De database-backend is van invloed op de applicatie, wat vervolgens van invloed kan zijn op de prestaties van de organisatie. Wanneer dit gebeurt, hebben de verantwoordelijken de neiging om een snelle oplossing te willen. Er zijn veel verschillende wegen om de prestaties in MySQL te verbeteren. Als een zeer populaire keuze voor veel organisaties, is het vrij gebruikelijk om een MySQL-installatie te vinden met de standaardconfiguratie. Dit is echter mogelijk niet geschikt voor uw werklast en instellingen.
In deze blog helpen we je een beter inzicht te krijgen in de werkbelasting van je database en de dingen die daar schade aan kunnen toebrengen. Kennis van het gebruik van beperkte middelen is essentieel voor iedereen die de database beheert, vooral als u uw productiesysteem op MySQL DB draait.
Om ervoor te zorgen dat de database werkt zoals verwacht, beginnen we met de gratis MySQL-monitoringtools. We zullen dan kijken naar de gerelateerde MySQL-parameters die u kunt aanpassen om de database-instantie te verbeteren. We zullen ook kijken naar indexering als een factor in het beheer van databaseprestaties.
Om optimaal gebruik te kunnen maken van hardwarebronnen, zullen we kijken naar kerneloptimalisatie en andere cruciale OS-instellingen. Ten slotte zullen we kijken naar trendy setups op basis van MySQL-replicatie en hoe deze kunnen worden onderzocht in termen van prestatievertraging.
Identificatie van MySQL-prestatieproblemen
Deze analyse helpt u de gezondheid en prestaties van uw database beter te begrijpen. De onderstaande tools kunnen helpen om elke transactie vast te leggen en te begrijpen, zodat u op de hoogte blijft van de prestaties en het verbruik van hulpbronnen.
PMM (Percona Monitoring en Beheer)
Percona Monitoring and Management-tool is een open-source verzameling tools voor MySQL-, MongoDB- en MariaDB-databases (op locatie of in de cloud). PPM is gratis te gebruiken en is gebaseerd op de bekende Grafana en Prometheus tijdreeksen DB. Het biedt een grondige, op tijd gebaseerde analyse voor MySQL. Het biedt voorgeconfigureerde dashboards die u helpen uw databasewerklast te begrijpen.
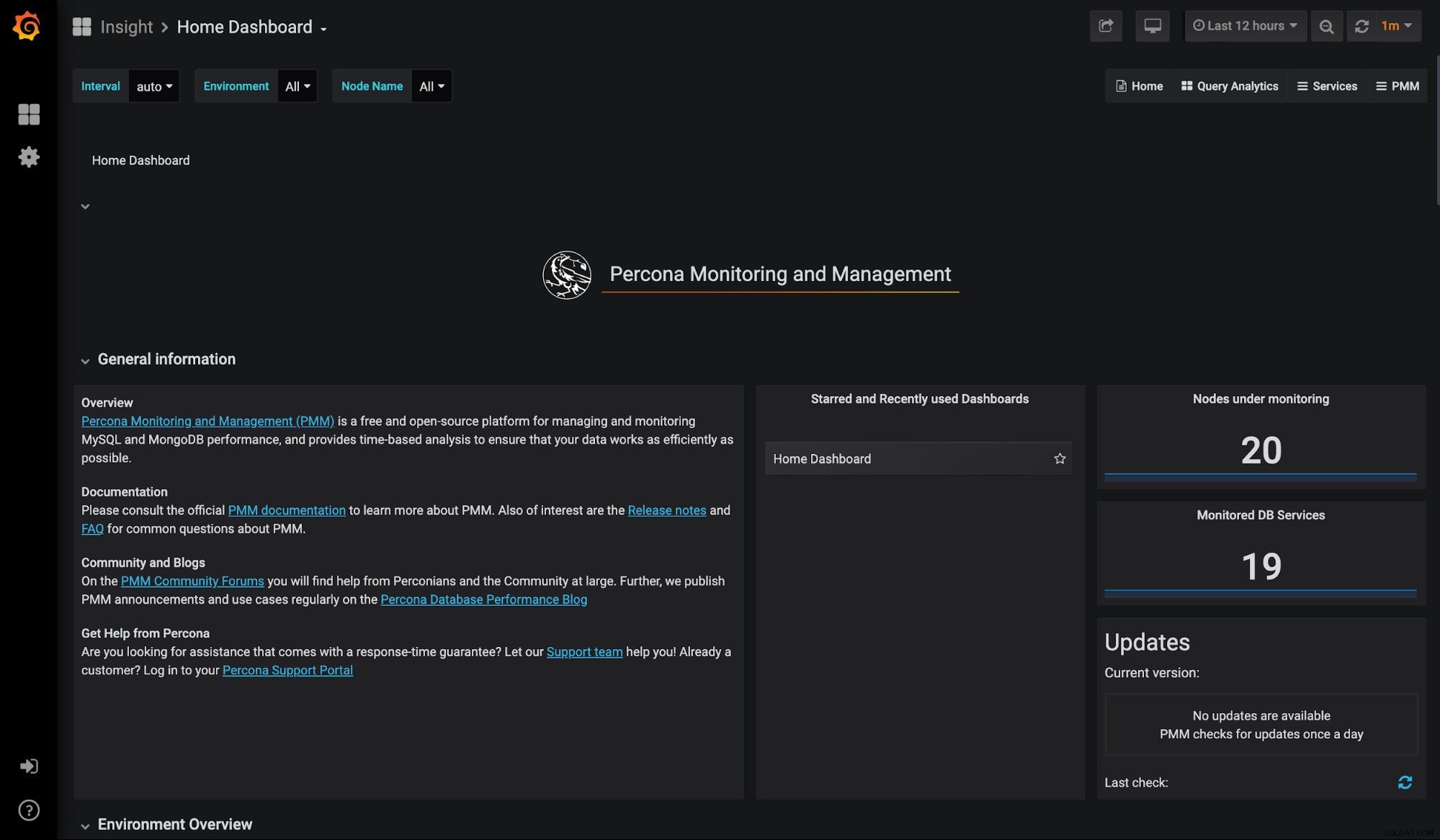
PMM gebruikt een client/server-model. U moet zowel de client als de server downloaden en installeren. Voor de server kunt u Docker Container gebruiken. Het is net zo eenvoudig als het ophalen van de PMM-serverdocker-image, het maken van een container en het starten van PMM.
PMM-serverafbeelding ophalen
docker pull percona/pmm-server:2
2: Pulling from percona/pmm-server
ab5ef0e58194: Downloading 2.141MB/75.78MB
cbbdeab9a179: Downloading 2.668MB/400.5MBPMM-container maken
docker create \
-v /srv \
--name pmm-data \
percona/pmm-server:2 /bin/trueContainer uitvoeren
docker run -d \
-p 80:80 \
-p 443:443 \
--volumes-from pmm-data \
--name pmm-server \
--restart always \
percona/pmm-server:2U kunt ook controleren hoe het eruit ziet zonder installatie. Een demo van PMM is hier beschikbaar.
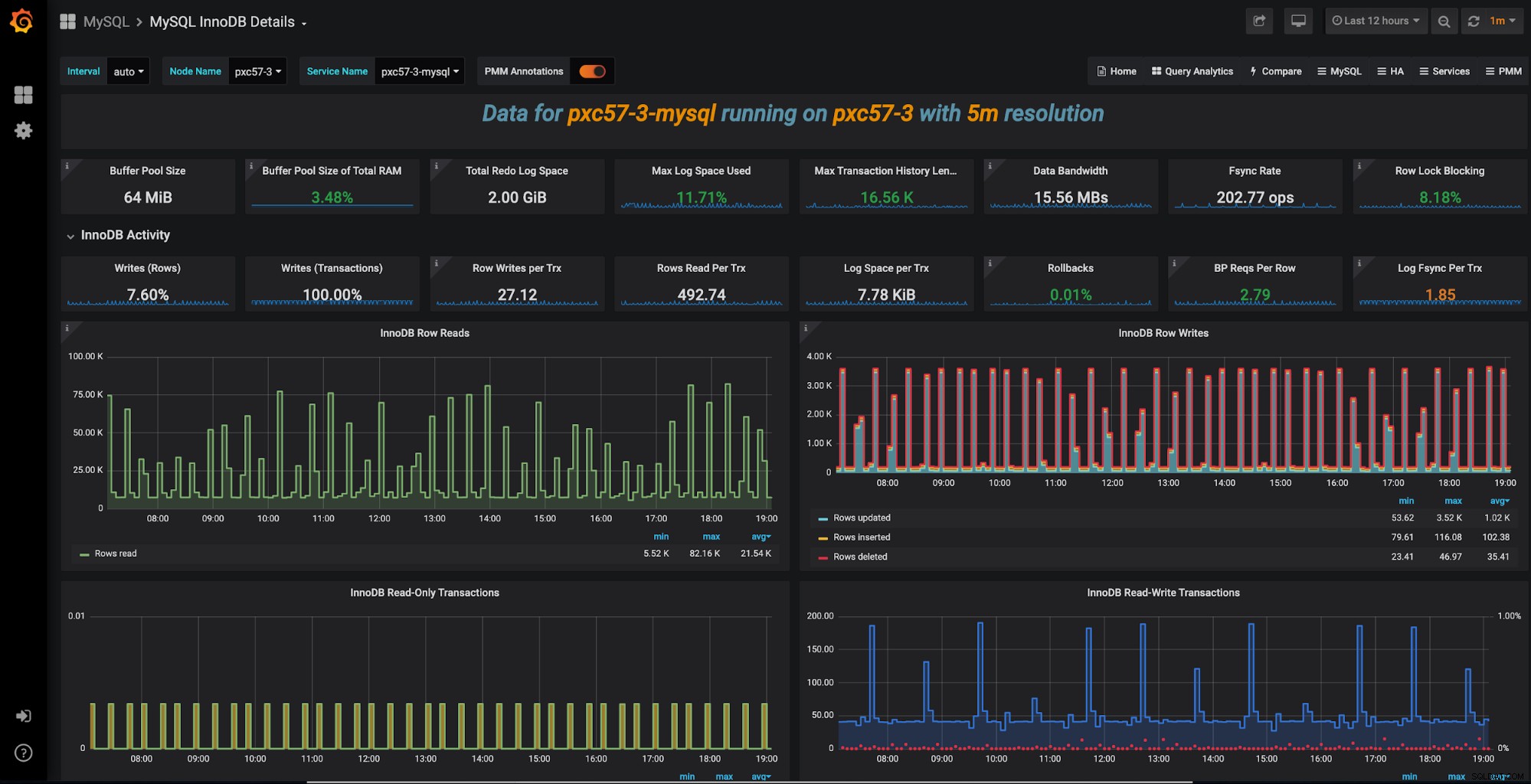
Een andere tool die deel uitmaakt van de PMM-toolset is Query Analytics (QAN). QAN-tool blijft op de hoogte van de uitvoeringstijd van query's. U kunt zelfs details van SQL-query's krijgen. Het geeft ook een historisch overzicht van de verschillende parameters die cruciaal zijn voor de optimale prestaties van een MySQL-databaseserver. Dit helpt vaak om te begrijpen of wijzigingen in de code uw prestaties kunnen schaden. Er is bijvoorbeeld een nieuwe code ingevoerd zonder uw medeweten. Een eenvoudig gebruik zou zijn om huidige SQL-query's weer te geven en problemen te markeren om u te helpen de prestaties van uw database te verbeteren.
PMM biedt point-in-time en historische zichtbaarheid van MySQL-databaseprestaties. Dashboards kunnen worden aangepast aan uw specifieke vereisten. Je kunt zelfs een bepaald paneel uitvouwen om de gewenste informatie over een vorig evenement te vinden.
Gratis databasebewaking met ClusterControl
ClusterControl biedt realtime monitoring van de gehele database-infrastructuur. Het ondersteunt verschillende databasesystemen, te beginnen met MySQL, MariaDB, PerconaDB, MySQL NDB Cluster, Galera Cluster (zowel Percona als MariaDB), MongoDB, PostgreSQL en TimescaleDB. De monitoring- en implementatiemodules zijn gratis te gebruiken.
ClusterControl bestaat uit verschillende modules. In de gratis ClusterControl Community Edition kunnen we gebruik maken van:

Prestatieadviseurs bieden specifiek advies over het aanpakken van database- en serverproblemen, zoals zoals prestaties, beveiliging, logbeheer, configuratie en capaciteitsplanning. Operationele rapporten kunnen worden gebruikt om naleving van honderden instanties te waarborgen. Monitoring is echter geen beheer. ClusterControl heeft functies zoals back-upbeheer, geautomatiseerd herstel/failover, implementatie/schaling, rolling upgrades, beveiliging/encryptie, load balancer-beheer, enzovoort.
Bewaking en adviseurs
De ClusterControl Community Edition biedt gratis databasebewaking die een uniform beeld geeft van al uw implementaties in datacenters en u in staat stelt om in te zoomen op afzonderlijke knooppunten. Net als bij PMM kunnen we dashboards vinden op basis van realtime gegevens. Het is om te weten wat er nu gebeurt, met statistieken met hoge resolutie voor een betere nauwkeurigheid, vooraf geconfigureerde dashboards en een breed scala aan meldingsservices van derden voor waarschuwingen.
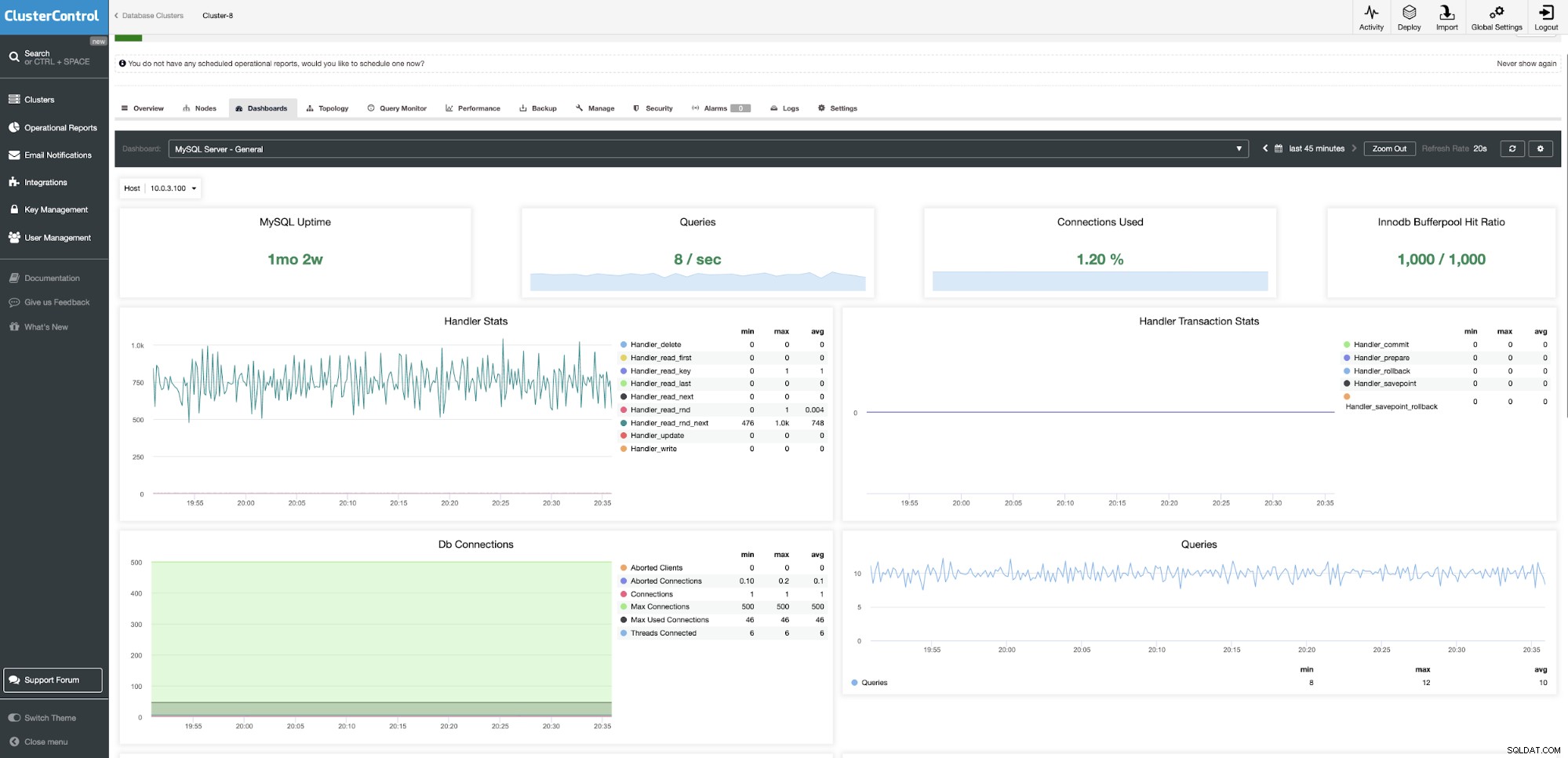
On-premises en cloudsystemen kunnen vanaf één enkel punt worden bewaakt en beheerd . Intelligente gezondheidscontroles worden geïmplementeerd voor gedistribueerde topologieën, bijvoorbeeld detectie van netwerkpartitionering door gebruik te maken van de load balancer-weergave van de databaseknooppunten.
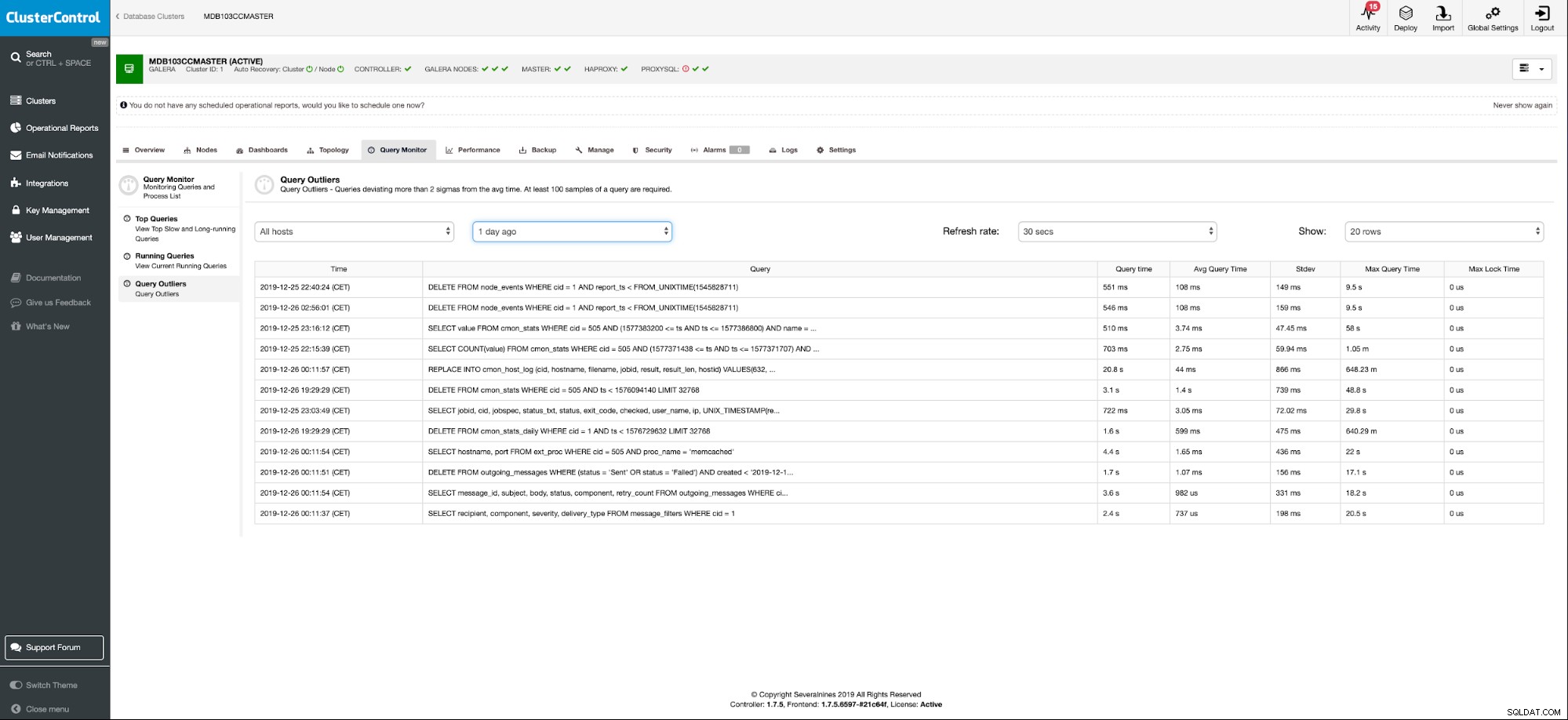
ClusterControl Workload Analytics in een van de monitoringcomponenten die u gemakkelijk kunnen helpen om volg uw database-activiteiten. Het geeft duidelijkheid in transacties/query's van applicaties. Prestatie-uitzonderingen worden nooit verwacht, maar ze komen voor en zijn gemakkelijk te missen in een zee van gegevens. Uitbijterdetectie zal vragen krijgen die plotseling veel langzamer worden uitgevoerd dan normaal. Het volgt het voortschrijdend gemiddelde en de standaarddeviatie voor de uitvoeringstijden van query's en detecteert/waarschuwt wanneer het verschil tussen de waarde het gemiddelde met twee standaarddeviaties overschrijdt.
Zoals we op de onderstaande afbeelding kunnen zien, hebben we een aantal zoekopdrachten kunnen opvangen die op een bepaalde dag de uitvoeringstijd op een bepaald tijdstip veranderen.
Klik hier om ClusterControl te installeren en download het installatiescript. Het installatiescript zorgt voor de nodige installatiestappen.
Bekijk ook de ClusterControl-demo om deze in actie te zien.
Je kunt ook een docker-image krijgen met ClusterControl.
$ docker pull severalnines/clustercontrolVolg dit artikel voor meer informatie hierover.
MySQL-database-indexering
Zonder een index resulteert het uitvoeren van diezelfde query in een scan van elke rij voor de benodigde gegevens. Door een index op een veld in een tabel te maken, wordt een extra gegevensstructuur gecreëerd, namelijk de veldwaarde, en een verwijzing naar het record waarop het betrekking heeft. Met andere woorden, indexeren levert een snelkoppeling op, met veel snellere querytijden op uitgebreide tabellen. Zonder index moet MySQL beginnen met de eerste rij en vervolgens de hele tabel doorlezen om de relevante rijen te vinden.
Over het algemeen werkt indexeren het beste voor die kolommen die het onderwerp zijn van de WHERE-clausules in uw veelgebruikte zoekopdrachten.
Tabellen kunnen meerdere indexen hebben. Het beheren van indexen vereist onvermijdelijk dat u de bestaande indexen in een tabel kunt weergeven. De syntaxis voor het bekijken van een index staat hieronder.
Indexen controleren op MySQL-tabelrun:
SHOW INDEX FROM table_name;Omdat indexen alleen worden gebruikt om het zoeken naar een overeenkomend veld binnen de records te versnellen, is het logisch dat het indexeren van velden die alleen voor uitvoer worden gebruikt, gewoon een verspilling van schijfruimte zou zijn. Een ander neveneffect is dat indexen de invoeg- of verwijderbewerkingen kunnen verlengen, en dus moeten worden vermeden als ze niet nodig zijn.
Verwisseling van MySQL-database
Op servers waarop MySQL de enige service is die draait, is het een goede gewoonte om vm.swapiness =1 in te stellen. De standaardinstelling is 60, wat niet geschikt is voor een databasesysteem.
vi /etc/sysctl.conf
vm.swappiness = 1Transparante grote pagina's
Als je MySQL op RedHat draait, zorg er dan voor dat Transparent Huge Pages is uitgeschakeld.
Dit kan worden gecontroleerd met het commando:
cat /proc/sys/vm/nr_hugepages
0(0 betekent dat transparante grote pagina's zijn uitgeschakeld.)
MySQL I/O-planner
In de meeste distributies moeten noop of deadline I/O-planners standaard zijn ingeschakeld. Om het te controleren, voer het uit
cat /sys/block/sdb/queue/scheduler MySQL-bestandssysteemopties
Het wordt aanbevolen om gejournaliseerde bestandssystemen zoals xfs, ext4 of btrfs te gebruiken. MySQL werkt prima met dat alles en de verschillen zullen waarschijnlijk komen met de ondersteunde maximale bestandsgrootte.
- XFS (maximale bestandssysteemgrootte 8EB, maximale bestandsgrootte 8EB)
- XT4 (maximale bestandssysteemgrootte 8EB, maximale bestandsgrootte 16TB)
- BTRFS (maximale bestandssysteemgrootte 16EB, maximale bestandsgrootte 16EB)
De standaardinstellingen van het bestandssysteem zouden goed moeten zijn.
NTP Deamon
Het is een goede gewoonte om NTP time server demon op databaseservers te installeren. Gebruik een van de volgende systeemopdrachten.
#Red Hat
yum install ntp
#Debian
sudo apt-get install ntpConclusie
Dit is allemaal voor deel één. In het volgende artikel gaan we verder met MySQL-variabelen, instellingen voor besturingssystemen en nuttige query's om de prestatiestatus van de database te verzamelen.