PostgreSQL is een geweldig project en het evolueert in een verbazingwekkend tempo. We zullen ons concentreren op de evolutie van fouttolerantiemogelijkheden in PostgreSQL in alle versies met een reeks blogposts. Dit is het tweede bericht van de serie en we zullen het hebben over replicatie en het belang ervan voor fouttolerantie en betrouwbaarheid van PostgreSQL.
Als je vanaf het begin getuige wilt zijn van de evolutie van de evolutie, bekijk dan de eerste blogpost van de serie:Evolution of Fault Tolerance in PostgreSQL
PostgreSQL-replicatie
Databasereplicatie is de term die we gebruiken om de technologie te beschrijven die wordt gebruikt om een kopie . te onderhouden van een set gegevens op een afstandsbediening systeem. Het bijhouden van een betrouwbare kopie van een draaiend systeem is een van de grootste zorgen van redundantie en we houden allemaal van onderhoudbare, gebruiksvriendelijke en stabiele kopieën van onze gegevens.
Laten we eens kijken naar de basisarchitectuur. Naar individuele databaseservers wordt doorgaans verwezen als knooppunten . De hele groep databaseservers die betrokken is bij replicatie staat bekend als een cluster . Een databaseserver waarmee een gebruiker wijzigingen kan aanbrengen, staat bekend als een master of primair , of kan worden beschreven als een bron van veranderingen. Een databaseserver die alleen alleen-lezen toegang toestaat staat bekend als een Hot Standby . (De term Hot Standby wordt in detail uitgelegd onder de titel Standby Modes. )
Het belangrijkste aspect van replicatie is dat gegevenswijzigingen worden vastgelegd op een master en vervolgens worden overgedragen naar andere knooppunten. In sommige gevallen kan een knooppunt gegevenswijzigingen naar andere knooppunten verzenden, wat een proces is dat bekend staat als cascadering of estafette . De master is dus een verzendend knooppunt, maar niet alle verzendende knooppunten hoeven masters te zijn. Replicatie wordt vaak gecategoriseerd op basis van de vraag of er meer dan één hoofdknooppunt is toegestaan, in welk geval het bekend staat als multimaster-replicatie .
Laten we eens kijken hoe PostgreSQL replicatie in de loop van de tijd afhandelt en wat de state-of-art is voor fouttolerantie volgens de voorwaarden van replicatie.
PostgreSQL-replicatiegeschiedenis
Historisch gezien (rond het jaar 2000-2005), concentreerde Postgres zich alleen op fouttolerantie/herstel van één knooppunt, wat meestal wordt bereikt door het WAL, transactielogboek. Fouttolerantie wordt gedeeltelijk afgehandeld door MVCC (multi-version concurrency system), maar het is vooral een optimalisatie.
Write-ahead logging was en is nog steeds de grootste fouttolerantiemethode in PostgreSQL. Kortom, gewoon WAL-bestanden hebben waarin u alles schrijft en kunt herstellen in termen van mislukking door ze opnieuw af te spelen. Dit was voldoende voor architecturen met één knooppunt en replicatie wordt beschouwd als de beste oplossing voor het bereiken van fouttolerantie met meerdere knooppunten.
De Postgres-gemeenschap geloofde lang dat replicatie iets is dat Postgres niet zou moeten bieden en moet worden afgehandeld door externe tools, daarom zijn tools zoals Slony en Londiste ontstaan. (We bespreken op triggers gebaseerde replicatieoplossingen in de volgende blogposts van de serie.)
Uiteindelijk werd duidelijk dat één servertolerantie niet genoeg was en eisten meer mensen een goede fouttolerantie van de hardware en een goede manier van schakelen, iets wat ingebouwd was in Postgres. Dit is het moment waarop fysieke (toen fysieke streaming) replicatie tot leven kwam.
We zullen alle replicatiemethoden later in de post doornemen, maar laten we de chronologische gebeurtenissen van de PostgreSQL-replicatiegeschiedenis bekijken per grote release:
- PostgreSQL 7.x (~2000)
- Replicatie zou geen onderdeel moeten zijn van de kern van Postgres
- Londiste – Slony (op triggers gebaseerde logische replicatie)
- PostgreSQL 8.0 (2005)
- Point-In-Time Recovery (WAL)
- PostgreSQL 9.0 (2010)
- Streaming-replicatie (fysiek)
- PostgreSQL 9.4 (2014)
- Logische decodering (extractie van wijzigingenset)
Fysieke replicatie
PostgreSQL loste de behoefte aan kernreplicatie op met wat de meeste relationele databases doen; nam de WAL en maakte het mogelijk om deze via het netwerk te verzenden. Vervolgens worden deze WAL-bestanden toegepast op een afzonderlijke Postgres-instantie die alleen-lezen wordt uitgevoerd.
De alleen-lezen standby-instantie past alleen de wijzigingen (door WAL) en de enige schrijfbewerkingen toe komen weer uit hetzelfde WAL-logboek. Dit is eigenlijk hoe streaming-replicatie mechanisme werkt. In het begin vervoerde replicatie oorspronkelijk alle bestanden -log verzending- , maar later evolueerde het naar streaming.
Bij het verzenden van logbestanden stuurden we hele bestanden via het archive_command . De logica is daar vrij eenvoudig:u verstuurt het archief en log het ergens naartoe - zoals het hele WAL-bestand van 16 MB - en dan pas je toe het ergens naar toe, en dan haalt u de volgende en pas toe die en zo gaat het. Later werd het streamen via het netwerk met behulp van het libpq-protocol in PostgreSQL-versie 9.0.
De bestaande replicatie is beter bekend als Physical Streaming Replication, omdat we een reeks fysieke veranderingen van het ene knooppunt naar het andere streamen. Dat betekent dat wanneer we invoegen een rij in een tabel genereren we records wijzigen voor de invoeging plus alle indexitems .
Wanneer we VACUUM een tabel genereren we ook wijzigingsrecords.
Fysieke streamingreplicatie registreert ook alle wijzigingen op byte/blokniveau , waardoor het erg moeilijk is om iets anders te doen dan alles opnieuw af te spelen
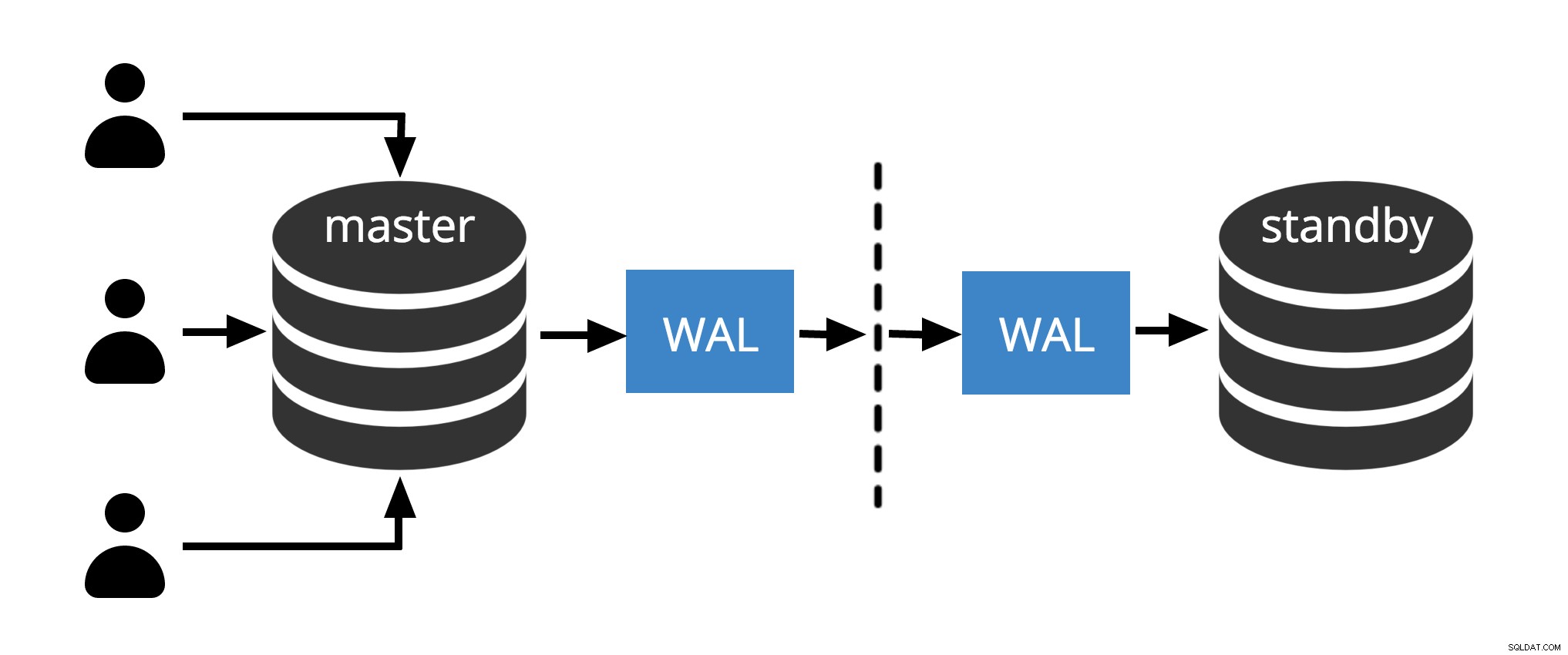
Fig.1 Fysieke replicatie
Fig.1 laat zien hoe fysieke replicatie werkt met slechts twee knooppunten. Client voert query's uit op het hoofdknooppunt, de wijzigingen worden geschreven naar een transactielogboek (WAL) en via het netwerk gekopieerd naar WAL op het stand-byknooppunt. Het herstelproces op het standby-knooppunt leest vervolgens de wijzigingen van WAL en past ze toe op de gegevensbestanden, net als tijdens crashherstel. Als de stand-by in hot stand-by staat modus kunnen clients alleen-lezen query's op het knooppunt uitvoeren terwijl dit gebeurt.
Opmerking: Fysieke replicatie verwijst eenvoudigweg naar het verzenden van WAL-bestanden via het netwerk van master naar standby-knooppunt. Bestanden kunnen via verschillende protocollen worden verzonden, zoals scp, rsync, ftp... Het verschil tussen Fysieke replicatie en Fysieke streaming-replicatie is Streaming Replication gebruikt een intern protocol voor het verzenden van WAL-bestanden (afzender en ontvangerprocessen )
Standby-modi
Meerdere nodes zorgen voor hoge beschikbaarheid. Om die reden hebben moderne architecturen meestal stand-by nodes. Er zijn verschillende modi voor stand-by nodes (warm en warm stand-by). In de onderstaande lijst worden de basisverschillen tussen de verschillende standby-modi uitgelegd en wordt ook het geval van multi-master-architectuur getoond.
Warme stand-by
Kan onmiddellijk worden geactiveerd, maar kan geen nuttig werk uitvoeren totdat het is geactiveerd. Als we de reeks WAL-bestanden continu naar een andere machine voeren die is geladen met hetzelfde basisback-upbestand, hebben we een warm stand-bysysteem:op elk moment kunnen we de tweede machine oproepen en deze zal een bijna-actuele kopie hebben van de databank. Warme stand-by staat geen alleen-lezen-query's toe, Fig.2 geeft dit eenvoudig weer.
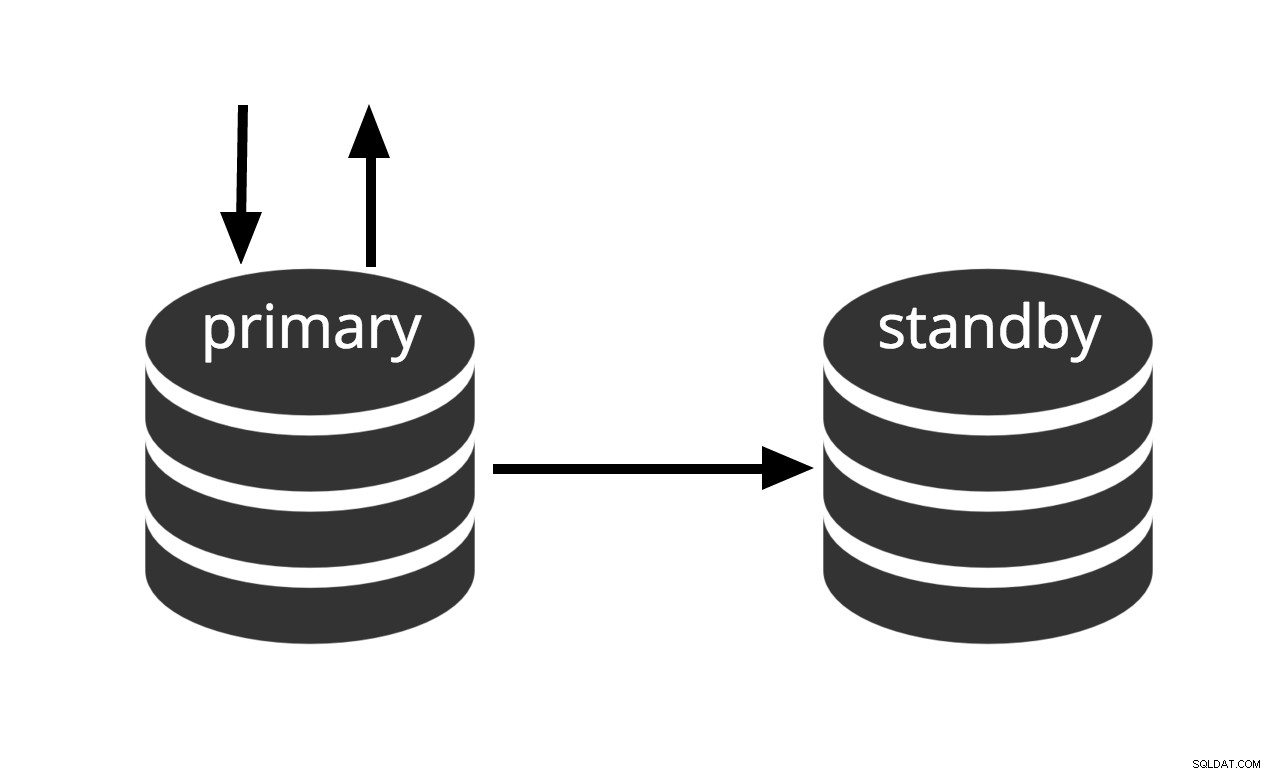
Fig.2 Warm Standby
De herstelprestaties van een warme stand-by zijn zo goed dat de stand-by doorgaans slechts enkele ogenblikken verwijderd is van volledige beschikbaarheid nadat deze is geactiveerd. Als gevolg hiervan wordt dit een warme standby-configuratie genoemd die een hoge beschikbaarheid biedt.
Hete stand-by
Hot-standby is de term die wordt gebruikt om de mogelijkheid te beschrijven om verbinding te maken met de server en alleen-lezenquery's uit te voeren terwijl de server zich in de archiefherstel- of stand-bymodus bevindt. Dit is zowel handig voor replicatiedoeleinden als voor het met grote precisie terugzetten van een back-up naar de gewenste staat.
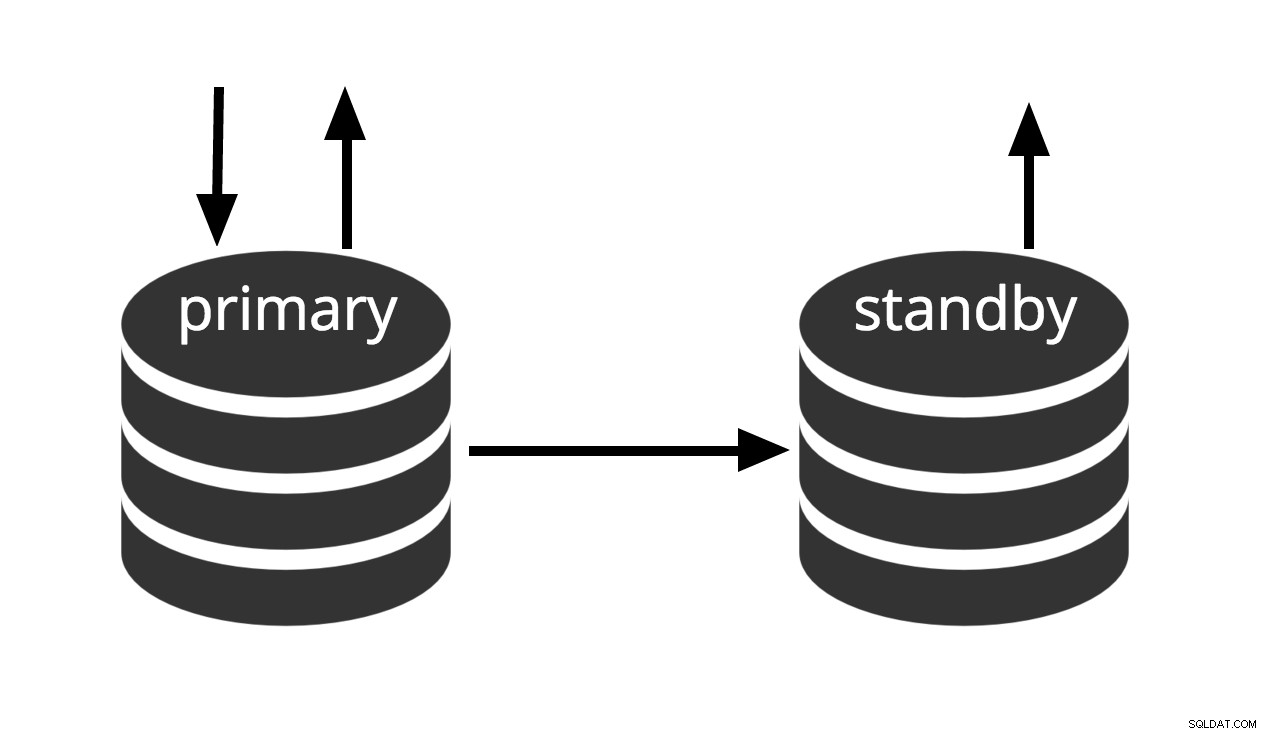 Fig.3 Hot Standby
Fig.3 Hot Standby
De term 'hot standby' verwijst ook naar het vermogen van de server om van herstel naar normaal bedrijf te gaan terwijl gebruikers query's blijven uitvoeren en/of hun verbindingen open houden. Fig.3 laat zien dat de standby-modus alleen-lezen zoekopdrachten toestaat.
Multimaster
Alle nodes kunnen lees-/schrijfwerk uitvoeren. (We zullen multi-master architecturen behandelen in de volgende blogposts van de serie.)
WAL-niveauparameter
Er is een relatie tussen het instellen van wal_level parameter in het bestand postgresql.conf en waarvoor deze instelling geschikt is. Ik heb een tabel gemaakt om de relatie voor PostgreSQL versie 9.6 te tonen.

Failover en omschakeling
Bij replicatie met één master moet, als de master sterft, een van de standbys zijn plaats innemen (promotie ). Anders kunnen we geen nieuwe schrijftransacties accepteren. De term aanduidingen, master en standby, zijn dus slechts rollen die elk knooppunt op een bepaald moment kan aannemen. Om de hoofdrol naar een ander knooppunt te verplaatsen, voeren we een procedure uit met de naam Switchover .
Als de master sterft en niet herstelt, staat de meer ernstige rolwisseling bekend als een Failover . Deze kunnen in veel opzichten op elkaar lijken, maar het helpt om voor elk evenement verschillende termen te gebruiken. (Als we de voorwaarden van failover en omschakeling kennen, kunnen we de tijdlijnproblemen in de volgende blogpost beter begrijpen.)
Conclusie
In deze blogpost hebben we PostgreSQL-replicatie besproken en het belang ervan voor fouttolerantie en betrouwbaarheid. We hebben fysieke streaming-replicatie besproken en gesproken over stand-bymodi voor PostgreSQL. We noemden Failover en Switchover. We gaan verder met PostgreSQL-tijdlijnen in de volgende blogpost.
Referenties
PostgreSQL-documentatie
Logische replicatie in PostgreSQL 5432…MeetUs-presentatie door Petr Jelinek
PostgreSQL 9 Administration Cookbook – Tweede editie