden met grote efficiëntie. De keerzijde is, zoals gebruikelijk, dat elke wijziging in de onderliggende tabel het aantal rijen moet bijwerken dat is opgeslagen in de gerealiseerde weergave.
Elk van de hier gepresenteerde oplossingen heeft zijn plaats, afhankelijk van de vereisten. Het hebben van een breed scala aan tools is over het algemeen een goede zaak bij het afstemmen van queries. Meestal zou ik een van de batchmodusoplossingen kiezen omdat hun prestaties behoorlijk voorspelbaar zijn, ongeacht hoeveel duplicaten er zijn.