Percona XtraDB Cluster is een zeer bekende oplossing met hoge beschikbaarheid in de MySQL-wereld. Het is gebaseerd op Galera Cluster en biedt vrijwel synchrone replicatie over meerdere knooppunten. Zoals bij elke database is het van cruciaal belang om bij te houden wat er in het systeem gebeurt, of de prestaties op het verwachte niveau zijn en, zo niet, wat het knelpunt is. Dit is van het grootste belang om goed te kunnen reageren in de situatie waarin de prestaties worden beïnvloed. Natuurlijk wordt Percona XtraDB Cluster geleverd met meerdere statistieken en het is niet altijd duidelijk welke van hen de belangrijkste zijn om de status van de database bij te houden. In deze blog bespreken we een aantal van de belangrijkste statistieken die je in de gaten wilt houden tijdens het werken met PXC.
Om het duidelijk te maken, zullen we ons concentreren op de statistieken die uniek zijn voor PXC en Galera, we zullen geen statistieken behandelen voor MySQL of InnoDB. Die statistieken zijn besproken in onze vorige blogs.
Laten we eens kijken naar enkele van de belangrijkste informatie die PXC ons presenteert.
Flowregeling
Flow control is zo'n beetje de belangrijkste statistiek die je kunt controleren in een Galera-cluster, dus laten we wat achtergrondinformatie geven. Galera is een multi-master, vrijwel synchroon cluster. Het is mogelijk om schrijfbewerkingen uit te voeren op elk van de databaseknooppunten waaruit het bestaat. Elke schrijfactie moet naar alle knooppunten in het cluster worden verzonden om ervoor te zorgen dat deze kan worden toegepast - dit proces wordt de certificering genoemd. Er kan geen transactie worden toegepast voordat alle knooppunten het erover eens zijn dat deze kan worden uitgevoerd. Als een van de nodes prestatieproblemen heeft waardoor het het verkeer niet aankan, begint het met het uitgeven van flow control-berichten die bedoeld zijn om de rest van het cluster te informeren over de prestatieproblemen en hen te vragen de werklast te verminderen en de vertraagde node om de rest van het cluster in te halen.
Je kunt bijhouden wanneer knooppunten kunstmatige pauzes moesten introduceren om hun achterblijvende peers te laten inhalen met behulp van gepauzeerde datastroombesturing (wsrep_flow_control_paused):

U kunt ook volgen of het knooppunt de flow control-berichten verzendt of ontvangt (wsrep_flow_control_recv en wsrep_flow_control_sent).
Deze informatie helpt u beter te begrijpen welk knooppunt niet op dezelfde niveau als zijn collega's. U kunt zich dan concentreren op dat knooppunt en proberen te begrijpen wat het probleem is en hoe u het knelpunt kunt verwijderen.
Verzend en ontvang wachtrijen
Die statistieken hebben een beetje te maken met de stroomregeling. Zoals we hebben besproken, loopt een knooppunt mogelijk achter op andere knooppunten in het cluster. Het kan worden veroorzaakt door een ongelijke verdeling van de werklast of door andere redenen (een proces dat op de achtergrond wordt uitgevoerd, een back-up of een aantal aangepaste, zware zoekopdrachten). Voordat de flow control van start gaat, zullen achterblijvende nodes proberen de binnenkomende schrijfsets op te slaan in de ontvangstwachtrij (wsrep_local_recv_queue), in de hoop dat de prestatie-impact van voorbijgaande aard is en dat deze zeer snel zal kunnen worden ingehaald. Alleen als de wachtrij te groot wordt (deze wordt bepaald door de gcs.fc_limit-instelling), worden er stroomcontroleberichten over het cluster verzonden.

Je kunt een ontvangstwachtrij beschouwen als de vroege markering die aangeeft dat er zijn er problemen met de prestaties en kan de stroomregeling optreden.

Aan de andere kant zal de verzendwachtrij (wsrep_local_send_queue) u vertellen dat het knooppunt de schrijfsets niet naar andere leden van het cluster kan verzenden, wat kan duiden op problemen met de netwerkverbinding (door de schrijfsets naar het netwerk is niet echt arbeidsintensief).
Parallisatiestatistieken
Percona XtraDB-cluster kan worden geconfigureerd om meerdere threads te gebruiken om de inkomende schrijfsets toe te passen - het stelt het in staat om meerdere threads die verbinding maken met het cluster en tegelijkertijd schrijfopdrachten uit te voeren, beter af te handelen. Er zijn twee belangrijke statistieken die u misschien in de gaten wilt houden.
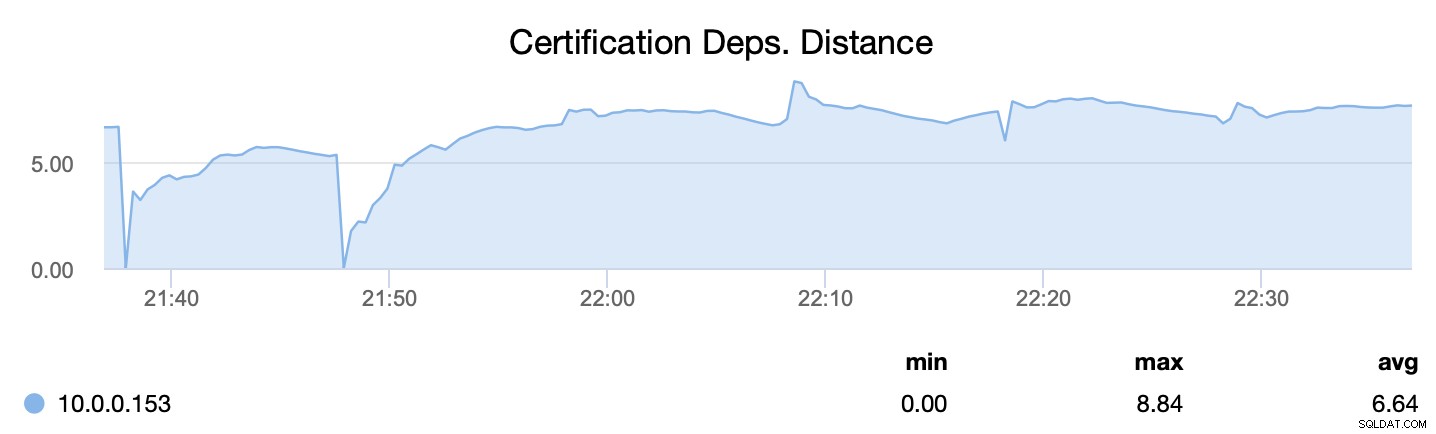
Ten eerste vertelt wsrep_cert_deps_distance ons wat het parallellisatiepotentieel is - hoeveel schrijfsets er mogelijk tegelijkertijd kunnen worden toegepast. Op basis van deze waarde kunt u het aantal parallelle slave-threads (wsrep_slave_threads) configureren dat zal werken bij het toepassen van inkomende schrijfsets. De vuistregel is dat het geen zin heeft om meer threads te configureren dan de waarde van wsrep_cert_deps_distance.
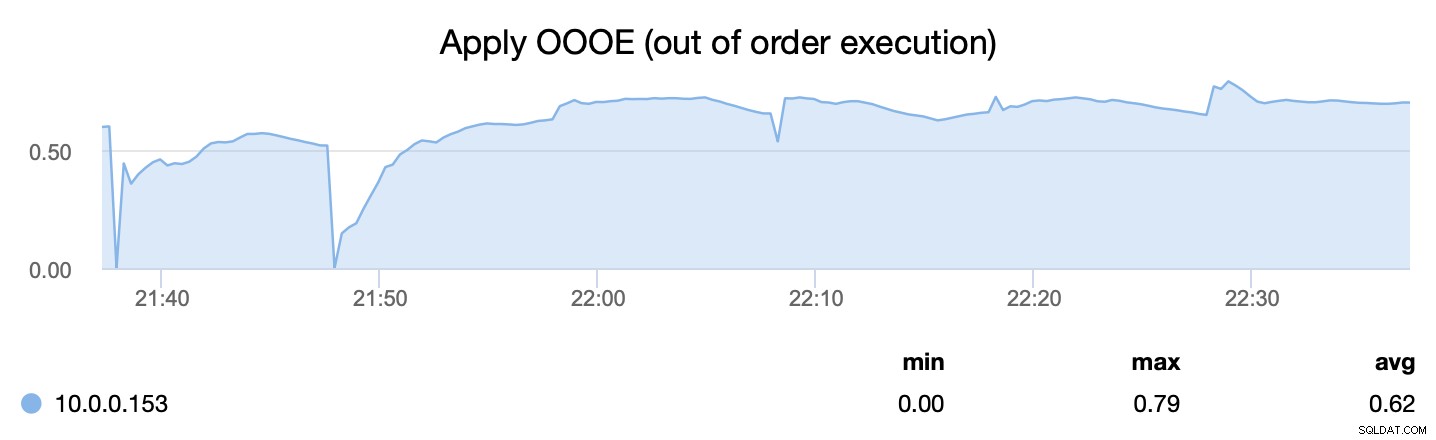
De tweede statistiek daarentegen vertelt ons hoe efficiënt we het proces van het toepassen van schrijfsets konden parallelliseren - wsrep_apply_oooe vertelt ons hoe vaak applier begon met het toepassen van schrijfsets in de verkeerde volgorde (wat wijst op een betere parallellisatie ).
Conclusie
Zoals u kunt zien, zijn er een aantal statistieken die het bekijken waard zijn in Percona XtraDB Cluster. Zoals we aan het begin van deze blog al zeiden, zijn dit natuurlijk statistieken die strikt verband houden met PXC en Galera Cluster in het algemeen.
U moet ook de reguliere MySQL- en InnoDB-statistieken in de gaten houden om een beter inzicht te krijgen in de status van uw database. En vergeet niet dat u deze technologie gratis kunt volgen met de ClusterControl Community Edition.