Het verplaatsen van uw gegevens naar een openbare cloudservice is een grote beslissing. Alle grote cloudleveranciers bieden clouddatabaseservices, waarbij Amazon RDS voor MySQL waarschijnlijk het populairst is.
In deze blog bekijken we wat het is, hoe het werkt en vergelijken we de voor- en nadelen ervan.
RDS (Relational Database Service) is een aanbod van Amazon Web Services. Kortom, het is een Database as a Service, waarbij Amazon uw database implementeert en beheert. Het zorgt voor taken zoals back-up en patching van de databasesoftware, evenals hoge beschikbaarheid. Een paar databases worden ondersteund door RDS, we zijn hier echter vooral geïnteresseerd in MySQL - Amazon ondersteunt MySQL en MariaDB. Er is ook Aurora, de Amazon-kloon van MySQL, verbeterd, vooral op het gebied van replicatie en hoge beschikbaarheid.
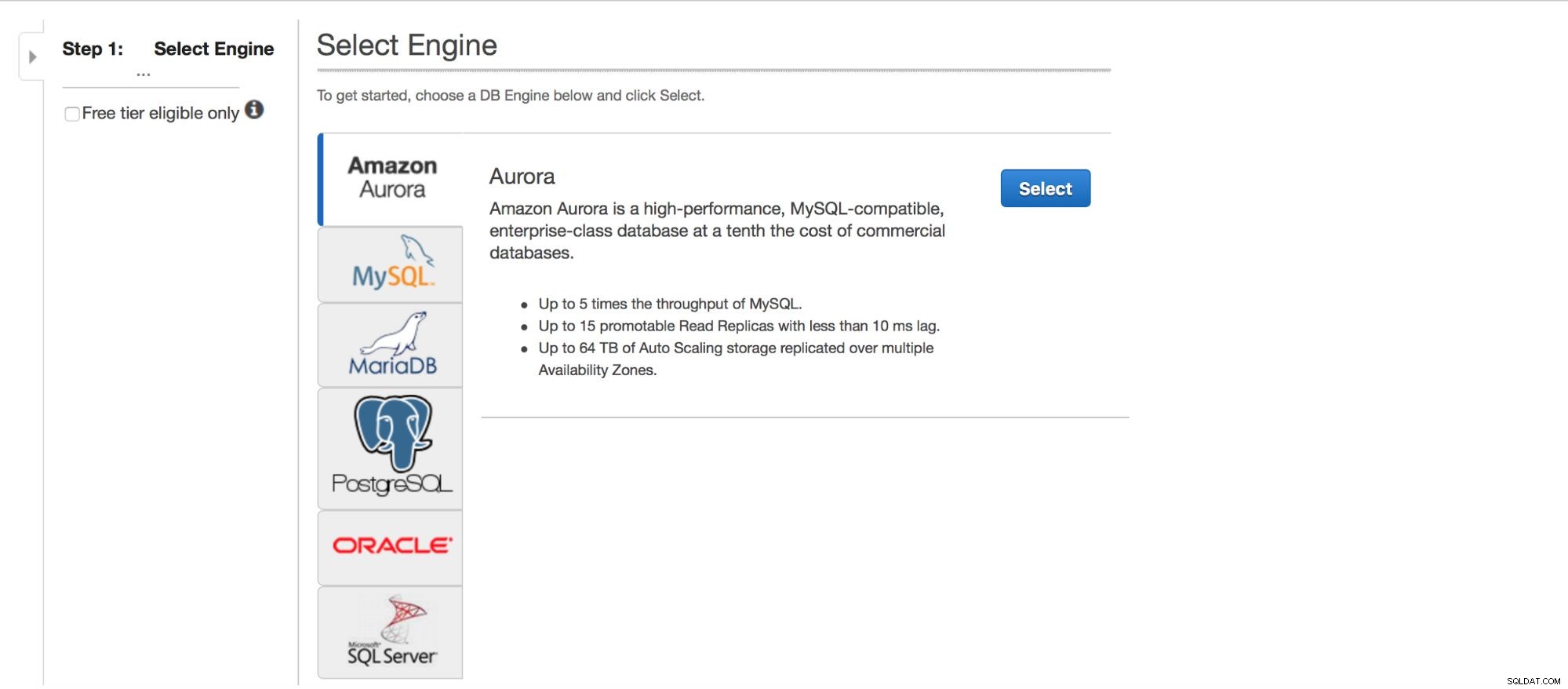
MySQL implementeren via RDS
Laten we eens kijken naar de inzet van MySQL via RDS. We hebben MySQL gekozen en vervolgens krijgen we een aantal implementatiepatronen te zien waaruit we kunnen kiezen.
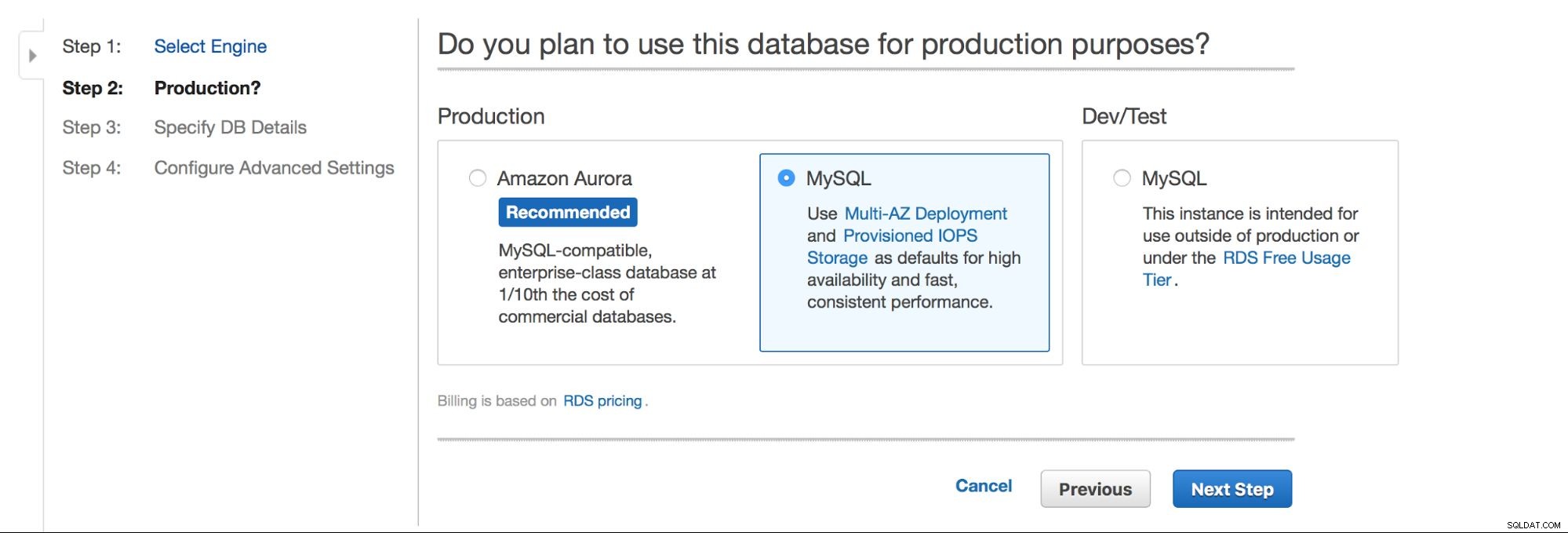
De belangrijkste keuze is:willen we een hoge beschikbaarheid hebben of niet? Aurora wordt ook gepromoot.
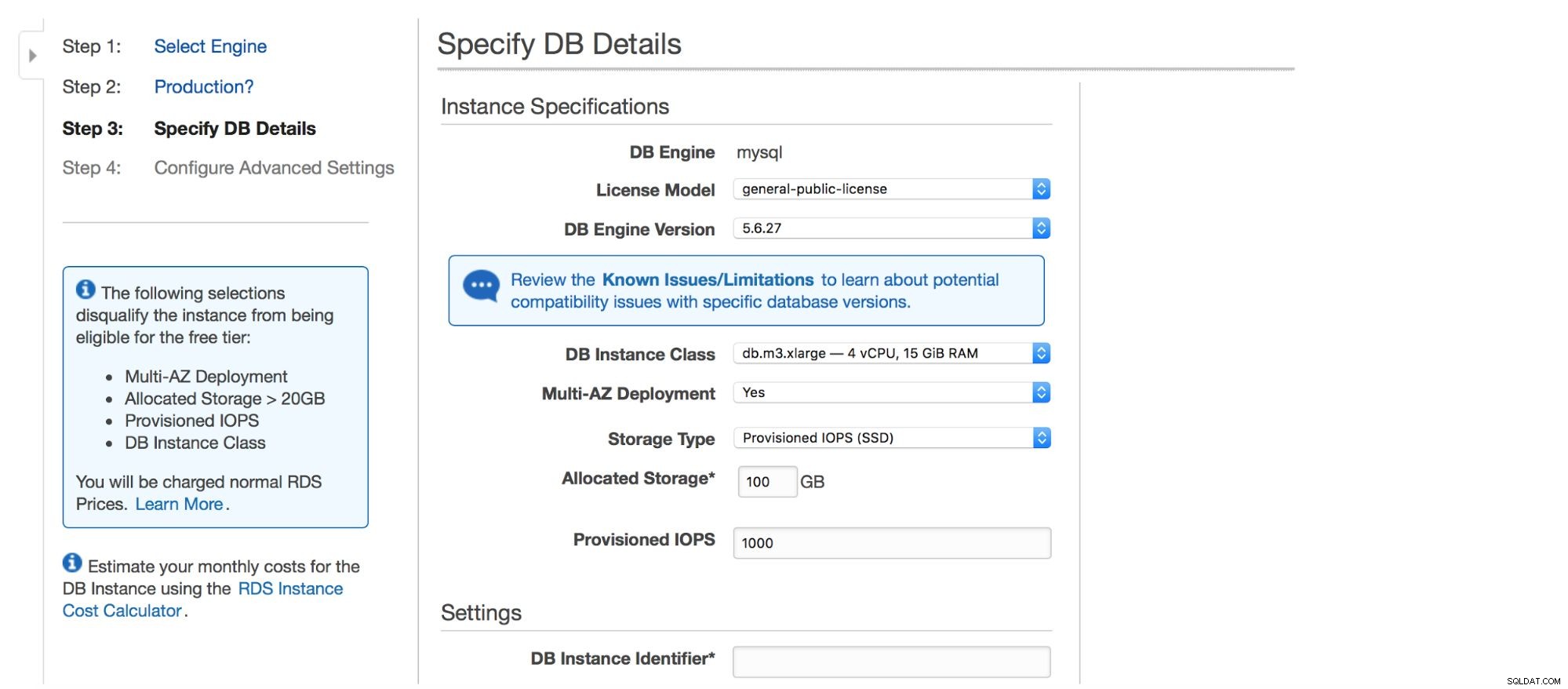
Het volgende dialoogvenster geeft ons enkele opties om aan te passen. U kunt een van de vele MySQL-versies kiezen - er zijn verschillende 5.5-, 5.6- en 5.7-versies beschikbaar. Database-instantie - u kunt kiezen uit typische instantiegroottes die beschikbaar zijn in een bepaalde regio.
De volgende optie is een vrij belangrijke keuze:wil je multi-AZ-implementatie gebruiken of niet? Dit heeft alles te maken met hoge beschikbaarheid. Als u geen multi-AZ-implementatie wilt gebruiken, wordt één exemplaar geïnstalleerd. In het geval van een storing, wordt er een nieuwe gedraaid en wordt het datavolume erop teruggeplaatst. Dit proces duurt enige tijd, gedurende welke uw database niet beschikbaar zal zijn. Natuurlijk kun je deze impact minimaliseren door slaven te gebruiken en een van hen te promoten, maar het is geen geautomatiseerd proces. Als u geautomatiseerde hoge beschikbaarheid wilt hebben, moet u multi-AZ-implementatie gebruiken. Wat er zal gebeuren, is dat er twee database-instanties worden gemaakt. Een daarvan is voor u zichtbaar. Een tweede exemplaar, in een aparte beschikbaarheidszone, is niet zichtbaar voor de gebruiker. Het zal fungeren als een schaduwkopie, klaar om het verkeer over te nemen zodra het actieve knooppunt uitvalt. Het is nog steeds geen perfecte oplossing omdat het verkeer moet worden omgeschakeld van de mislukte instantie naar de schaduwinstantie. In onze tests duurde het ~45s om een failover uit te voeren, maar dit kan natuurlijk afhangen van de grootte van de instantie, I/O-prestaties enz. Maar het is veel beter dan niet-geautomatiseerde failover waarbij alleen slaves betrokken zijn.
Ten slotte hebben we opslaginstellingen - type, grootte, PIOPS (indien van toepassing) en database-instellingen - identifier, gebruiker en wachtwoord.
In de volgende stap wachten nog een paar opties op gebruikersinvoer.
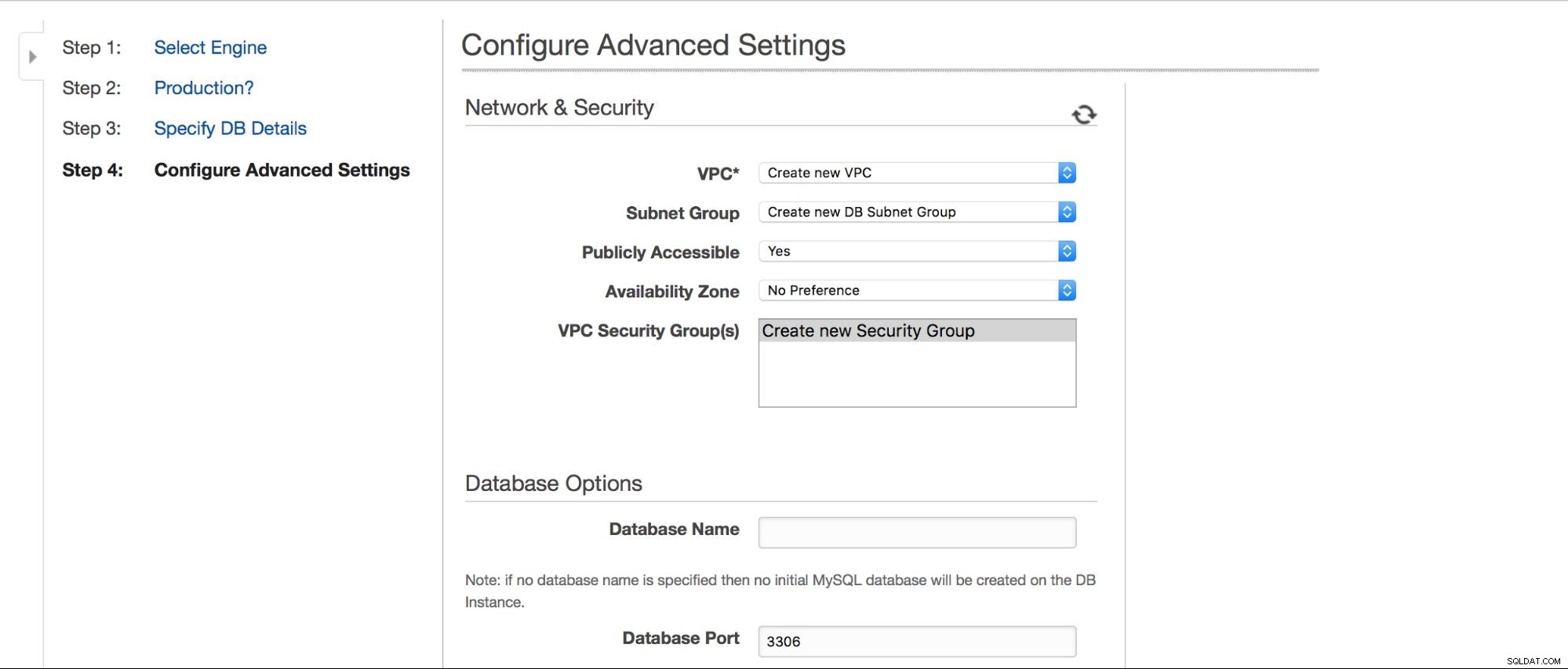
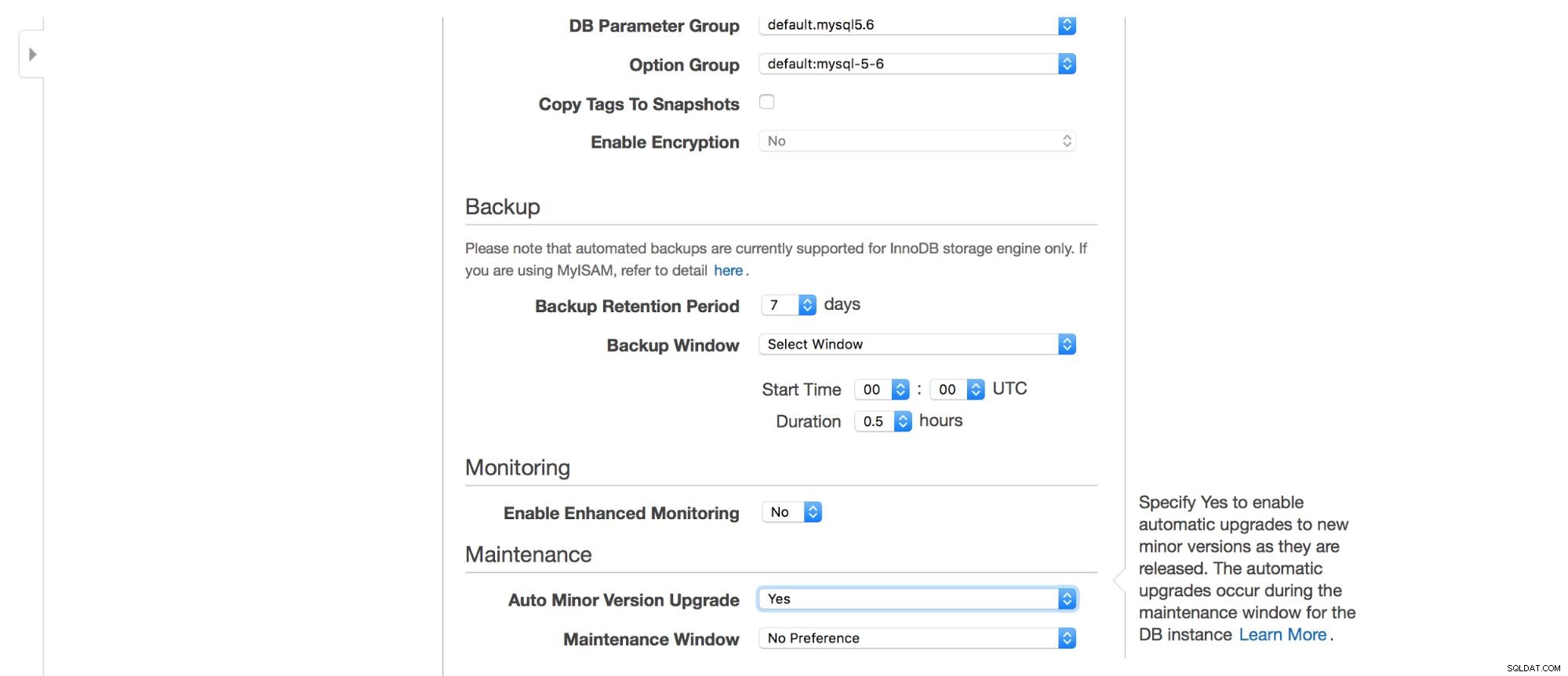
We kunnen kiezen waar de instantie moet worden gemaakt:VPC, subnet, of deze openbaar beschikbaar moet zijn of niet (zoals in - moet een openbaar IP-adres worden toegewezen aan de RDS-instantie), beschikbaarheidszone en VPC-beveiligingsgroep. Dan hebben we database-opties:eerst te maken schema, poort-, parameter- en optiegroepen, of metadatatags in snapshots moeten worden opgenomen of niet, encryptie-instellingen.
Vervolgens back-upopties - hoe lang wilt u uw back-ups bewaren? Wanneer zou je ze willen hebben? Een soortgelijke installatie is gerelateerd aan onderhoud - soms moeten Amazon-beheerders onderhoud uitvoeren aan uw RDS-instantie - dit gebeurt binnen een vooraf gedefinieerd venster dat u hier kunt instellen. Houd er rekening mee dat er geen optie is om niet ten minste 30 minuten te kiezen voor het onderhoudsvenster, daarom is het erg belangrijk om multi-AZ-instantie in productie te hebben. Onderhoud kan leiden tot het opnieuw opstarten van de node of het enige tijd niet beschikbaar zijn. Zonder multi-AZ moet je die downtime accepteren. Met multi-AZ-implementatie vindt failover plaats.
Ten slotte hebben we instellingen met betrekking tot aanvullende monitoring - willen we dit ingeschakeld hebben of niet?
RDS beheren
In dit hoofdstuk gaan we dieper in op het beheren van MySQL RDS. We zullen niet alle beschikbare opties doornemen, maar we willen graag enkele van de functies benadrukken die Amazon beschikbaar heeft gesteld.
Momentopnamen
MySQL RDS gebruikt EBS-volumes als opslag, dus het kan EBS-snapshots voor verschillende doeleinden gebruiken. Back-ups, slaves - allemaal gebaseerd op snapshots. U kunt snapshots handmatig maken of ze kunnen automatisch worden gemaakt, wanneer dat nodig is. Het is belangrijk om in gedachten te houden dat EBS-snapshots in het algemeen (niet alleen op RDS-instanties) enige overhead toevoegen aan I/O-bewerkingen. Als u een momentopname wilt maken, verwacht dan dat uw I/O-prestaties afnemen. Tenzij u multi-AZ-implementatie gebruikt, tenminste. In dat geval wordt de "schaduw"-instantie gebruikt als een bron van snapshots en is er geen impact zichtbaar op de productie-instantie.
DevOps-gids voor databasebeheer van verschillendenines Lees meer over wat u moet weten om uw open source-databases te automatiseren en beherenGratis downloadenBack-ups
Back-ups zijn gebaseerd op snapshots. Zoals hierboven vermeld, kunt u uw back-upschema en retentie definiëren wanneer u een nieuwe instantie maakt. Natuurlijk kun je die instellingen achteraf nog aanpassen via de optie 'instantie wijzigen'.
U kunt op elk moment een momentopname herstellen - u moet naar het momentopnamegedeelte gaan, de momentopname kiezen die u wilt herstellen, en u krijgt een dialoogvenster te zien dat lijkt op het dialoogvenster dat u hebt gezien toen u een nieuwe instantie aanmaakte. Dit is geen verrassing, aangezien u een momentopname alleen in een nieuwe instantie kunt herstellen - er is geen manier om deze op een van de bestaande RDS-instanties te herstellen. Het kan als een verrassing komen, maar zelfs in een cloudomgeving kan het zinvol zijn om hardware (en instanties die u al heeft) opnieuw te gebruiken. In een gedeelde omgeving kunnen de prestaties van een enkele virtuele instantie verschillen - misschien houdt u liever vast aan het prestatieprofiel waarmee u al bekend bent. Helaas is dit niet mogelijk in RDS.
Een andere optie in RDS is herstel op een bepaald tijdstip - een zeer belangrijke functie, een vereiste voor iedereen die goed voor haar gegevens moet zorgen. Hier zijn de zaken complexer en minder helder. Om te beginnen is het belangrijk om in gedachten te houden dat MySQL RDS binaire logs voor de gebruiker verbergt. U kunt een aantal instellingen wijzigen en aangemaakte binlogs weergeven, maar u hebt er geen directe toegang toe - om enige bewerking uit te voeren, inclusief het gebruik ervan voor herstel, kunt u alleen de gebruikersinterface of CLI gebruiken. Dit beperkt uw opties tot wat Amazon u toestaat, en het stelt u in staat uw back-up te herstellen tot de laatste "herstelbare tijd", die toevallig wordt berekend met een interval van 5 minuten. Dus als uw gegevens om 9.33 uur zijn verwijderd, kunt u deze alleen herstellen tot de staat om 9.30 uur. Herstel op een bepaald tijdstip werkt op dezelfde manier als het herstellen van snapshots - er wordt een nieuwe instantie gemaakt.
Uitschalen, replicatie
MySQL RDS maakt scale-out mogelijk door nieuwe slaves toe te voegen. Wanneer een slave wordt gemaakt, wordt een momentopname van de master gemaakt en deze wordt gebruikt om een nieuwe host te maken. Dit onderdeel werkt redelijk goed. Helaas kunt u geen complexere replicatietopologie maken zoals een met tussenliggende masters. U kunt geen master-master-configuratie maken, waardoor elke HA in handen is van Amazon (en multi-AZ-implementaties). Van wat we kunnen zien, is er geen manier om GTID in te schakelen (niet dat je er voordeel uit zou kunnen halen omdat je geen controle hebt over de replicatie, geen CHANGE MASTER in RDS), alleen normale, ouderwetse binlog-posities.
Gebrek aan GTID maakt het niet haalbaar om multithreaded replicatie te gebruiken - terwijl het mogelijk is om een aantal werkers in te stellen met behulp van RDS-parametergroepen, is dit zonder GTID onbruikbaar. Het belangrijkste probleem is dat er geen manier is om een enkele binaire logpositie te lokaliseren in het geval van een crash - sommige werknemers kunnen achterop zijn geweest, andere zouden geavanceerder kunnen zijn. Als u de laatst toegepaste gebeurtenis gebruikt, verliest u gegevens die nog niet zijn toegepast door die "achterblijvende" werknemers. Als u de oudste gebeurtenis gebruikt, krijgt u hoogstwaarschijnlijk "dubbele sleutel" -fouten die worden veroorzaakt door gebeurtenissen die worden toegepast door die werknemers die meer geavanceerd zijn. Natuurlijk is er een manier om dit probleem op te lossen, maar het is niet triviaal en tijdrovend - zeker niet iets dat u gemakkelijk kunt automatiseren.
Gebruikers die zijn gemaakt op MySQL RDS hebben geen SUPER-rechten, dus bewerkingen, die eenvoudig zijn in stand-alone MySQL, zijn niet triviaal in RDS. Amazon besloot om opgeslagen procedures te gebruiken om de gebruiker in staat te stellen een aantal van die bewerkingen uit te voeren. Voor zover we kunnen zien, worden een aantal potentiële problemen behandeld, hoewel dit niet altijd het geval is geweest - we herinneren ons wanneer je niet naar het volgende binaire logboek op de master kon draaien. Een mastercrash + binlog-corruptie kunnen alle slaves kapot maken - nu is daar een procedure voor:rds_next_master_log .
Een slave kan handmatig worden gepromoveerd tot master. Dit zou je in staat stellen een soort HA te creëren bovenop het multi-AZ-mechanisme (of het te omzeilen), maar het is zinloos gemaakt door het feit dat je geen van de bestaande slaves kunt reslaven aan de nieuwe master. Onthoud dat u geen controle heeft over de replicatie. Dit maakt de hele oefening zinloos - tenzij je master al je verkeer kan verwerken. Nadat je een nieuwe master hebt gepromoveerd, kun je er geen failover naar uitvoeren omdat deze geen slaves heeft om je lading af te handelen. Het opstarten van nieuwe slaves kost tijd omdat er eerst EBS-snapshots moeten worden gemaakt en dit kan uren duren. Vervolgens moet u de infrastructuur opwarmen voordat u deze kunt belasten.
Gebrek aan SUPER Privilege
Zoals we eerder vermeldden, verleent RDS gebruikers geen SUPER-privilege en dit wordt vervelend voor iemand die gewend is om het op MySQL te hebben. Neem het als vanzelfsprekend aan dat u in de eerste weken zult leren hoe vaak het nodig is om dingen te doen die u vrij vaak doet - zoals het doden van query's of het uitvoeren van het prestatieschema. In RDS moet u zich houden aan een vooraf gedefinieerde lijst met opgeslagen procedures en deze gebruiken in plaats van dingen direct te doen. U kunt ze allemaal weergeven met de volgende zoekopdracht:
SELECT specific_name FROM information_schema.routines;Net als bij replicatie zijn een aantal taken gedekt, maar als je in een situatie bent beland die nog niet is gedekt, heb je pech.
Interoperabiliteit en hybride cloudconfiguraties
Dit is een ander gebied waar het RDS aan flexibiliteit ontbreekt. Stel dat u een gemengde cloud/on-premises setup wilt bouwen - u heeft een RDS-infrastructuur en u wilt een aantal slaves on-premises maken. Het grootste probleem waarmee u te maken krijgt, is dat er geen manier is om gegevens uit RDS te verplaatsen, behalve door een logische dump te maken. U kunt snapshots van RDS-gegevens maken, maar u hebt er geen toegang toe en u kunt ze niet weghalen van AWS. Je hebt ook geen fysieke toegang tot de instantie om xtrabackup, rsync of zelfs cp te gebruiken. De enige optie voor u is om mysqldump, mydumper of soortgelijke tools te gebruiken. Dit voegt complexiteit toe (karakterset en sorteerinstellingen kunnen mogelijk problemen veroorzaken) en is tijdrovend (het duurt lang om gegevens te dumpen en te laden met behulp van logische back-uptools).
Het is mogelijk om replicatie tussen RDS en een externe instantie in te stellen (op beide manieren, dus het migreren van gegevens naar RDS is ook mogelijk), maar het kan een zeer tijdrovend proces zijn.
Aan de andere kant, als je binnen een RDS-omgeving wilt blijven en je infrastructuur wilt overspannen over de Atlantische Oceaan of van de oost- tot westkust van de VS, dan kun je dat met RDS doen - je kunt gemakkelijk een regio kiezen wanneer je een nieuwe slaaf aanmaakt.
Als u uw master van de ene regio naar de andere wilt verplaatsen, is dit helaas vrijwel niet mogelijk zonder downtime - tenzij uw enkele node al uw verkeer aankan.
Beveiliging
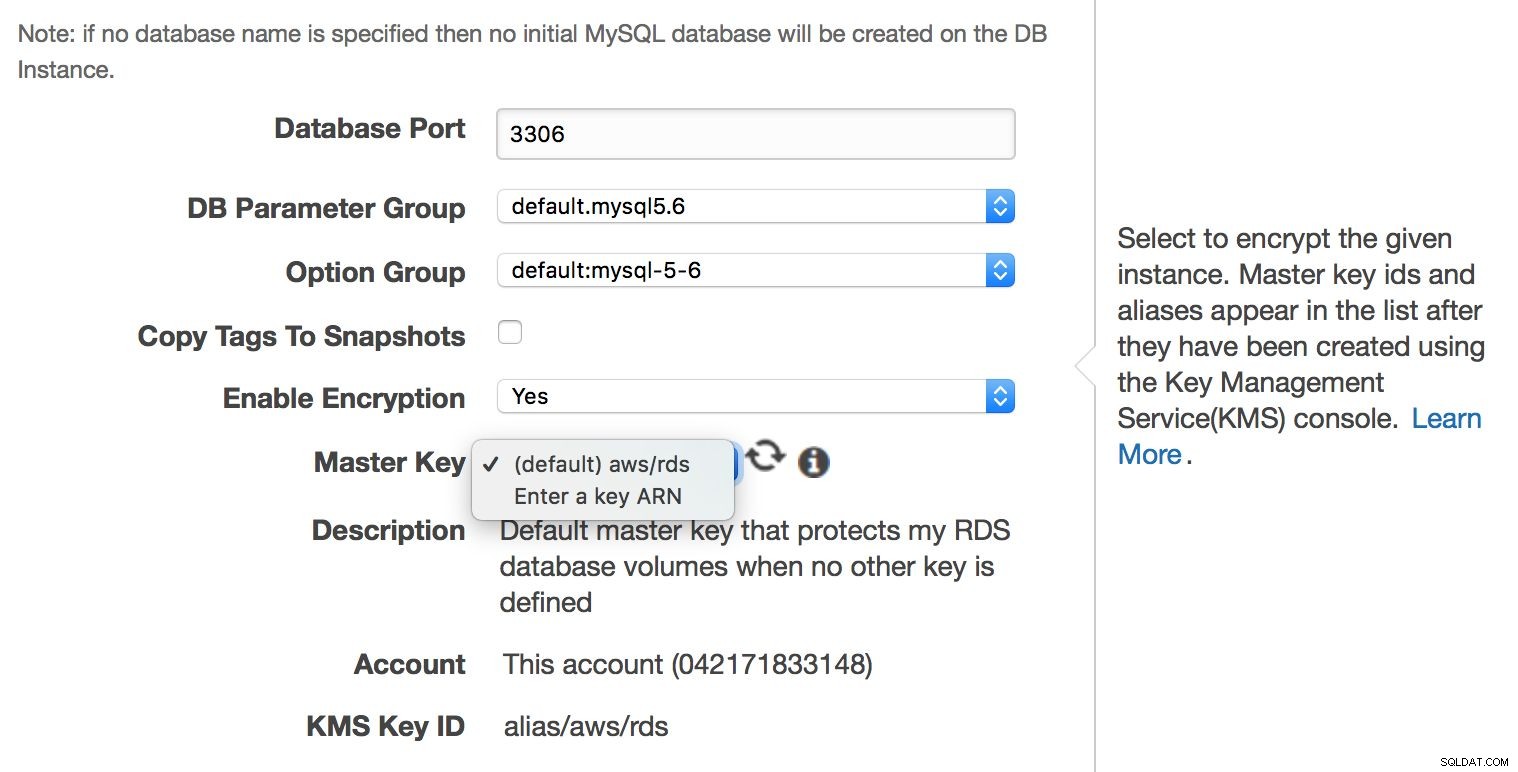
Hoewel MySQL RDS een beheerde service is, wordt niet elk aspect met betrekking tot beveiliging verzorgd door de technici van Amazon. Amazon noemt het "Shared Responsibility Model". Kortom, Amazon zorgt voor de beveiliging van de netwerk- en opslaglaag (zodat gegevens op een veilige manier worden overgedragen), besturingssysteem (patches, security fixes). Aan de andere kant moet de gebruiker voor de rest van het beveiligingsmodel zorgen. Zorg ervoor dat het verkeer van en naar de RDS-instantie binnen VPC beperkt is, zorg ervoor dat authenticatie op databaseniveau correct wordt uitgevoerd (geen MySQL-gebruikersaccounts zonder wachtwoord), controleer of de API-beveiliging is gegarandeerd (AMI's zijn correct ingesteld en met minimaal vereiste privileges). De gebruiker moet ook zorgen voor firewall-instellingen (beveiligingsgroepen) om de blootstelling van RDS en de VPC waarin deze zich bevindt aan externe netwerken te minimaliseren. Het is ook de verantwoordelijkheid van de gebruiker om data-at-rest-codering te implementeren - op applicatieniveau of op databaseniveau, door in de eerste plaats een gecodeerde RDS-instantie te maken.
Versleuteling op databaseniveau kan alleen worden ingeschakeld bij het maken van de instantie, u kunt een bestaande, al actieve database niet versleutelen.
RDS-beperkingen
Als u van plan bent RDS te gebruiken of als u het al gebruikt, moet u rekening houden met de beperkingen die met MySQL RDS worden geleverd.
Gebrek aan SUPER-privilege kan, zoals we al zeiden, erg vervelend zijn. Hoewel opgeslagen procedures voor een aantal bewerkingen zorgen, is het een leercurve omdat u moet leren dingen op een andere manier te doen. Gebrek aan SUPER-privileges kan ook problemen veroorzaken bij het gebruik van externe monitoring- en trendingtools - er zijn nog steeds enkele tools die dit voorrecht voor een deel van zijn functionaliteit nodig hebben.
Gebrek aan directe toegang tot MySQL-gegevensmap en logboeken maakt het moeilijker om acties uit te voeren waarbij ze betrokken zijn. Het gebeurt zo nu en dan dat een DBA binaire logs of staartfouten, langzame query's of algemeen logboek moet ontleden. Hoewel het mogelijk is om toegang te krijgen tot die logboeken op RDS, is het omslachtiger dan doen wat je nodig hebt door in te loggen op shell op de MySQL-host. Het lokaal downloaden ervan kost ook wat tijd en voegt extra latentie toe aan wat je ook doet.
Gebrek aan controle over replicatietopologie, hoge beschikbaarheid alleen in multi-AZ-implementaties. Aangezien u geen controle heeft over de replicatie, kunt u geen enkele vorm van mechanisme voor hoge beschikbaarheid in uw databaselaag implementeren. Het maakt niet uit dat je meerdere slaven hebt, je kunt sommige niet als masterkandidaten gebruiken, want zelfs als je een slaaf promoveert tot master, is er geen manier om de resterende slaven van deze nieuwe master te reslaven. Dit dwingt gebruikers om multi-AZ-implementaties te gebruiken en verhoogt de kosten (de 'schaduw'-instantie wordt niet gratis geleverd, de gebruiker moet ervoor betalen).
Verlaagde beschikbaarheid door geplande uitvaltijd. Wanneer u een RDS-instantie implementeert, moet u een wekelijks tijdvenster van 30 minuten kiezen waarin onderhoudswerkzaamheden aan uw RDS-instantie mogen worden uitgevoerd. Aan de ene kant is dit begrijpelijk, aangezien RDS een Database as a Service is, zodat hardware- en software-upgrades van uw RDS-instanties worden beheerd door AWS-ingenieurs. Aan de andere kant vermindert dit uw beschikbaarheid omdat u niet kunt voorkomen dat uw hoofddatabase voor de duur van de onderhoudsperiode uitvalt. Nogmaals, in dit geval verhoogt het gebruik van multi-AZ-setup de beschikbaarheid omdat wijzigingen eerst plaatsvinden op de schaduwinstantie en vervolgens de failover wordt uitgevoerd. Failover zelf is echter niet transparant, dus op de een of andere manier verliest u de uptime. Dit dwingt je om je app te ontwerpen met onverwachte MySQL-masterfouten in gedachten. Niet dat het een slecht ontwerppatroon is - databases kunnen op elk moment crashen en uw toepassing moet zo worden gebouwd dat deze zelfs het meest verschrikkelijke scenario kan weerstaan. Alleen heb je met RDS beperkte opties voor hoge beschikbaarheid.
Verminderde opties voor implementatie met hoge beschikbaarheid. Gezien het gebrek aan flexibiliteit in het beheer van de replicatietopologie, is multi-AZ-implementatie de enige haalbare methode met hoge beschikbaarheid. Deze methode is goed, maar er zijn tools voor MySQL-replicatie die de downtime nog verder zouden minimaliseren. MHA of ClusterControl kan bijvoorbeeld, wanneer gebruikt in combinatie met ProxySQL, (onder bepaalde voorwaarden, zoals het ontbreken van langlopende transacties) een transparant failoverproces voor de toepassing leveren. Als u RDS gebruikt, kunt u deze methode niet gebruiken.
Verminderd inzicht in de prestaties van uw database. Hoewel u statistieken van MySQL zelf kunt krijgen, is het soms gewoon niet genoeg om een volledig beeld van de situatie van 10.000 voet te krijgen. Op een gegeven moment zullen de meeste gebruikers te maken krijgen met echt rare problemen veroorzaakt door defecte hardware of defecte infrastructuur - verloren netwerkpakketten, abrupt beëindigde verbindingen of onverwacht hoog CPU-gebruik. Als je toegang hebt tot je MySQL-host, kun je veel tools gebruiken die je helpen om de status van een Linux-server te diagnosticeren. Wanneer u RDS gebruikt, bent u beperkt tot de statistieken die beschikbaar zijn in Cloudwatch, de monitoring- en trendingtool van Amazon. Voor een meer gedetailleerde diagnose moet u contact opnemen met de ondersteuning en hen vragen het probleem te controleren en op te lossen. Dit kan snel gaan, maar het kan ook een erg lang proces zijn met veel heen en weer e-mailcommunicatie.
Lock-in van leveranciers veroorzaakt door een complex en tijdrovend proces om gegevens uit de MySQL RDS te halen. RDS geeft geen toegang tot MySQL-gegevensdirectory, dus er is geen manier om industriestandaardtools zoals xtrabackup te gebruiken om gegevens op een binaire manier te verplaatsen. Aan de andere kant is de RDS onder de motorkap een MySQL die wordt onderhouden door Amazon, het is moeilijk te zeggen of het 100% compatibel is met upstream of niet. RDS is alleen beschikbaar op AWS, dus je zou geen hybride setup kunnen doen.
Samenvatting
MySQL RDS heeft zowel sterke als zwakke punten. Dit is een zeer goede tool voor diegenen die zich op de applicatie willen concentreren zonder zich zorgen te hoeven maken over het bedienen van de database. Je implementeert een database en begint met het uitbrengen van queries. U hoeft geen back-upscripts te bouwen of een monitoringoplossing in te stellen, omdat dit al door AWS-technici wordt gedaan - u hoeft het alleen maar te gebruiken.
Er is ook een donkere kant van de MySQL RDS. Gebrek aan opties om complexere setups te bouwen en te schalen buiten alleen het toevoegen van meer slaven. Gebrek aan ondersteuning voor een betere hoge beschikbaarheid dan wat wordt voorgesteld onder multi-AZ-implementaties. Omslachtige toegang tot MySQL-logboeken. Gebrek aan directe toegang tot MySQL-gegevensdirectory en gebrek aan ondersteuning voor fysieke back-ups, waardoor het moeilijk is om de gegevens uit de RDS-instantie te verplaatsen.
Kortom, RDS kan prima voor u werken als u gebruiksgemak belangrijker vindt dan gedetailleerde controle over de database. U moet er rekening mee houden dat u op een bepaald moment in de toekomst MySQL RDS kunt ontgroeien. We hebben het hier niet per se alleen over prestaties. Het gaat meer om de behoefte van uw organisatie aan complexere replicatietopologie of om een beter inzicht in databasebewerkingen om snel verschillende problemen op te lossen die zich van tijd tot tijd voordoen. In dat geval, als uw dataset al in omvang is gegroeid, vindt u het misschien lastig om uit de RDS te stappen. Alvorens een beslissing te nemen om uw gegevens naar RDS te verplaatsen, moeten informatiemanagers rekening houden met de vereisten en beperkingen van hun organisatie op specifieke gebieden.
In de volgende blogposts laten we u zien hoe u uw gegevens uit de RDS naar een aparte locatie kunt brengen. We bespreken zowel de migratie naar EC2 als naar de infrastructuur op locatie.