De meeste OLTP-workloads hebben betrekking op willekeurig schijf-I/O-gebruik. Wetende dat schijven (inclusief SSD) langzamer presteren dan het gebruik van RAM, gebruiken databasesystemen caching om de prestaties te verbeteren. Caching heeft alles te maken met het opslaan van gegevens in het geheugen (RAM) voor snellere toegang op een later tijdstip.
PostgreSQL gebruikt ook caching van zijn gegevens in een ruimte genaamd shared_buffers. In deze blog zullen we deze functionaliteit onderzoeken om u te helpen de prestaties te verbeteren.
Basisbeginselen van PostgreSQL-caching
Laten we, voordat we dieper ingaan op het concept van caching, de basis wat opfrissen.
In PostgreSQL worden gegevens georganiseerd in de vorm van pagina's met een grootte van 8 KB, en elke dergelijke pagina kan meerdere tupels bevatten (afhankelijk van de grootte van de tuple). Een simplistische weergave zou als volgt kunnen zijn:
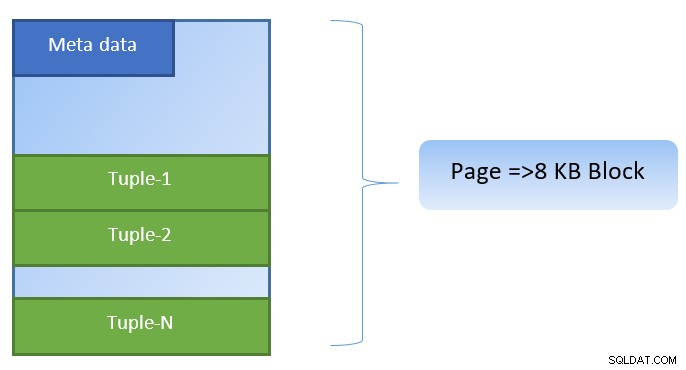
PostgreSQL slaat het volgende op in de cache om de toegang tot gegevens te versnellen:
- Gegevens in tabellen
- Indexen
- Uitvoeringsplannen voor query's
Terwijl het cachen van het query-uitvoeringsplan zich richt op het opslaan van CPU-cycli; caching voor tabelgegevens en indexgegevens is gericht op het besparen van kostbare schijf-I/O-bewerkingen.
PostgreSQL laat gebruikers bepalen hoeveel geheugen ze willen reserveren voor het bewaren van een dergelijke cache voor gegevens. De relevante instelling is shared_buffers in het postgresql.conf-configuratiebestand. De eindige waarde van shared_buffers bepaalt hoeveel pagina's op elk moment in de cache kunnen worden opgeslagen.
Terwijl een query wordt uitgevoerd, zoekt PostgreSQL naar de pagina op de schijf die de relevante tuple bevat en duwt deze naar de cache van shared_buffers voor laterale toegang. De volgende keer dat dezelfde tuple (of een andere tuple op dezelfde pagina) moet worden geopend, kan PostgreSQL schijf-IO opslaan door deze in het geheugen te lezen.
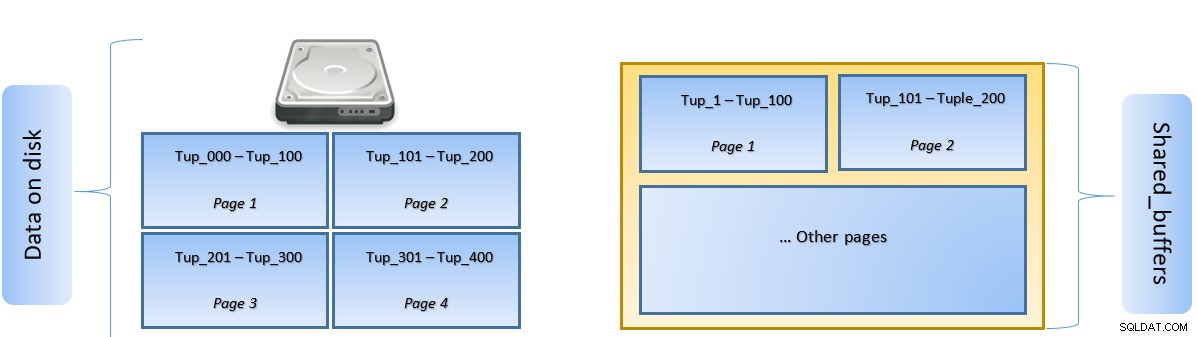
In de bovenstaande afbeelding, Pagina-1 en Pagina-2 van een bepaald tabel zijn gecached. In het geval dat een gebruikersquery toegang moet krijgen tot tuples tussen Tuple-1 en Tuple-200, kan PostgreSQL het zelf uit het RAM halen.
Als de query echter toegang moet krijgen tot Tuples 250 tot 350, moet deze schijf I/O uitvoeren voor pagina 3 en pagina 4. Alle verdere toegang voor Tuple 201 tot 400 wordt opgehaald uit de cache en schijf-I/O is niet nodig, waardoor de query sneller wordt uitgevoerd.
Op een hoog niveau volgt PostgreSQL het LRU-algoritme (minst recent gebruikt) om identificeer de pagina's die uit de cache moeten worden verwijderd. Met andere woorden, een pagina die slechts één keer wordt geopend, heeft een grotere kans op uitzetting (vergeleken met een pagina die meerdere keren wordt geopend), voor het geval een nieuwe pagina door PostgreSQL in de cache moet worden opgehaald.
PostgreSQL-caching in actie
Laten we een voorbeeld uitvoeren en de impact van cache op de prestaties bekijken.
Start PostgreSQL met shared_buffer ingesteld op standaard 128 MB
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startMaak verbinding met de server en maak een dummy-tabel tblDummy en een index op c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Vul dummy-gegevens met 200000 tuples, zodat er 10.000 unieke p_id's zijn en voor elke p_id 200 c_id's
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Start de server opnieuw op om de cache te wissen. Voer nu een query uit en controleer de tijd die nodig is om hetzelfde uit te voeren
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msControleer vervolgens de blokken die van de schijf zijn gelezen
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0In het bovenstaande voorbeeld werden er 1000 blokken van de schijf gelezen om teltupels te vinden waarbij c_id =1. Het kostte 160 ms omdat er schijf-I/O bij betrokken was om die records van schijf op te halen.
Uitvoering is sneller als dezelfde query opnieuw wordt uitgevoerd, aangezien alle blokken zich in dit stadium nog in de cache van de PostgreSQL-server bevinden
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msen blokken die van de schijf worden gelezen versus van de cache
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Het is van bovenaf duidelijk dat aangezien alle blokken uit de cache werden gelezen en er geen schijf-I/O nodig was. Dit gaf dus ook sneller de resultaten.
De grootte van de PostgreSQL-cache instellen
De grootte van de cache moet worden afgestemd in een productieomgeving in overeenstemming met de hoeveelheid RAM die beschikbaar is en de query's die moeten worden uitgevoerd.
Als voorbeeld:een gedeelde_buffer van 128 MB is mogelijk niet voldoende om alle gegevens in de cache op te slaan als de query meer tupels zou ophalen:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Verander de gedeelde_buffer in 1024 MB om de heap_blks_hit te vergroten.
In feite, gezien de zoekopdrachten (gebaseerd op c_id), kan in het geval dat gegevens opnieuw worden georganiseerd, ook een betere cache-hitverhouding worden bereikt met een kleinere gedeelde_buffer.
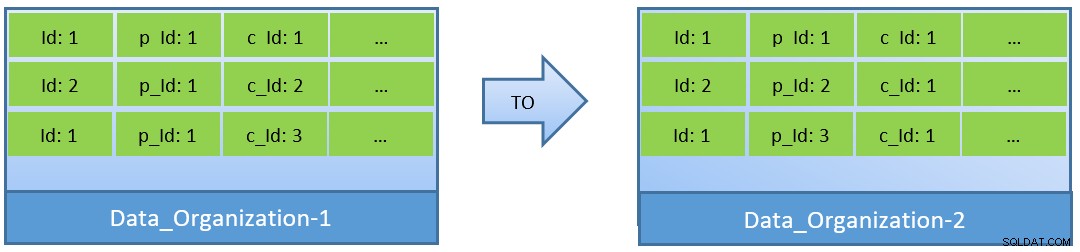
In Data_Organization-1 heeft PostgreSQL 1000 block reads nodig (en cacheverbruik ) voor het vinden van c_id=1. Aan de andere kant heeft PostgreSQL voor Data_Organisation-2 voor dezelfde zoekopdracht slechts 104 blokken nodig.
Minder blokken die nodig zijn voor dezelfde zoekopdracht, verbruiken uiteindelijk minder cachegeheugen en houden ook de uitvoeringstijd van de zoekopdracht geoptimaliseerd.
Conclusie
Hoewel de shared_buffer op PostgreSQL-procesniveau wordt onderhouden, wordt ook rekening gehouden met de cache op kernelniveau voor het identificeren van geoptimaliseerde plannen voor het uitvoeren van query's. Ik zal dit onderwerp in een latere serie blogs behandelen.