Hoge beschikbaarheid is een vereiste voor veel systemen, ongeacht welke technologie u gebruikt. Dit is vooral belangrijk voor databases, omdat ze gegevens opslaan waar applicaties op vertrouwen. Afhankelijk van de vereisten zijn er verschillende manieren om een High Availability-omgeving voor PostgreSQL in te zetten, maar het is altijd nodig om een aanvullende tool te gebruiken omdat de native PostgreSQL-functies niet voldoende zijn.
In deze blog zullen we zien hoe Percona Distribution voor PostgreSQL voor hoge beschikbaarheid kan worden geïmplementeerd en welke tools daarvoor nodig zijn.
Percona-distributie voor PostgreSQL
Het is een verzameling hulpprogramma's om u te helpen bij het beheren van uw PostgreSQL-databasesysteem. Het installeert PostgreSQL en vult het aan met een selectie van extensies die het mogelijk maken om essentiële praktische taken efficiënt op te lossen, waaronder:
- pg_repack :Het herbouwt PostgreSQL-databaseobjecten.
- pgaudit :Het biedt gedetailleerde sessie- of object-auditregistratie via de standaard PostgreSQL-registratiefaciliteit.
- pgBackRest :Het is een back-up- en hersteloplossing voor PostgreSQL.
- Patroni :Het is een High Availability-oplossing voor PostgreSQL.
- pg_stat_monitor :Het verzamelt en aggregeert statistieken voor PostgreSQL en biedt histograminformatie.
- Een verzameling aanvullende PostgreSQL-bijdrage-extensies.
Hoge beschikbaarheid op PostgreSQL
Er zijn verschillende architecturen voor hoge beschikbaarheid van PostgreSQL, maar de meest voorkomende is een Master-Slave-topologie (Primary-Standby). Het is gebaseerd op één primaire database met een of meer standby-knooppunten. Deze standby-databases blijven gesynchroniseerd (of bijna gesynchroniseerd) met de primaire, afhankelijk van of de replicatie synchroon of asynchroon is. Als de hoofdserver uitvalt, bevat de stand-by bijna alle gegevens van de hoofdserver en kan deze snel worden omgezet in de nieuwe primaire databaseserver.
Maar een master-slave-configuratie is niet voldoende om effectief een hoge beschikbaarheid te garanderen, omdat je ook storingen moet afhandelen. Zodra een fout is gedetecteerd, moet u een standby-knooppunt kunnen selecteren en er een failover naar toe kunnen nemen met een zo kort mogelijke vertraging. PostgreSQL zelf bevat geen automatisch failover-mechanisme, dus dat vereist een aangepast script of tools van derden voor deze automatisering.
Nadat er een failover heeft plaatsgevonden, moeten de toepassing(en) hiervan op de hoogte worden gesteld, zodat ze het nieuwe primaire knooppunt kunnen gaan gebruiken. U moet ook de staat van onze architectuur evalueren na een failover, omdat u kunt werken in een situatie waarin alleen de nieuwe primaire actief is (d.w.z. u had een primaire en slechts één standby-knooppunt vóór het probleem). In dat geval moet u op de een of andere manier een nieuw stand-byknooppunt toevoegen om de master-slave-configuratie die u oorspronkelijk had voor hoge beschikbaarheid opnieuw te maken.
Om het te laten werken, heb je verschillende tools/diensten nodig om je bij deze taak te helpen.
Loadbalancers
Load balancers zijn tools die kunnen worden gebruikt om het verkeer van uw applicatie te beheren om het meeste uit uw database-architectuur te halen.
Het is niet alleen handig voor het balanceren van de belasting van onze databases, het helpt ook om applicaties om te leiden naar de beschikbare/gezonde nodes en zelfs om poorten met verschillende rollen te specificeren.
HAProxy is een load balancer die verkeer van de ene herkomst naar een of meer bestemmingen verdeelt en specifieke regels en/of protocollen voor deze taak kan definiëren. Als een van de bestemmingen niet meer reageert, wordt deze gemarkeerd als offline en wordt het verkeer naar de overige beschikbare bestemmingen gestuurd.
Keepalived is een service waarmee je een virtueel IP-adres kunt configureren binnen een actieve/passieve groep servers. Dit virtuele IP-adres is toegewezen aan een actieve server. Als deze server uitvalt, wordt het IP automatisch gemigreerd naar de "Secundaire" passieve server, waardoor deze op een transparante manier voor de systemen met hetzelfde IP kan blijven werken.
Om al deze dingen te implementeren, kunt u het handmatig doen, wat extra werk en tijdrovende taken met zich meebrengt, of u kunt het vanaf slechts één systeem doen met ClusterControl.
Laten we eens kijken hoe u uw bestaande Percona-distributie voor PostgreSQL naar ClusterControl kunt importeren en vervolgens hoe u een omgeving met hoge beschikbaarheid kunt configureren met HAProxy en Keepalive rond deze installatie vanuit een gebruiksvriendelijke en gebruiksvriendelijke interface.
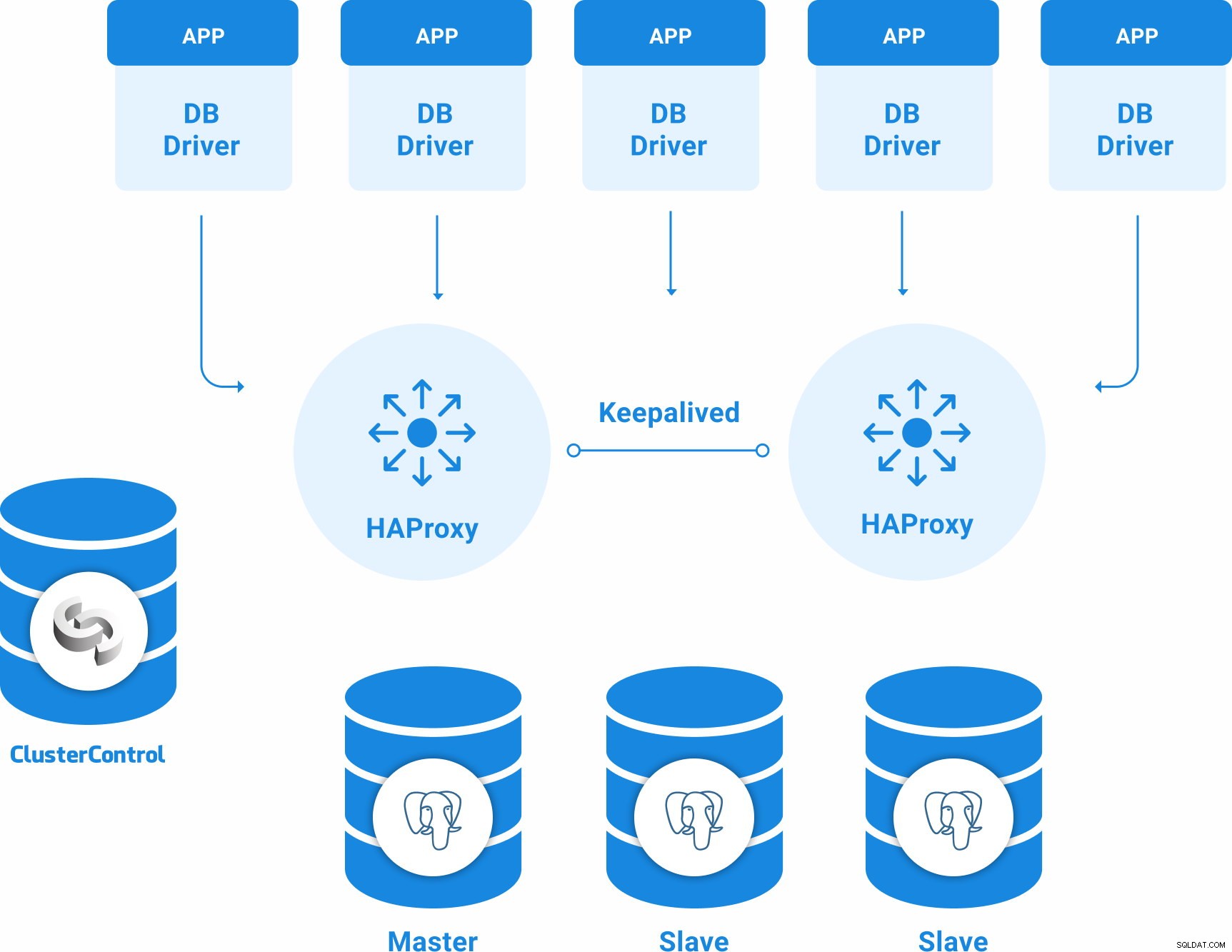
PostgreSQL-topologie voor hoge beschikbaarheid
Een basistopologie met hoge beschikbaarheid voor PostgreSQL kan zijn:
- 3 PostgreSQL 12-servers (één primaire en twee standby-knooppunten).
- 2 HAProxy Load Balancers.
- Keepalived geconfigureerd tussen de load balancer-servers.
- 1 ClusterControl-server
Dus je hebt de volgende topologie:
Hoe Percona Distribution voor PostgreSQL te installeren
Laten we beginnen met het installeren van Percona Distribution voor PostgreSQL. Voor dit voorbeeld gebruiken we CentOS 7 en PostgreSQL 12.
Als u uw cluster hebt geïnstalleerd, gaat u naar de volgende sectie om uw bestaande database naar ClusterControl te importeren.
Epel-release en percona-release installeren
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmDe PostgreSQL 12-repository inschakelen
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Installeer het serverpakket
$ yum install percona-postgresql12-serverMerk op dat dit pakket niet alle componenten van Percona Distribution zal installeren. Gebruik de juiste optionele pakketten om deze componenten te installeren, zoals hieronder getoond:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribDe database initialiseren
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKZorg ervoor dat u de juiste configuratie heeft om een PostgreSQL-replicatie te kunnen configureren, vergelijkbaar met:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onStart vervolgens de databaseservice
$ systemctl start postgresql-12Als u nu stand-by-knooppunten wilt toevoegen, herhaalt u de stappen 1, 2 en 3 in alle knooppunten die u aan het cluster wilt toevoegen. Voor die knooppunten hoeft u niets anders te configureren, aangezien ClusterControl de bijbehorende configuratie zal maken.
Percona-distributie voor PostgreSQL importeren in ClusterControl
Met ClusterControl kunt u verschillende open source database-engines van hetzelfde systeem implementeren of importeren, en alleen SSH-toegang en een bevoegde gebruiker is vereist om het te gebruiken.
Ga naar het gedeelte "Importeren" en vul de vereiste informatie van uw PostgreSQL-server in.
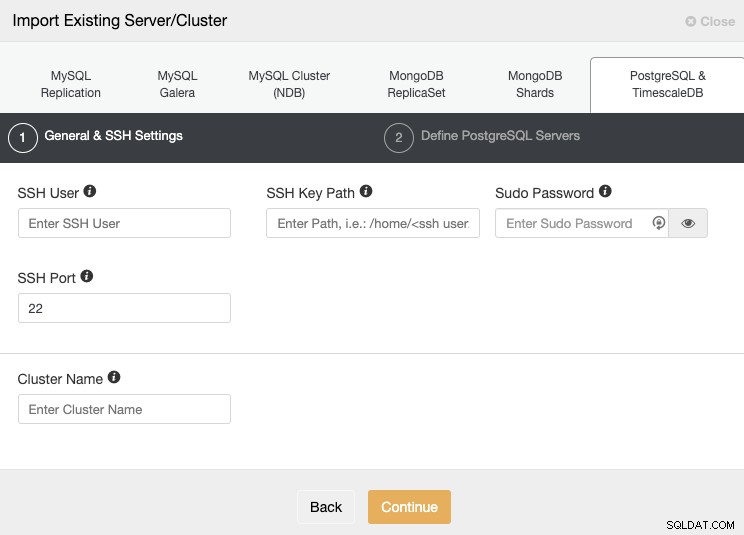
U moet de gebruiker, sleutel of wachtwoord en poort opgeven om verbinding te maken via SSH naar uw servers. U heeft ook een naam nodig voor uw nieuwe cluster, anders zal ClusterControl u een generieke naam toewijzen.
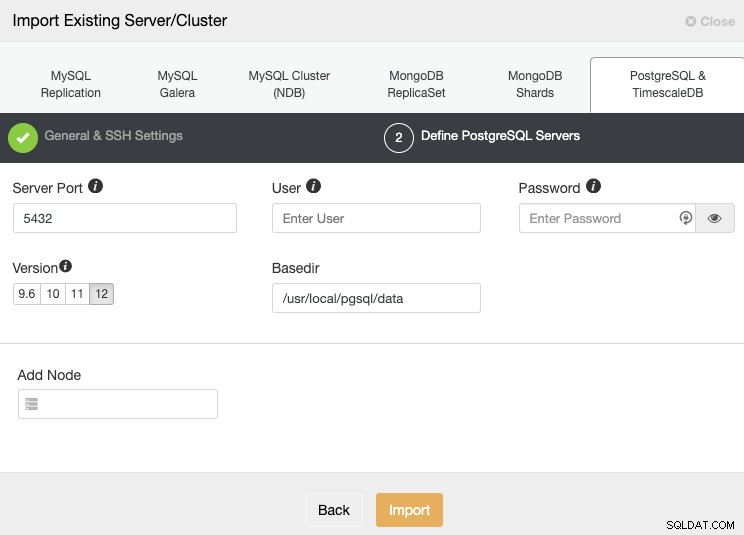
Na het instellen van de SSH-toegangsinformatie, moet u de databasereferenties definiëren, versie, basedir en het IP-adres of de hostnaam voor elk databaseknooppunt.
Als je de replicatie nog niet hebt geconfigureerd, hoef je alleen maar het IP-adres of de hostnaam voor het primaire knooppunt toe te voegen, aangezien we je later zullen laten zien hoe je de rest van de knooppunten kunt toevoegen.
Zorg ervoor dat u het groene vinkje krijgt bij het invoeren van de hostnaam of het IP-adres, wat aangeeft dat ClusterControl kan communiceren met het knooppunt. Klik vervolgens op de knop Importeren en wacht tot ClusterControl klaar is met zijn taak. U kunt het proces volgen in de sectie ClusterControl Activity. Als het klaar is, ziet u het nieuwe cluster op het hoofdscherm van ClusterControl. Om een nieuwe replica toe te voegen, gaat u naar de clusteracties en selecteert u de optie "Replicatieslave toevoegen".
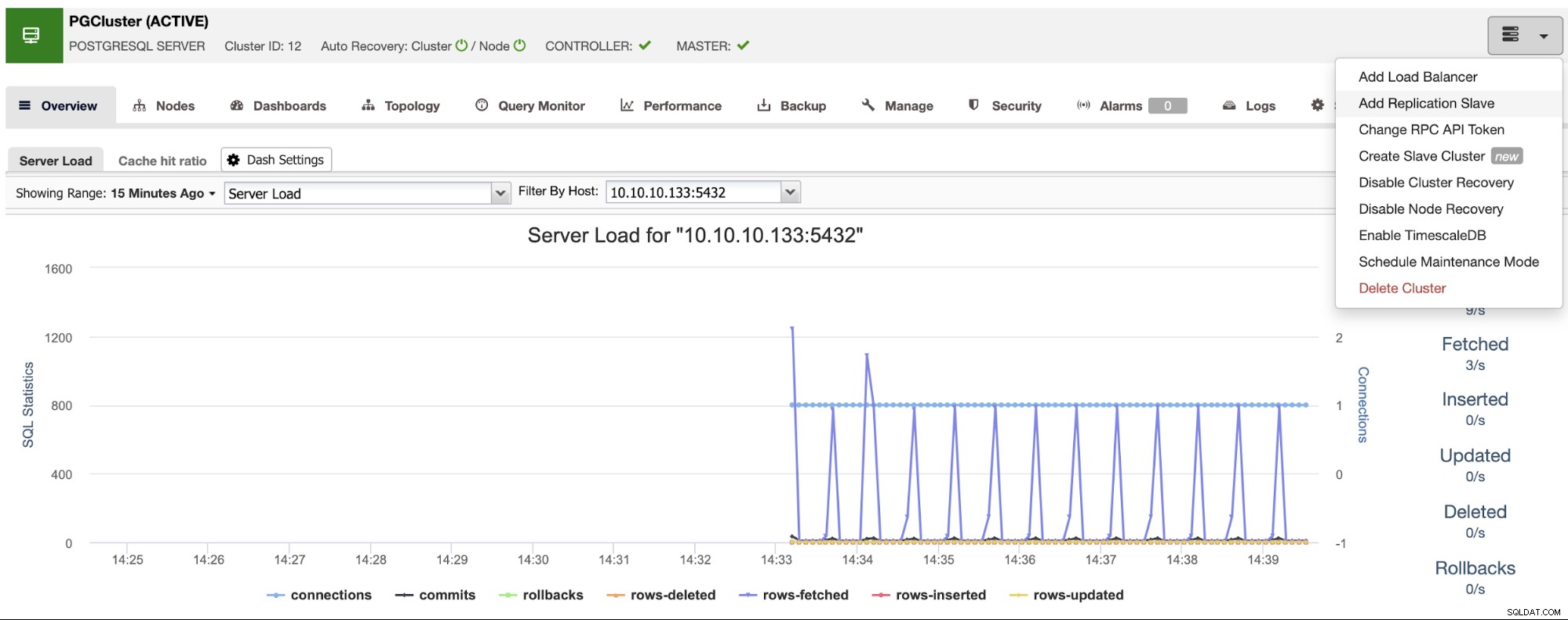
Als u de vorige stappen hebt gevolgd, heeft u Percona Distribution voor PostgreSQL geïnstalleerd in alle stand-by-knooppunten, dus u moet de "PostgreSQL-software installeren" in dit gedeelte uitschakelen.
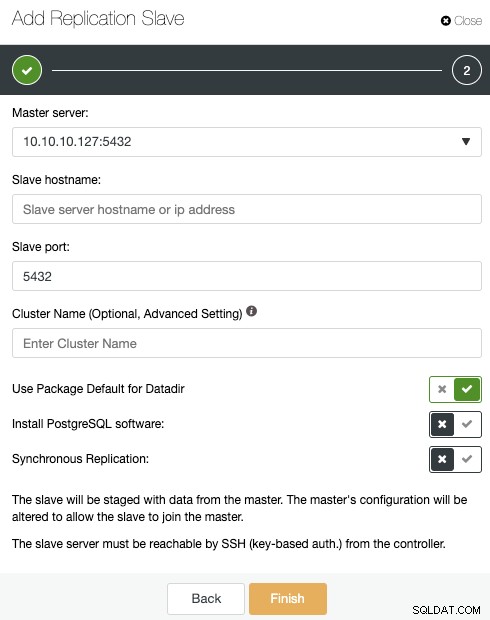
Op deze manier gebruikt ClusterControl in plaats daarvan de geïnstalleerde Percona Distribution voor PostgreSQL-pakketten van het installeren van de officiële PostgreSQL-pakketten.
Als u hiermee klaar bent, ziet u alle knooppunten in het cluster en de status van allemaal in het overzichtsgedeelte.
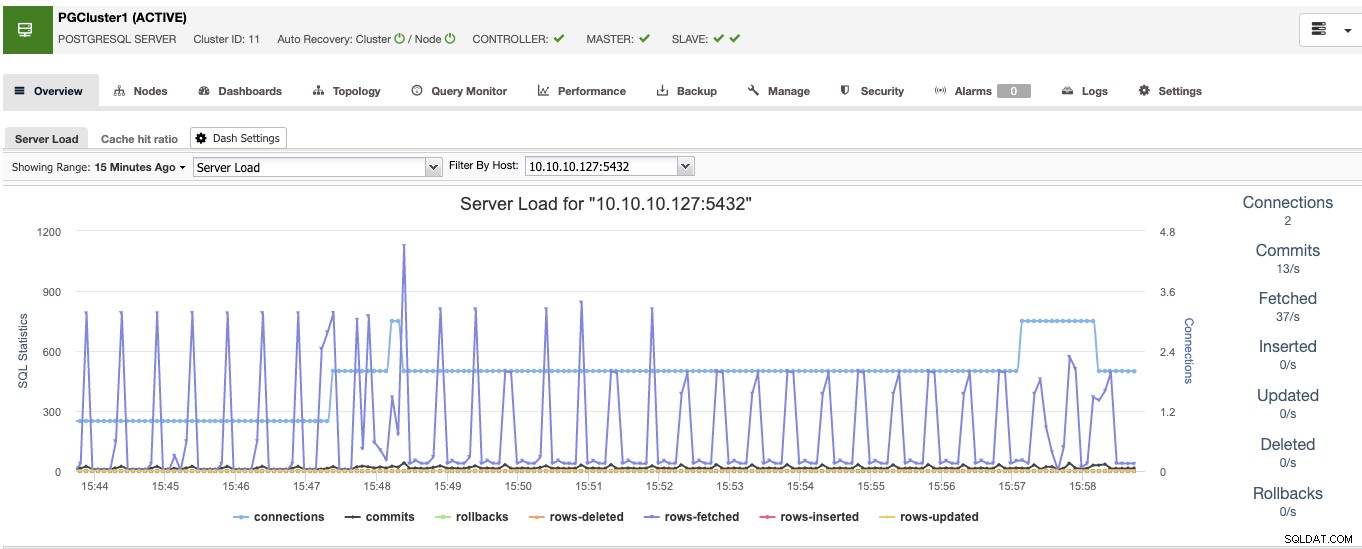
Nu heb je de database-kant klaar, laten we eens kijken hoe je de High Beschikbaarheidsomgeving door de rest van de tools toe te voegen met ClusterControl.
Load Balancer-implementatie
Als u een load balancer-implementatie wilt uitvoeren, selecteert u de optie "Load Balancer toevoegen" in clusteracties en vult u de gevraagde informatie in. 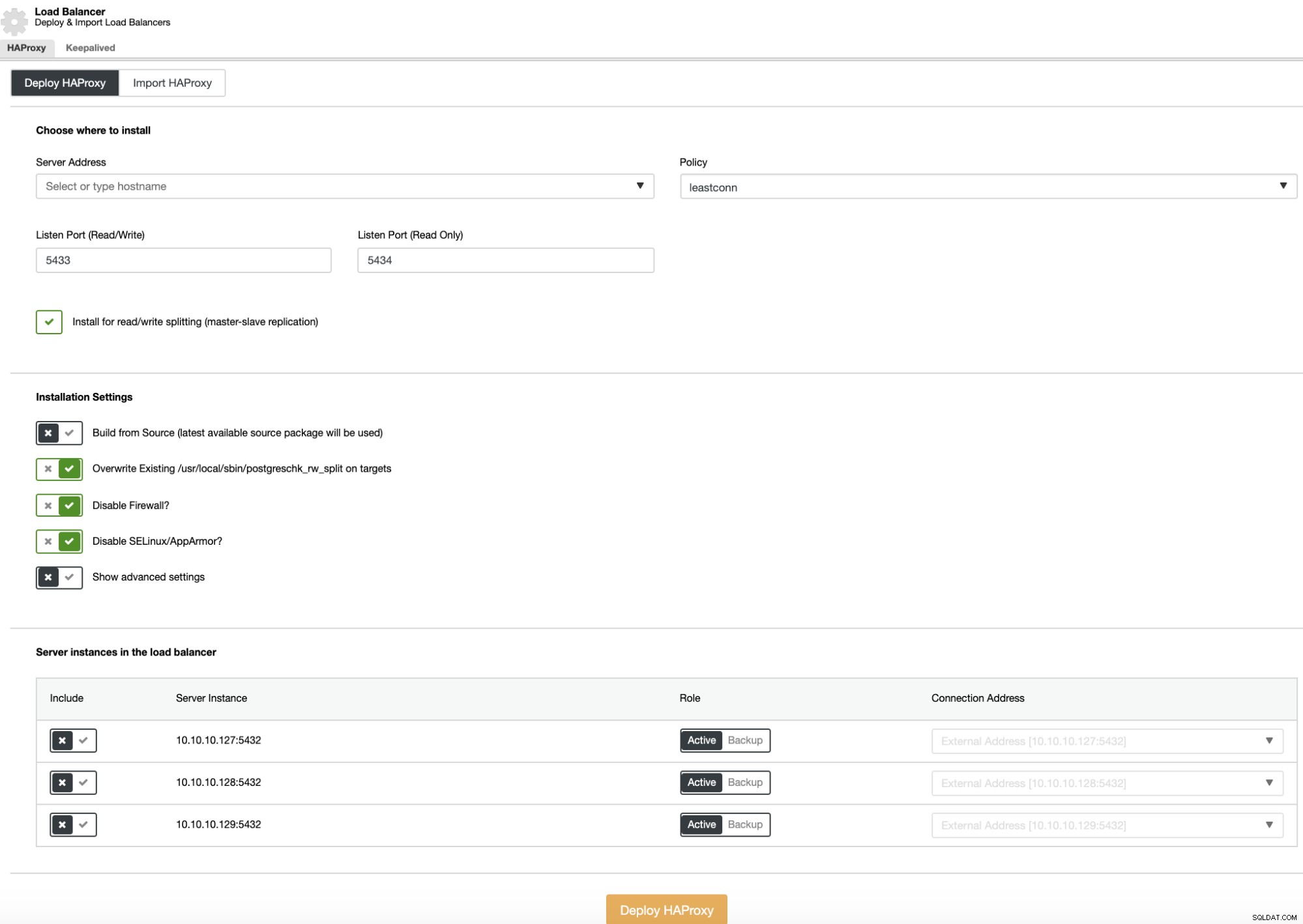
U hoeft alleen het IP-adres of de hostnaam, poort, beleid en de knooppunten die u gaat toevoegen aan de load balancer-configuratie toe te voegen.
Behoud implementatie
Als u een Keepalived-implementatie wilt uitvoeren, selecteert u het cluster, gaat u naar clusteracties, selecteert u 'Load Balancer toevoegen' en gaat u vervolgens naar het gedeelte 'Keepalived'.
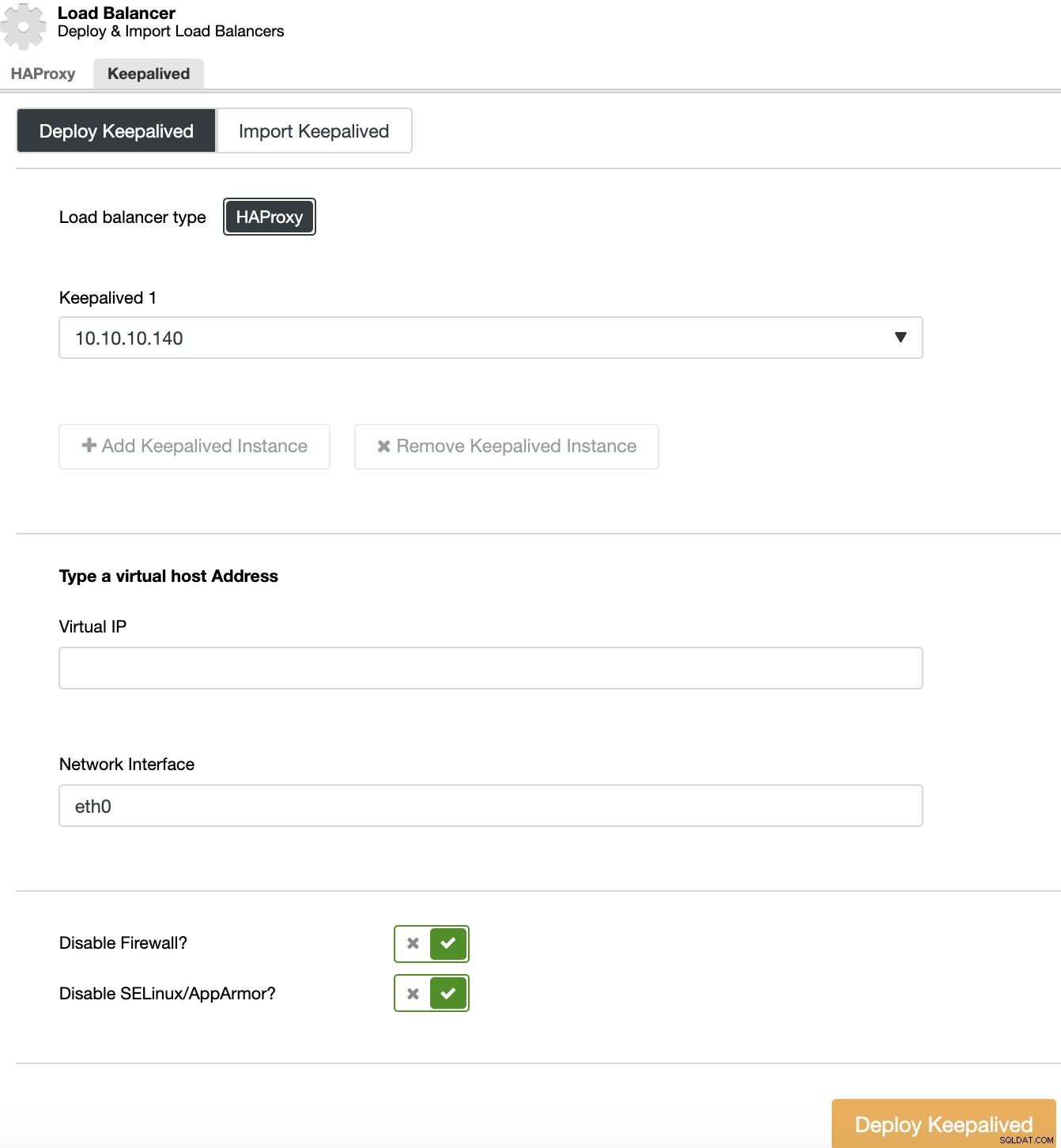
Voor uw omgeving met hoge beschikbaarheid moet u de load balancer-servers en het virtuele IP-adres selecteren, die u moet gebruiken om toegang te krijgen tot uw cluster. Keepalived configureert dit virtuele IP-adres in de actieve load balancer en migreert het van de ene load balancer naar de andere in geval van storing, zodat je setup normaal kan blijven functioneren.
Conclusie
Omdat je Percona Distribution voor PostgreSQL nog niet rechtstreeks vanuit ClusterControl kunt implementeren, hebben we je in deze blog laten zien hoe je het kunt beheren met ClusterControl en hoe je verschillende tools zoals HAProxy en Keepalive kunt toevoegen om een High Availability-omgeving te hebben. op een gemakkelijke manier.