Tegenwoordig zijn databases verspreid over meerdere clouds heel gewoon. Ze beloven een hoge beschikbaarheid en de mogelijkheid om procedures voor noodherstel gemakkelijk te implementeren. Ze zijn ook een methode om vendor lock-in te voorkomen:als u uw database-omgeving zo ontwerpt dat deze over meerdere cloudproviders kan werken, bent u hoogstwaarschijnlijk niet gebonden aan functies en implementaties die specifiek zijn voor één bepaalde provider. Dit maakt het voor u gemakkelijker om een andere infrastructuurprovider aan uw omgeving toe te voegen, of dit nu een andere cloud is of een on-prem setup. Een dergelijke flexibiliteit is erg belangrijk aangezien er hevige concurrentie is tussen cloudproviders en migreren van de ene naar de andere zou best haalbaar kunnen zijn als het zou worden ondersteund door kostenbesparingen.
Als je je infrastructuur uitbreidt over meerdere datacenters (van dezelfde provider of niet, het maakt niet echt uit) kun je serieuze problemen oplossen. Hoe kan men de gehele infrastructuur zo ontwerpen dat de gegevens veilig zijn? Hoe ga je om met uitdagingen waar je mee te maken krijgt als je in een multi-cloudomgeving werkt? In deze blog zullen we een, maar misschien wel de meest serieuze, bekijken:het potentieel van een split-brain. Wat betekent het? Laten we wat dieper ingaan op wat split-brain is.
Wat is "Split-Brain"?
Split-brain is een toestand waarin een omgeving die uit meerdere knooppunten bestaat, lijdt aan netwerkpartitionering en is opgesplitst in meerdere segmenten die geen contact met elkaar hebben. Het eenvoudigste geval ziet er als volgt uit:
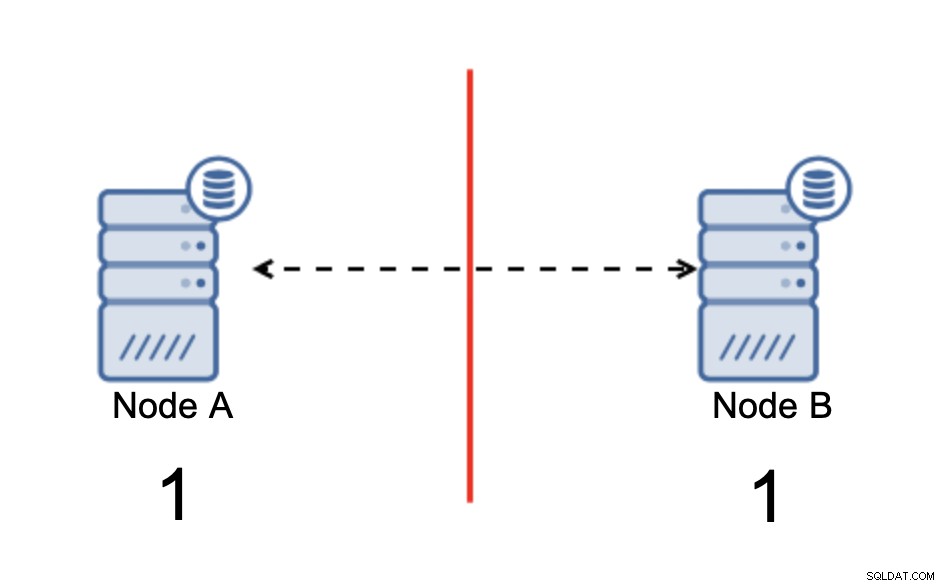
We hebben twee knooppunten, A en B, verbonden via een netwerk met bi -directionele asynchrone replicatie. Vervolgens wordt de netwerkverbinding tussen die knooppunten verbroken. Als gevolg hiervan kunnen beide knooppunten geen verbinding met elkaar maken en kunnen eventuele wijzigingen die op knooppunt A worden uitgevoerd, niet worden verzonden naar knooppunt B en vice versa. Beide knooppunten, A en B, zijn actief en accepteren verbindingen, ze kunnen alleen geen gegevens uitwisselen. Dit kan tot ernstige problemen leiden, aangezien de toepassing wijzigingen kan aanbrengen op beide knooppunten in de verwachting de volledige status van de database te zien, terwijl deze in feite alleen werkt op een gedeeltelijk bekende gegevensstatus. Als gevolg hiervan kunnen onjuiste acties worden ondernomen door de toepassing, kunnen onjuiste resultaten aan de gebruiker worden gepresenteerd, enzovoort. We denken dat het duidelijk is dat split-brain potentieel een zeer gevaarlijke toestand is en dat een van de prioriteiten zou zijn om er tot op zekere hoogte mee om te gaan. Wat kan eraan gedaan worden?
Hoe split-brain te vermijden
Kortom, het hangt ervan af. Het belangrijkste probleem om mee om te gaan, is het feit dat knooppunten actief zijn, maar geen connectiviteit hebben, daarom zijn ze zich niet bewust van de status van het andere knooppunt. Over het algemeen heeft MySQL asynchrone replicatie geen enkel soort mechanisme dat het probleem van de split-brain intern zou oplossen. Je kunt proberen een aantal oplossingen te implementeren die je helpen split-brain te voorkomen, maar ze hebben beperkingen of ze lossen het probleem nog steeds niet volledig op.
Als we afstand nemen van de asynchrone replicatie, zien de zaken er anders uit. MySQL Group Replication en MySQL Galera Cluster zijn technologieën die profiteren van build-it cluster awareness. Beide oplossingen onderhouden de communicatie tussen knooppunten en zorgen ervoor dat het cluster op de hoogte is van de status van de knooppunten. Ze implementeren een quorummechanisme dat bepaalt of clusters operationeel kunnen zijn of niet.
Laten we deze twee oplossingen (asynchrone replicatie en op quorum gebaseerde clusters) in meer detail bespreken.
Quorum-gebaseerde clustering
We gaan niet in op de implementatieverschillen tussen MySQL Galera Cluster en MySQL Group Replication, we zullen ons concentreren op het basisidee achter de op quorum gebaseerde aanpak en hoe deze is ontworpen om het probleem van de split-brain in je cluster.
Het komt erop neer dat:cluster, om te kunnen werken, vereist dat de meeste van zijn knooppunten beschikbaar zijn. Met deze eis kunnen we er zeker van zijn dat de minderheid nooit echt invloed kan hebben op de rest van het cluster, omdat de minderheid geen acties zou moeten kunnen uitvoeren. Dit betekent ook dat, om een uitval van één node te kunnen opvangen, een cluster minimaal drie nodes moet hebben. Als u slechts twee knooppunten heeft:
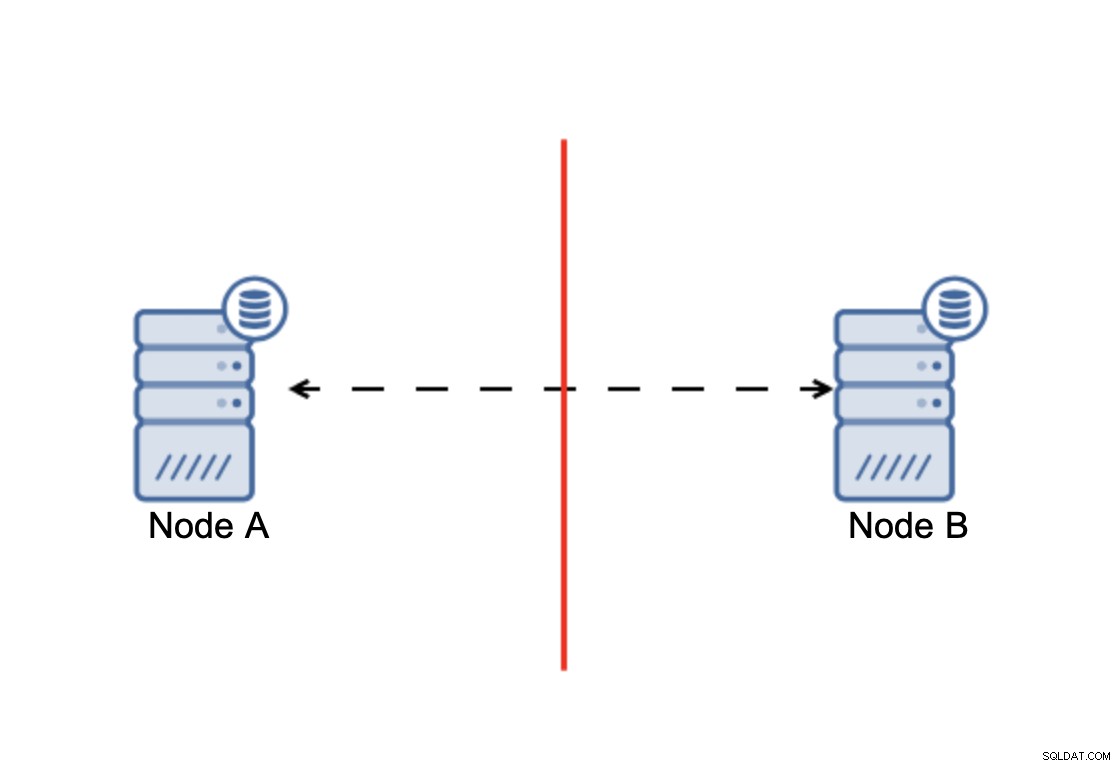
Als er een netwerksplitsing is, krijg je twee delen van de cluster, elk bestaande uit precies 50% van het totale aantal knooppunten in het cluster. Geen van beide delen heeft een meerderheid. Als je echter drie nodes hebt, is het anders:
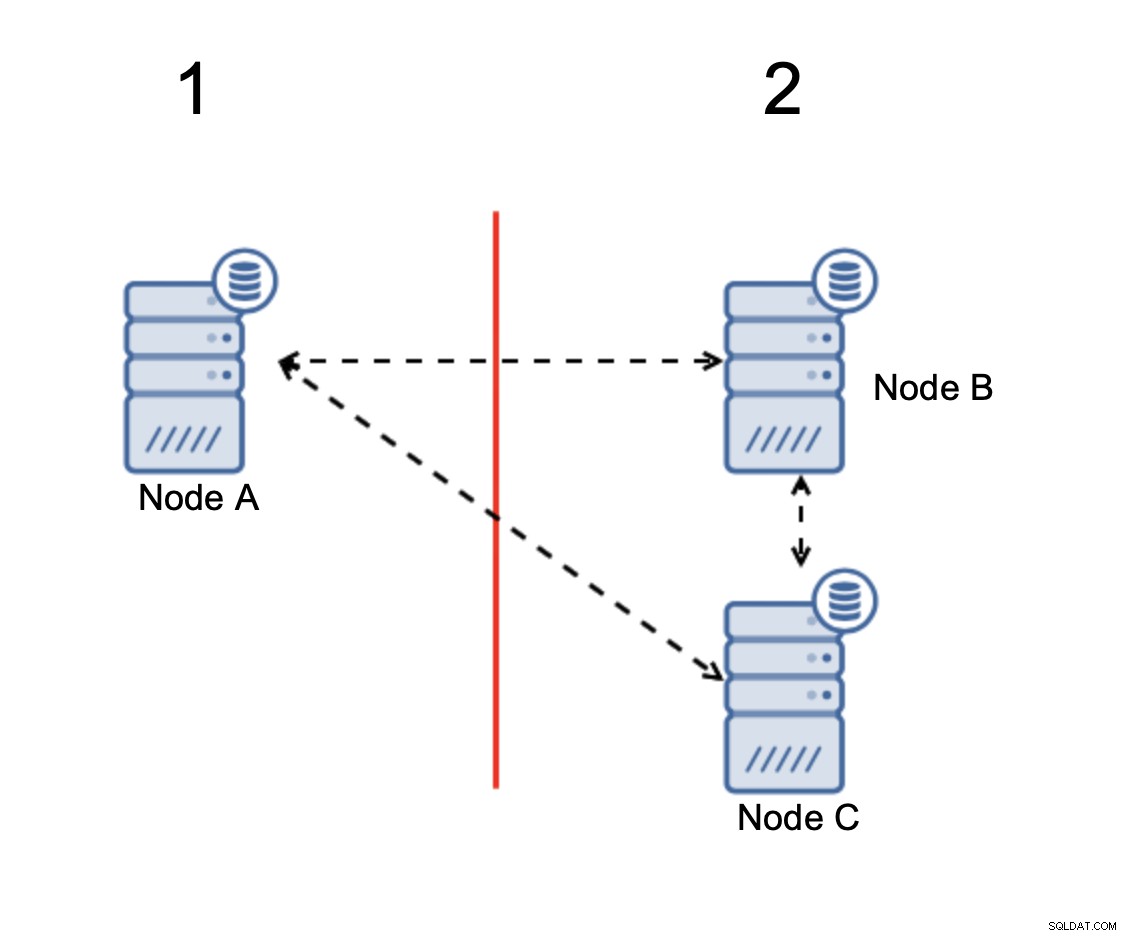
Knooppunten B en C hebben de meerderheid:dat deel bestaat uit twee knooppunten van drie dus het kan blijven werken. Aan de andere kant vertegenwoordigt knooppunt A slechts de 33% van de knooppunten in het cluster, dus het heeft geen meerderheid en het zal stoppen met het verwerken van verkeer om het gespleten brein te vermijden.
Met een dergelijke implementatie is het zeer onwaarschijnlijk dat split-brain zal plaatsvinden (het zou moeten worden geïntroduceerd door een aantal vreemde en onverwachte netwerkstatussen, race-omstandigheden of duidelijke bugs in de clustercode. Hoewel niet onmogelijk om tegen te komen dergelijke omstandigheden, is het gebruik van een van de oplossingen die gebaseerd zijn op het quorum de beste optie om de verdeeldheid die op dit moment bestaat te vermijden.
Asynchrone replicatie
Hoewel niet de ideale keuze als het gaat om het omgaan met split-brain, is asynchrone replicatie nog steeds een haalbare optie. Er zijn verschillende dingen waarmee u rekening moet houden voordat u een multi-clouddatabase met asynchrone replicatie implementeert.
Eerst failover. Asynchrone replicatie wordt geleverd met één schrijver - alleen de master moet beschrijfbaar zijn en andere knooppunten mogen alleen alleen-lezen verkeer bedienen. De uitdaging is hoe om te gaan met het falen van de master?
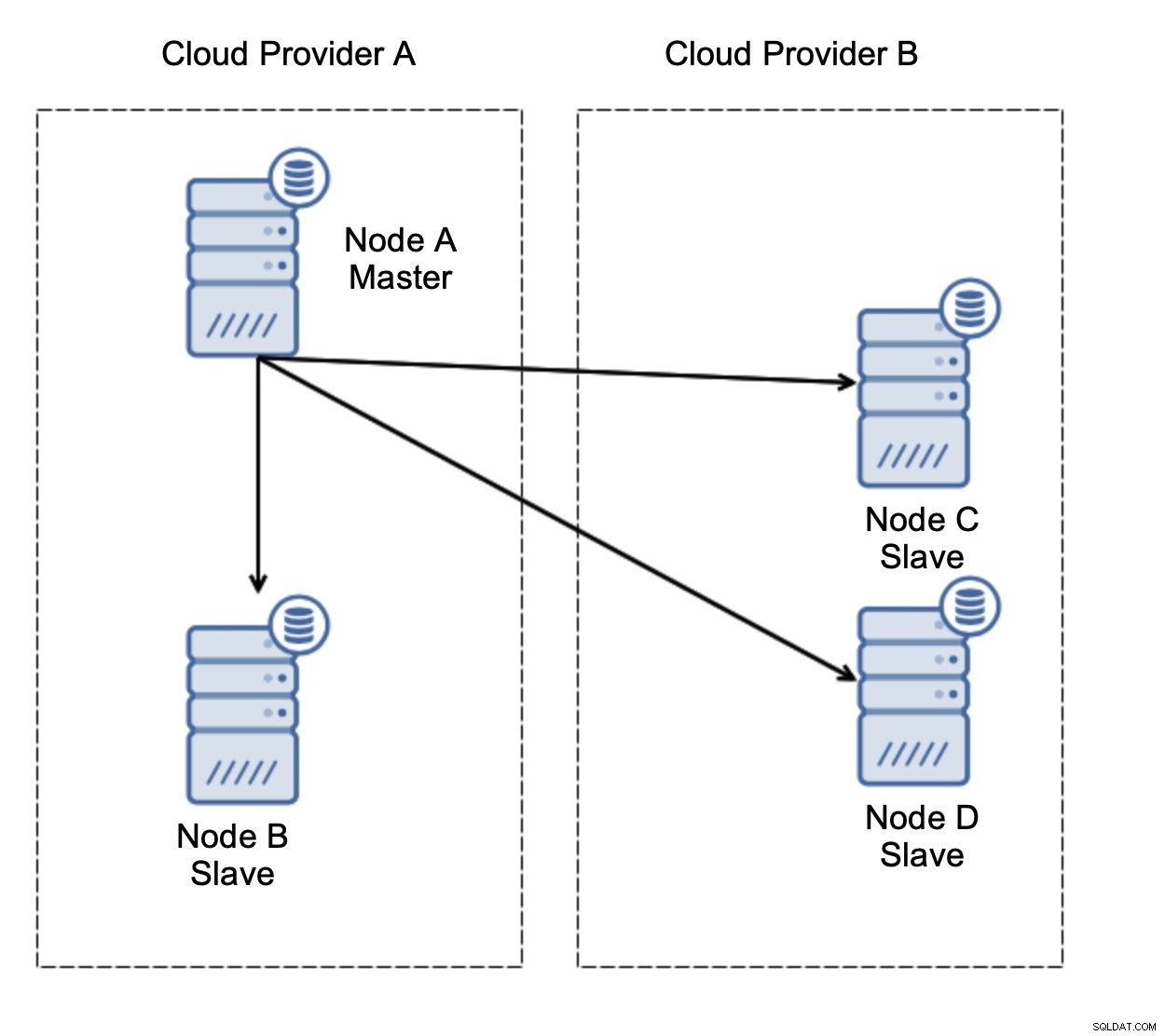
Laten we de configuratie bekijken zoals in het bovenstaande diagram. We hebben twee cloudproviders, elk met twee nodes. Provider A host ook de master. Wat moet er gebeuren als de master faalt? Een van de slaven moet worden gepromoveerd om ervoor te zorgen dat de database operationeel blijft. Idealiter zou het een geautomatiseerd proces moeten zijn om de tijd te verminderen die nodig is om de database in de operationele staat te brengen. Wat zou er echter gebeuren als er een netwerkpartitionering zou zijn? Hoe moeten we de status van het cluster verifiëren?
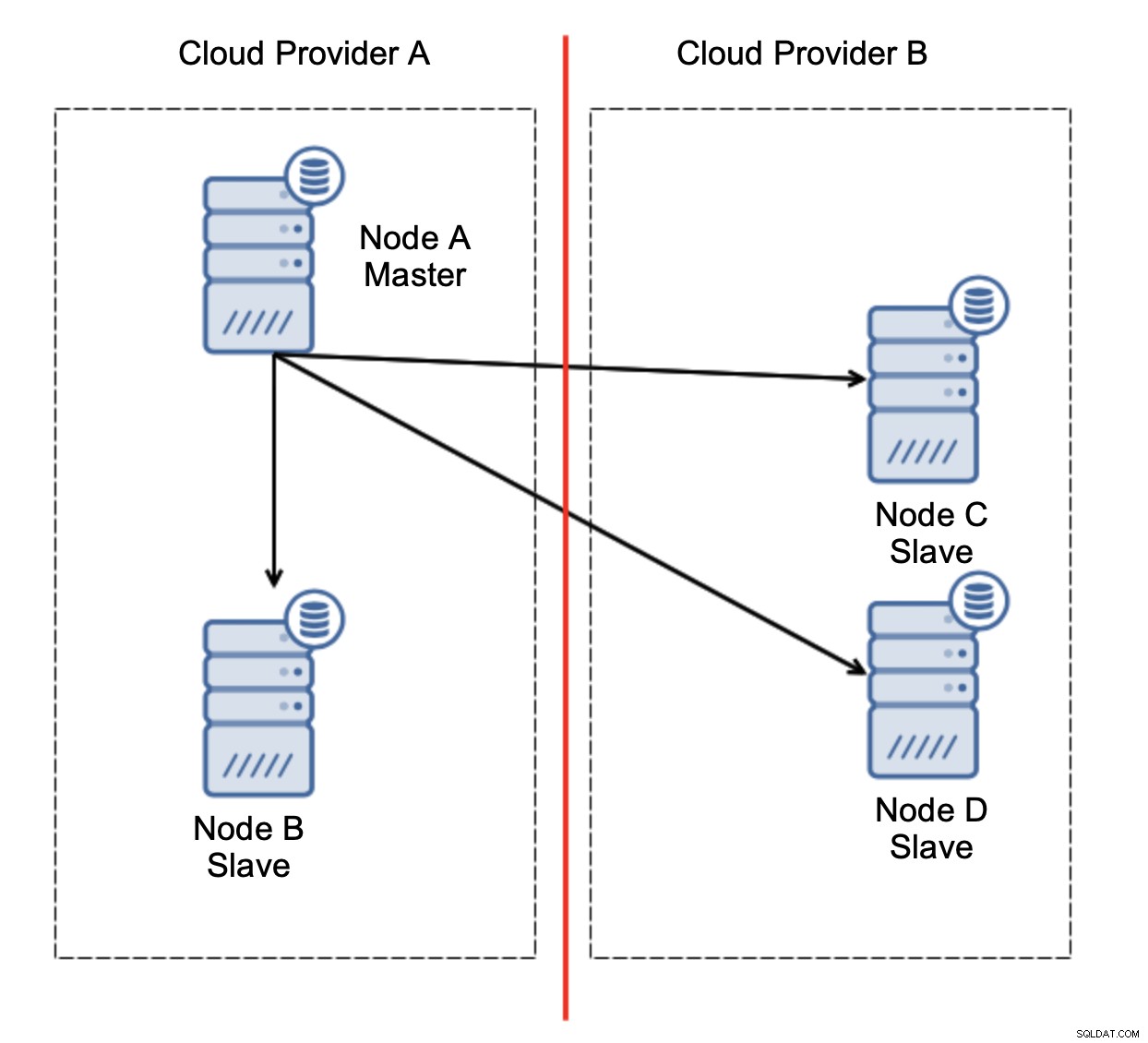
Dit is de uitdaging. De netwerkverbinding tussen twee cloudproviders gaat verloren. Vanuit het standpunt van de knooppunten C en D zijn zowel knooppunt B als master, knooppunt A offline. Moet knooppunt C of D worden gepromoveerd tot master? Maar de oude master is nog steeds actief - hij is niet gecrasht, hij is alleen niet bereikbaar via het netwerk. Als we een van de knooppunten bij provider B zouden promoten, krijgen we twee beschrijfbare masters, twee datasets en split brain:
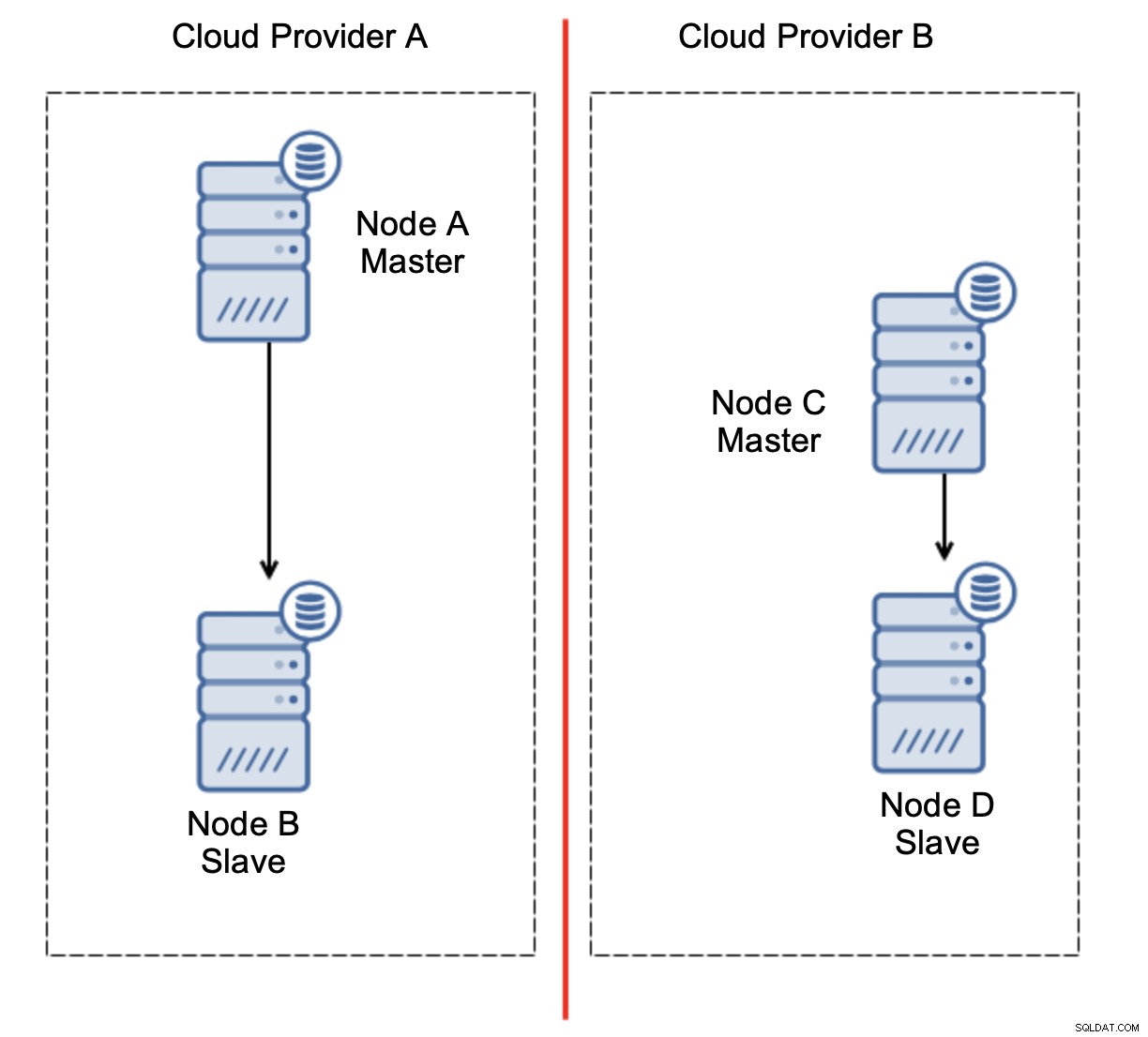
Dit is absoluut niet iets dat we willen. Er zijn hier een aantal opties. Ten eerste kunnen we failover-regels zo definiëren dat de failover alleen kan plaatsvinden in een van de netwerksegmenten, waar de master zich bevindt. In ons geval zou dit betekenen dat alleen knooppunt B automatisch kan worden gepromoveerd tot master. Op die manier kunnen we ervoor zorgen dat de geautomatiseerde failover plaatsvindt als het knooppunt A niet beschikbaar is, maar dat er geen actie wordt ondernomen als er een netwerkpartitionering is. Sommige tools die u kunnen helpen bij het afhandelen van geautomatiseerde failovers (zoals ClusterControl) ondersteunen witte en zwarte lijsten, zodat gebruikers kunnen bepalen naar welke nodes een failover kan worden overwogen en welke nooit als master mogen worden gebruikt.
Een andere optie zou zijn om een soort van "topologiebewustzijn"-oplossing te implementeren. Je zou bijvoorbeeld kunnen proberen de masterstatus te controleren met behulp van externe services zoals load balancers.
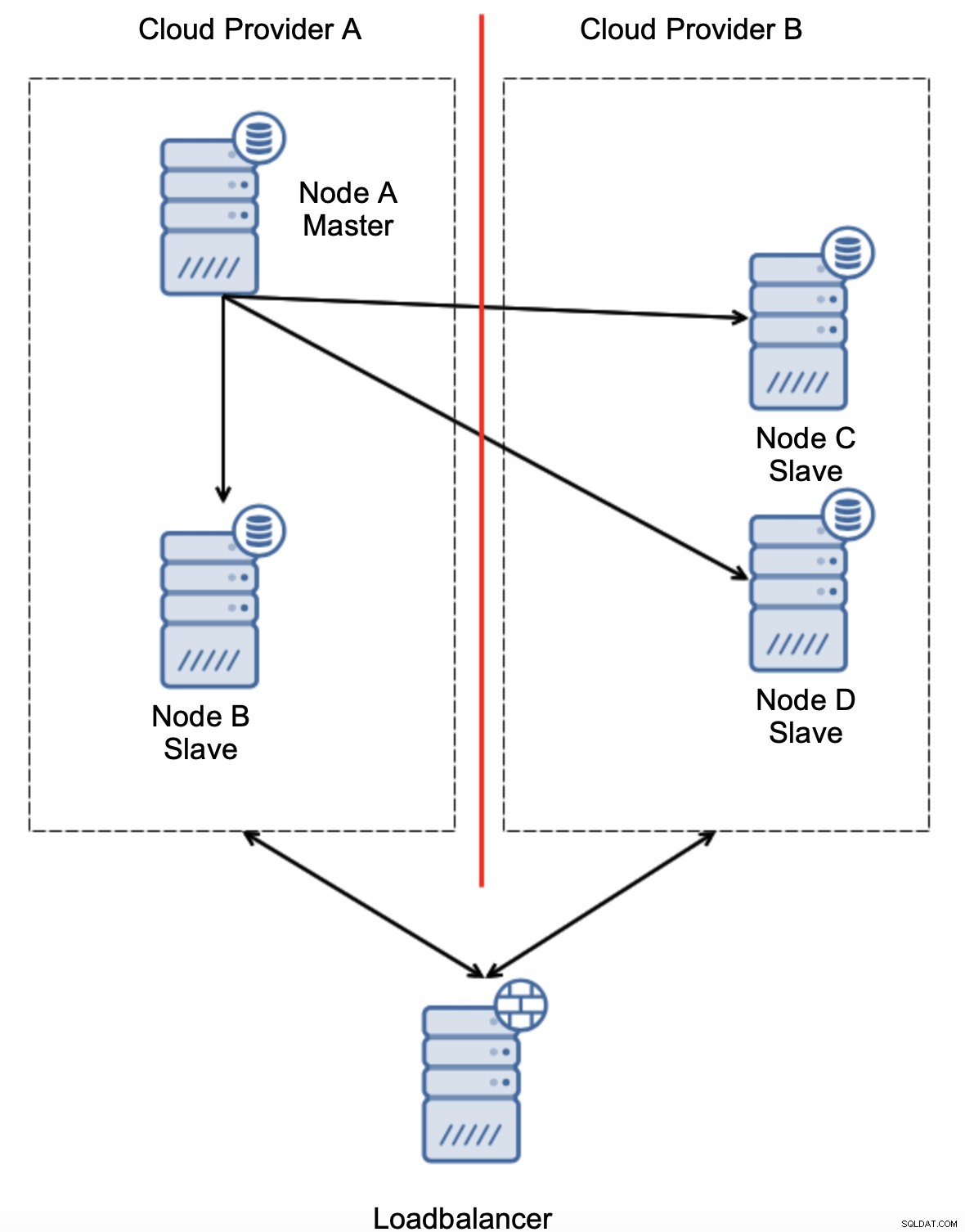
Als de failover-automatisering de status van de topologie zou kunnen controleren, zoals gezien door de load balancer, kan het zijn dat de load balancer, die zich op een derde locatie bevindt, daadwerkelijk beide datacenters kan bereiken en duidelijk kan maken dat nodes in de cloudprovider A niet down zijn, ze zijn gewoon niet bereikbaar vanaf de cloudprovider B. Dergelijke een extra controlelaag is geïmplementeerd in ClusterControl.
Ten slotte, welke tool je ook gebruikt om geautomatiseerde failover te implementeren, het kan ook zo zijn ontworpen dat het quorumbewust is. Met drie knooppunten op drie locaties kunt u vervolgens gemakkelijk zien welk deel van de infrastructuur in leven moet worden gehouden en welke niet.
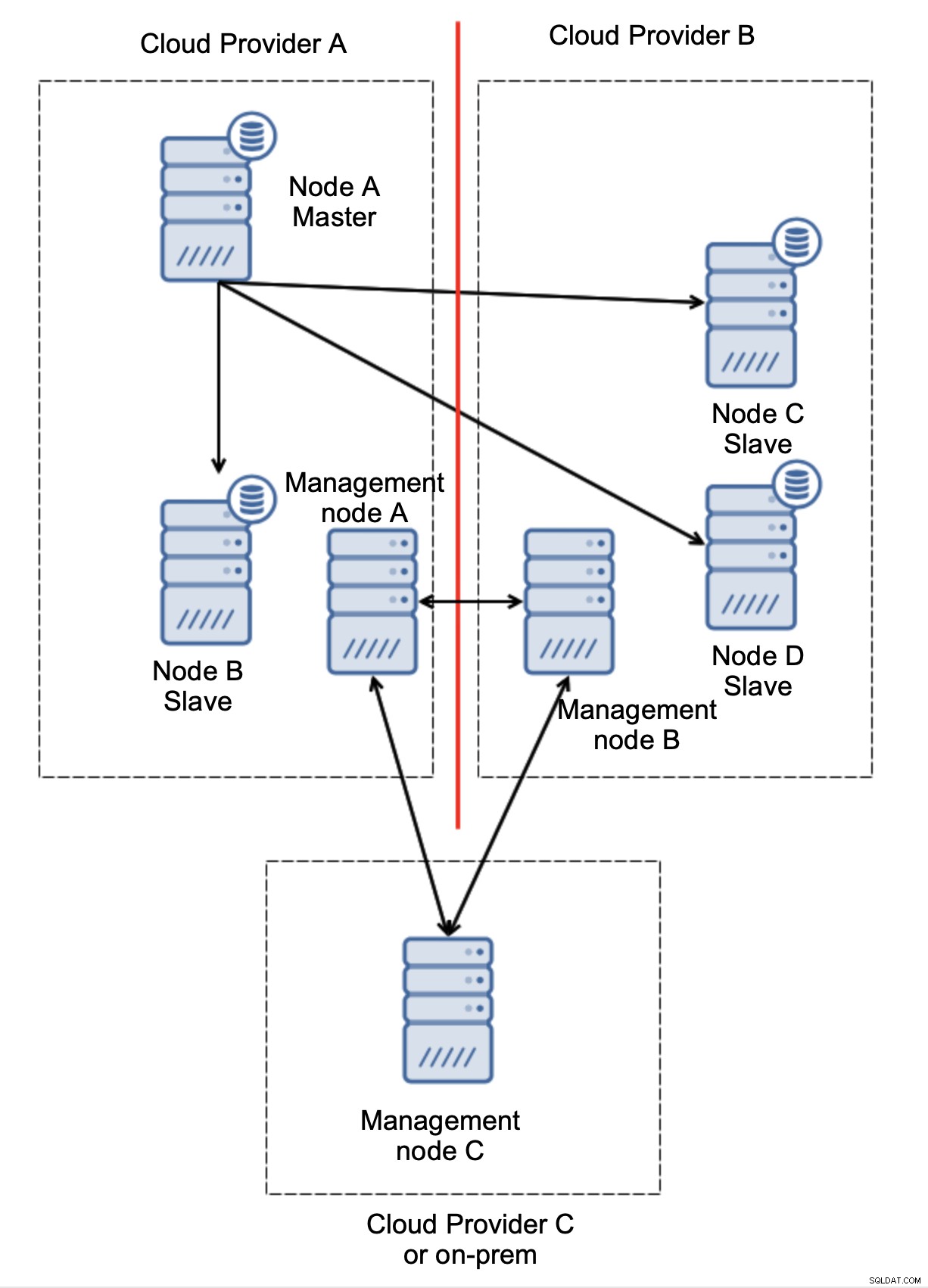
Hier kunnen we duidelijk zien dat het probleem alleen te maken heeft met de connectiviteit tussen providers A en B. Beheerknooppunt C fungeert als een relais en als gevolg daarvan mag er geen failover worden gestart. Aan de andere kant, als een datacenter volledig is afgesloten:

Het is ook vrij duidelijk wat er is gebeurd. Beheerknooppunt A meldt dat het de meerderheid van het cluster niet kan bereiken, terwijl beheerknooppunten B en C de meerderheid vormen. Het is mogelijk om hierop voort te bouwen en bijvoorbeeld scripts te schrijven die de topologie zullen beheren volgens de status van het beheerknooppunt. Dat zou kunnen betekenen dat de scripts die worden uitgevoerd in cloudprovider A zouden detecteren dat beheerknooppunt A niet de meerderheid vormt en dat ze alle databaseknooppunten zullen stoppen om ervoor te zorgen dat er geen schrijfbewerkingen plaatsvinden in de gepartitioneerde cloudprovider.
ClusterControl kan, indien geïmplementeerd in de modus voor hoge beschikbaarheid, worden behandeld als de beheerknooppunten die we in onze voorbeelden hebben gebruikt. Drie ClusterControl-knooppunten, bovenop het RAFT-protocol, kunnen u helpen bepalen of een bepaald netwerksegment is gepartitioneerd of niet.
Conclusie
We hopen dat deze blogpost je een idee geeft van split-brain-scenario's die zich kunnen voordoen bij MySQL-implementaties die zich over meerdere cloudplatforms uitstrekken.