Virtueel IP-adres is een IP-adres dat niet overeenkomt met een daadwerkelijke fysieke netwerkinterface. Het zweeft tussen meerdere netwerkinterfaces en slechts één actieve interface houdt het IP-adres vast voor fouttolerantie en mobiliteit. ClusterControl gebruikt Keepalive om virtuele IP-adresintegratie te bieden met database-load balancers om elk single point of failure (SPOF) op load balancer-niveau te elimineren.
In deze blogpost laten we u zien hoe ClusterControl het virtuele IP-adres configureert en wat u kunt verwachten wanneer failover of failback plaatsvindt. Het begrijpen van dit gedrag is van vitaal belang om eventuele serviceonderbrekingen tot een minimum te beperken en onderhoudswerkzaamheden die af en toe moeten worden uitgevoerd, te vergemakkelijken.
Vereisten
Er zijn enkele vereisten om Keepalive in uw netwerk te gebruiken:
- IP-protocol 112 (Virtual Router Redundancy Protocol - VRRP) moet worden ondersteund in het netwerk. Sommige netwerken schakelen ondersteuning voor VRRP uit, met name communicatie tussen VLAN's. Controleer dit bij de netwerkbeheerder.
- Als u multicast gebruikt, moet het netwerk multicast-verzoeken ondersteunen (gebruik ip a | grep -i multicast). Anders kunt u unicast gebruiken via unicast_src_ip en unicast_peer opties. Het gebruik van multicast is handig wanneer u een dynamische omgeving heeft, zoals een cloudomgeving, of wanneer IP-toewijzing wordt uitgevoerd via DHCP.
- Een set VRRP-instanties moet een unieke virtual_router_id gebruiken waarde, die niet met andere instanties kan worden gedeeld. Anders zul je valse pakketten zien en zal de master-backup-switch waarschijnlijk kapot gaan.
- Als je in een cloudomgeving zoals AWS draait, moet je waarschijnlijk een extern script gebruiken (hint:gebruik de optie "notify") om het virtuele IP-adres (elastische IP) los te koppelen en te associëren, zodat het wordt herkend en kan worden gerouteerd door de router.
Keepalived inzetten
Om Keepalived via ClusterControl te installeren, hebt u twee of meer load balancers nodig die zijn geïnstalleerd door of geïmporteerd in ClusterControl. Voor productiegebruik raden we ten zeerste aan dat de load balancer-software op een zelfstandige host wordt uitgevoerd en niet samen met uw databaseknooppunten.
Nadat u ten minste twee load balancers hebt beheerd door ClusterControl, om Keepalive te installeren en het virtuele IP-adres in te schakelen, gaat u naar ClusterControl -> kies het cluster -> Beheren -> Load Balancer -> Keepalive:
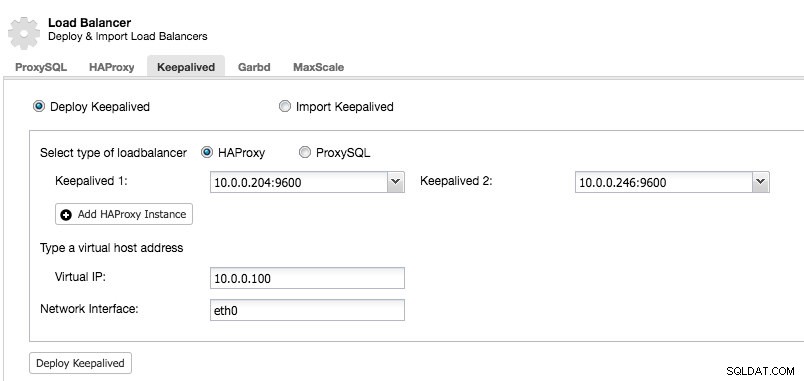
De meeste velden spreken voor zich. U kunt een nieuwe set Keepalived implementeren of bestaande Keepalive-instanties importeren. De belangrijke velden zijn onder meer het daadwerkelijke virtuele IP-adres en de netwerkinterface waar het virtuele IP-adres zal bestaan. Als de hosts twee verschillende interfacenamen gebruiken, specificeer dan de interfacenaam van de Keepalived 1-host en pas het configuratiebestand op Keepalived 2 later handmatig aan met een correcte interfacenaam.
VRRP-instantie
Op het moment van schrijven installeert ClusterControl v1.5.1 Keepalive v1.3.5 (afhankelijk van het hostbesturingssysteem) en het volgende is geconfigureerd voor de VRRP-instantie:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl configureert de VRRP-instantie om te communiceren via unicast. Met unicast moeten we alle unicast-peers van de andere Keepalived-knooppunten definiëren. Het is minder dynamisch, maar werkt meestal wel. Met multicast kunt u die regels (unicast_*) verwijderen en vertrouwen op het multicast-IP-adres voor hostdetectie en peering. Het is eenvoudiger, maar wordt vaak geblokkeerd door netwerkbeheerders.
Het volgende deel is het virtuele IP-adres. U kunt meerdere virtuele IP-adressen per VRRP-instantie opgeven, gescheiden door een nieuwe regel. Tegelijkertijd vereist taakverdeling in HAProxy/ProxySQL en Keepalive ook de mogelijkheid om te binden aan een IP-adres dat niet-lokaal is, wat betekent dat het niet is toegewezen aan een apparaat op het lokale systeem. Hierdoor kan een actieve load balancer-instantie zich binden aan een IP-adres dat niet lokaal is voor failover. Zo configureert ClusterControl ook net.ipv4.ip_nonlocal_bind=1 binnen /etc/sysctl.conf.
De volgende instructie is de track_script , waar u het script kunt specificeren voor het statuscontroleproces dat wordt uitgelegd in de volgende sectie.
Gezondheidscontroles
ClusterControl configureert Keepalive om gezondheidscontroles uit te voeren door de foutcode te onderzoeken die wordt geretourneerd door het track_script. In het Keepalived-configuratiebestand, dat zich standaard in /etc/keepalived/keepalived.conf bevindt, zou je zoiets als dit moeten zien:
track_script {
chk_proxysql
}Waar het chk_proxysql aanroept dat bevat:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}De opdracht "killall -0" retourneert exit-code 0 als er een proces met de naam "proxysql" op de host wordt uitgevoerd. Anders zou de instantie zichzelf moeten verlagen en een failover moeten starten, zoals uitgelegd in de volgende sectie. Houd er rekening mee dat Keepalived ook Linux Virtual Server (LVS)-componenten ondersteunt om gezondheidscontroles uit te voeren, waar het ook in staat is om TCP/IP-verbindingen te load balancing, vergelijkbaar met HAProxy, maar dat valt buiten het bestek van deze blogpost.
Failover simuleren
Voor VRRP-componenten gebruikt Keepalived het VRRP-protocol (IP-protocol 112) om te communiceren tussen VRRP-instanties. De hogere prioriteitswaarde van een MASTER betekent dat de master altijd het hogere recht heeft om het virtuele IP-adres te behouden, tenzij u de instantie configureert met "nopreempt". Laten we een voorbeeld gebruiken om de failover- en failback-stroom beter uit te leggen. Beschouw het volgende diagram:
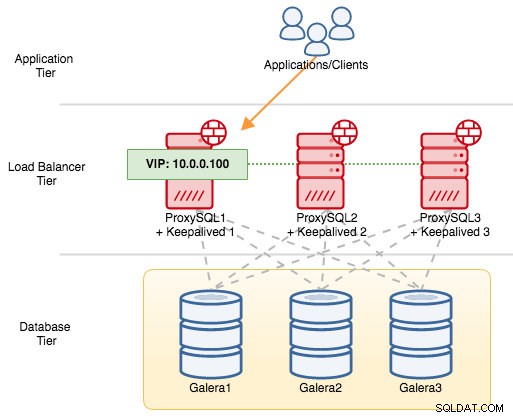
Er zijn drie ProxySQL-instanties voor drie MySQL Galera-knooppunten. Elke ProxySQL-host is geconfigureerd met Keepalive als MASTER met het volgende prioriteitsnummer:
- ProxySQL1 - prioriteit 101
- ProxySQL2 - prioriteit 100
- ProxySQL3 - prioriteit 99
Wanneer Keepalived als MASTER wordt gestart, adverteert het eerst het prioriteitsnummer aan de leden en associeert het zichzelf vervolgens met het virtuele IP-adres. In tegenstelling tot de BACKUP-instantie, zal het alleen de advertentie observeren en het virtuele IP-adres pas toewijzen nadat het heeft bevestigd dat het zichzelf kan verheffen tot een MASTER.
Houd er rekening mee dat als u het "proxysql"- of "haproxy"-proces handmatig beëindigt via het kill-commando, systemd process manager standaard zal proberen het proces te herstellen dat onfatsoenlijk is gestopt. Als u automatisch herstel van ClusterControl hebt ingeschakeld, zal ClusterControl altijd proberen het proces te starten, zelfs als u een schone afsluiting uitvoert via systemd (systemctl stop proxysql). Om de storing zo goed mogelijk te simuleren, raden we de gebruiker aan om de automatische herstelfunctie van ClusterControl uit te schakelen of gewoon de ProxySQL-server af te sluiten om de communicatie te verbreken.
Als we ProxySQL1 afsluiten, wordt het virtuele IP-adres overgedragen aan de volgende host die op dat moment een hogere prioriteit heeft (dat is ProxySQL2):
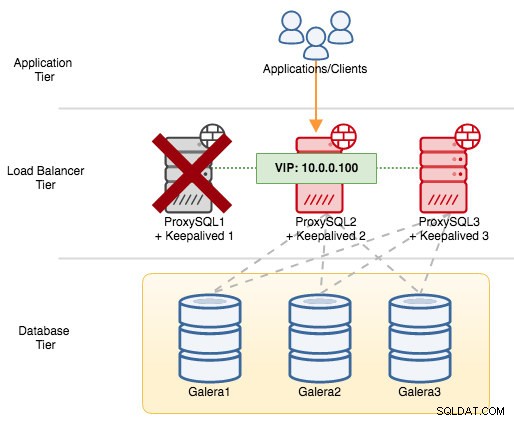
U zou het volgende zien in de syslog van de mislukte node:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.Op het secundaire knooppunt gebeurde het volgende:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.In dit geval duurde de failover ongeveer 3 seconden, met een maximale failovertijd van interval + advert_int . Achter de schermen is het database-eindpunt gewijzigd en wordt databaseverkeer omgeleid via ProxySQL2 zonder dat applicaties het merken.
Wanneer ProxySQL1 weer online komt, zal het een nieuwe MASTER-verkiezing forceren en het IP-adres overnemen vanwege een hogere prioriteit:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.Tegelijkertijd verlaagt ProxySQL2 zichzelf naar de BACKUP-status en verwijdert het het virtuele IP-adres van de netwerkinterface:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.Op dit moment is ProxySQL1 weer online en wordt het de actieve load balancer die de verbindingen van applicaties en clients bedient. VRRP zal normaal gesproken voorrang hebben op een server met een lagere prioriteit wanneer een server met een hogere prioriteit online komt. Als u wilt dat het IP-adres op ProxySQL2 blijft nadat ProxySQL1 weer online is, gebruikt u de optie "nopreempt". Hierdoor kan de machine met een lagere prioriteit de hoofdrol behouden, zelfs wanneer een machine met een hogere prioriteit weer online komt. Om dit te laten werken, moet de beginstatus van dit item echter BACKUP zijn. Anders ziet u de volgende regel:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTEROmdat ClusterControl standaard alle knooppunten als MASTER configureert, moet u de volgende configuratie-optie voor de respectieve VRRP-instantie dienovereenkomstig configureren:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Start het Keepalive-proces opnieuw om deze wijzigingen te laden. Het virtuele IP-adres wordt alleen gefailleerd naar ProxySQL1 of ProxySQL3 (afhankelijk van de prioriteit en welk knooppunt op dat moment beschikbaar is) als de statuscontrole op ProxySQL2 mislukt. In veel gevallen is het voldoende om Keepalive op twee hosts te draaien.