- Kort over draaitabellen
- Gegevens draaien door middel van tools (dbForge Studio for MySQL)
- Gegevens draaien door middel van SQL
- T-SQL-gebaseerd voorbeeld voor SQL Server
- Voorbeeld voor MySQL
- Het draaien van gegevens automatiseren, dynamisch query's maken
Kort over draaitabellen
Dit artikel behandelt de transformatie van tabelgegevens van rijen naar kolommen. Een dergelijke transformatie wordt draaitabellen genoemd. Vaak is het resultaat van de spil een samenvattende tabel waarin statistische gegevens worden gepresenteerd in de vorm die geschikt of vereist is voor een rapport.
Bovendien kan een dergelijke gegevenstransformatie nuttig zijn als een database niet is genormaliseerd en de informatie daarin in een niet-optimale vorm wordt opgeslagen. Dus bij het reorganiseren van de database en het overbrengen van gegevens naar nieuwe tabellen of het genereren van een vereiste gegevensrepresentatie, kan het draaien van gegevens nuttig zijn, d.w.z. het verplaatsen van waarden van rijen naar resulterende kolommen.
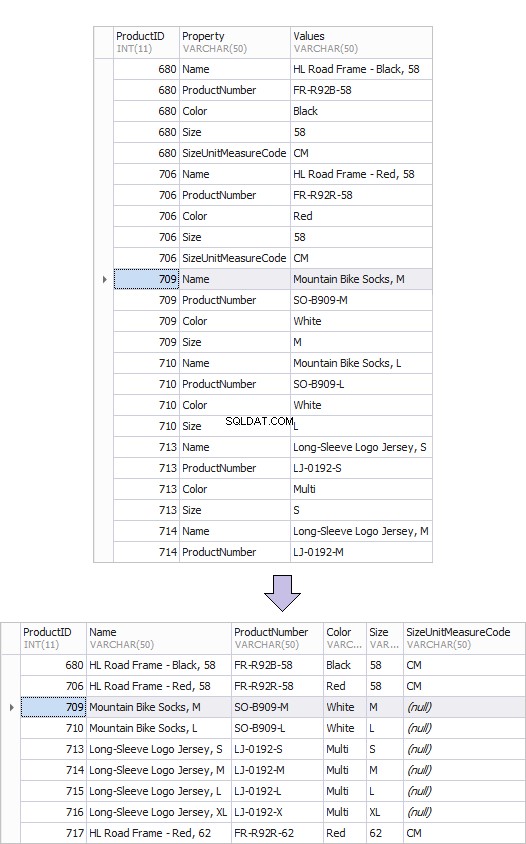
Hieronder ziet u een voorbeeld van de oude tabel met producten - ProductenOud en de nieuwe - ProductenNieuw. Het is door de transformatie van rijen naar kolommen dat een dergelijk resultaat gemakkelijk kan worden bereikt.
Hier is een voorbeeld van een draaitabel.
Gegevens draaien door middel van tools (dbForge Studio for MySQL)
Er zijn applicaties die tools hebben die het mogelijk maken om data pivot te implementeren in een handige grafische omgeving. dbForge Studio voor MySQL bevat bijvoorbeeld draaitabellenfunctionaliteit die in slechts een paar stappen het gewenste resultaat oplevert.

Laten we eens kijken naar het voorbeeld met een vereenvoudigde tabel met bestellingen - PurchaseOrderHeader .
TABEL MAKEN PurchaseOrderHeader ( PurchaseOrderID INT (11) NOT NULL, EmployeeID INT (11) NOT NULL, VendorID INT (11) NOT NULL, PRIMAIRE SLEUTEL (PurchaseOrderID));INSERT PurchaseOrderHeader (PurchaseOrderID, EmployeeID, VendorID) WAARDEN (1 , 258, 1580);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (2, 254, 1496);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (3, 257, 1494);INSERT PurchaseOrderHeader(PurchaseOrderID, VendorID, EmployeeID, VendorID, EmployeeID ) VALUES (4, 261, 1650);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (5, 251, 1654);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (6, 253, 1664);INSERT PurchaseOrderHeader(PurchaseOrderID) , EmployeeID, VendorID) VALUES (7, 255, 1678);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (8, 256, 1616);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (9, 259, 1492); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (10, 250, 1602);INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (11, 258, 1540);...
Stel dat we een selectie uit de tabel moeten maken en het aantal bestellingen van bepaalde medewerkers van bepaalde leveranciers moeten bepalen. De lijst met werknemers waarvoor informatie nodig is - 250, 251, 252, 253, 254.
Een voorkeursweergave voor het rapport is als volgt.
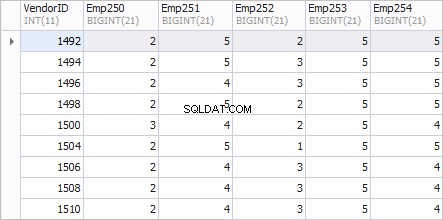
De linkerkolom VendorID toont de ID's van leveranciers; kolommen Emp250 , Emp251 , Emp252 , Emp253 , en Emp254 het aantal bestellingen weergeven.
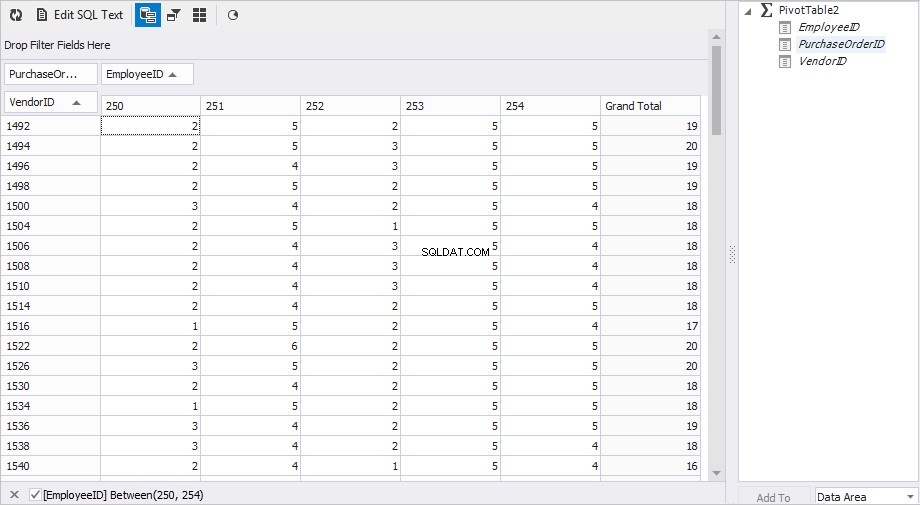
Om dit te bereiken in dbForge Studio voor MySQL, moet u:
- Voeg de tabel toe als gegevensbron voor de 'draaitabel'-weergave van het document. Klik in Database Explorer met de rechtermuisknop op de PurchaseOrderHeader tabel en selecteer Verzenden naar en dan Draaitabel in het pop-upmenu.
- Geef een kolom op waarvan de waarden rijen zijn. Sleep de VendorID kolom naar het vak 'Velden voor rijen hier neerzetten'.
- Geef een kolom op waarvan de waarden kolommen zijn. Sleep de EmployeeID kolom naar het vak 'Kolomvelden hier neerzetten'. U kunt ook een filter instellen voor de benodigde medewerkers (250, 251, 252, 253, 254).
- Geef een kolom op waarvan de waarden de gegevens zijn. Sleep de PurchaseOrderID naar het vak 'Gegevensitems hier neerzetten'.
- In de eigenschappen van de PurchaseOrderID kolom, specificeer het type aggregatie - Aantal waarden .
We kregen snel het resultaat dat we nodig hadden.
Gegevens draaien door middel van SQL
Natuurlijk kan datatransformatie worden uitgevoerd door middel van een database door een SQL-query te schrijven. Maar er is een kleine hapering, MySQL heeft geen specifieke verklaring die dit mogelijk maakt.
T-SQL-gebaseerd voorbeeld voor SQL Server
SqlServer en Oracle hebben bijvoorbeeld de PIVOT-operator waarmee dergelijke gegevenstransformatie kan worden uitgevoerd. Als we met SqlServer zouden werken, zou onze query er als volgt uitzien.
SELECT VendorID ,[250] AS Emp1 ,[251] AS Emp2 ,[252] AS Emp3 ,[253] AS Emp4 ,[254] AS Emp5FROM (SELECT PurchaseOrderID ,EmployeeID ,VendorID FROM Purchasing.PurchaseOrderHeader) pPIVOT( COUNT (PurchaseOrderID) VOOR EmployeeID IN ([250], [251], [252], [253], [254])) ALS TORDER DOOR t.VendorID;
Voorbeeld voor MySQL
In MySQL zullen we de middelen van SQL moeten gebruiken. De gegevens moeten worden gegroepeerd op de leverancierskolom - VendorID , en voor elke vereiste werknemer (EmployeeID ), moet u een aparte kolom maken met een aggregatiefunctie.
In ons geval moeten we het aantal bestellingen berekenen, dus gebruiken we de aggregatiefunctie COUNT.
In de brontabel wordt de informatie over alle medewerkers opgeslagen in één kolom EmployeeID , en we moeten het aantal bestellingen voor een bepaalde medewerker berekenen, dus we moeten onze aggregatiefunctie leren om alleen bepaalde rijen te verwerken.
De aggregatiefunctie houdt geen rekening met NULL-waarden en we gebruiken deze eigenaardigheid voor onze doeleinden.
U kunt de voorwaardelijke operator IF of CASE gebruiken die een specifieke waarde voor de gewenste werknemer retourneert, anders wordt gewoon NULL geretourneerd; als resultaat telt de COUNT-functie alleen niet-NULL-waarden.
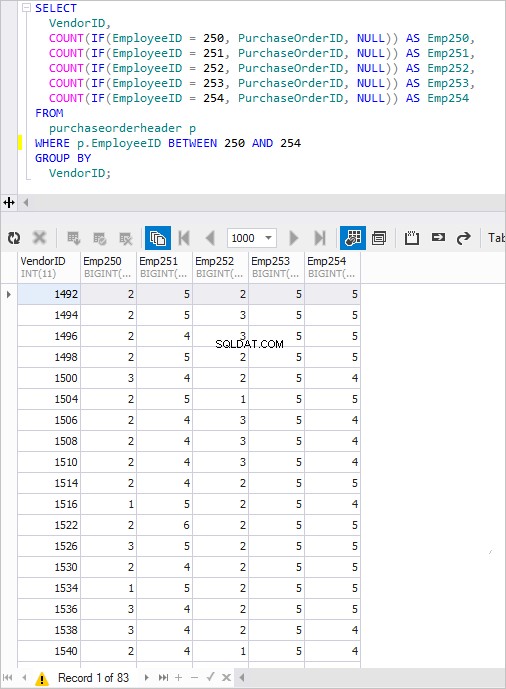
De resulterende vraag is als volgt:
SELECT VendorID, COUNT(IF(EmployeeID =250, PurchaseOrderID, NULL)) AS Emp250, COUNT(IF(EmployeeID =251, PurchaseOrderID, NULL)) AS EmployeeID =251, COUNT(IF(EmployeeID =252, PurchaseOrderID, NULL) ) AS Werknemer252, COUNT(IF(EmployeeID =253, PurchaseOrderID, NULL)) AS Werknemer253, COUNT(IF(EmployeeID =254, PurchaseOrderID, NULL)) AS Werknemer254FROM PurchaseOrderHeader pWHERE p.EmployeeID TUSSEN 250 EN 254GROUP OP VendorID;>Of zelfs zo:
VendorID, COUNT(IF(EmployeeID =250, 1, NULL)) AS Emp250, COUNT(IF(EmployeeID =251, 1, NULL)) AS EmployeeID =251, 1, NULL)) AS EmployeeID =251, 1, NULL)) AS EmployeeID =252, 1, NULL)) AS Werknemer252, COUNT(IF(Werknemer-ID =253, 1, NULL)) AS Werknemer253, COUNT(IF(Werknemer-ID =254, 1, NULL)) AS Werknemer254FROM PurchaseOrderHeader pWHERE p.EmployeeID TUSSEN 250 EN 254GROEP PER leverancier-ID;Wanneer uitgevoerd, wordt een bekend resultaat verkregen.
Data pivot automatiseren, query dynamisch maken
Zoals te zien is, heeft de query een bepaalde consistentie, d.w.z. alle getransformeerde kolommen zijn op dezelfde manier gevormd, en om de query te schrijven, moet u de specifieke waarden uit de tabel kennen. Om een spilquery te vormen, moet u alle mogelijke waarden bekijken en pas dan moet u de query schrijven. Als alternatief kunt u deze taak doorgeven aan een server waardoor deze deze waarden verkrijgt en de routinetaak dynamisch uitvoert.
Laten we terugkeren naar het eerste voorbeeld, waarin we de nieuwe tabel hebben gevormd ProductsNew uit de ProductsOld tafel. Daar zijn de waarden van eigenschappen beperkt en kunnen we niet eens alle mogelijke waarden kennen; we hebben alleen de informatie over waar de namen van de eigenschappen en hun waarde zijn opgeslagen. Dit zijn de Eigendom en Waarde kolommen, respectievelijk.
Het hele algoritme voor het maken van de SQL-query komt neer op het verkrijgen van de waarden, waaruit nieuwe kolommen en aaneenschakelingen van onveranderlijke delen van de query zullen worden gevormd.
SELECT GROUP_CONCAT( CONCAT( 'MAX(IF(Property =''', t.Property, ''', Value, NULL)) AS ', t.Property ) ) INTO @PivotQueryFROM (SELECT Property FROM ProductOld GROUP BY Property) t;SET @PivotQuery =CONCAT('SELECT ProductID,', @PivotQuery, ' FROM ProductOld GROUP BY ProductID');Variabele @PivotQuery slaat onze zoekopdracht op, de tekst is voor de duidelijkheid opgemaakt.
SELECT ProductID, MAX(IF(Property ='Color', Value, NULL)) AS Color, MAX(IF(Property ='Name', Value, NULL)) AS Name, MAX(IF(Property ='ProductNumber) ', Value, NULL)) AS ProductNumber, MAX(IF(Property ='Size', Value, NULL)) AS Size, MAX(IF(Property ='SizeUnitMeasureCode', Value, NULL)) AS SizeUnitMeasureCodeFROM ProductOldGROUP BY ProductIDNadat we het hebben uitgevoerd, verkrijgen we het gewenste resultaat dat overeenkomt met het schema van de tabel ProductsNew.
Bovendien kan de query van variabele @PivotQuery in het script worden uitgevoerd met het MySQL-statement EXECUTE.PREPARE-instructie FROM @PivotQuery;EXECUTE-instructie;DEALLOCATE PREPARE-instructie;