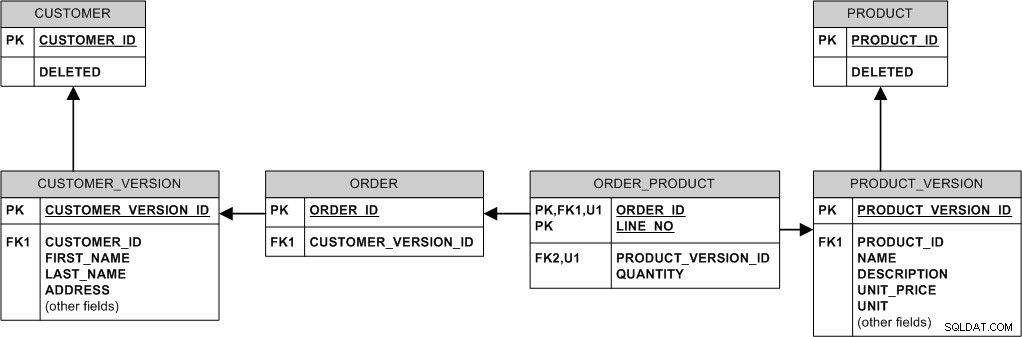
Hier is een manier om het te doen:
In wezen wijzigen of verwijderen we de bestaande gegevens nooit. We "wijzigen" het door een nieuwe versie te maken. We "verwijderen" het door de markering VERWIJDERD in te stellen.
Bijvoorbeeld:
- Als het product de prijs wijzigt, voegen we een nieuwe rij toe aan PRODUCT_VERSION terwijl oude bestellingen gekoppeld blijven aan de oude PRODUCT_VERSION en de oude prijs.
- Als de koper het adres wijzigt, voegen we eenvoudig een nieuwe rij in CUSTOMER_VERSION in en koppelen we nieuwe bestellingen daaraan, terwijl de oude bestellingen aan de oude versie worden gekoppeld.
- Als een product is verwijderd, verwijderen we het niet echt - we stellen gewoon de markering PRODUCT.DELETED in, zodat alle bestellingen die in het verleden voor dat product zijn gedaan, in de database blijven.
- Als de klant is verwijderd (bijvoorbeeld omdat hij/zij heeft verzocht om uitgeschreven te worden), stelt u de vlag CUSTOMER.DELETED in.
Waarschuwingen:
- Als de productnaam uniek moet zijn, kan dat niet declaratief worden afgedwongen in het bovenstaande model. Je moet ofwel de NAAM "promoten" van PRODUCT_VERSION naar PRODUCT, er een sleutel van maken en de mogelijkheid opgeven om de naam van het product te "evolueren", of uniciteit afdwingen op alleen de nieuwste PRODUCT_VER (waarschijnlijk via triggers).
- Er is een mogelijk probleem met de privacy van de klant. Als een klant uit het systeem wordt verwijderd, kan het wenselijk zijn om zijn gegevens fysiek uit de database te verwijderen en alleen het instellen van CUSTOMER.DELETED zal dat niet doen. Als dat een probleem is, verwijder dan ofwel de privacygevoelige gegevens in alle versies van de klant, of koppel bestaande bestellingen los van de echte klant en koppel ze opnieuw aan een speciale "anonieme" klant, en verwijder vervolgens fysiek alle klantversies.
Dit model gebruikt veel identificerende relaties. Dit leidt tot "dikke" externe sleutels en kan een beetje een opslagprobleem zijn, aangezien MySQL geen geavanceerde indexcompressie ondersteunt (in tegenstelling tot bijvoorbeeld Oracle), maar aan de andere kant InnoDB altijd clustert de gegevens op PK en deze clustering kan gunstig zijn voor de prestaties. Ook zijn JOINs minder nodig.
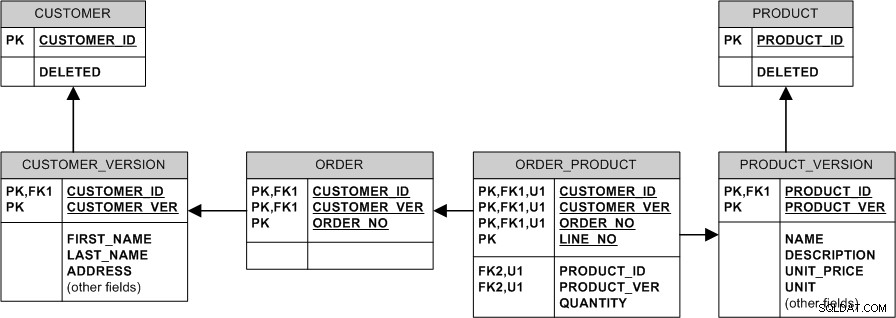
Equivalent model met niet-identificerende relaties en surrogaatsleutels ziet er als volgt uit: