Ik ben begonnen te schrijven over de tool (pglupgrade) die ik heb ontwikkeld om geautomatiseerde upgrades van PostgreSQL-clusters vrijwel zonder downtime uit te voeren. In dit bericht zal ik het hebben over de tool en de ontwerpdetails bespreken.
Je kunt het eerste deel van de serie hier bekijken:Geautomatiseerde upgrades van bijna nul downtime van PostgreSQL-clusters in de cloud (deel I).

De tool is geschreven in Ansible. Ik heb eerdere ervaring met het werken met Ansible en werk er momenteel ook mee in 2ndQuadrant, daarom was het een comfortabele optie voor mij. Dat gezegd hebbende, kun je de upgradelogica voor minimale downtime implementeren, die later in dit bericht wordt uitgelegd, met je favoriete automatiseringstool.
Verder lezen:blogberichten Ansible houdt van PostgreSQL , PostgreSQL Planet in Ansible Galaxy en presentatie PostgreSQL beheren met Ansible.
Pglupgrade Playbook
In Ansible, playbooks zijn de belangrijkste scripts die zijn ontwikkeld om de processen te automatiseren, zoals het inrichten van cloudinstanties en het upgraden van databaseclusters. Playbooks kunnen een of meer plays . bevatten . Playbooks kunnen ook variabelen bevatten , rollen , en handlers indien gedefinieerd.
De tool bestaat uit twee hoofd-playbooks. Het eerste playbook is provision.yml dat het proces automatiseert voor het maken van Linux-machines in de cloud, volgens de specificaties (Dit is een optioneel playbook dat alleen is geschreven om cloudinstanties te voorzien en niet direct gerelateerd is aan de upgrade ). Het tweede (en het belangrijkste) playbook is pglupgrade.yml dat het upgradeproces van databaseclusters automatiseert.
Pglupgrade playbook heeft acht toneelstukken om de upgrade te orkestreren. Gebruik voor elk van de spelen één configuratiebestand (config.yml ), voer enkele taken uit op de hosts of hostgroepen die zijn gedefinieerd in host inventarisbestand (host.ini ).
Inventarisbestand
Een inventarisatiebestand laat Ansible weten welke servers het nodig heeft om verbinding te maken via SSH, welke verbindingsinformatie het nodig heeft en optioneel welke variabelen aan die servers zijn gekoppeld. Hieronder ziet u een voorbeeld van een inventarisatiebestand dat is gebruikt om geautomatiseerde clusterupgrades uit te voeren voor een van de casestudy's die voor de tool zijn ontworpen. We zullen deze casestudy's bespreken in komende berichten van deze serie.
[old-primary] 54.171.211.188 [new-primary] 54.246.183.100 [old-standbys] 54.77.249.81 54.154.49.180 [new-standbys:children] old-standbys [pgbouncer] 54.154.49.180
Inventarisbestand (host.ini )
Het voorbeeldinventarisbestand bevat vijf hosts minder dan vijf gastgroepen die old-primary . bevatten , new-primary , old-standbys , new-standbys en pgbouncer . Een server kan tot meer dan één groep behoren. Bijvoorbeeld de old-standbys is een groep met de new-standbys groep, wat de hosts betekent die zijn gedefinieerd onder de old-standbys groep (54.77.249.81 en 54.154.49.180) behoort ook tot de new-standbys groep. Met andere woorden, de new-standbys groep is geërfd van (kinderen van) old-standbys groep. Dit wordt bereikt door gebruik te maken van de speciale :children achtervoegsel.
Zodra het inventarisbestand klaar is, kan Ansible playbook worden uitgevoerd via ansible-playbook commando door te verwijzen naar het inventarisbestand (als het inventarisbestand zich niet op de standaardlocatie bevindt, anders zal het het standaard inventarisbestand gebruiken), zoals hieronder weergegeven:
$ ansible-playbook -i hosts.ini pglupgrade.yml
Een Ansible-playbook gebruiken
Configuratiebestand
Pglupgrade playbook gebruikt een configuratiebestand (config.yml ) waarmee gebruikers waarden kunnen specificeren voor de logische upgradevariabelen.
Zoals hieronder getoond, is de config.yml slaat voornamelijk PostgreSQL-specifieke variabelen op die nodig zijn om een PostgreSQL-cluster in te stellen, zoals postgres_old_datadir en postgres_new_datadir om het pad van de PostgreSQL-gegevensmap op te slaan voor de oude en nieuwe PostgreSQL-versies; postgres_new_confdir om het pad van de PostgreSQL-configuratiemap op te slaan voor de nieuwe PostgreSQL-versie; postgres_old_dsn en postgres_new_dsn om de verbindingsreeks op te slaan voor de pglupgrade_user om verbinding te kunnen maken met de pglupgrade_database van de nieuwe en de oude primaire servers. De verbindingsreeks zelf bestaat uit de configureerbare variabelen zodat de gebruiker (pglupgrade_user ) en de database (pglupgrade_database ) informatie kan worden gewijzigd voor de verschillende gebruikssituaties.
ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user {{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main" Configuratiebestand (config.yml )
Als een belangrijke stap voor elke upgrade kan de PostgreSQL-versie-informatie worden gespecificeerd voor de huidige versie (postgres_old_version ) en de versie waarnaar wordt geüpgraded (postgres_new_version ). In tegenstelling tot fysieke replicatie waarbij de replicatie een kopie is van het systeem op byte-/blokniveau, maakt logische replicatie selectieve replicatie mogelijk waar de replicatie de logische gegevens kan kopiëren, zijn gespecificeerde databases en de tabellen in die databases. Om deze reden, config.yml maakt het mogelijk om te configureren welke database moet worden gerepliceerd via pglupgrade_database variabel. De gebruiker van logische replicatie moet ook replicatierechten hebben, daarom pglupgrade_user variabele moet worden opgegeven in het configuratiebestand. Er zijn andere variabelen die verband houden met werkende internals van pglogical, zoals subscription_name en replication_set die worden gebruikt in de pglogische rol.
Ontwerp met hoge beschikbaarheid van de Pglupgrade-tool
De Pglupgrade-tool is ontworpen om de gebruiker de flexibiliteit te geven in termen van High Availability (HA)-eigenschappen voor de verschillende systeemvereisten. De initial_standbys variabele (zie config.yml ) is de sleutel voor het toewijzen van HA-eigenschappen van het cluster terwijl de upgradebewerking plaatsvindt.
Als bijvoorbeeld initial_standbys is ingesteld op 1 (kan worden ingesteld op elk nummer dat de clustercapaciteit toestaat), wat betekent dat er 1 stand-by wordt gemaakt in het geüpgradede cluster samen met de master voordat de replicatie begint. Met andere woorden, als je 4 servers hebt en je initial_standbys instelt op 1, heb je 1 primaire en 1 standby-server in de bijgewerkte nieuwe versie, evenals 1 primaire en 1 standby-server in de oude versie.
Met deze optie kunt u de bestaande servers hergebruiken terwijl de upgrade nog plaatsvindt. In het voorbeeld van 4 servers kunnen de oude primaire en standby-servers worden herbouwd als 2 nieuwe standby-servers nadat de replicatie is voltooid.
Wanneer initial_standbys variabele is ingesteld op 0, worden er geen initiële standby-servers gemaakt in de nieuwe cluster voordat de replicatie begint.
Als de initial_standbys configuratie klinkt verwarrend, maak je geen zorgen. Dit wordt beter uitgelegd in de volgende blogpost wanneer we twee verschillende casestudies bespreken.
Ten slotte maakt het configuratiebestand het mogelijk om oude en nieuwe servergroepen te specificeren. Dit zou op twee manieren kunnen gebeuren. Ten eerste, als er een bestaand cluster is, IP-adressen van de servers (kunnen bare-metal of virtuele servers zijn ) moet worden ingevoerd in hosts.ini bestand door de gewenste HA-eigenschappen te overwegen tijdens het upgraden.
De tweede manier is om provision.yml . uit te voeren playbook (zo heb ik de cloudinstanties ingericht, maar u kunt uw eigen inrichtingsscripts gebruiken of handmatig instanties inrichten ) om lege Linux-servers in de cloud in te richten (AWS EC2-instanties) en de IP-adressen van de servers in de hosts.ini te krijgen het dossier. Hoe dan ook, config.yml ontvangt hostinformatie via hosts.ini bestand.
Workflow van het upgradeproces
Na uitleg over het configuratiebestand (config.yml ) die wordt gebruikt door pglupgrade playbook, kunnen we de workflow van het upgradeproces uitleggen.
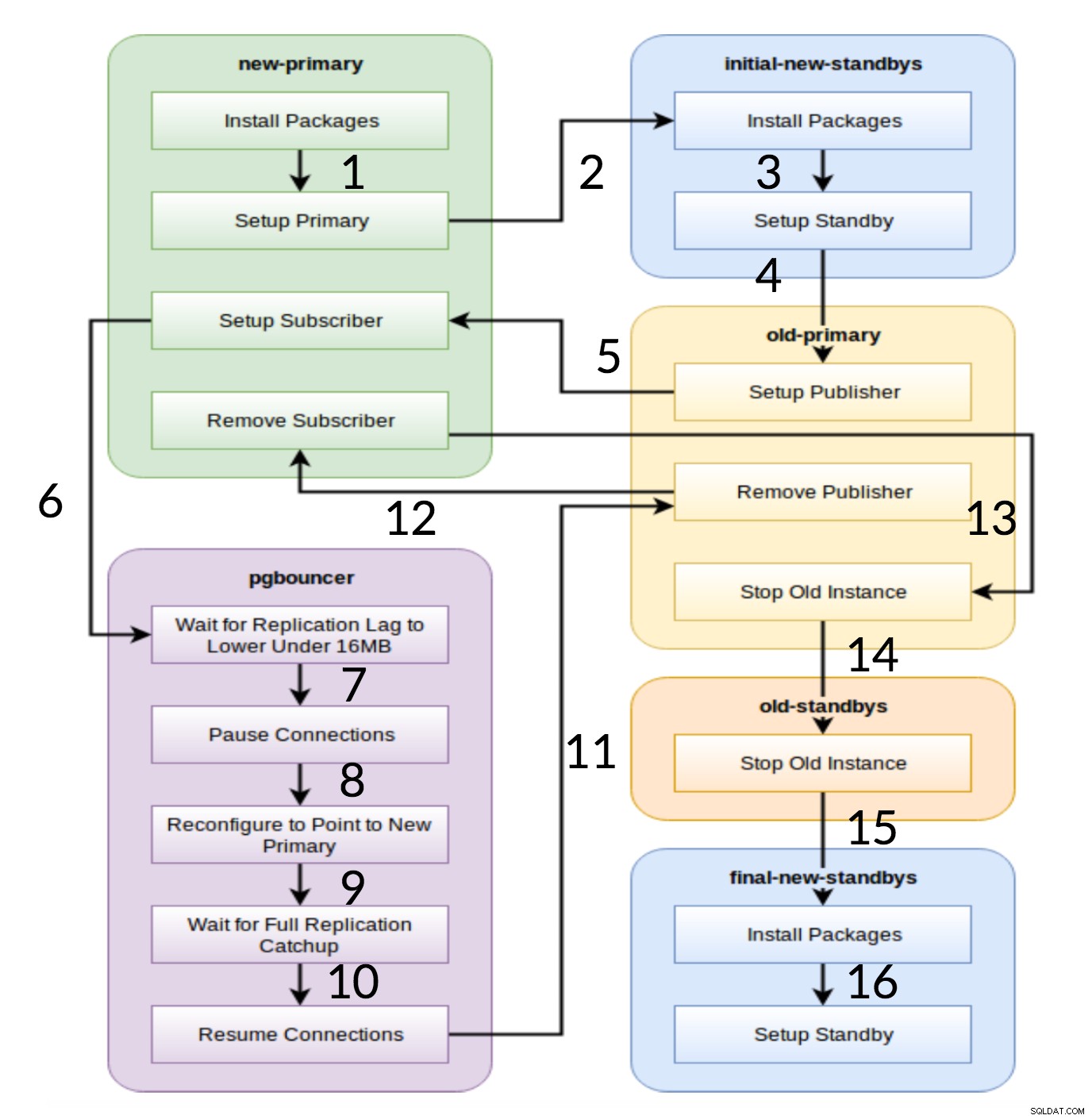
Pglupgrade-werkstroom
Zoals te zien is in het bovenstaande diagram, zijn er in het begin zes servergroepen die worden gegenereerd op basis van de configuratie (beide hosts.ini en de config.yml ). De new-primary en old-primary groepen hebben altijd één server, pgbouncer groep kan een of meer servers hebben en alle standby-groepen kunnen nul of meer servers bevatten. Qua implementatie is het hele proces opgedeeld in acht stappen. Elke stap komt overeen met een toneelstuk in het pglupgrade-playbook, dat de vereiste taken uitvoert op de toegewezen hostgroepen. Het upgradeproces wordt uitgelegd aan de hand van de volgende toneelstukken:
- Maak hosts op basis van configuratie: Voorbereidingsspel dat interne groepen servers bouwt op basis van de configuratie. Het resultaat van deze play (in combinatie met de
hosts.iniinhoud) zijn de zes servergroepen (geïllustreerd met verschillende kleuren in het werkstroomdiagram) die zullen worden gebruikt door de volgende zeven toneelstukken. - Nieuw cluster instellen met initiële standby(s): Stelt een leeg PostgreSQL-cluster in met de nieuwe primaire en initiële standby(s) (als die zijn gedefinieerd). Het zorgt ervoor dat er niets overblijft van PostgreSQL-installaties van het vorige gebruik.
- Wijzig de oude primaire om logische replicatie te ondersteunen: Installeert pglogical extensie. Stel vervolgens de uitgever in door alle tabellen en reeksen aan de replicatie toe te voegen.
- Repliceren naar de nieuwe primaire: Stelt de abonnee in op de nieuwe master die fungeert als een trigger om logische replicatie te starten. Dit spel voltooit het repliceren van de bestaande gegevens en begint in te halen wat er is veranderd sinds het begon met de replicatie.
- Schakel de pgbouncer (en applicaties) naar nieuwe primaire: Wanneer de replicatievertraging convergeert naar nul, pauzeert de pgbouncer om de toepassing geleidelijk te wisselen. Vervolgens wijst het pgbouncer-configuratie naar de nieuwe primaire en wacht tot het replicatieverschil nul wordt. Ten slotte wordt pgbouncer hervat en worden alle wachtende transacties gepropageerd naar de nieuwe primaire en beginnen ze daar met verwerken. De eerste standbys zijn al in gebruik en beantwoorden leesverzoeken.
- Ruim de replicatie-instellingen op tussen oude primaire en nieuwe primaire: Beëindigt de verbinding tussen de oude en de nieuwe primaire servers. Aangezien alle toepassingen naar de nieuwe primaire server zijn verplaatst en de upgrade is voltooid, is logische replicatie niet langer nodig. Replicatie tussen primaire en standby-servers wordt voortgezet met fysieke replicatie.
- Stop het oude cluster: De Postgres-service wordt gestopt in oude hosts om ervoor te zorgen dat geen enkele toepassing er meer verbinding mee kan maken.
- De rest van de standbys opnieuw configureren voor de nieuwe primaire: Herbouwt andere standbys als er nog andere hosts zijn dan de initiële standbys. In de tweede case study zijn er geen resterende standby-servers om opnieuw op te bouwen. Deze stap geeft de kans om de oude primaire server opnieuw op te bouwen als een nieuwe stand-by als deze wordt verwezen naar de groep nieuwe stand-bys op hosts.ini. De herbruikbaarheid van bestaande servers (zelfs de oude primaire) wordt bereikt door gebruik te maken van het tweestaps stand-byconfiguratieontwerp van de pglupgrade-tool. De gebruiker kan specificeren welke servers stand-by moeten worden van het nieuwe cluster vóór de upgrade en welke na de upgrade stand-by moeten worden.
Conclusie
In dit bericht hebben we de implementatiedetails en het hoge beschikbaarheidsontwerp van de pglupgrade-tool besproken. Daarbij noemden we ook enkele sleutelconcepten van Ansible-ontwikkeling (d.w.z. playbook, inventaris- en configuratiebestanden) met de tool als voorbeeld. We hebben de workflow van het upgradeproces geïllustreerd en samengevat hoe elke stap werkt met een bijbehorende play. We gaan door met het uitleggen van pglupgrade door casestudy's te laten zien in toekomstige posts van deze serie.
Bedankt voor het lezen!