Het gebruik van Galera-cluster is een geweldige manier om een omgeving met hoge beschikbaarheid voor MySQL of MariaDB te bouwen. Het is een gedeelde-niets-clusteromgeving die zelfs voorbij 12-15 nodes kan worden geschaald. Galera heeft echter enkele beperkingen. Het schittert in omgevingen met lage latentie en hoewel het via WAN kan worden gebruikt, worden de prestaties beperkt door netwerklatentie. De prestaties van Galera kunnen ook worden beïnvloed als een van de knooppunten zich onjuist begint te gedragen. Overmatige belasting van een van de knooppunten kan deze bijvoorbeeld vertragen, wat resulteert in een langzamere verwerking van de schrijfbewerkingen en dat heeft gevolgen voor alle andere knooppunten in het cluster. Aan de andere kant is het vrijwel onmogelijk om een bedrijf te runnen zonder uw gegevens te analyseren. Een dergelijke analyse vereist doorgaans het uitvoeren van zware query's, wat nogal verschilt van een OLTP-workload. In deze blogpost bespreken we een eenvoudige manier om analytische query's uit te voeren voor gegevens die zijn opgeslagen in Galera Cluster voor MySQL of MariaDB, op een manier die geen invloed heeft op de prestaties van het kerncluster.
Hoe analytische zoekopdrachten uitvoeren op Galera Cluster?
Zoals we al zeiden, is het uitvoeren van langlopende query's rechtstreeks op een Galera-cluster te doen, maar misschien niet zo'n goed idee. Afhankelijk van de hardware kan dit een acceptabele oplossing zijn (als u sterke hardware gebruikt en u geen multi-threaded analytische werklast uitvoert), maar zelfs als het CPU-gebruik geen probleem zal zijn, het feit dat een van de knooppunten een gemengde werklast zal hebben ( OLTP en OLAP) alleen al zullen enkele prestatie-uitdagingen opleveren. OLAP-query's verwijderen gegevens die nodig zijn voor uw OLTP-workload uit de bufferpool, en dit vertraagt uw OLTP-query's. Gelukkig is er een eenvoudige maar efficiënte manier om analytische werklast te scheiden van reguliere zoekopdrachten:een asynchrone replicatieslave.
Replicatieslave is een zeer eenvoudige oplossing - u hebt alleen een andere host nodig die kan worden ingericht en asynchrone replicatie moet worden geconfigureerd vanuit Galera Cluster naar dat knooppunt. Bij asynchrone replicatie heeft de slave op geen enkele manier invloed op de rest van het cluster. Het maakt niet uit of het zwaar wordt belast, andere (minder krachtige) hardware gebruikt, het blijft gewoon repliceren vanuit het kerncluster. Het worstcasescenario is dat de replicatieslave achterblijft, maar dan is het aan jou om multi-threaded replicatie te implementeren of, uiteindelijk, om de replicatieslave op te schalen.
Zodra de replicatieslave actief is, moet u de zwaardere query's erop uitvoeren en het Galera-cluster ontlasten. Dit kan op meerdere manieren, afhankelijk van uw setup en omgeving. Als u ProxySQL gebruikt, kunt u eenvoudig query's naar de analytische slave sturen op basis van de bronhost, gebruiker, schema of zelfs de query zelf. Anders is het aan uw applicatie om analytische vragen naar de juiste host te sturen.
Het opzetten van een replicatieslave is niet erg ingewikkeld, maar het kan nog steeds lastig zijn als je niet bedreven bent met MySQL en tools zoals xtrabackup. Het hele proces zou bestaan uit het opzetten van de repository op een nieuwe server en het installeren van de MySQL-database. Vervolgens moet u die host inrichten met behulp van gegevens uit het Galera-cluster. Je kunt daarvoor xtrabackup gebruiken, maar andere tools zoals mydumper/myloader of zelfs mysqldump zullen ook werken (zolang je ze correct uitvoert). Zodra de gegevens er zijn, moet u de replicatie instellen tussen een master Galera-node en de replicatieslave. Ten slotte zou u uw proxylaag opnieuw moeten configureren om de nieuwe slave op te nemen en het verkeer ernaartoe te leiden of aanpassingen door te voeren in de manier waarop uw toepassing verbinding maakt met de database om een deel van de belasting naar de replicatieslave om te leiden.
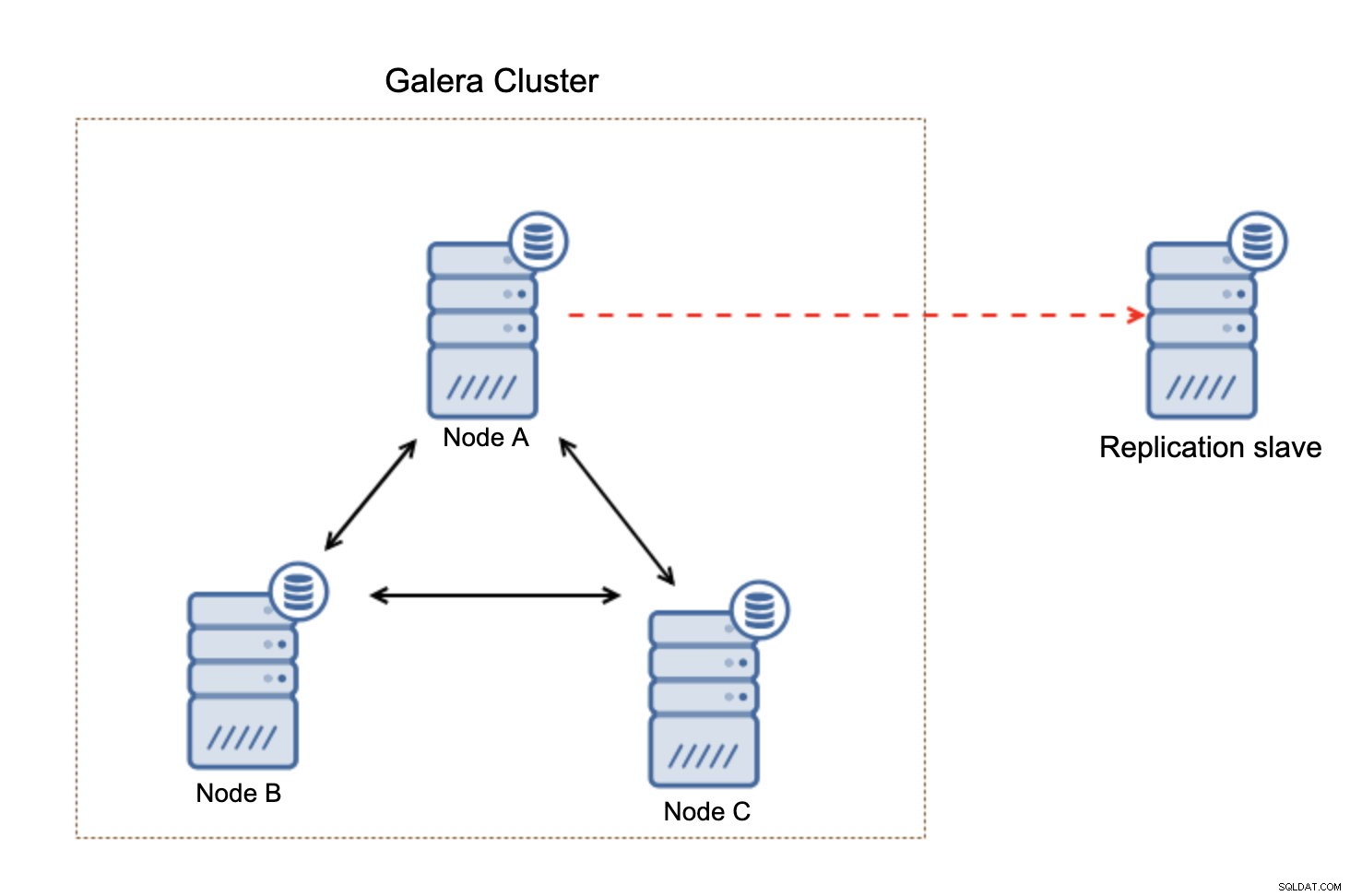
Wat belangrijk is om in gedachten te houden, is dat deze opstelling niet veerkrachtig is. Als de "master" Galera-node uitvalt, wordt de replicatielink verbroken en zal er een handmatige actie worden ondernomen om de replica van een andere master-node in de Galera-cluster te slaven.
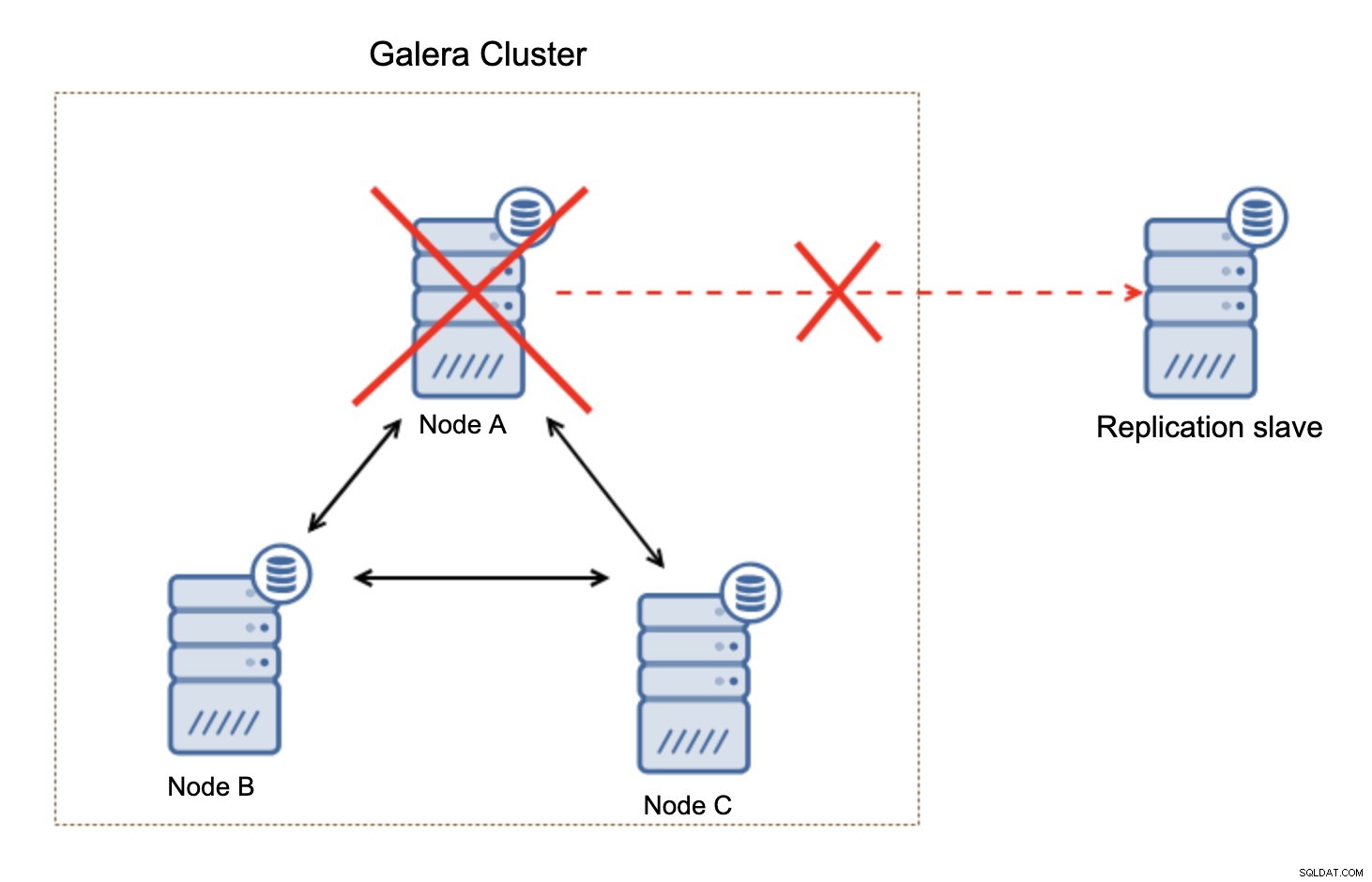
Dit is niet erg, vooral als u replicatie met GTID (Global Transaction ID) gebruikt, maar u moet vaststellen dat de replicatie is verbroken en vervolgens de handmatige actie ondernemen.
Hoe de asynchrone slave voor Galera Cluster instellen met ClusterControl?
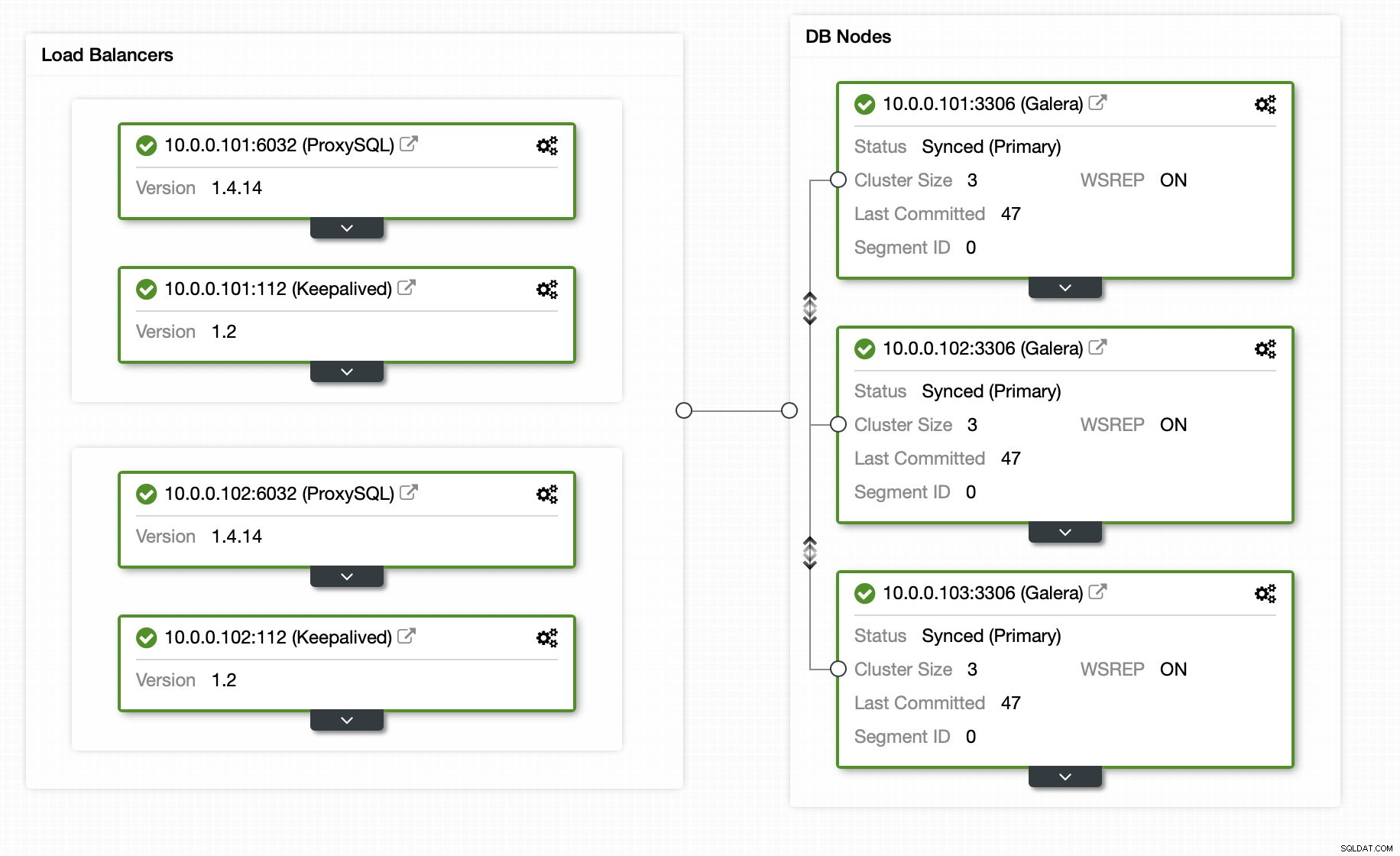
Gelukkig, als je ClusterControl gebruikt, kan het hele proces worden geautomatiseerd en vereist het slechts een handvol klikken. De initiële status is al ingesteld met ClusterControl - een Galera-cluster met 3 knooppunten met 2 ProxySQL-knooppunten en 2 Keepalived-knooppunten voor hoge beschikbaarheid van zowel de database als de proxylaag.
Het toevoegen van de replicatieslave is slechts een klik verwijderd:
Voor replicatie moeten uiteraard binaire logboeken zijn ingeschakeld. Als u geen binlogs hebt ingeschakeld op uw Galera-knooppunten, kunt u dit ook doen vanuit ClusterControl. Houd er rekening mee dat het inschakelen van binaire logboeken een herstart van het knooppunt vereist om de configuratiewijzigingen toe te passen.
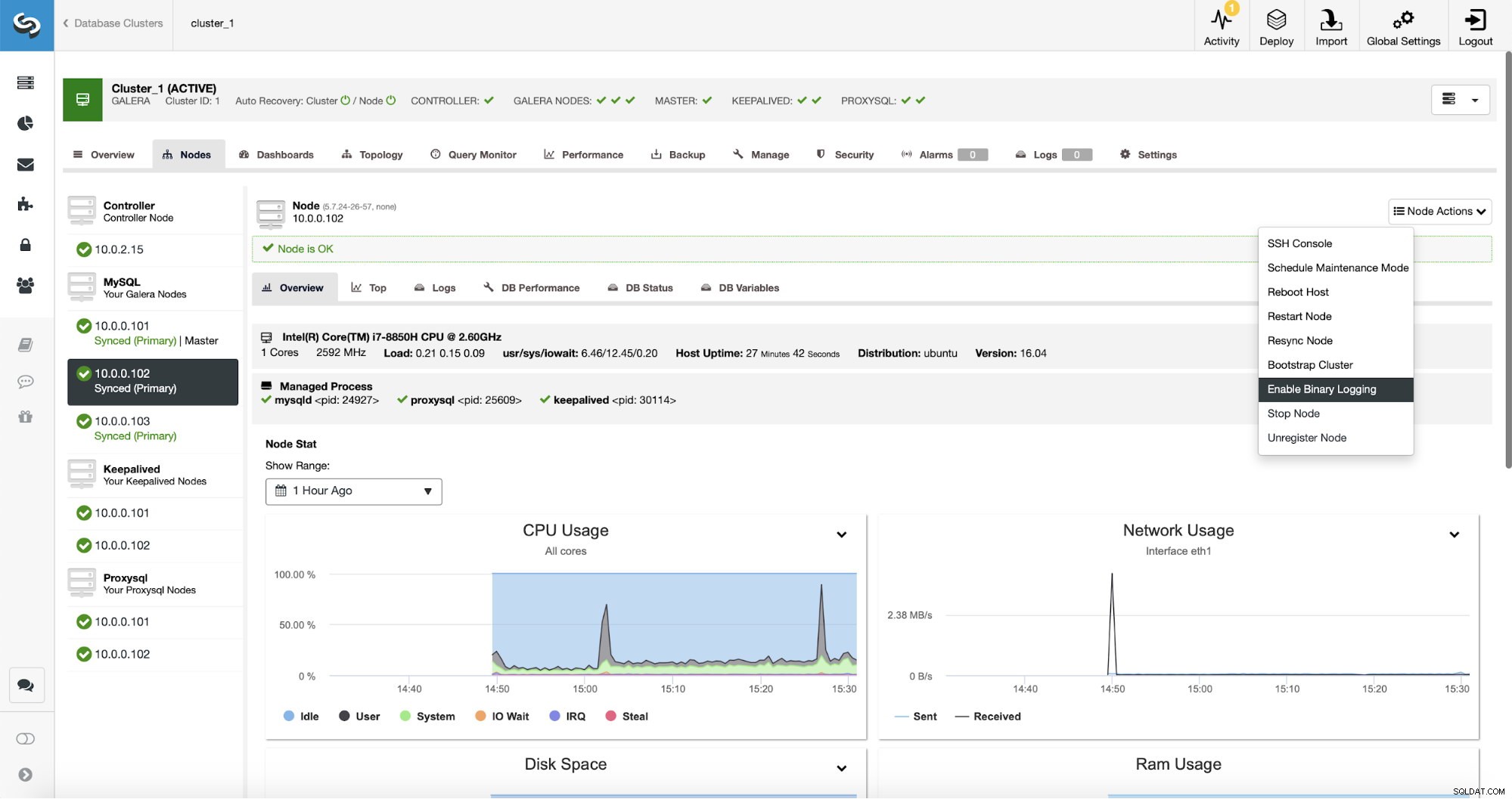
Zelfs als een knooppunt in het cluster binaire logboeken heeft ingeschakeld (gemarkeerd als "Master" op de bovenstaande schermafbeelding), is het nog steeds goed om binair logboek in te schakelen op ten minste één extra knooppunt. ClusterControl kan de replicatieslave automatisch overnemen nadat het heeft gedetecteerd dat het hoofd Galera-knooppunt is gecrasht, maar daarvoor is een ander hoofdknooppunt met binaire logboeken ingeschakeld nodig, anders heeft het niets om naar over te stappen.
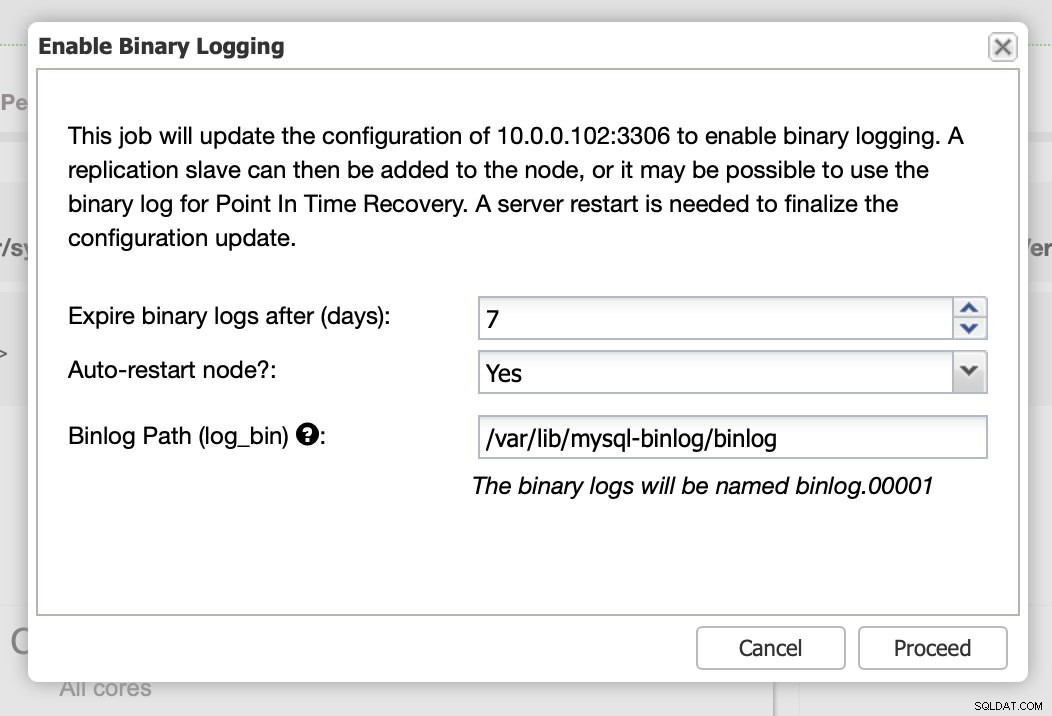
Zoals we al zeiden, vereist het inschakelen van binaire logboeken opnieuw opstarten. U kunt het direct uitvoeren of u kunt de configuratie wijzigen en de herstart op een ander moment uitvoeren.
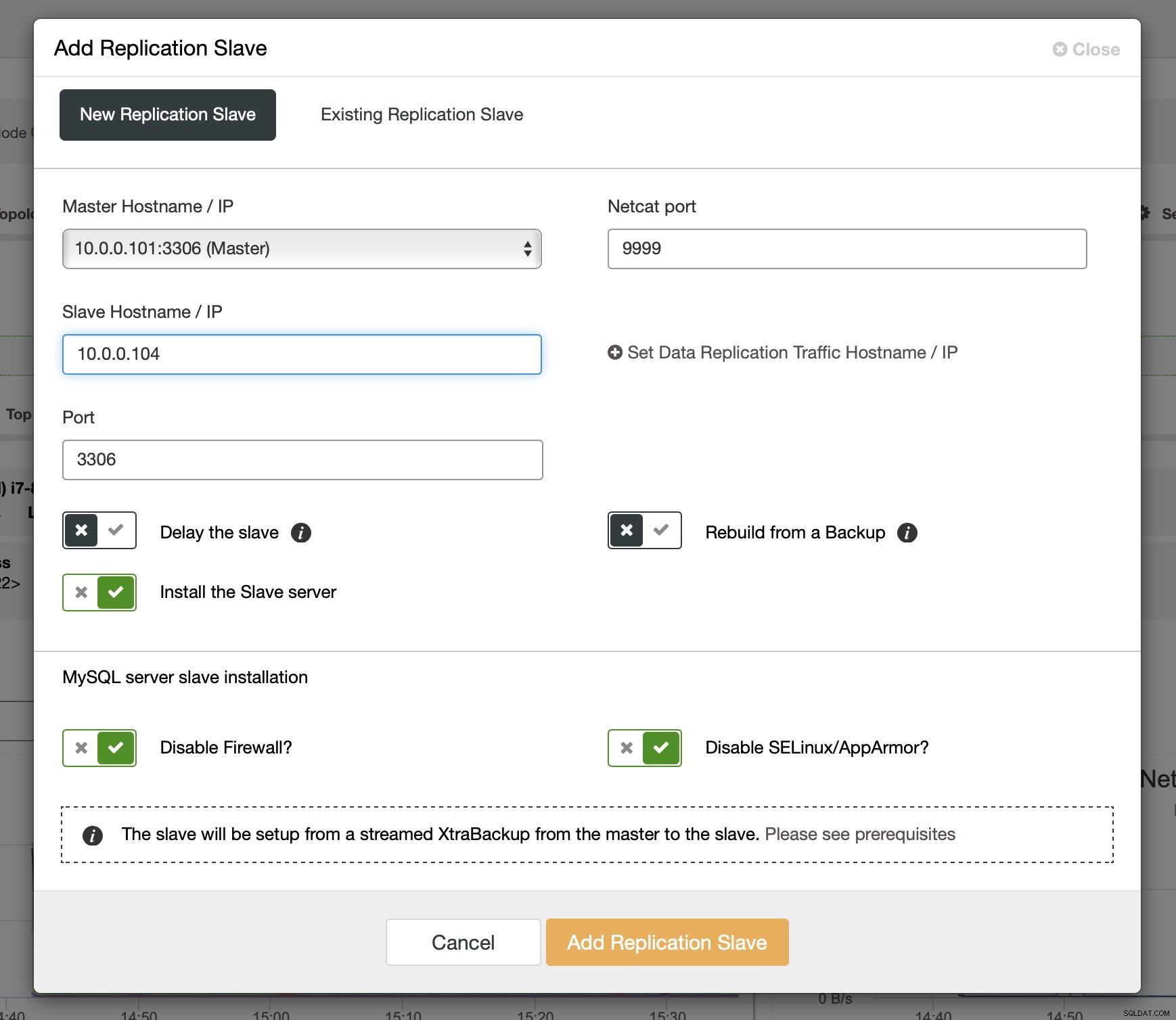
Nadat binlogs zijn ingeschakeld op sommige van de Galera-knooppunten, kunt u doorgaan met het toevoegen van de replicatieslave. In het dialoogvenster moet u de masterhost kiezen, de hostnaam of het IP-adres van de slave doorgeven. Als je recente back-ups bij de hand hebt (wat je zou moeten doen), kun je er een gebruiken om de slave in te richten. Anders zal ClusterControl het inrichten met xtrabackup - alle recente mastergegevens worden naar de slave gestreamd en vervolgens wordt de replicatie geconfigureerd.
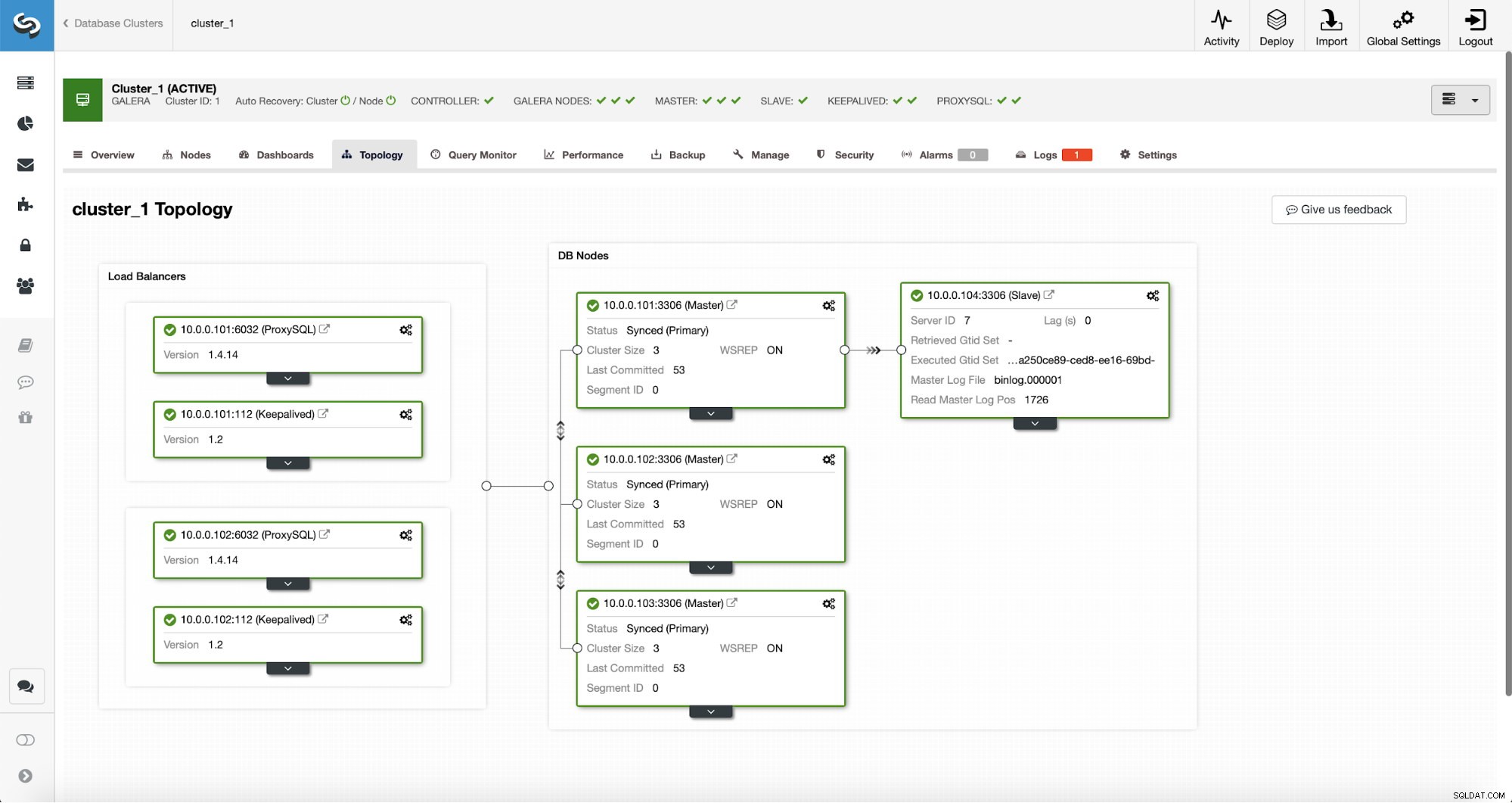
Nadat de taak is voltooid, is een replicatieslave toegevoegd aan het cluster. Zoals eerder vermeld, als de 10.0.0.101 sterft, wordt een andere host in het Galera-cluster gekozen als de master en ClusterControl zal 10.0.0.104 automatisch van een ander knooppunt afslaan.
Omdat we ProxySQL gebruiken, moeten we het configureren. We voegen een nieuwe server toe aan ProxySQL.
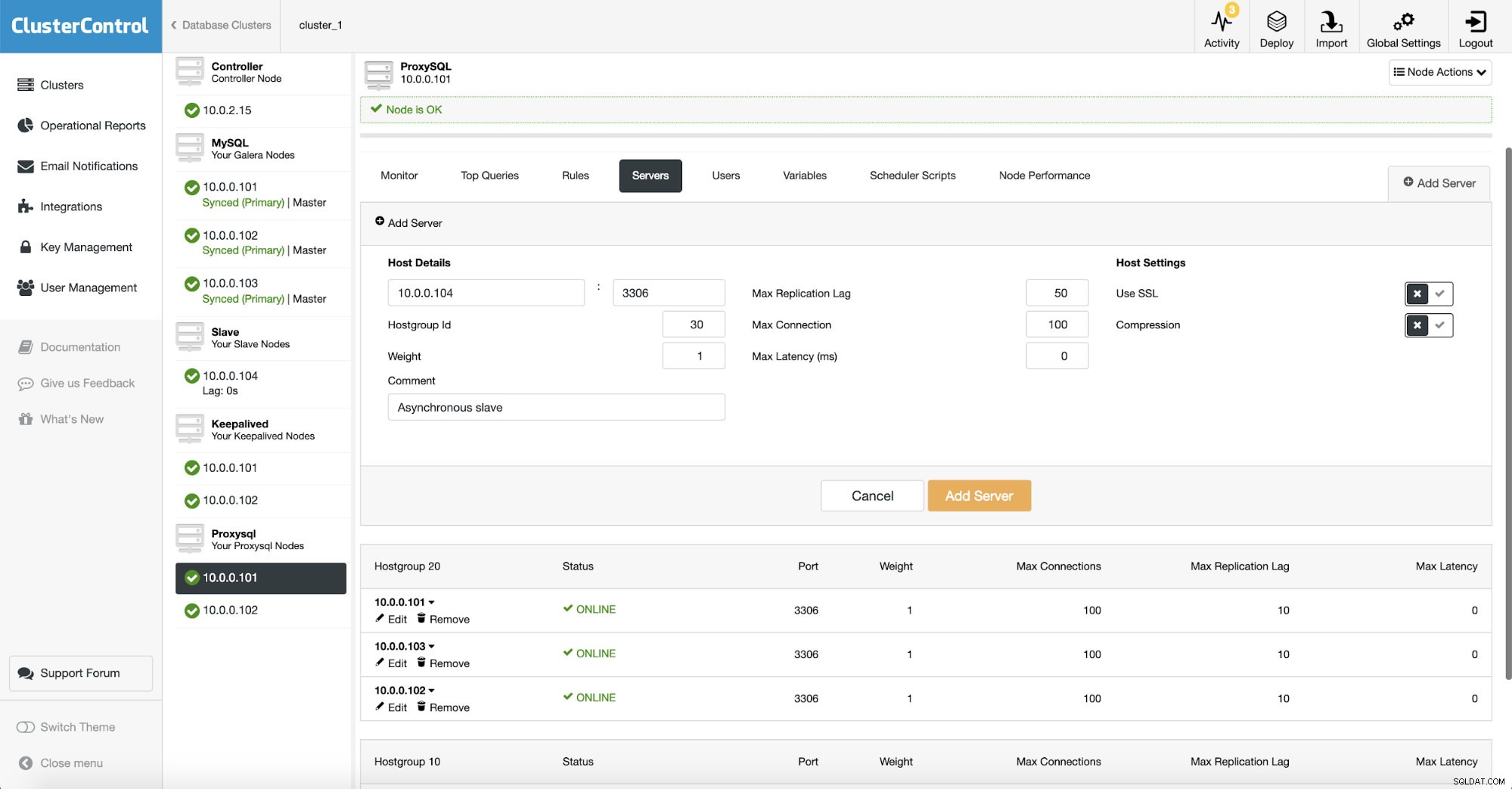
We hebben een andere hostgroep (30) gemaakt waar we onze asynchrone slaaf hebben geplaatst. We hebben ook de "Max replicatievertraging" verhoogd naar 50 seconden ten opzichte van de standaard 10. Het is aan uw zakelijke vereisten hoe erg de analyseslave kan achterblijven voordat het een probleem wordt.
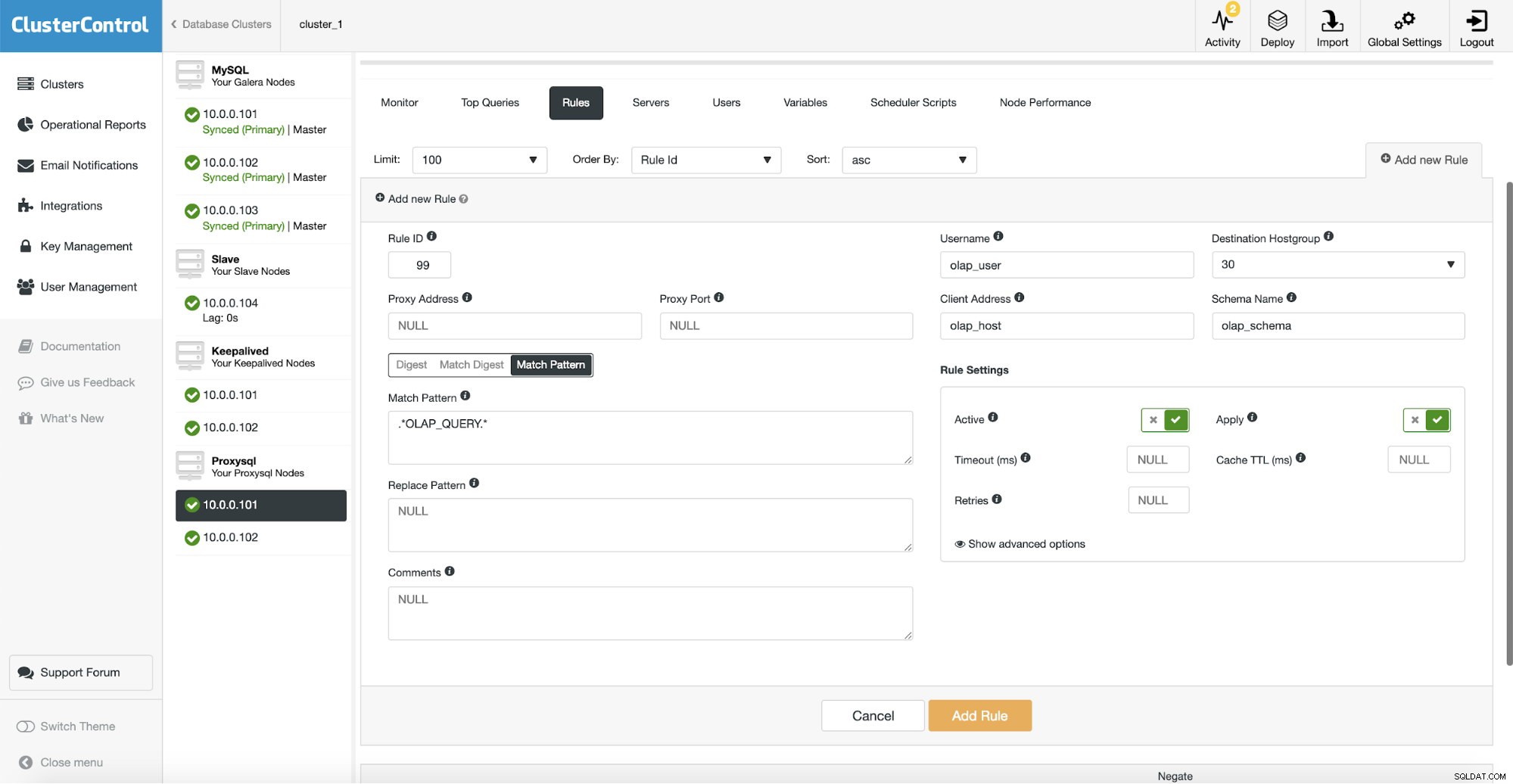
Daarna moeten we een queryregel configureren die overeenkomt met ons OLAP-verkeer en dit naar de OLAP-hostgroep sturen (30). Op de bovenstaande schermafbeelding hebben we verschillende velden ingevuld - dit is niet verplicht. Meestal moet u er één gebruiken, maximaal twee. Bovenstaande schermafbeelding dient als voorbeeld, zodat we gemakkelijk kunnen zien dat u query's kunt matchen met behulp van schema (als u een apart schema met analytische gegevens hebt), hostnaam/IP (als OLAP-query's worden uitgevoerd vanaf een bepaalde host), gebruiker (als toepassing gebruikmaakt van bepaalde gebruiker voor analytische query's. U kunt query's ook rechtstreeks matchen door een volledige query door te geven of door ze te markeren met SQL-opmerkingen en ProxySQL alle query's met een "OLAP_QUERY"-tekenreeks naar onze analytische hostgroep te laten routeren.
Zoals u kunt zien, konden we dankzij ClusterControl in slechts een paar klikken een replicatieslave in Galera Cluster implementeren. Sommigen zullen misschien beweren dat MySQL niet de meest geschikte database is voor analytische werklast en wij zijn het daar meestal mee eens. U kunt deze configuratie eenvoudig uitbreiden met ClickHouse en door een replicatie van asynchrone slave naar ClickHouse-kolomvormige datastore in te stellen voor veel betere prestaties van analytische query's. We hebben deze opzet beschreven in een van de eerdere blogposts.