In deze blogpost gaan we kijken naar enkele belangrijke statistieken en status bij het bewaken van een Percona Server voor MySQL om ons te helpen de MySQL-serverconfiguratie voor een lange termijn te verfijnen. Voor de duidelijkheid:Percona Server heeft enkele monitoringstatistieken die alleen beschikbaar zijn op deze build. Bij vergelijking op versie 8.0.20 zijn de volgende 51 statussen alleen beschikbaar op Percona Server voor MySQL, die niet beschikbaar zijn in de upstream MySQL Community Server van Oracle:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Bekijk de Extended InnoDB Status-pagina voor meer informatie over elk van de bovenstaande monitoringstatistieken. Merk op dat een extra status zoals threadpool alleen beschikbaar is in Oracle's MySQL Enterprise. Bekijk de Percona Server voor MySQL 8.0-documentatie om alle verbeteringen te zien die specifiek voor deze build zijn gemaakt ten opzichte van Oracle's MySQL Community Server 8.0.
Gebruik een van de volgende instructies om de algemene MySQL-status op te halen:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Databasestatus en overzicht
We beginnen met de uptime-status, het aantal seconden dat de server actief is geweest.
Alle com_*-statussen zijn de statement-tellervariabelen die het aantal keren aangeven dat elke instructie is uitgevoerd. Er is één statusvariabele voor elk type instructie. Bijvoorbeeld, com_delete en com_update tellen respectievelijk DELETE- en UPDATE-instructies. De com_delete_multi en com_update_multi zijn vergelijkbaar, maar zijn van toepassing op DELETE- en UPDATE-instructies die syntaxis met meerdere tabellen gebruiken.
Om alle lopende processen van MySQL op te sommen, voert u gewoon een van de volgende instructies uit:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Verbindingen en schroefdraad
Huidige verbindingen
De verhouding van momenteel open verbindingen (verbindingsdraad). Als de verhouding hoog is, geeft dit aan dat er veel gelijktijdige verbindingen met de MySQL-server zijn en kan dit leiden tot de fout 'Te veel verbindingen'. Om het verbindingspercentage te krijgen:
Current connections(%) = (threads_connected / max_connections) x 100Een goede waarde moet 80% en lager zijn. Probeer de max_connections variabele te verhogen of inspecteer de verbindingen met SHOW FULL PROCESSLIST. Wanneer "Te veel verbindingen" fouten optreden, zal de MySQL-databaseserver niet meer beschikbaar zijn voor de niet-supergebruiker totdat er enkele verbindingen zijn vrijgemaakt. Merk op dat het verhogen van de variabele max_connections mogelijk ook de geheugenvoetafdruk van MySQL kan vergroten.
Maximale verbindingen ooit gezien
De verhouding van maximale verbindingen met de MySQL-server die ooit is gezien. Een eenvoudige berekening zou zijn:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100De goede waarde moet lager zijn dan 80%. Als de verhouding hoog is, geeft dit aan dat MySQL ooit een groot aantal verbindingen heeft bereikt, wat zou leiden tot een 'te veel verbindingen'-fout. Inspecteer de verhouding van de huidige verbindingen om te zien of deze inderdaad constant laag blijft. Verhoog anders de variabele max_connections. Controleer de max_used_connections_time-status om aan te geven wanneer de max_used_connections-status zijn huidige waarde heeft bereikt.
Hitpercentage voor threadcache
De status van threads_created is het aantal threads dat is gemaakt om verbindingen af te handelen. Als de threads_created groot is, wilt u misschien de waarde thread_cache_size verhogen. Het hit/miss-percentage van de cache kan als volgt worden berekend:
Threads cache hit rate (%) = (threads_created / connections) x 100Het is een breuk die een indicatie geeft van de hitrate van de threadcache. Hoe dichterbij minder dan 50%, hoe beter. Als uw server honderden verbindingen per seconde ziet, moet u thread_cache_size normaal zo hoog instellen dat de meeste nieuwe verbindingen gecachte threads gebruiken.
Queryprestaties
Volledige tabelscans
De verhouding van volledige tabelscans, een bewerking waarbij de volledige inhoud van een tabel moet worden gelezen in plaats van alleen geselecteerde delen met behulp van een index. Deze waarde is hoog als u veel query's uitvoert waarvoor het sorteren van resultaten of tabelscans vereist is. Over het algemeen suggereert dit dat tabellen niet correct zijn geïndexeerd of dat uw zoekopdrachten niet zijn geschreven om te profiteren van de indexen die u heeft. Om het percentage volledige tafelscans te berekenen:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100De goede waarde moet lager zijn dan 25%. Bekijk de MySQL trage query log output om de suboptimale queries te achterhalen.
Volledige deelname selecteren
De status van select_full_join is het aantal joins dat tabelscans uitvoert omdat ze geen indexen gebruiken. Als deze waarde niet 0 is, moet u de indexen van uw tabellen zorgvuldig controleren.
Selecteer bereikcontrole
De status van select_range_check is het aantal joins zonder sleutels die het sleutelgebruik na elke rij controleren. Als dit niet 0 is, moet u de indexen van uw tabellen zorgvuldig controleren.
Passen sorteren
De verhouding van samenvoegpassages die het sorteeralgoritme heeft moeten doen. Als deze waarde hoog is, kunt u overwegen de waarde van sort_buffer_size en read_rnd_buffer_size te verhogen. Een eenvoudige verhoudingsberekening is:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Een verhoudingswaarde lager dan 3 zou een goede waarde moeten zijn. Als u de sort_buffer_size of read_rnd_buffer_size wilt vergroten, probeer dan in kleine stappen te verhogen totdat u de acceptabele verhouding bereikt.
InnoDB-prestaties
InnoDB Buffer Pool Hit Rate
De verhouding van hoe vaak uw pagina's uit het geheugen worden opgehaald in plaats van uit de schijf. Als de waarde laag is tijdens het vroege opstarten van MySQL, wacht dan even totdat de bufferpool is opgewarmd. Gebruik de instructie SHOW ENGINE INNODB STATUS om de hitrate van de bufferpool te krijgen:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...De beste waarde is 1000/10000 treffers. Voor een lagere waarde, bijvoorbeeld, geeft de hitrate van 986 / 1000 aan dat van de 1000 gelezen pagina's, het in staat was om pagina's in RAM 986 keer te lezen. De overige 14 keer moest MySQL de pagina's van schijf lezen. Simpel gezegd, 1000 / 1000 is de beste waarde die we hier proberen te bereiken, wat betekent dat de veelgebruikte gegevens volledig in het RAM passen.
Het verhogen van de variabele innodb_buffer_pool_size zal veel helpen om meer ruimte te creëren voor MySQL om aan te werken. Zorg er echter van tevoren voor dat u over voldoende RAM-bronnen beschikt. Het verwijderen van overtollige indexen kan ook helpen. Als je meerdere bufferpoolinstanties hebt, zorg er dan voor dat de hitrate voor elke instantie 1000 / 1000 bereikt.
InnoDB vuile pagina's
De verhouding van hoe vaak InnoDB moet worden gespoeld. Tijdens de schrijfzware belasting is het normaal dat dit percentage stijgt.
Een eenvoudige berekening zou zijn:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Een goede waarde moet 75% en lager zijn. Als het percentage vuile pagina's lange tijd hoog blijft, wilt u misschien de bufferpool vergroten of snellere schijven aanschaffen om prestatieknelpunten te voorkomen.
InnoDB wacht op controlepunt
De verhouding van hoe vaak InnoDB een pagina moet lezen of maken waar geen schone pagina's beschikbaar zijn. Normaal gesproken gebeurt het schrijven naar de InnoDB-bufferpool op de achtergrond. Als het echter nodig is om een pagina te lezen of aan te maken en er zijn geen schone pagina's beschikbaar, moet u ook wachten tot de pagina's eerst worden leeggemaakt. De innodb_buffer_pool_wait_free teller telt hoe vaak dit is gebeurd. Om de verhouding van InnoDB wacht op checkpointing te berekenen, kunnen we de volgende berekening gebruiken:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsAls innodb_buffer_pool_wait_free groter is dan 0, is dit een sterke aanwijzing dat de InnoDB-bufferpool te klein is en dat operaties moesten wachten op een controlepunt. Het vergroten van de innodb_buffer_pool_size zal meestal de innodb_buffer_pool_wait_free verlagen, evenals deze verhouding. Een goede verhoudingswaarde moet onder de 1 blijven.
InnoDB wacht op opnieuw inloggen
De verhouding van redo log-conflicten. Controleer innodb_log_waits en als het blijft toenemen, verhoog dan de innodb_log_buffer_size. Het kan ook betekenen dat de schijven te traag zijn en de schijf-IO niet kunnen ondersteunen, misschien vanwege de piekschrijfbelasting. Gebruik de volgende berekening om de wachtratio voor opnieuw loggen te berekenen:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesEen goede verhoudingswaarde moet lager zijn dan 1. Vergroot anders de innodb_log_buffer_size.
Tafels
Gebruik van tabelcache
De verhouding van het gebruik van de tabelcache voor alle threads. Een eenvoudige berekening zou zijn:
Table cache usage(%) = (opened_tables / table_open_cache) x 100De goede waarde moet minder dan 80% zijn. Verhoog de variabele table_open_cache totdat het percentage een goede waarde bereikt.
Table Cache Hit Ratio
De verhouding van het hitgebruik in de tabelcache. Een eenvoudige berekening zou zijn:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Een goede hitratio moet 90% en hoger zijn. Verhoog anders de variabele table_open_cache totdat de hitratio een goede waarde bereikt.
Metrische controle met ClusterControl
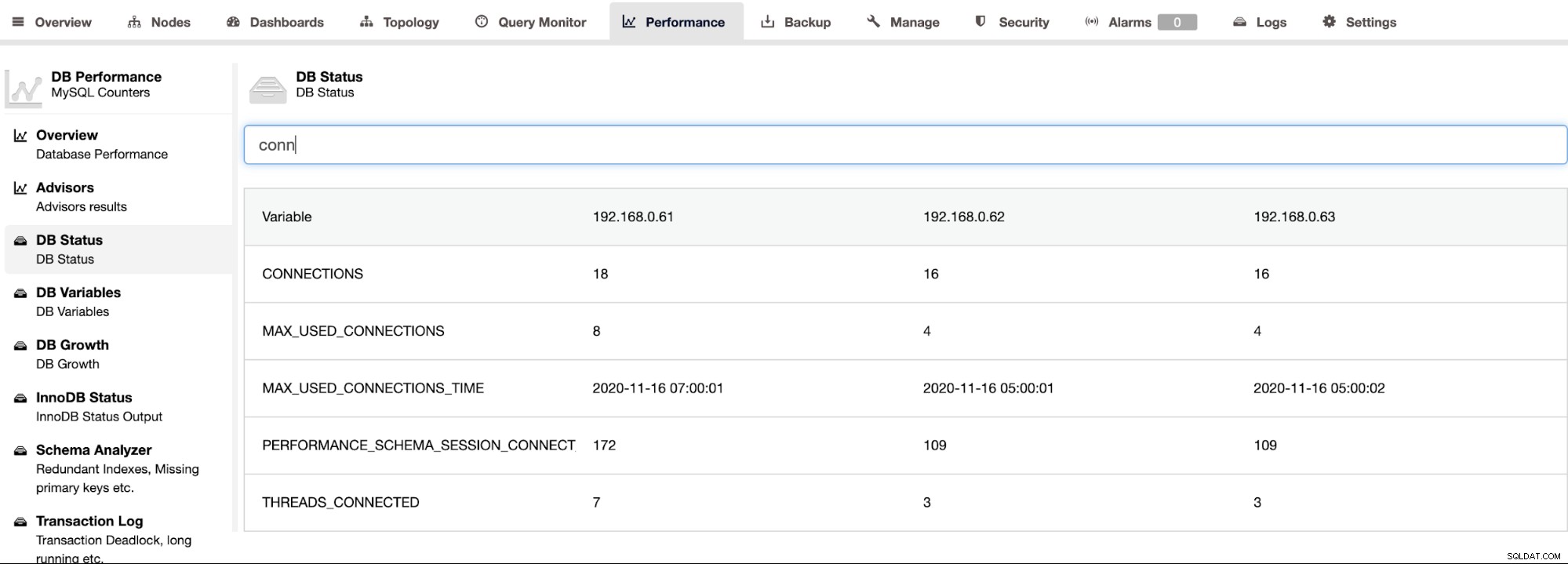
ClusterControl ondersteunt Percona Server voor MySQL en biedt een geaggregeerde weergave van alle knooppunten in een cluster op de pagina ClusterControl -> Prestaties -> DB-status. Dit biedt een gecentraliseerde aanpak om alle status op alle hosts op te zoeken met de mogelijkheid om de status te filteren, zoals weergegeven in de volgende schermafbeelding:
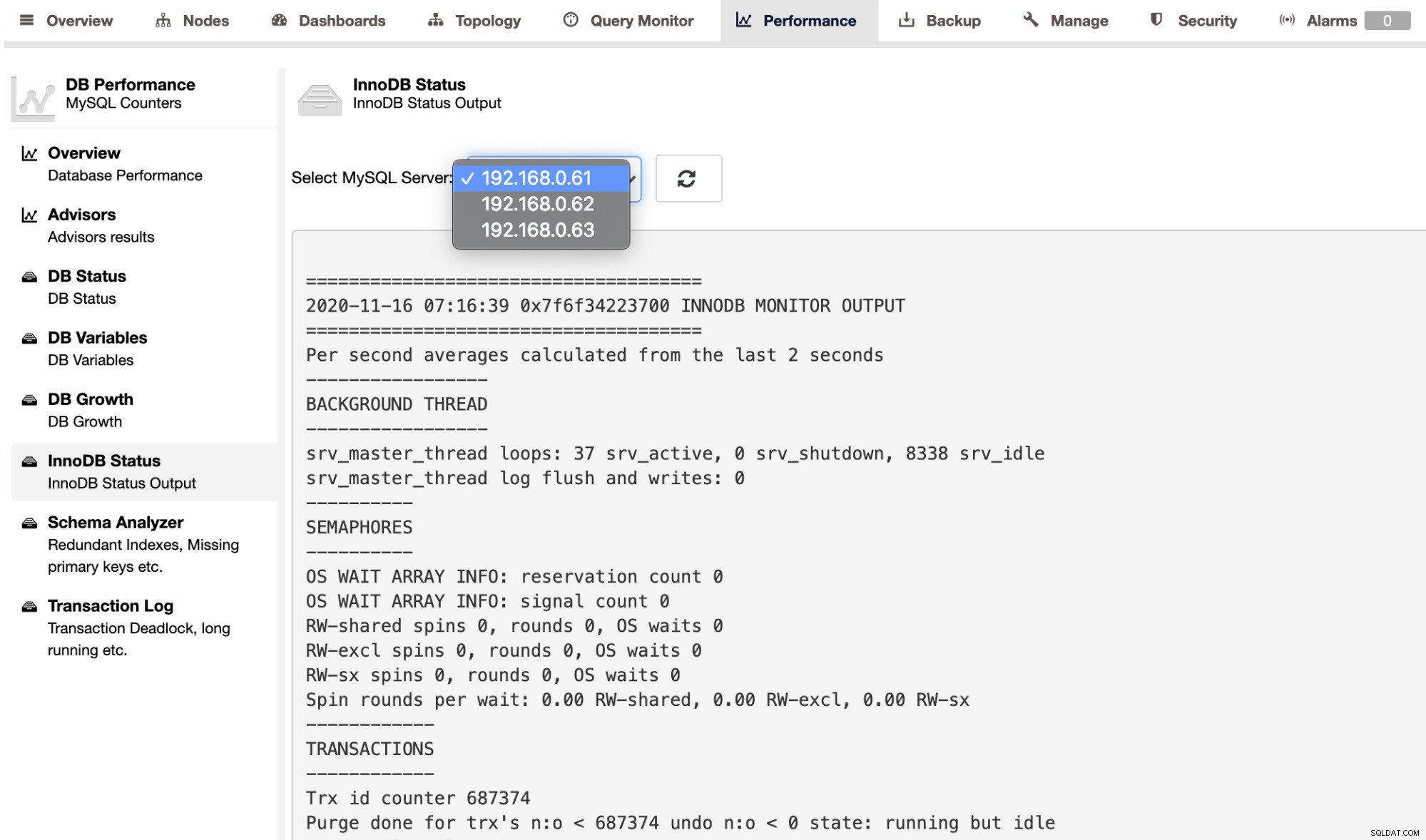
Als u de SHOW ENGINE INNODB STATUS-uitvoer voor een individuele server wilt ophalen, kunt u gebruik de pagina Performance -> InnoDB Status, zoals hieronder weergegeven:
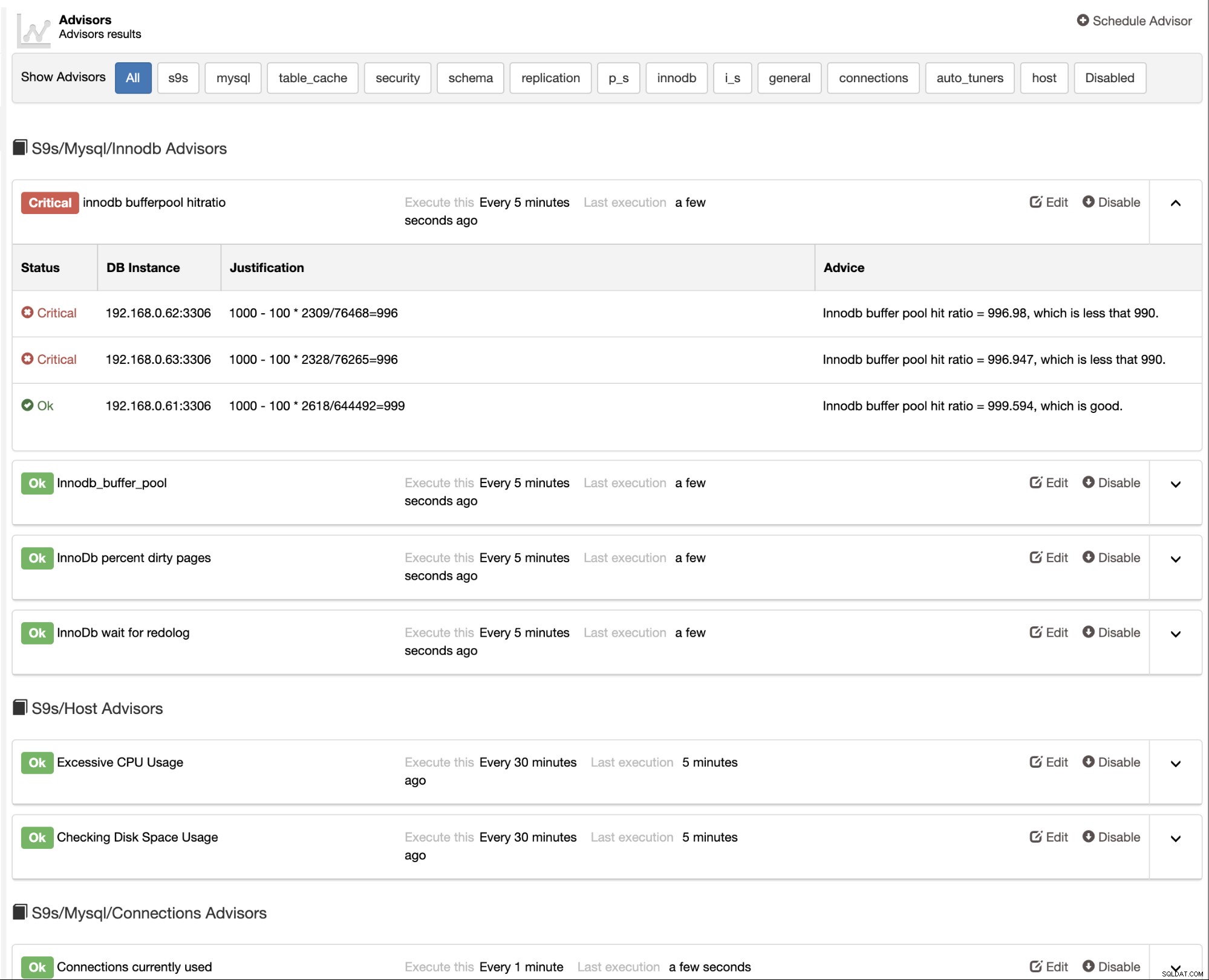
ClusterControl biedt ook ingebouwde adviseurs die u kunt gebruiken om uw database bij te houden uitvoering. Deze functie is toegankelijk onder ClusterControl -> Prestaties -> Adviseurs:
Advisors zijn in feite miniprogramma's die door ClusterControl worden uitgevoerd in een geplande timing zoals cron banen. U kunt een adviseur plannen door op de knop "Adviseur plannen" te klikken en een bestaande adviseur uit de Developer Studio-objectstructuur te kiezen:
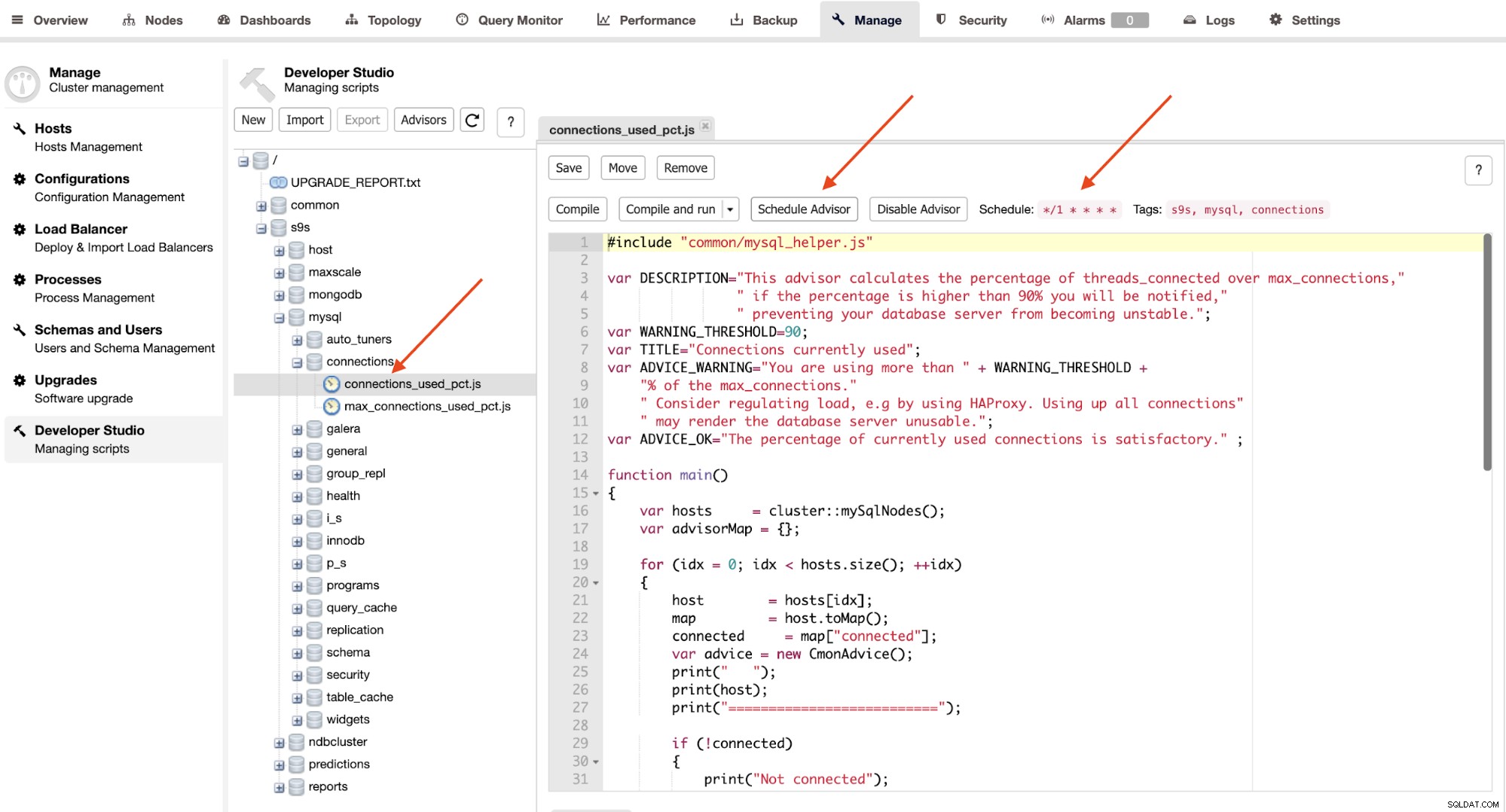
Klik op de knop "Schedule Advisor" om de planning in te stellen, argument op pas en ook de tags van de adviseur. U kunt de adviseur ook compileren om de uitvoer onmiddellijk te zien door op de knop "Compileren en uitvoeren" te klikken, waar u de volgende uitvoer zou moeten zien onder de "Berichten" eronder:

U kunt uw eigen adviseur maken door deze handleiding voor ontwikkelaars te raadplegen, geschreven in ClusterControl Domain Specific Language (zeer vergelijkbaar met Javascript), of pas een bestaande adviseur aan uw monitoringbeleid aan. Kortom, de monitoringtaak van ClusterControl kan worden uitgebreid met onbeperkte mogelijkheden via ClusterControl Advisors.