Je hebt misschien gehoord van de term "failover" in de context van MySQL-replicatie. Misschien vroeg je je af wat het is als je je avontuur met databases begint. Misschien weet je wat het is, maar weet je niet zeker wat de mogelijke problemen zijn en hoe ze kunnen worden opgelost?
In deze blogpost proberen we je een inleiding te geven over het afhandelen van failover in MySQL &MariaDB.
We bespreken wat de failover is, waarom deze onvermijdelijk is, wat het verschil is tussen failover en switchover. We bespreken het failover-proces in de meest generieke vorm. We zullen ook een beetje ingaan op verschillende problemen waarmee u te maken krijgt in verband met het failover-proces.
Wat betekent 'failover'?
MySQL-replicatie is een verzameling knooppunten, die elk één rol tegelijk kunnen vervullen. Het kan een meester of een replica worden. Er is slechts één hoofdknooppunt tegelijk. Dit knooppunt ontvangt schrijfverkeer en repliceert schrijfacties naar zijn replica's.
Zoals u zich kunt voorstellen, is het hoofdknooppunt vrij belangrijk omdat het een enkel toegangspunt is voor gegevens in het replicatiecluster. Wat zou er gebeuren als het was mislukt en niet meer beschikbaar zou zijn?
Dit is een vrij ernstige voorwaarde voor een replicatiecluster. Het kan op een bepaald moment geen schrijfacties accepteren. Zoals je mag verwachten, zal een van de replica's de taken van de master moeten overnemen en schrijfbewerkingen gaan accepteren. De rest van de replicatietopologie moet mogelijk ook worden gewijzigd - overblijvende replica's moeten hun master wijzigen van het oude, mislukte knooppunt naar het nieuw gekozen knooppunt. Dit proces waarbij een replica wordt "gepromoot" om een master te worden nadat de oude master is mislukt, wordt "failover" genoemd.
Aan de andere kant vindt "omschakeling" plaats wanneer de gebruiker de promotie van de replica activeert. Een nieuwe master wordt gepromoveerd van een replica die door de gebruiker is aangewezen en de oude master wordt doorgaans een replica naar de nieuwe master.
Het belangrijkste verschil tussen “failover” en “switchover” is de toestand van de oude master. Wanneer een failover wordt uitgevoerd, is de oude master op de een of andere manier niet bereikbaar. Het kan zijn gecrasht, het kan een netwerkpartitionering hebben ondergaan. Het kan op een bepaald moment niet worden gebruikt en de staat ervan is meestal onbekend.
Aan de andere kant, wanneer een omschakeling wordt uitgevoerd, is de oude meester springlevend. Dit heeft ernstige gevolgen. Als een master onbereikbaar is, kan dit betekenen dat een deel van de gegevens nog niet naar de slaves is verzonden (tenzij semi-synchrone replicatie is gebruikt). Sommige gegevens zijn mogelijk beschadigd of gedeeltelijk verzonden.
Er zijn mechanismen om te voorkomen dat dergelijke corrupties op slaves worden verspreid, maar het punt is dat sommige gegevens tijdens het proces verloren kunnen gaan. Aan de andere kant, tijdens het uitvoeren van een omschakeling, is de oude master beschikbaar en blijft de gegevensconsistentie behouden.
Failover-proces
Laten we wat tijd besteden aan het bespreken hoe het failover-proces er precies uitziet.
Master-crash gedetecteerd
Om te beginnen moet een master crashen voordat de failover wordt uitgevoerd. Zodra het niet beschikbaar is, wordt een failover geactiveerd. Tot nu toe lijkt het eenvoudig, maar de waarheid is dat we ons al op gladde grond bevinden.
Allereerst, hoe wordt de gezondheid van de meester getest? Wordt het getest vanaf één locatie of worden tests verspreid? Probeert de failoverbeheersoftware alleen verbinding te maken met de master of voert het geavanceerdere verificaties uit voordat de masterfout wordt verklaard?
Laten we ons de volgende topologie eens voorstellen:
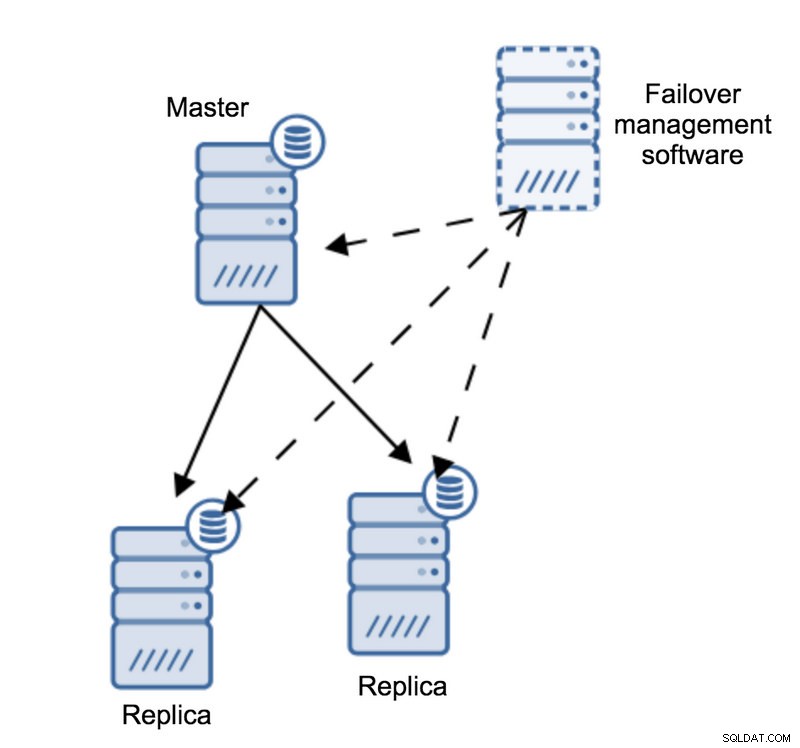
We hebben een master en twee replica's. We hebben ook software voor failoverbeheer op een externe host. Wat zou er gebeuren als een netwerkverbinding tussen de host met failover-software en de master mislukt?
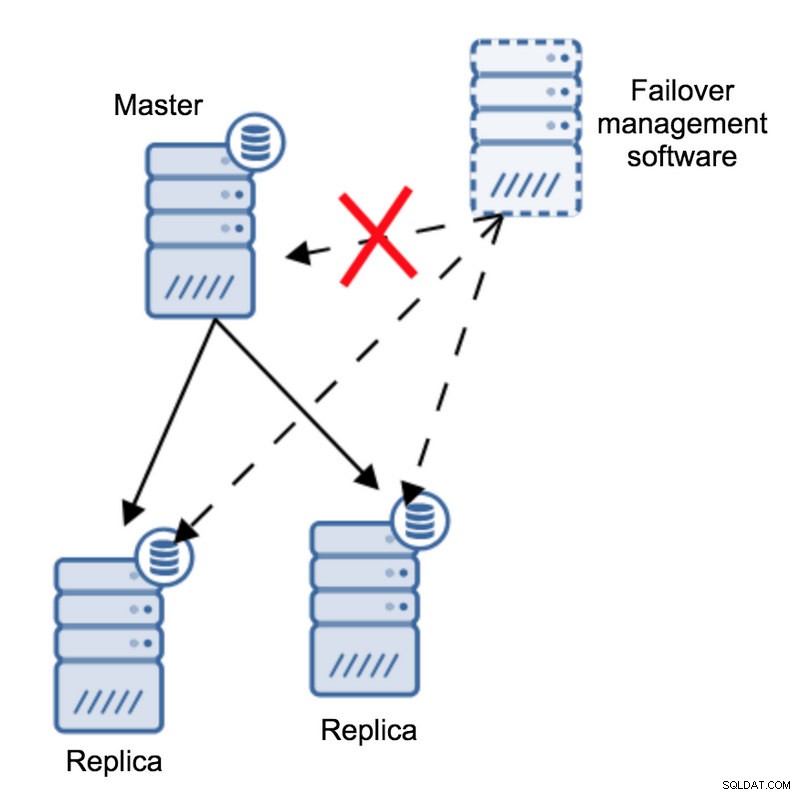
Volgens de failover-beheersoftware is de master gecrasht - er is geen verbinding mee. Toch werkt de replicatie zelf prima. Wat hier zou moeten gebeuren, is dat de failover-beheersoftware zou proberen verbinding te maken met replica's en te kijken wat hun standpunt is.
Klagen ze over een gebroken replicatie of repliceren ze graag?
De zaken kunnen nog complexer worden. Wat als we een proxy (of een set proxy's) zouden toevoegen? Het wordt gebruikt om verkeer te routeren - schrijft naar master en leest naar replica's. Wat als een proxy geen toegang heeft tot de master? Wat als geen van de proxy's toegang heeft tot de master?
Dit betekent dat de applicatie onder die omstandigheden niet kan functioneren. Moet de failover (eigenlijk zou het meer een omschakeling zijn omdat de master technisch gezien in leven is) worden geactiveerd?
Technisch gezien leeft de master, maar deze kan niet door de applicatie worden gebruikt. Hier moet de bedrijfslogica binnenkomen en moet er een beslissing worden genomen.
Voorkomen dat de oude meester gaat rennen
Het maakt niet uit hoe en waarom, als er een beslissing wordt genomen om een van de replica's te promoten om een nieuwe master te worden, moet de oude master worden gestopt en idealiter niet opnieuw kunnen beginnen.
Hoe dit kan worden bereikt, hangt af van de details van de specifieke omgeving; daarom wordt dit deel van het failoverproces gewoonlijk versterkt door externe scripts die via verschillende hooks in het failoverproces zijn geïntegreerd.
Die scripts kunnen worden ontworpen om tools te gebruiken die beschikbaar zijn in de specifieke omgeving om de oude master te stoppen. Het kan een CLI- of API-aanroep zijn die een VM stopt; het kan shell-code zijn die commando's uitvoert via een soort "lights out management" -apparaat; het kan een script zijn dat SNMP-traps naar de stroomdistributie-eenheid stuurt die de stopcontacten uitschakelen die de oude meester gebruikt (zonder elektrische stroom kunnen we er zeker van zijn dat het niet opnieuw zal starten).
Als failoverbeheersoftware een onderdeel is van een complexer product, dat ook het herstel van knooppunten afhandelt (zoals het geval is voor ClusterControl), kan de oude master worden gemarkeerd als uitgesloten van de herstelroutines.
Je vraagt je misschien af waarom het zo belangrijk is om te voorkomen dat de oude meester weer beschikbaar komt?
Het belangrijkste probleem is dat in replicatie-instellingen slechts één knooppunt kan worden gebruikt voor schrijfbewerkingen. Doorgaans zorgt u ervoor dat door een read_only (en super_read_only, indien van toepassing) variabele op alle replica's in te schakelen en deze alleen op de master uitgeschakeld te houden.
Zodra een nieuwe master is gepromoveerd, is alleen-lezen uitgeschakeld. Het probleem is dat, als de oude master niet beschikbaar is, we deze niet terug kunnen zetten naar read_only=1. Als MySQL of een host is gecrasht, is dit niet zo'n probleem, aangezien het een goede gewoonte is om my.cnf met die instelling te configureren, zodat zodra MySQL eenmaal is gestart, het altijd in de alleen-lezen modus start.
Het probleem wordt weergegeven wanneer het geen crash is, maar een netwerkprobleem. De oude master is nog steeds actief met alleen-lezen uitgeschakeld, het is gewoon niet beschikbaar. Wanneer netwerken convergeren, krijgt u twee beschrijfbare knooppunten. Dit kan al dan niet een probleem zijn. Sommige proxy's gebruiken de instelling alleen-lezen als een indicator of een knoop punt een master of een replica is. Twee masters die op dat moment verschijnen, kunnen een enorm probleem opleveren, aangezien gegevens naar beide hosts worden geschreven, maar replica's krijgen slechts de helft van het schrijfverkeer (het deel dat de nieuwe master raakt).
Soms gaat het om hardgecodeerde instellingen in sommige van de scripts die zijn geconfigureerd om alleen verbinding te maken met een bepaalde host. Normaal gesproken zouden ze mislukken en zou iemand merken dat de master is veranderd.
Nu de oude master beschikbaar is, zullen ze er graag verbinding mee maken en zullen er gegevensverschillen ontstaan. Zoals je kunt zien, is ervoor zorgen dat de oude master niet start een item met hoge prioriteit.
Beslis over een Master Kandidaat
De oude meester is neer en hij zal niet terugkeren uit zijn graf, nu is het tijd om te beslissen welke gastheer we als nieuwe meester moeten gebruiken. Meestal is er meer dan één replica om uit te kiezen, dus er moet een beslissing worden genomen. Er zijn veel redenen waarom de ene replica boven de andere kan worden gekozen, daarom moeten er controles worden uitgevoerd.
Witte lijsten en zwarte lijsten
Om te beginnen kan een team dat databases beheert, redenen hebben om de ene replica boven de andere te verkiezen bij het kiezen van een masterkandidaat. Misschien gebruikt het zwakkere hardware of heeft het een bepaalde taak toegewezen gekregen (de replica voert back-up, analytische query's uit, ontwikkelaars hebben er toegang toe en voeren aangepaste, handgemaakte query's uit). Misschien is het een testreplica waarbij een nieuwe versie acceptatietests ondergaat voordat de upgrade wordt uitgevoerd. De meeste software voor failoverbeheer ondersteunt witte en zwarte lijsten, die kunnen worden gebruikt om nauwkeurig te definiëren welke replica's wel of niet als masterkandidaten moeten worden gebruikt.
Semi-synchrone replicatie
Een replicatie-instelling kan een combinatie zijn van asynchrone en semi-synchrone replica's. Er is een enorm verschil tussen hen - een semi-synchrone replica bevat gegarandeerd alle gebeurtenissen van de master. Een asynchrone replica heeft mogelijk niet alle gegevens ontvangen, dus als u er niet naar toegaat, kan dit leiden tot gegevensverlies. We zien liever dat semi-synchrone replica's worden gepromoot.
Replicatievertraging
Hoewel een semi-synchrone replica alle gebeurtenissen bevat, kunnen deze gebeurtenissen zich nog steeds alleen in relay-logboeken bevinden. Bij veel verkeer kunnen alle replica's, of het nu semi-sync of async is, vertraging oplopen.
Het probleem met replicatievertraging is dat wanneer u een replica promoot, u de replicatie-instellingen moet resetten, zodat deze niet zal proberen verbinding te maken met de oude master. Hiermee worden ook alle relaislogboeken verwijderd, zelfs als ze nog niet zijn toegepast, wat leidt tot gegevensverlies.
Zelfs als u de replicatie-instellingen niet reset, kunt u nog steeds geen nieuwe master openen voor verbindingen als deze niet alle gebeurtenissen uit het relaislogboek heeft toegepast. Anders loopt u het risico dat de nieuwe zoekopdrachten van invloed zijn op transacties uit het relaislogboek, waardoor allerlei problemen ontstaan (een toepassing kan bijvoorbeeld enkele rijen verwijderen die toegankelijk zijn voor transacties uit het relaislogboek).
Dit alles in overweging nemend, is wachten tot het relaislogboek is toegepast de enige veilige optie. Toch kan het even duren als de replica zwaar achterbleef. Er moeten beslissingen worden genomen over welke replica een betere master zou zijn - asynchroon, maar met een kleine vertraging of semi-synchroon, maar met vertraging zou het een aanzienlijke hoeveelheid tijd kosten om toe te passen.
Foutieve transacties
Hoewel er niet naar replica's mag worden geschreven, kan het toch gebeuren dat iemand (of iets) ernaar heeft geschreven.
In het verleden was het misschien maar een enkele transactie, maar het kan nog steeds een ernstig effect hebben op de mogelijkheid om een failover uit te voeren. Het probleem houdt strikt verband met Global Transaction ID (GTID), een functie die een afzonderlijke ID toewijst aan elke transactie die wordt uitgevoerd op een bepaald MySQL-knooppunt.
Tegenwoordig is het een vrij populaire setup omdat het een hoge mate van flexibiliteit biedt en betere prestaties mogelijk maakt (met replica's met meerdere threads).
Het probleem is dat bij het opnieuw slaaf maken van een nieuwe master, GTID-replicatie vereist dat alle gebeurtenissen van die master (die niet op replica zijn uitgevoerd) naar de replica worden gerepliceerd.
Laten we eens kijken naar het volgende scenario:op een bepaald moment in het verleden is er op een replica geschreven. Het is lang geleden en deze gebeurtenis is verwijderd uit de binaire logs van de replica. Op een gegeven moment is een master gefaald en is de replica aangesteld als nieuwe master. Alle resterende replica's zullen van de nieuwe master worden geslaved. Ze zullen vragen naar transacties die op de nieuwe master zijn uitgevoerd. Het zal reageren met een lijst met GTID's die afkomstig zijn van de oude master en de enkele GTID die betrekking heeft op die oude schrijfactie. GTID's van de oude master zijn geen probleem, aangezien alle resterende replica's ten minste de meeste (zo niet alle) bevatten en alle ontbrekende gebeurtenissen recent genoeg moeten zijn om beschikbaar te zijn in de binaire logboeken van de nieuwe master.
In het ergste geval worden enkele ontbrekende gebeurtenissen uit de binaire logboeken gelezen en naar replica's overgebracht. Het probleem is met dat oude schrijven - het gebeurde alleen op een nieuwe master, terwijl het nog een replica was, dus het bestaat niet op de resterende hosts. Het is een oude gebeurtenis, daarom is er geen manier om deze uit binaire logboeken op te halen. Als gevolg hiervan kan geen van de replica's de nieuwe master als slaaf maken. De enige oplossing hier is om een handmatige actie uit te voeren en een lege gebeurtenis met die problematische GTID op alle replica's te injecteren. Het betekent ook dat, afhankelijk van wat er is gebeurd, de replica's mogelijk niet synchroon lopen met de nieuwe master.
Zoals je kunt zien, is het heel belangrijk om foutieve transacties bij te houden en te bepalen of het veilig is om een bepaalde replica te promoten om een nieuwe master te worden. Als het foutieve transacties bevat, is het misschien niet de beste optie.
Failover-afhandeling voor de toepassing
Het is cruciaal om in gedachten te houden dat hoofdschakelaar, geforceerd of niet, effect heeft op de hele topologie. Schrijfbewerkingen moeten worden omgeleid naar een nieuw knooppunt. Dit kan op meerdere manieren worden gedaan en het is van cruciaal belang ervoor te zorgen dat deze wijziging zo transparant mogelijk is voor de toepassing. In deze sectie zullen we enkele voorbeelden bekijken van hoe de failover transparant kan worden gemaakt voor de toepassing.
DNS
Een van de manieren waarop een toepassing naar een master kan worden verwezen, is door DNS-vermeldingen te gebruiken. Met lage TTL is het mogelijk om het IP-adres te wijzigen waarnaar een DNS-vermelding zoals 'master.dc1.example.com' verwijst. Een dergelijke wijziging kan worden gedaan via externe scripts die tijdens het failoverproces worden uitgevoerd.
Servicedetectie
Tools zoals Consul of etc.d kunnen ook worden gebruikt om het verkeer naar een juiste locatie te leiden. Dergelijke tools kunnen informatie bevatten dat het IP-adres van de huidige master op een bepaalde waarde is ingesteld. Sommigen van hen bieden ook de mogelijkheid om zoekopdrachten voor hostnamen te gebruiken om naar een correct IP-adres te verwijzen. Nogmaals, vermeldingen in hulpprogramma's voor het ontdekken van services moeten worden onderhouden en een van de manieren om dat te doen is om die wijzigingen aan te brengen tijdens het failoverproces, met behulp van hooks die in verschillende fasen van de failover worden uitgevoerd.
Proxy
Proxy's kunnen ook worden gebruikt als een bron van waarheid over topologie. Over het algemeen moeten ze, ongeacht hoe ze de topologie ontdekken (het kan een automatisch proces zijn of de proxy moet opnieuw worden geconfigureerd wanneer de topologie verandert), de huidige status van de replicatieketen bevatten, omdat ze anders niet in staat zouden zijn om route query's correct.
De benadering om een proxy te gebruiken als een bron van waarheid kan heel gebruikelijk zijn in combinatie met de benadering om proxy's op applicatiehosts te plaatsen. Er zijn tal van voordelen aan het samenbrengen van proxy- en webservers:snelle en veilige communicatie met behulp van Unix-socket, een caching-laag (zoals sommige proxy's, zoals ProxySQL ook de caching kunnen doen) dicht bij de applicatie houden. In een dergelijk geval is het logisch dat de toepassing alleen verbinding maakt met de proxy en ervan uitgaat dat deze de zoekopdrachten correct zal routeren.
Failover in ClusterControl
ClusterControl past best practices uit de branche toe om ervoor te zorgen dat het failoverproces correct wordt uitgevoerd. Het zorgt er ook voor dat het proces veilig is - standaardinstellingen zijn bedoeld om de failover af te breken als er mogelijke problemen worden gedetecteerd. Deze instellingen kunnen worden overschreven door de gebruiker als hij voorrang wil geven aan failover boven gegevensbeveiliging.
Zodra een masterfout is gedetecteerd door ClusterControl, wordt een failoverproces gestart en wordt onmiddellijk een eerste failover-hook uitgevoerd:

Vervolgens wordt de beschikbaarheid van de master getest.

ClusterControl doet uitgebreide tests om er zeker van te zijn dat de master inderdaad niet beschikbaar is. Dit gedrag is standaard ingeschakeld en wordt beheerd door de volgende variabele:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Als volgende stap zorgt ClusterControl ervoor dat de oude master niet beschikbaar is en zo niet, dan zal ClusterControl niet proberen deze te herstellen:

De volgende stap is om te bepalen welke host als masterkandidaat kan worden gebruikt. ClusterControl controleert wel of er een witte lijst of een zwarte lijst is gedefinieerd.
U kunt dat doen door de volgende variabelen in het cmon-configuratiebestand te gebruiken:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Het is ook mogelijk om ClusterControl te configureren om te zoeken naar verschillen in binaire logboekfilters voor alle replica's. Het kan worden gedaan met behulp van de variabele replication_check_binlog_filtratie_bf_failover. Standaard zijn die controles uitgeschakeld. ClusterControl controleert ook of er geen foutieve transacties zijn die problemen kunnen veroorzaken.

U kunt ClusterControl ook vragen om replica's die niet kunnen worden gerepliceerd vanaf de nieuwe master automatisch opnieuw op te bouwen met de volgende instelling in het cmon-configuratiebestand:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Daarna wordt een tweede script uitgevoerd:het wordt gedefinieerd in de instelling replication_pre_failover_script. Vervolgens ondergaat een kandidaat een voorbereidingsproces.


ClusterControl wacht op het toepassen van redo-logs (waardoor gegevensverlies minimaal is). Het controleert ook of er andere transacties beschikbaar zijn op resterende replica's, die niet zijn toegepast op de masterkandidaat. Beide gedragingen kunnen door de gebruiker worden gecontroleerd met behulp van de volgende instellingen in het cmon-configuratiebestand:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Zoals u kunt zien, kunt u een failover afdwingen, ook al zijn niet alle redo-loggebeurtenissen toegepast - het stelt de gebruiker in staat te beslissen wat de hogere prioriteit heeft - gegevensconsistentie of failover-snelheid.


Ten slotte wordt de master gekozen en wordt het laatste script uitgevoerd (een script dat kan worden gedefinieerd als replication_post_failover_script.
Als je ClusterControl nog niet hebt geprobeerd, raad ik je aan het te downloaden (het is gratis) en het eens te proberen.
Hoofddetectie in ClusterControl
ClusterControl geeft u de mogelijkheid om een volledige High Availability-stack te implementeren, inclusief database- en proxylagen. Meesterontdekking is altijd een van de problemen om mee om te gaan.
Hoe werkt het in ClusterControl?
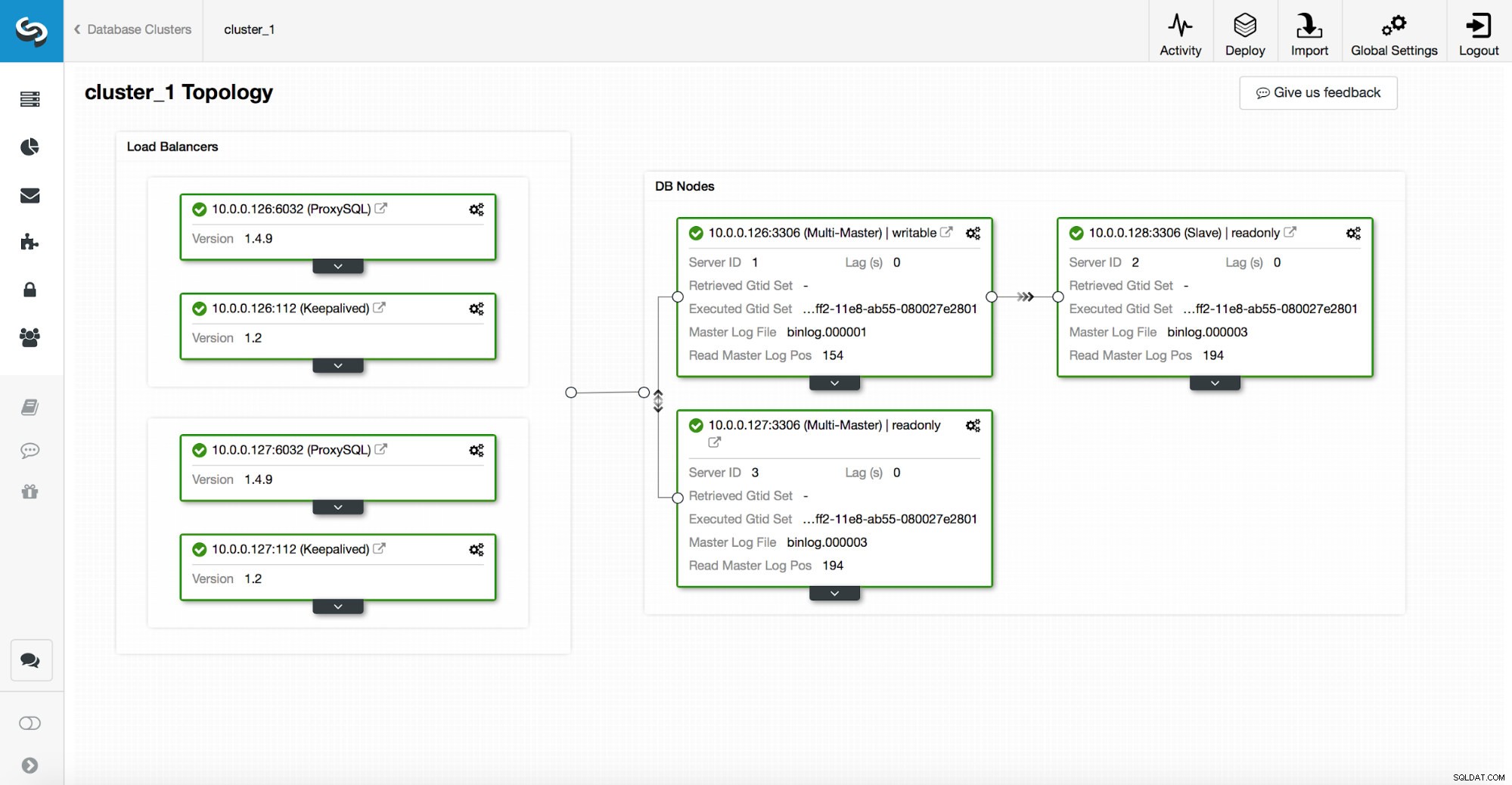
Een high-availability stack, geïmplementeerd via ClusterControl, bestaat uit drie delen:
- databaselaag
- proxylaag die HAProxy of ProxySQL kan zijn
- bewaarde laag, die, met gebruik van Virtual IP, zorgt voor een hoge beschikbaarheid van de proxylaag
Proxy's vertrouwen op alleen-lezen variabelen op de knooppunten.
Zoals u kunt zien in de bovenstaande schermafbeelding, is slechts één knooppunt in de topologie gemarkeerd als "beschrijfbaar". Dit is de master en dit is het enige knooppunt dat schrijfbewerkingen zal ontvangen.
Een proxy (in dit voorbeeld ProxySQL) controleert deze variabele en configureert zichzelf automatisch opnieuw.
Aan de andere kant van die vergelijking zorgt ClusterControl voor topologieveranderingen:failovers en switchovers. Het zal de nodige wijzigingen aanbrengen in de alleen-lezen waarde om de status van de topologie na de wijziging weer te geven. Als een nieuwe master wordt gepromoveerd, wordt deze de enige beschrijfbare node. Als er na de failover een master wordt gekozen, is alleen-lezen uitgeschakeld.
Bovenop de proxylaag wordt keepalive ingezet. Het implementeert een VIP en bewaakt de status van onderliggende proxy-knooppunten. VIP verwijst naar één proxyknooppunt op een bepaald moment. Als dit knooppunt uitvalt, wordt het virtuele IP-adres omgeleid naar een ander knooppunt, zodat het verkeer dat naar VIP wordt geleid een gezond proxyknooppunt bereikt.
Kortom, een applicatie maakt verbinding met de database via een virtueel IP-adres. Dit IP-adres verwijst naar een van de proxy's. Proxy's leiden het verkeer dienovereenkomstig om naar de topologiestructuur. Informatie over topologie is afgeleid van de read_only-status. Deze variabele wordt beheerd door ClusterControl en wordt ingesteld op basis van de topologiewijzigingen die door de gebruiker zijn aangevraagd of die ClusterControl automatisch heeft uitgevoerd.