Elke PostgreSQL-release wordt geleverd met enkele belangrijke functieverbeteringen, maar wat even interessant is, is dat elke release ook de eerdere functies verbetert.
Aangezien PostgreSQL 13 binnenkort wordt uitgebracht, is het tijd om te kijken welke functies en verbeteringen de community ons brengt. Een van die verbeteringen zonder ruis is de "Verbetering van de logische replicatie voor partitionering."
Laten we deze functieverbetering begrijpen met een doorlopend voorbeeld.
Terminologie
Twee termen die belangrijk zijn om deze functie te begrijpen zijn:
- Partitietabellen
- Logische replicatie
Partitietabellen
Een manier om een grote tafel in meerdere fysieke stukken te splitsen om voordelen te behalen zoals:
- Verbeterde zoekopdrachtprestaties
- Sneller updates
- Sneller bulk laden en verwijderen
- Het ordenen van zelden gebruikte gegevens op langzame schijven
Sommige van deze voordelen worden bereikt door partitie opschonen (d.w.z. een queryplanner die partitiedefinitie gebruikt om te beslissen of een partitie moet worden gescand of niet) en het feit dat een partitie vrij gemakkelijker in het eindige geheugen past in vergelijking met een enorme tafel.
Een tabel is gepartitioneerd op basis van:
- Lijst
- Hash
- Bereik

Logische replicatie
Zoals de naam al aangeeft, is dit een replicatiemethode waarbij gegevens incrementeel worden gerepliceerd op basis van hun identiteit (bijv. sleutel). Het is niet vergelijkbaar met WAL- of fysieke replicatiemethoden waarbij gegevens byte-by-byte worden verzonden.
Op basis van een uitgever-abonnee-patroon moet de bron van de gegevens een uitgever definiëren, terwijl het doel moet worden geregistreerd als een abonnee. De interessante use-cases hiervoor zijn:
- Selectieve replicatie (slechts een deel van de database)
- Gelijktijdig schrijven naar twee instanties van database waar gegevens worden gerepliceerd
- Replicatie tussen verschillende besturingssystemen (bijv. Linux en Windows)
- Fijne beveiliging bij replicatie van gegevens
- Activeert uitvoering wanneer gegevens aan de kant van de ontvanger binnenkomen
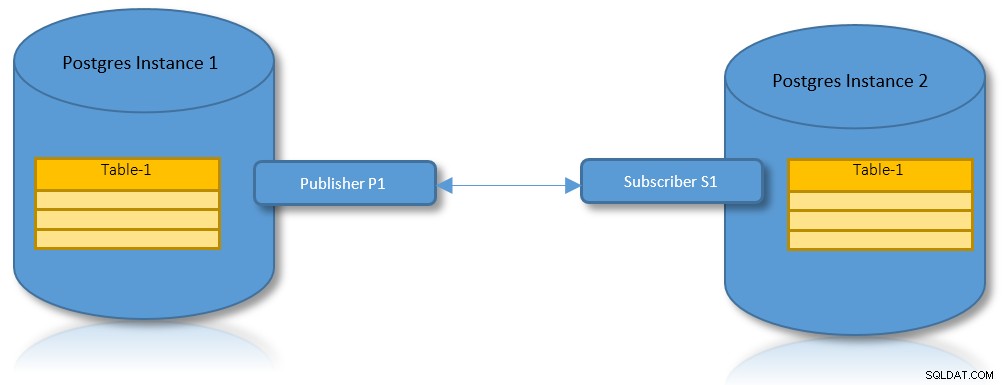
Logische replicatie voor partities
Met de voordelen van zowel logische replicatie als partitionering, is het een praktisch gebruiksscenario om een scenario te hebben waarin een gepartitioneerde tabel moet worden gerepliceerd over twee PostgreSQL-instanties.
Hier volgen de stappen om de verbetering in PostgreSQL 13 in deze context vast te stellen en te benadrukken.
Instellen
Overweeg een setup met twee knooppunten voor het uitvoeren van twee verschillende instanties die een gepartitioneerde tabel bevatten:
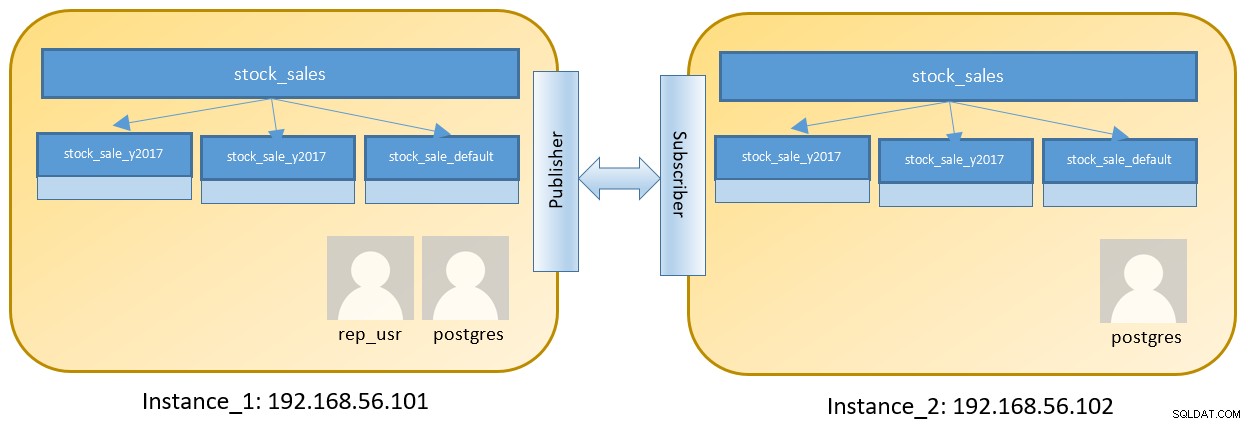
De stappen op Instance_1 zijn zoals hieronder na inloggen op 192.168.56.101 als postgres-gebruiker :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startHet instellen van 'wal_level' is specifiek ingesteld op 'logisch' om aan te geven dat logische replicatie zal worden gebruikt om gegevens van deze instantie te repliceren. Configuratiebestand 'pg_hba.conf' is ook aangepast om verbindingen vanaf 192.168.56.102 toe te staan.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Hoewel de postgres-rol standaard wordt gemaakt in de Instance_1-database, moet er ook een afzonderlijke gebruiker worden gemaakt die beperkte toegang heeft - waardoor het bereik alleen voor een bepaalde tabel wordt beperkt.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Bijna vergelijkbare instellingen zijn vereist voor Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startOpgemerkt moet worden dat aangezien Instance_2 geen gegevensbron zal zijn voor andere nodes, zowel de wal_level-instellingen als het pg_hba.conf-bestand geen extra instellingen nodig hebben. Onnodig te zeggen dat pg_hba.conf mogelijk moet worden bijgewerkt volgens de productiebehoeften.
Logische replicatie ondersteunt geen DDL, we moeten ook een tabelstructuur maken op Instance_2. Maak een gepartitioneerde tabel met behulp van de bovenstaande partitie-aanmaak om dezelfde tabelstructuur ook op Instance_2 te maken.
Logische replicatie instellen
Het instellen van logische replicatie wordt veel eenvoudiger met PostgreSQL 13. Tot aan PostgreSQL 12 was de structuur als volgt:
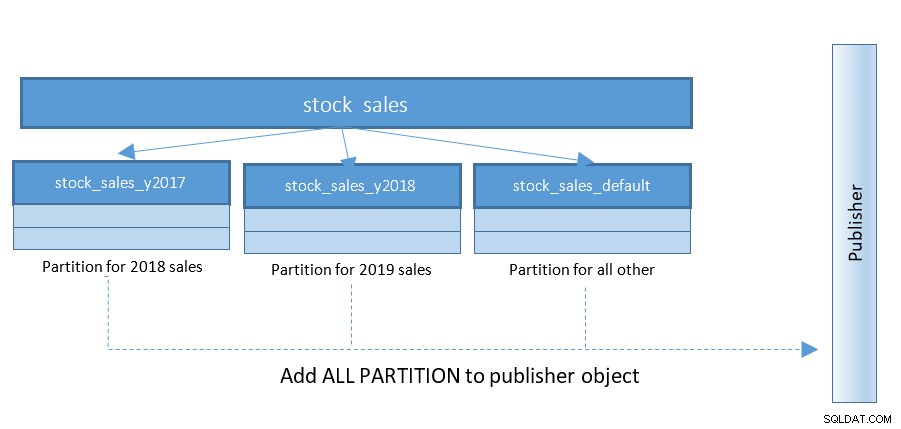
Met PostgreSQL 13 wordt het publiceren van partities veel eenvoudiger. Raadpleeg het onderstaande diagram en vergelijk met het vorige diagram:
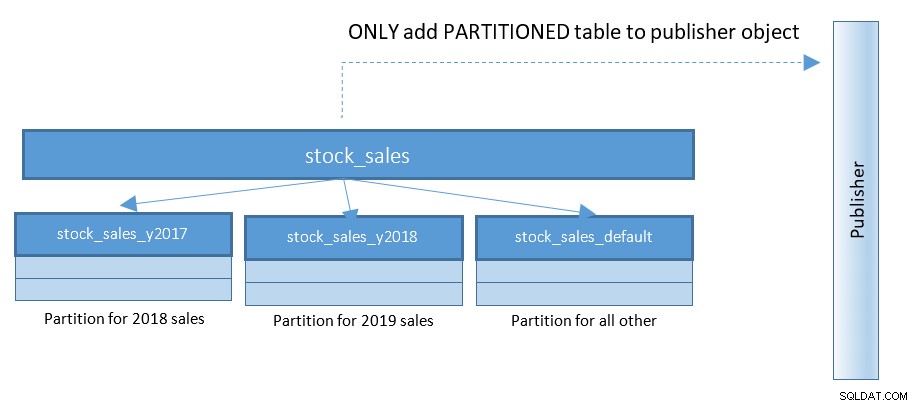
Met setups die woeden met honderden en duizenden gepartitioneerde tabellen - deze kleine verandering vereenvoudigt dingen in grote mate.
In PostgreSQL 13 zijn de instructies om een dergelijke publicatie te maken:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Configuratieparameter publish_via_partition_root is nieuw in PostgreSQL 13, waardoor het ontvangende knooppunt een iets andere bladhiërarchie kan hebben. Alleen het maken van publicaties op gepartitioneerde tabellen in PostgreSQL 12, geeft foutmeldingen zoals hieronder:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Als we de beperkingen van PostgreSQL 12 negeren en doorgaan met deze functie op PostgreSQL 13, moeten we een abonnee op Instance_2 vestigen met de volgende instructies:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Controleren of het echt werkt
We zijn zo goed als klaar met de hele installatie, maar laten we een paar tests uitvoeren om te zien of alles werkt.
Voeg op Instance_1 meerdere rijen in om ervoor te zorgen dat ze in meerdere partities spawnen:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Controleer de gegevens op Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Laten we nu eens kijken of logische replicatie werkt, zelfs als de leaf-knooppunten niet hetzelfde zijn aan de ontvangende kant.
Voeg nog een partitie toe aan Instance_1 en voeg record in:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Controleer de gegevens op Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Andere partitioneringsfuncties in PostgreSQL 13
Er zijn ook andere verbeteringen in PostgreSQL 13 die verband houden met partitionering, namelijk:
- Verbeteringen in samenvoegen tussen gepartitioneerde tabellen
- Gepartitioneerde tabellen ondersteunen nu VOORDAT triggers op rijniveau
Conclusie
Ik zal zeker de bovengenoemde twee aankomende functies in mijn volgende reeks blogs bekijken. Tot dan stof tot nadenken - met de gecombineerde kracht van partitionering en logische replicatie, komt PostgreSQL dichter bij een master-master setup?