Gebruik door de gebruiker gedefinieerd aggregaat
Live-test:https://sqlfiddle.com/#!17/03ee7/1
DDL
CREATE TABLE t
(grop varchar(1), month_year text, something int)
;
INSERT INTO t
(grop, month_year, something)
VALUES
('a', '201901', -2),
('a', '201902', -4),
('a', '201903', -6),
('a', '201904', 60),
('a', '201905', -2),
('a', '201906', 9),
('a', '201907', 11),
('b', '201901', 100),
('b', '201902', -200),
('b', '201903', 300),
('b', '201904', -50),
('b', '201905', 30),
('b', '201906', -88),
('b', '201907', -86)
;
Door gebruiker gedefinieerd aggregaat
create or replace function negative_accum(_accumulated_b numeric, _current_b numeric)
returns numeric as
$$
select case when _accumulated_b < 0 then
_accumulated_b + _current_b
else
_current_b
end
$$ language 'sql';
create aggregate negative_summer(numeric)
(
sfunc = negative_accum,
stype = numeric,
initcond = 0
);
select
*,
negative_summer(something) over (order by grop, month_year) as result
from t
De eerste parameter (_accumulated_b) bevat de geaccumuleerde waarde van de kolom. De tweede parameter (_current_b) bevat de waarde van de kolom van de huidige rij.
Uitgang:
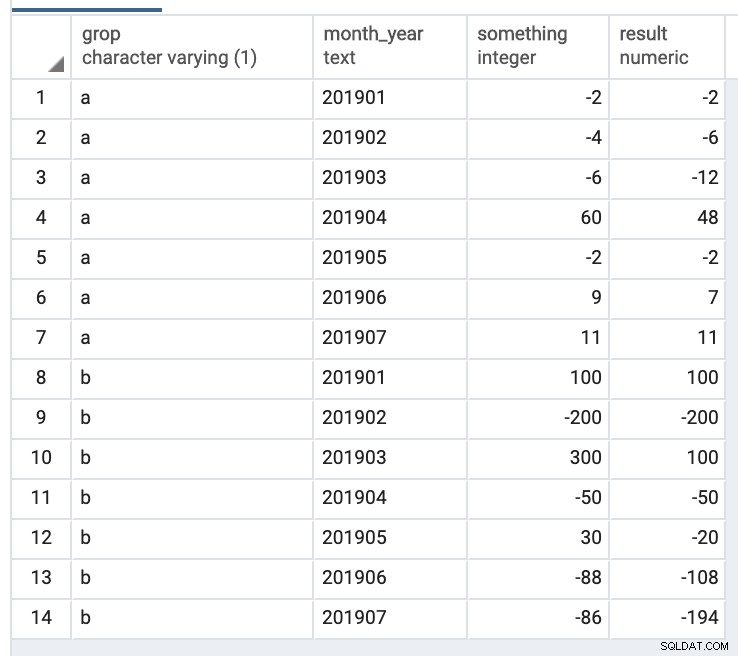
Wat betreft uw pseudo-code B3 = A3 + MIN(0, B2)
Ik gebruikte deze typische code:
select case when _accumulated_b < 0 then
_accumulated_b + _current_b
else
_current_b
end
Dat kan idiomatisch in Postgres worden geschreven als:
select _current_b + least(_accumulated_b, 0)
Live-test:https://sqlfiddle.com/#!17/70fa8/1
create or replace function negative_accum(_accumulated_b numeric, _current_b numeric)
returns numeric as
$$
select _current_b + least(_accumulated_b, 0)
$$ language 'sql';
U kunt ook een andere taal gebruiken met de accumulatorfunctie, bijvoorbeeld plpgsql. Merk op dat plpgsql (of misschien de $$ quote) niet wordt ondersteund in https://sqlfiddle.com . Dus geen live testlink, dit zou wel werken op jouw machine:
create or replace function negative_accum(_accumulated_b numeric, _current_b numeric)
returns numeric as
$$begin
return _current_b + least(_accumulated_b, 0);
end$$ language 'plpgsql';
UPDATE
Ik heb de partition by , hier is een voorbeeld van data (gewijzigd 11 in -11) waar zonder partition by en met partition by zou verschillende resultaten opleveren:
Live-test:https://sqlfiddle.com/#!17/87795/4
INSERT INTO t
(grop, month_year, something)
VALUES
('a', '201901', -2),
('a', '201902', -4),
('a', '201903', -6),
('a', '201904', 60),
('a', '201905', -2),
('a', '201906', 9),
('a', '201907', -11), -- changed this from 11 to -11
('b', '201901', 100),
('b', '201902', -200),
('b', '201903', 300),
('b', '201904', -50),
('b', '201905', 30),
('b', '201906', -88),
('b', '201907', -86)
;
Uitgang:
| grop | month_year | something | result_wrong | result |
|------|------------|-----------|--------------|--------|
| a | 201901 | -2 | -2 | -2 |
| a | 201902 | -4 | -6 | -6 |
| a | 201903 | -6 | -12 | -12 |
| a | 201904 | 60 | 48 | 48 |
| a | 201905 | -2 | -2 | -2 |
| a | 201906 | 9 | 7 | 7 |
| a | 201907 | -11 | -11 | -11 |
| b | 201901 | 100 | 89 | 100 |
| b | 201902 | -200 | -200 | -200 |
| b | 201903 | 300 | 100 | 100 |
| b | 201904 | -50 | -50 | -50 |
| b | 201905 | 30 | -20 | -20 |
| b | 201906 | -88 | -108 | -108 |
| b | 201907 | -86 | -194 | -194 |