Het is nu bijna twee maanden geleden dat we SCUMM (Severalnines ClusterControl Unified Management and Monitoring) hebben uitgebracht. SCUMM gebruikt Prometheus als de onderliggende methode om tijdreeksgegevens te verzamelen van exporteurs die draaien op database-instances en load balancers. Deze blog laat u zien hoe u problemen kunt oplossen wanneer Prometheus-exporteurs niet actief zijn, of als de grafieken geen gegevens weergeven of "Geen gegevenspunten" weergeven.
Wat is Prometheus?
Prometheus is een open-source monitoringsysteem met een dimensionaal gegevensmodel, flexibele querytaal, efficiënte tijdreeksdatabase en moderne waarschuwingsaanpak. Het is een monitoringplatform dat metrische gegevens verzamelt van bewaakte doelen door metrische HTTP-eindpunten op deze doelen te schrapen. Het biedt dimensionale gegevens, krachtige zoekopdrachten, geweldige visualisatie, efficiënte opslag, eenvoudige bediening, nauwkeurige waarschuwingen, veel clientbibliotheken en veel integraties.
Prometheus in actie voor SCUMM Dashboards
Prometheus verzamelt metrische gegevens van exporteurs, waarbij elke exporteur op een database of load balancer-host draait. In het onderstaande diagram ziet u hoe deze exporteurs zijn gekoppeld aan de server die het Prometheus-proces host. Het laat zien dat Prometheus op het ClusterControl-knooppunt draait, waar het ook process_exporter en node_exporter uitvoert.
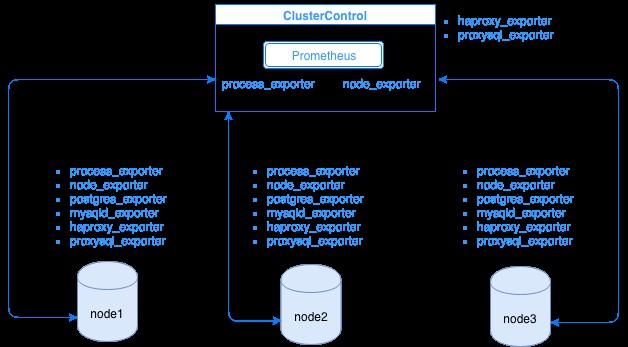
Het diagram laat zien dat Prometheus draait op de ClusterControl-host en exporters process_exporter en node_exporter zijn ook actief om metrische gegevens van zijn eigen knooppunt te verzamelen. Optioneel kunt u uw ClusterControl-host ook als doel maken waarin u HAProxy of ProxySQL kunt instellen.
Voor de clusterknooppunten hierboven (knooppunt1, knooppunt2 en knooppunt3) kan mysqld_exporter of postgres_exporter actief zijn, dit zijn de agenten die gegevens intern in dat knooppunt schrapen en doorgeven aan de Prometheus-server en deze opslaan in zijn eigen gegevensopslag. Je kunt de fysieke gegevens vinden via /var/lib/prometheus/data binnen de host waar Prometheus is ingesteld.
Wanneer u Prometheus instelt, bijvoorbeeld in de ClusterControl-host, moeten de volgende poorten zijn geopend. Zie hieronder:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusOp basis van de output heb ik ProxySQL ook draaien op de host testccnode waarin ClusterControl wordt gehost.
Veelvoorkomende problemen met SCUMM-dashboards met Prometheus
Als Dashboards zijn ingeschakeld, installeert en implementeert ClusterControl binaire bestanden en exportprogramma's zoals node_exporter, process_exporter, mysqld_exporter, postgres_exporter en daemon. Dit zijn de algemene sets pakketten voor de databaseknooppunten. Wanneer deze zijn ingesteld en geïnstalleerd, worden de volgende daemon-commando's gestart en uitgevoerd zoals hieronder te zien is:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusVoor een PostgreSQL-knooppunt,
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterHet heeft dezelfde exportprogramma's als voor een MySQL-knooppunt, maar verschilt alleen op de postgres_exporter omdat dit een PostgreSQL-databaseknooppunt is.
Wanneer een node echter last heeft van een stroomonderbreking, een systeemcrash of het opnieuw opstarten van het systeem, zullen deze exportprogramma's stoppen met werken. Prometheus zal melden dat een exporteur down is. ClusterControl bemonstert Prometheus zelf en vraagt naar de exportstatussen. Het handelt dus op basis van deze informatie en zal de exporteur opnieuw opstarten als deze niet beschikbaar is.
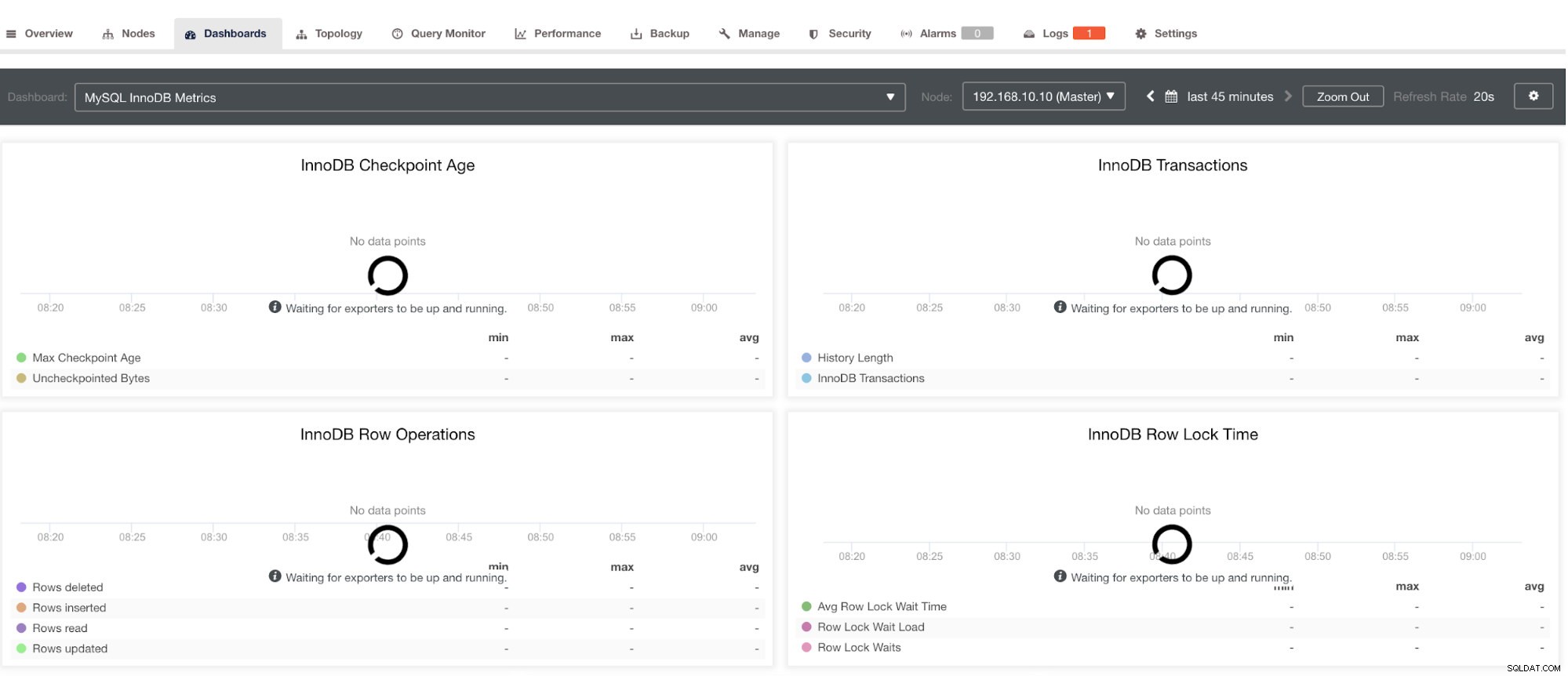
Houd er echter rekening mee dat exportprogramma's die niet via ClusterControl zijn geïnstalleerd, niet opnieuw worden gestart na een crash. De reden is dat ze niet worden gecontroleerd door systemd of een daemon die fungeert als een veiligheidsscript dat een proces zou herstarten bij een crash of een abnormale afsluiting. Daarom laat de onderstaande schermafbeelding zien hoe het eruit ziet als de exporteurs niet actief zijn. Zie hieronder:
en in PostgreSQL Dashboard, hetzelfde laadpictogram met het label "Geen gegevenspunten" in de grafiek hebben. Zie hieronder:
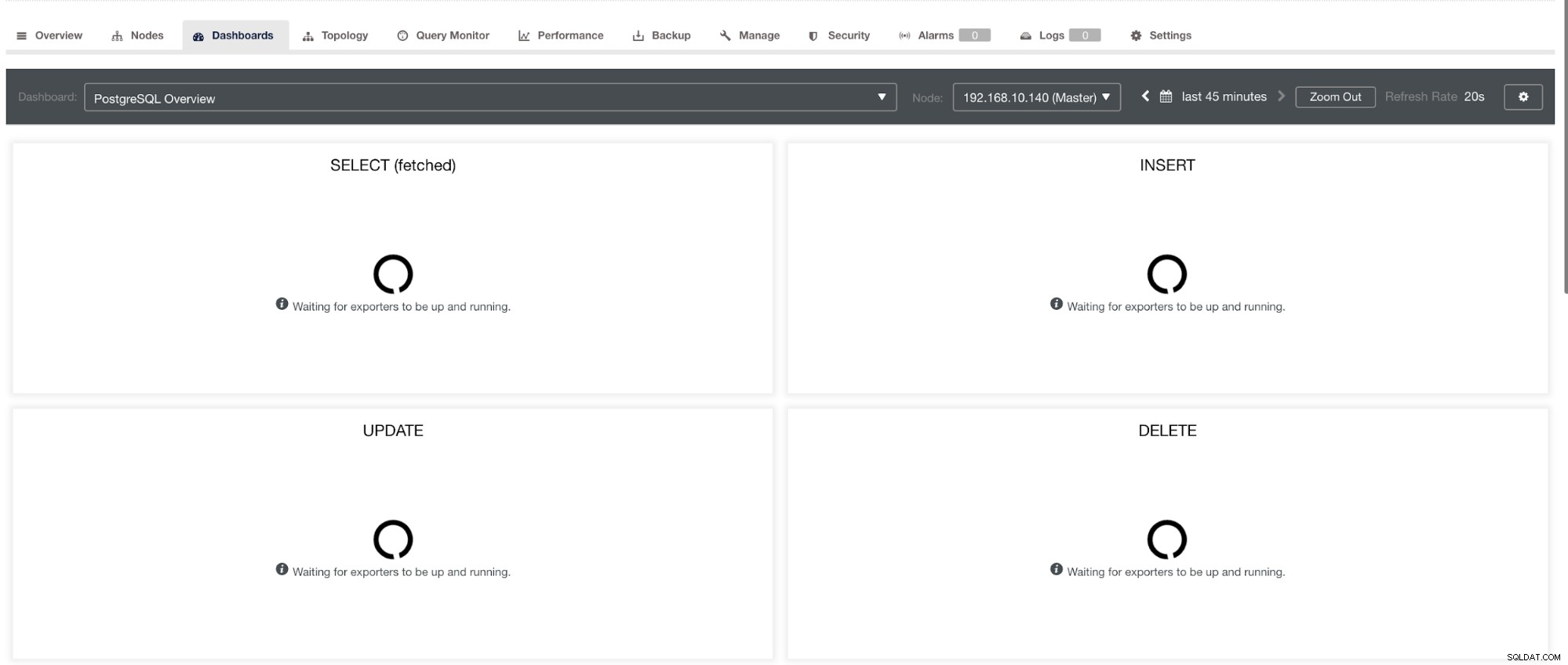
Daarom kunnen deze problemen worden opgelost met behulp van verschillende technieken die in de volgende secties zullen volgen.
Problemen oplossen met Prometheus
Prometheus-agenten, bekend als de exporteurs, gebruiken de volgende poorten:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter), en de eigen 9090 die eigendom is van een prometheus Verwerken. Dit zijn de poorten voor deze agents die door ClusterControl worden gebruikt.
Om te beginnen met het oplossen van problemen met het SCUMM Dashboard, kunt u beginnen met het controleren van de geopende poorten vanaf het databaseknooppunt. U kunt de onderstaande lijsten volgen:
-
Controleer of de poorten open zijn
bijv.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporHet kan zijn dat de poorten niet open zijn vanwege een firewall (zoals iptables of firewalld) die het openen van de poort blokkeert of omdat de procesdaemon zelf niet actief is.
-
Gebruik curl van de hostmonitor en controleer of de poort bereikbaar en open is.
bijv.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0In het ideale geval vond ik deze aanpak praktisch haalbaar voor mij omdat ik gemakkelijk grep en debuggen vanaf de terminal kan.
-
Waarom niet de webinterface gebruiken?
-
Prometheus onthult poort 9090 die door ClusterControl wordt gebruikt in onze SCUMM-dashboards. Afgezien hiervan kunnen de poorten die de exporteurs blootleggen ook worden gebruikt om problemen op te lossen en de beschikbare metrieknamen te bepalen met behulp van PromQL. Op de server waarop de Prometheus draait, kunt u https://
:9090/targets bezoeken . De onderstaande schermafbeelding toont het in actie: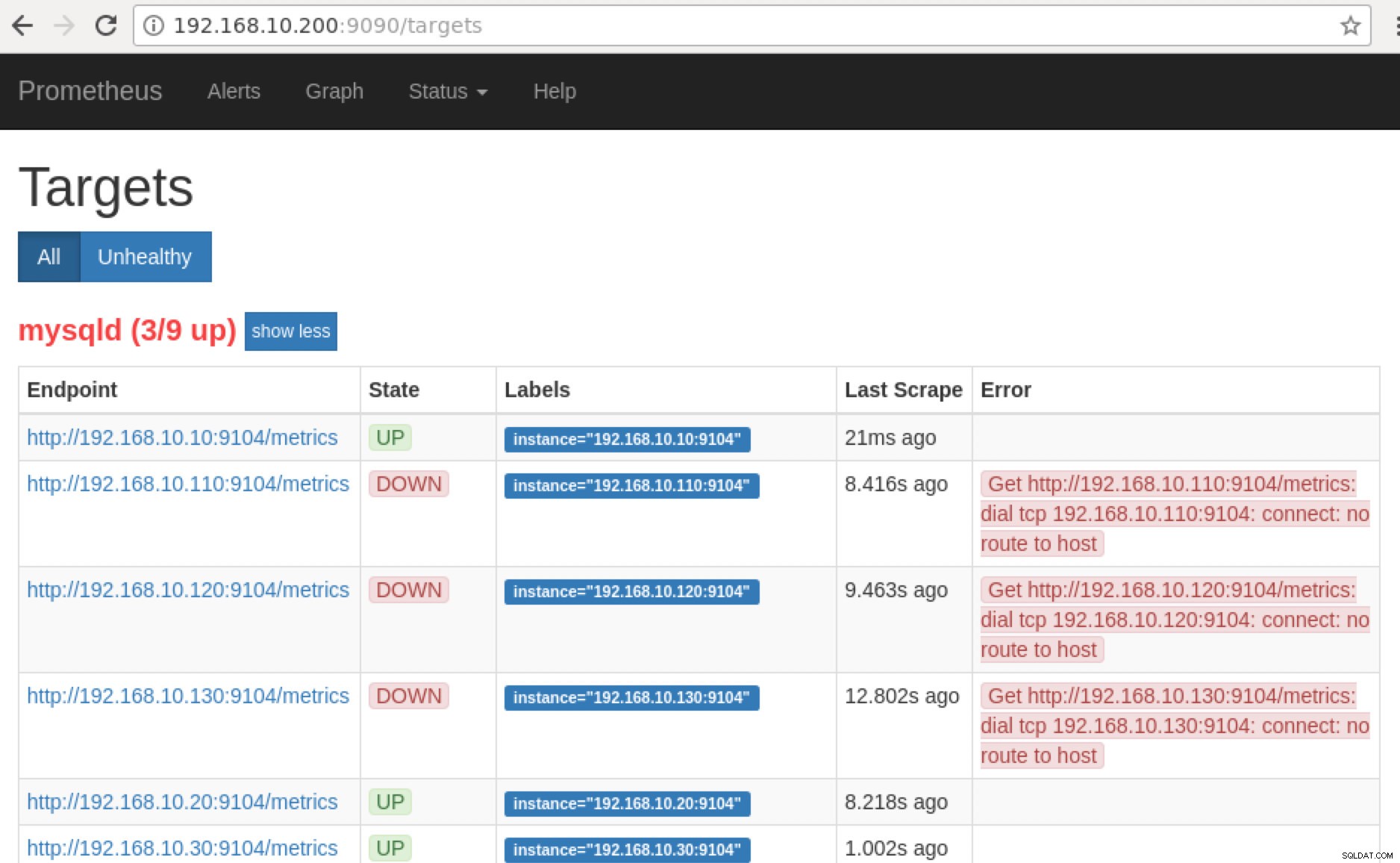
en door op "Eindpunten" te klikken, kunt u de statistieken verifiëren, evenals de onderstaande schermafbeelding:
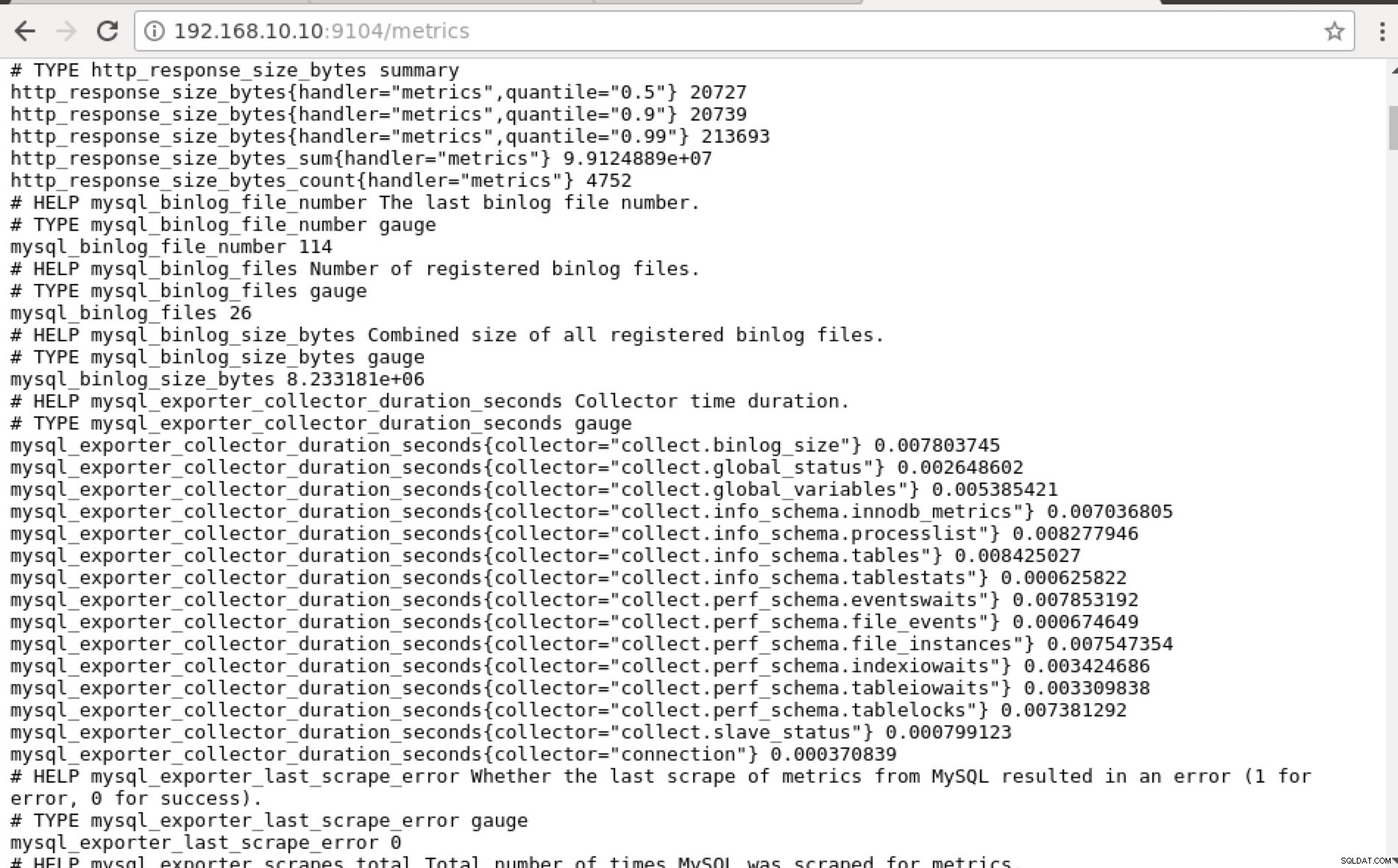
In plaats van het IP-adres te gebruiken, kunt u dit ook lokaal controleren via localhost op dat specifieke knooppunt, zoals een bezoek aan https://localhost:9104/metrics in een web-UI-interface of met behulp van cURL.
Als we nu teruggaan naar de "Doelen ” pagina, kunt u de lijst met knooppunten zien waar er een probleem kan zijn met de poort. De redenen die dit kunnen veroorzaken staan hieronder vermeld:
- Server is niet beschikbaar
- Netwerk is onbereikbaar of poorten niet geopend vanwege een actieve firewall
- De daemon draait niet waar de
_exporter is niet aan het rennen. Mysqld_exporter is bijvoorbeeld niet actief.
-
Wanneer deze exportprogramma's actief zijn, kunt u het proces starten en uitvoeren met behulp van daemon opdracht. Je kunt verwijzen naar de beschikbare lopende processen die ik in het bovenstaande voorbeeld had gebruikt, of die ik in het vorige gedeelte van deze blog heb genoemd.
Hoe zit het met die grafieken met 'geen gegevenspunten' in mijn dashboard?
SCUMM Dashboards komt met een algemeen gebruiksscenario dat vaak wordt gebruikt door MySQL. Er zijn echter enkele variabelen wanneer het aanroepen van dergelijke metrische gegevens mogelijk niet beschikbaar is in een bepaalde MySQL-versie of een MySQL-leverancier, zoals MariaDB of Percona Server.
Ik zal hieronder een voorbeeld laten zien:
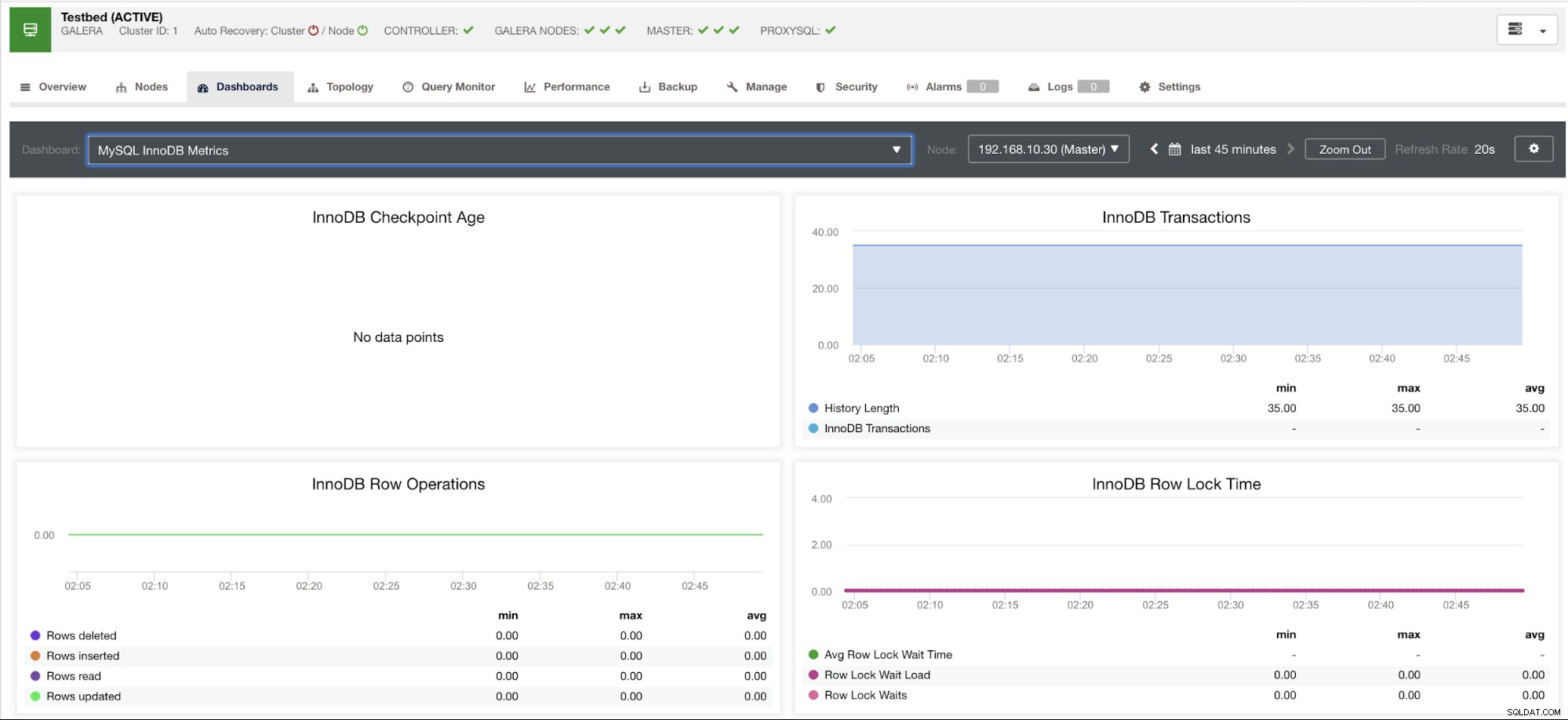
Deze grafiek is gemaakt op een databaseserver die draait op een MariaDB-server met versie 10.3.9-MariaDB-log met wsrep_patch_version of wsrep_25.23 instance. Nu is de vraag, waarom worden er geen gegevenspunten geladen? Welnu, toen ik het knooppunt opvroeg naar een leeftijdsstatus van het controlepunt, onthult het dat het leeg is of dat er geen variabele gevonden is. Zie hieronder:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Ik heb geen idee waarom MariaDB deze variabele niet heeft (laat het ons weten in het opmerkingengedeelte van deze blog als je het antwoord hebt). Dit in tegenstelling tot een Percona XtraDB Cluster Server waar de variabele Innodb_checkpoint_max_age wel bestaat. Zie hieronder:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)Wat dit echter betekent, is dat er grafieken kunnen zijn waarvoor geen gegevenspunten zijn verzameld, omdat er geen gegevens worden verzameld op die specifieke metriek toen een Prometheus-query werd uitgevoerd.
Een grafiek die geen datapunten heeft, betekent echter niet dat uw huidige versie van MySQL of zijn variant deze niet ondersteunt. Er zijn bijvoorbeeld bepaalde grafieken die bepaalde variabelen vereisen die correct moeten worden ingesteld of ingeschakeld.
Het volgende gedeelte laat zien wat deze grafieken zijn.
Index Conditie Pushdown (ICP) Grafiek

Deze grafiek is genoemd in mijn vorige blog. Het is gebaseerd op een algemene MySQL-variabele met de naam innodb_monitor_enable. Deze variabele is dynamisch, dus u kunt deze instellen zonder een harde herstart van uw MySQL-database. Het vereist ook innodb_monitor_enable =module_icp of je kunt deze globale variabele instellen op innodb_monitor_enable =all. Om dergelijke gevallen en verwarring over de reden waarom een dergelijke grafiek geen gegevenspunten weergeeft te voorkomen, moet u doorgaans alles behalve voorzichtig gebruiken. Er kan een zekere overhead zijn wanneer deze variabele is ingeschakeld en op alles is ingesteld.
MySQL-prestatieschemagrafieken
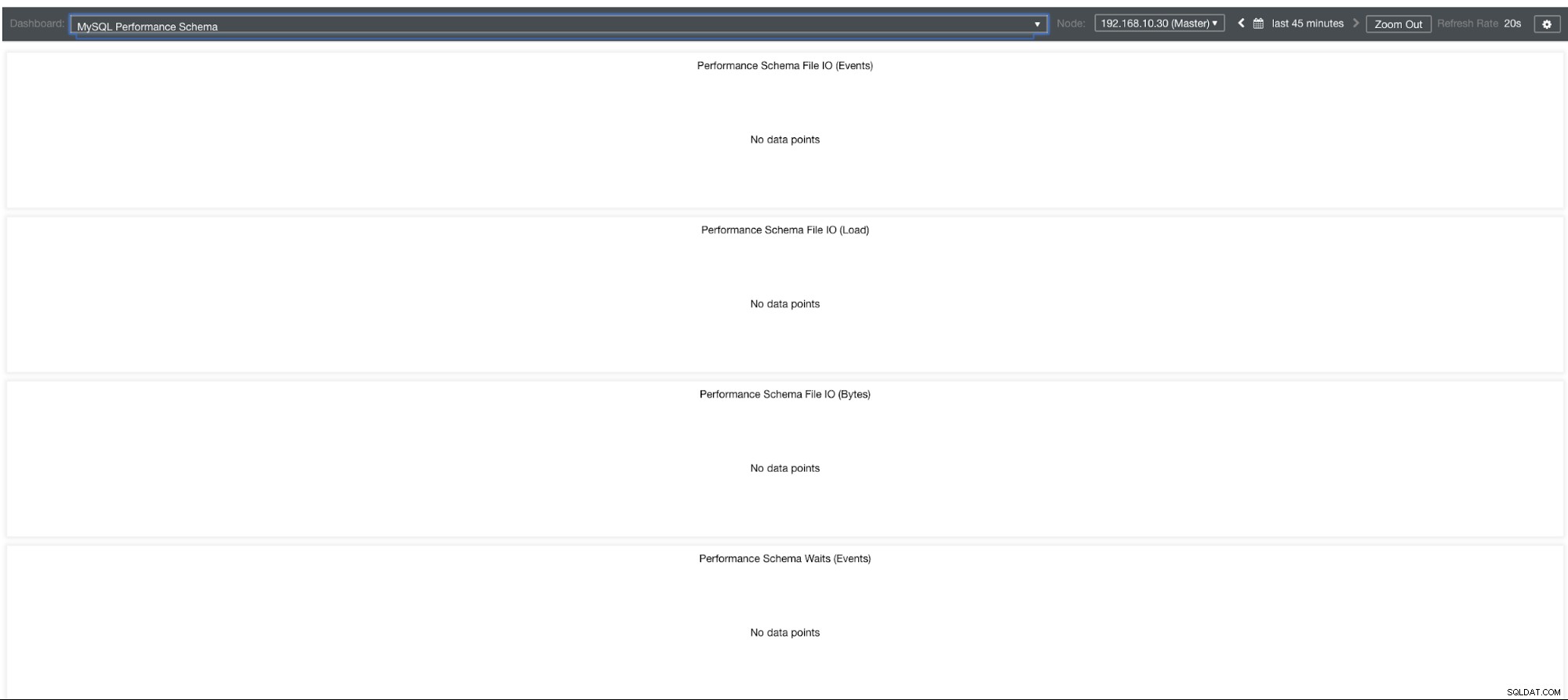
Dus waarom tonen deze grafieken "Geen gegevenspunten"? Wanneer u een cluster maakt met ClusterControl met behulp van onze sjablonen, definieert het standaard performance_schema-variabelen. De onderstaande variabelen zijn bijvoorbeeld ingesteld:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Als performance_schema =UIT, dan is dat de reden waarom de gerelateerde grafieken "Geen gegevenspunten" zouden weergeven.
Maar ik heb performance_schema ingeschakeld, waarom zijn andere grafieken nog steeds een probleem?
Welnu, er zijn nog steeds grafieken waarvoor meerdere variabelen moeten worden ingesteld. Dit is al behandeld in onze vorige blog. Je moet dus innodb_monitor_enable =all en userstat=1 instellen. Het resultaat ziet er als volgt uit:
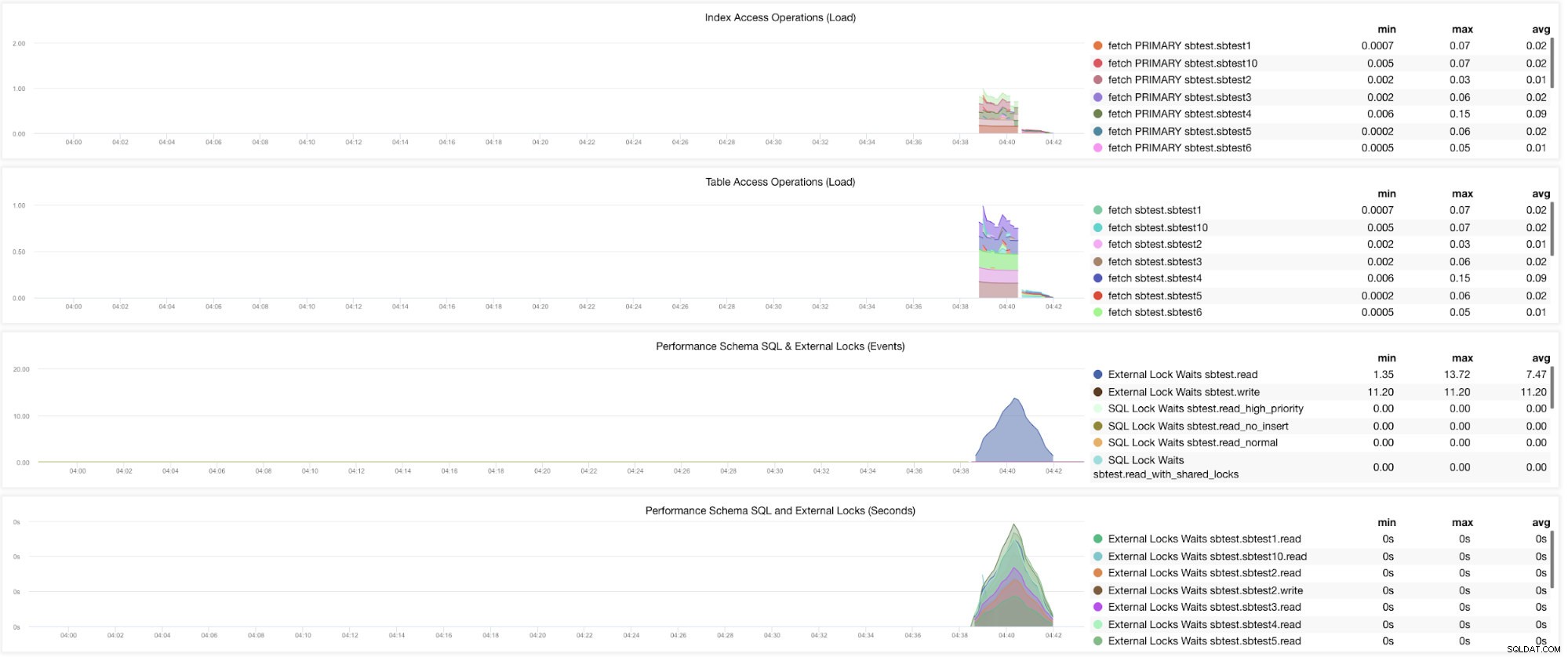
Ik merk echter dat in de versie van MariaDB 10.3 (met name 10.3.11), het instellen van performance_schema=ON de metrieken zal vullen die nodig zijn voor het MySQL Performance Schema Dashboard. Dit is een groot voordeel omdat innodb_monitor_enable=ON niet hoeft te worden ingesteld, wat extra overhead op de databaseserver zou veroorzaken.
Geavanceerde probleemoplossing
Is er een probleemoplossing vooraf die ik kan aanbevelen? Ja dat is er! U hebt echter op zijn minst enige JavaScript-vaardigheden nodig. Aangezien SCUMM Dashboards die Prometheus gebruiken afhankelijk is van highcharts, kan de manier waarop de statistieken die worden gebruikt voor PromQL-verzoeken worden bepaald via het app.js-script dat hieronder wordt weergegeven:
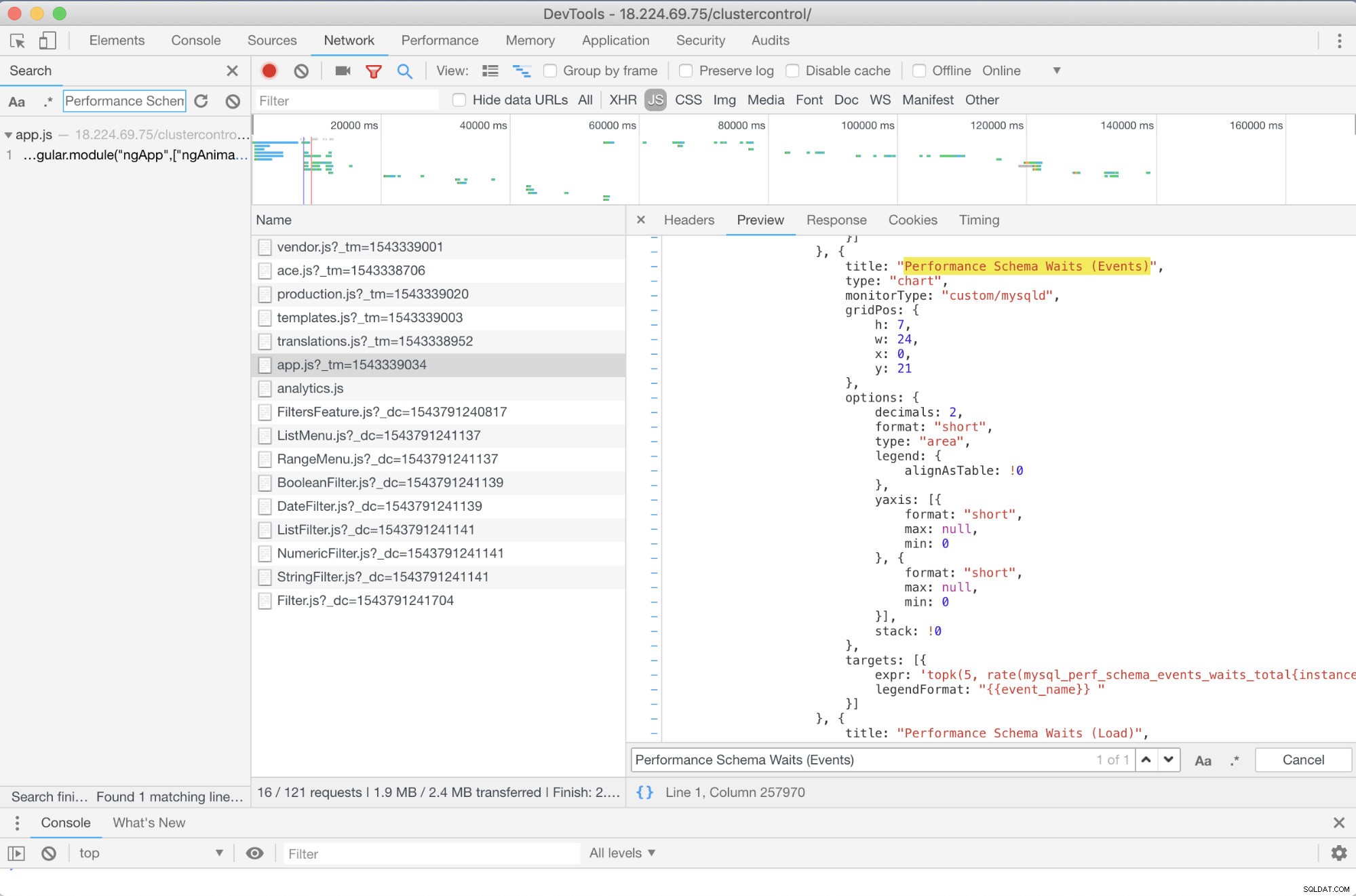
Dus in dit geval gebruik ik DevTools van Google Chrome en probeerde ik te zoeken naar Performance Schema Waits (Events) . Hoe dit kan helpen? Nou, als je naar de doelen kijkt, zie je:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
Nu kunt u de gevraagde statistieken gebruiken, namelijk mysql_perf_schema_events_waits_total. U kunt dat bijvoorbeeld controleren door https://
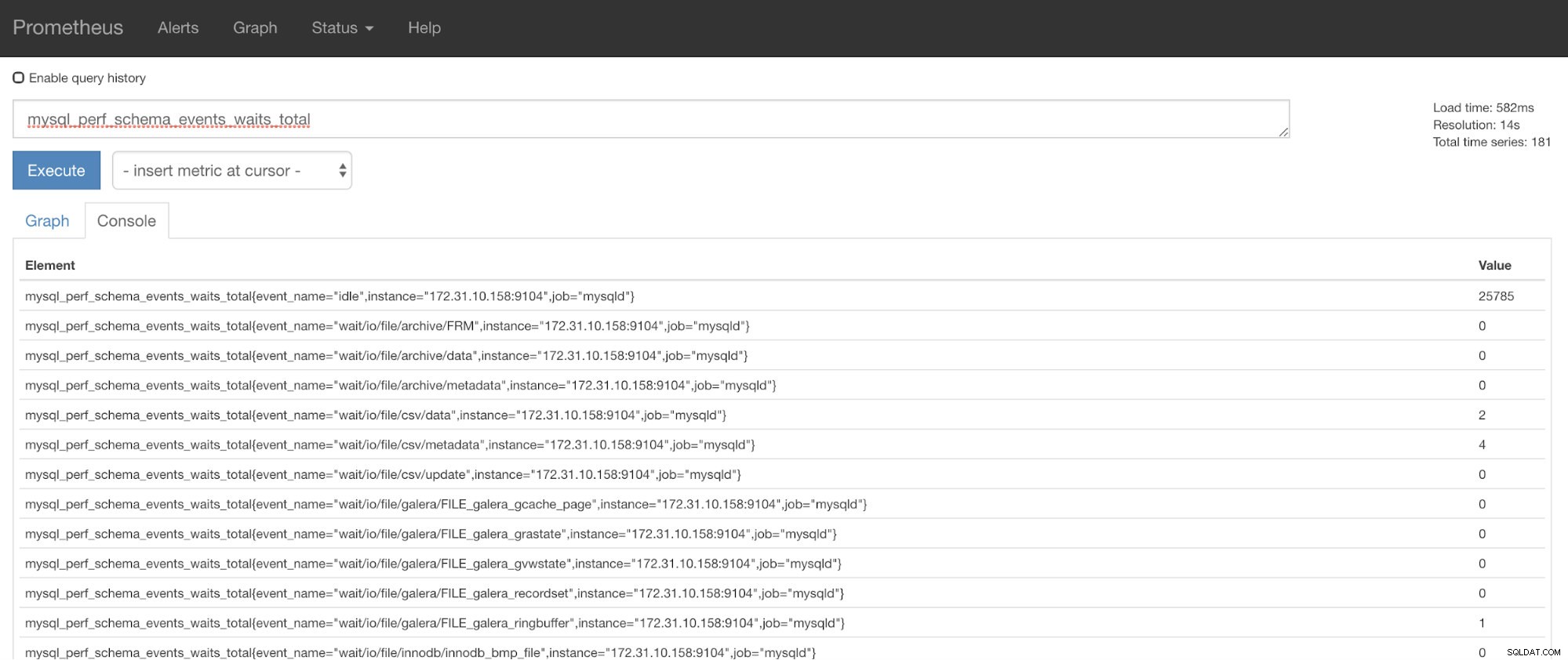
ClusterControl Auto-Recovery komt te hulp!
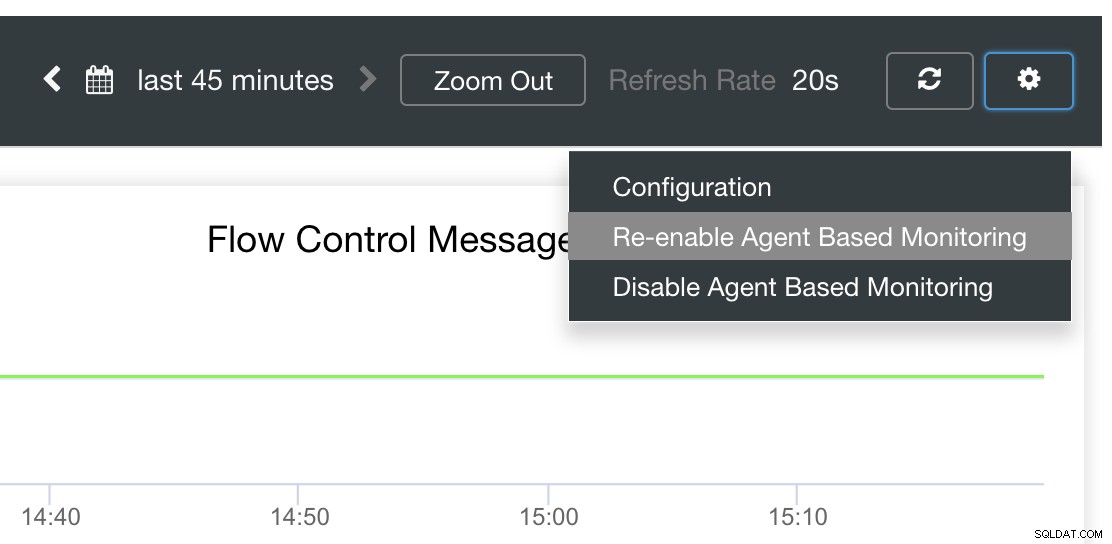
Ten slotte is de belangrijkste vraag:is er een gemakkelijke manier om mislukte exporteurs opnieuw te starten? Ja! We hebben eerder vermeld dat ClusterControl de status van de export in de gaten houdt en indien nodig opnieuw start. Als u merkt dat SCUMM-dashboards de grafieken niet normaal laden, zorg er dan voor dat Auto Recovery is ingeschakeld. Zie de afbeelding hieronder:

Als dit is ingeschakeld, zorgt dit ervoor dat de
Het is ook mogelijk om de exporteurs opnieuw te installeren of opnieuw te configureren.
Conclusie
In deze blog zagen we hoe ClusterControl Prometheus gebruikt om SCUMM Dashboards aan te bieden. Het biedt een krachtige reeks functies, van bewakingsgegevens met hoge resolutie en uitgebreide grafieken. Je hebt geleerd dat je met PromQL onze SCUMM-dashboards kunt bepalen en problemen kunt oplossen, waarmee je tijdreeksgegevens in realtime kunt aggregeren. U kunt ook grafieken genereren of bekijken via Console voor alle statistieken die zijn verzameld.
Je hebt ook geleerd hoe je onze SCUMM-dashboards kunt debuggen, vooral als er geen gegevenspunten worden verzameld.
Als je vragen hebt, voeg dan je opmerkingen toe of laat het ons weten via onze communityforums.