Een paar weken geleden schreef ik over hoe verbaasd ik was over de prestaties van een nieuwe native functie in SQL Server 2016, STRING_SPLIT() :
- Prestatieverrassingen en aannames:STRING_SPLIT()
Nadat het bericht was gepubliceerd, kreeg ik een paar opmerkingen (openbaar en privé) met deze suggesties (of vragen die ik in suggesties heb omgezet):
- Een expliciet uitvoergegevenstype specificeren voor de JSON-aanpak, zodat die methode geen last heeft van mogelijke prestatieoverhead als gevolg van de fallback van
nvarchar(max). - Een iets andere aanpak testen, waarbij er daadwerkelijk iets met de gegevens wordt gedaan – namelijk
SELECT INTO #temp. - Toon hoe het geschatte aantal rijen zich verhoudt tot bestaande methoden, met name bij het nesten van gesplitste bewerkingen.
Ik heb wel op sommige mensen offline gereageerd, maar dacht dat het de moeite waard zou zijn om hier een vervolg te plaatsen.
Eerlijker zijn voor JSON
De originele JSON-functie zag er als volgt uit, zonder specificatie voor het type uitvoergegevens:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Ik heb het hernoemd en er nog twee gemaakt, met de volgende definities:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Ik dacht dat dit de prestaties drastisch zou verbeteren, maar helaas was dit niet het geval. Ik heb de tests opnieuw uitgevoerd en de resultaten waren als volgt:
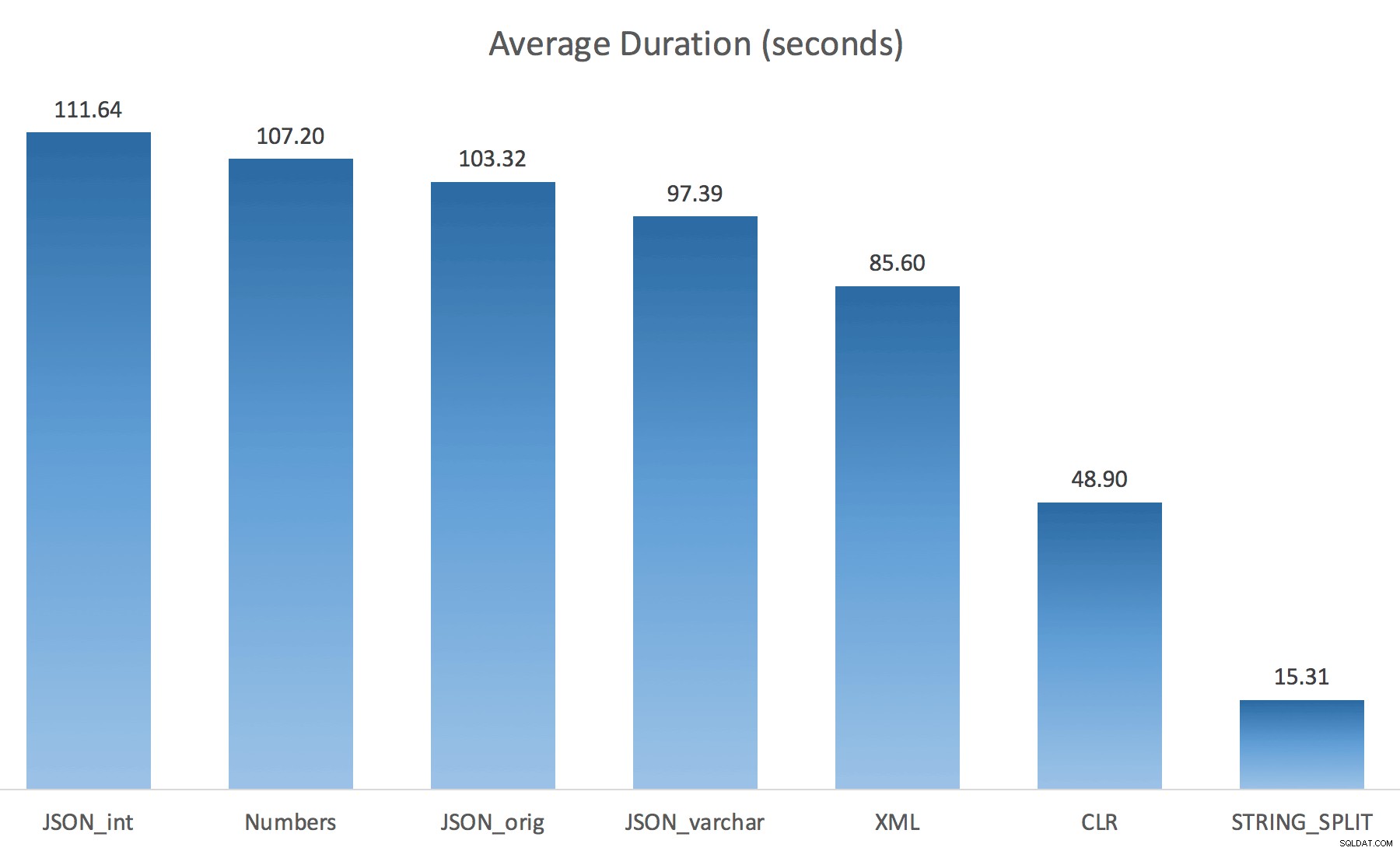
De wachttijden die zijn waargenomen tijdens een willekeurig exemplaar van de test (gefilterd op die> 25):
| CLR | IO_COMPLETION | 1.595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6.294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4.307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6.110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Cijfers | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1.917 |
| IO_COMPLETION | 1.616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Wachten waargenomen> 25 (let op:er is geen invoer voor STRING_SPLIT )
Bij het wijzigen van de standaardinstelling naar varchar(100) heeft de prestaties een beetje verbeterd, de winst was verwaarloosbaar en veranderde naar int maakte het eigenlijk nog erger. Voeg hieraan toe dat je waarschijnlijk STRING_ESCAPE() . moet toevoegen in sommige scenario's naar de inkomende tekenreeks, voor het geval ze tekens hebben die de JSON-parsering verpesten. Mijn conclusie is nog steeds dat dit een nette manier is om de nieuwe JSON-functionaliteit te gebruiken, maar vooral een nieuwigheid die niet geschikt is voor een redelijke schaal.
De uitvoer materialiseren
Jonathan Magnan maakte deze scherpzinnige observatie op mijn vorige bericht:
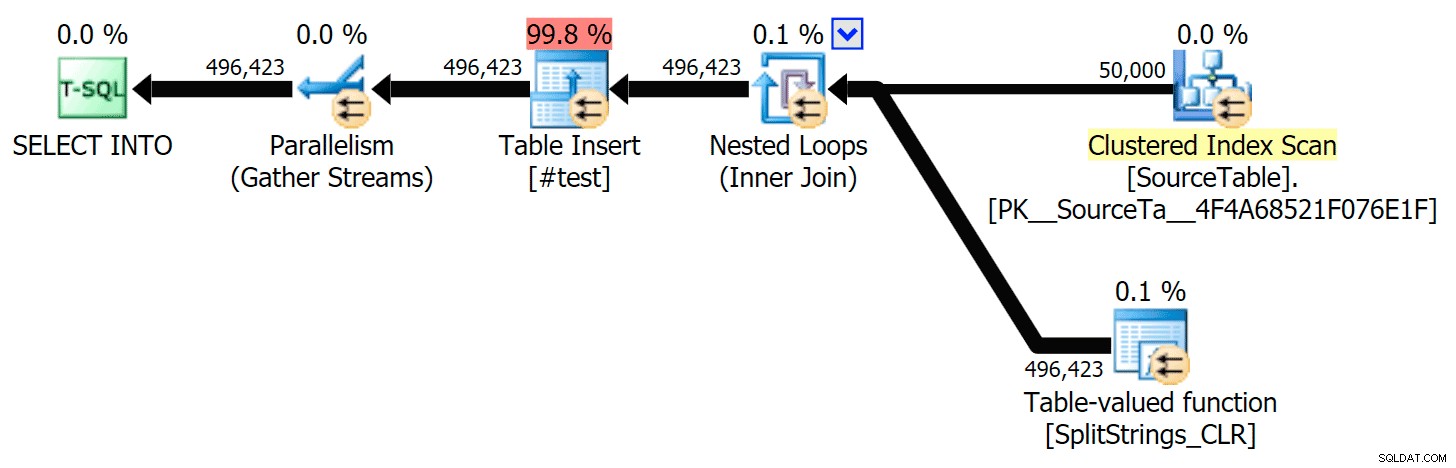
STRING_SPLIT is inderdaad erg snel, maar ook traag als je met een tijdelijke tabel werkt (tenzij het in een toekomstige build wordt gerepareerd).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Zal VEEL langzamer zijn dan de SQL CLR-oplossing (15x en meer!).
Dus ik groef erin. Ik maakte code die elk van mijn functies zou aanroepen en de resultaten in een #temp-tabel zou dumpen, en ze zou timen:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
Ik heb elke test slechts één keer uitgevoerd (in plaats van 100 keer te herhalen), omdat ik de I/O op mijn systeem niet volledig wilde vernietigen. Toch had Jonathan, na een gemiddelde van drie testritten, absoluut 100% gelijk. Dit waren de duur van het vullen van een #temp-tabel met ~500.000 rijen met elke methode:
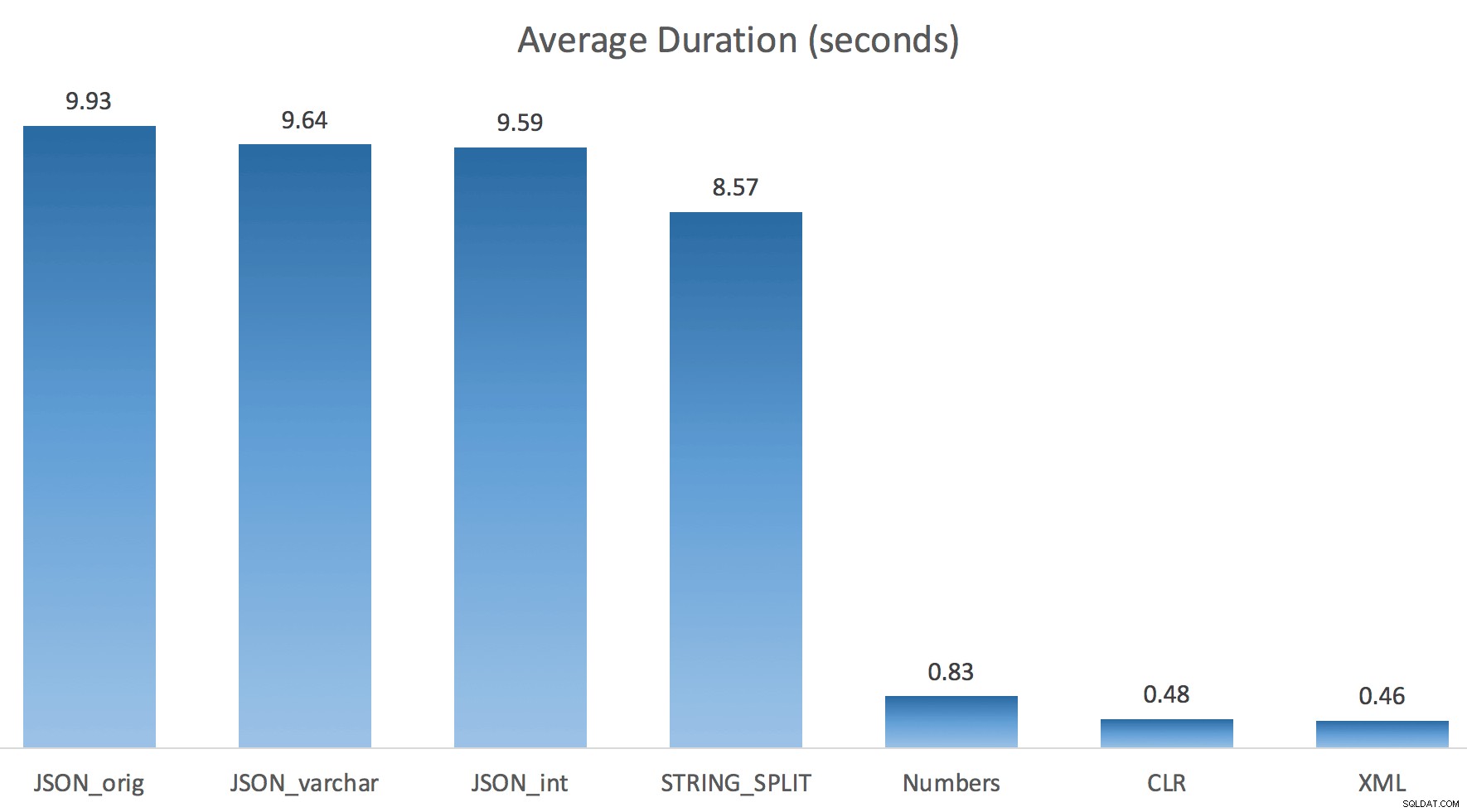
Dus hier, de JSON en STRING_SPLIT methoden namen elk ongeveer 10 seconden in beslag, terwijl de Numbers-tabel, CLR en XML-benaderingen minder dan een seconde duurden. Verbijsterd onderzocht ik de wachttijden, en ja hoor, de vier methoden aan de linkerkant leverden aanzienlijke LATCH_EX op wacht (ongeveer 25 seconden) niet gezien in de andere drie, en er waren geen andere significante wachttijden om van te spreken.
En aangezien de vergrendelingswachttijden groter waren dan de totale duur, gaf het me een idee dat dit te maken had met parallellisme (deze specifieke machine heeft 4 kernen). Dus ik heb opnieuw testcode gegenereerd, waarbij ik slechts één regel veranderde om te zien wat er zou gebeuren zonder parallellisme:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Nu STRING_SPLIT deed het een stuk beter (net als de JSON-methoden), maar nog steeds minstens het dubbele van de tijd die CLR in beslag nam:
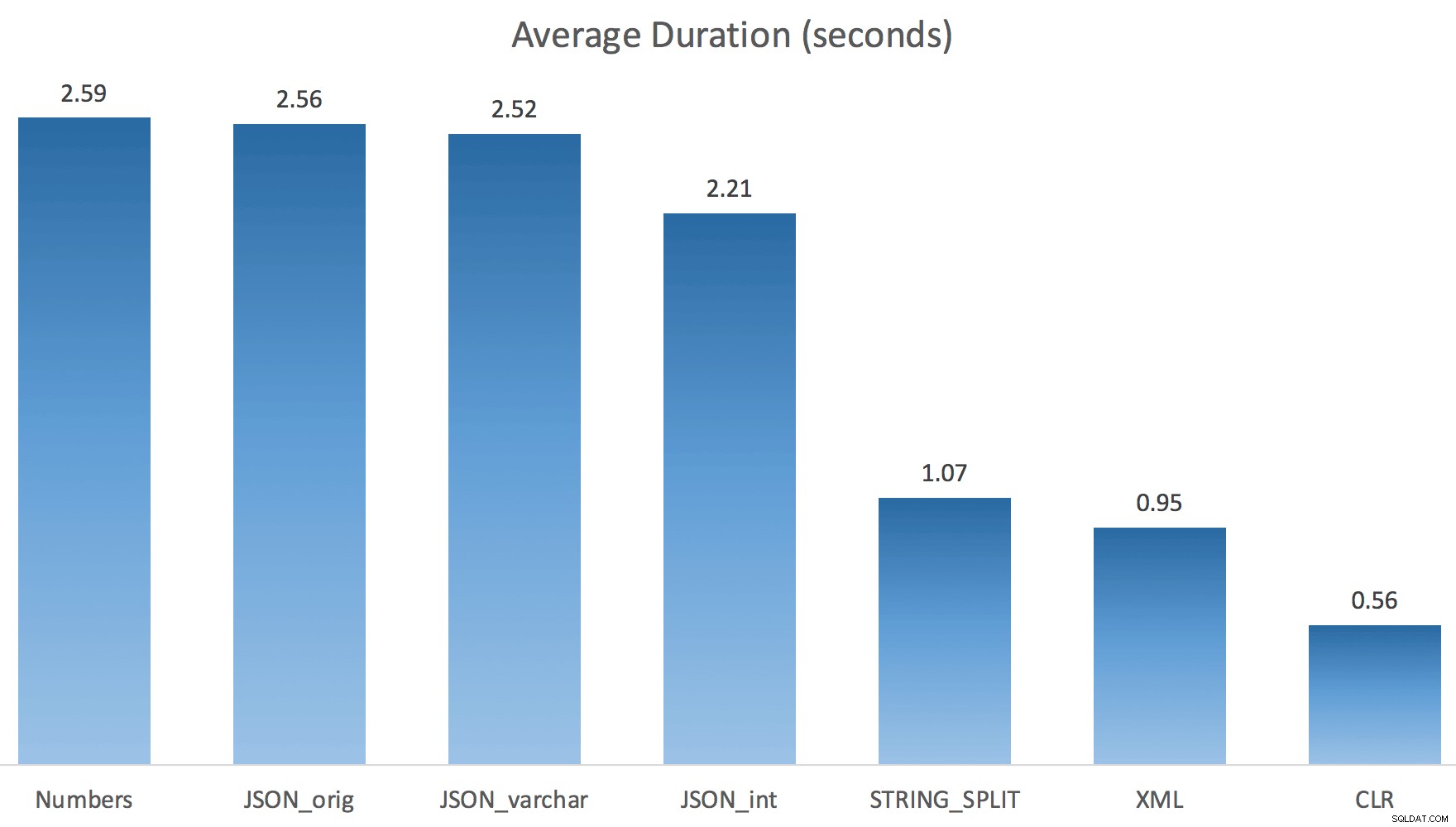
Er kan dus een probleem blijven bestaan bij deze nieuwe methoden als er sprake is van parallellisme. Het was geen probleem met de distributie van threads (ik heb dat gecontroleerd) en CLR had zelfs slechtere schattingen (100x werkelijk versus slechts 5x voor STRING_SPLIT ); gewoon een onderliggend probleem met het coördineren van vergrendelingen tussen threads, veronderstel ik. Voor nu kan het de moeite waard zijn om MAXDOP 1 . te gebruiken als u weet dat u de uitvoer naar nieuwe pagina's schrijft.
Ik heb de grafische plannen bijgevoegd die de CLR-benadering vergelijken met de oorspronkelijke, voor zowel parallelle als seriële uitvoering (ik heb ook een Query-analysebestand geüpload dat u kunt openen in SQL Sentry Plan Explorer om zelf rond te snuffelen):
STRING_SPLIT
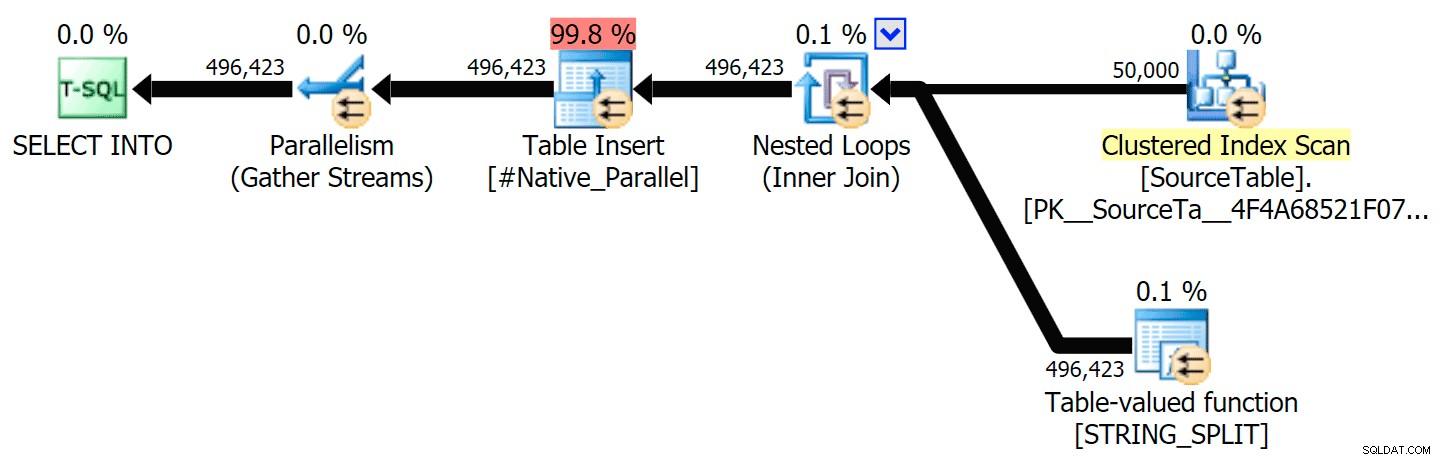
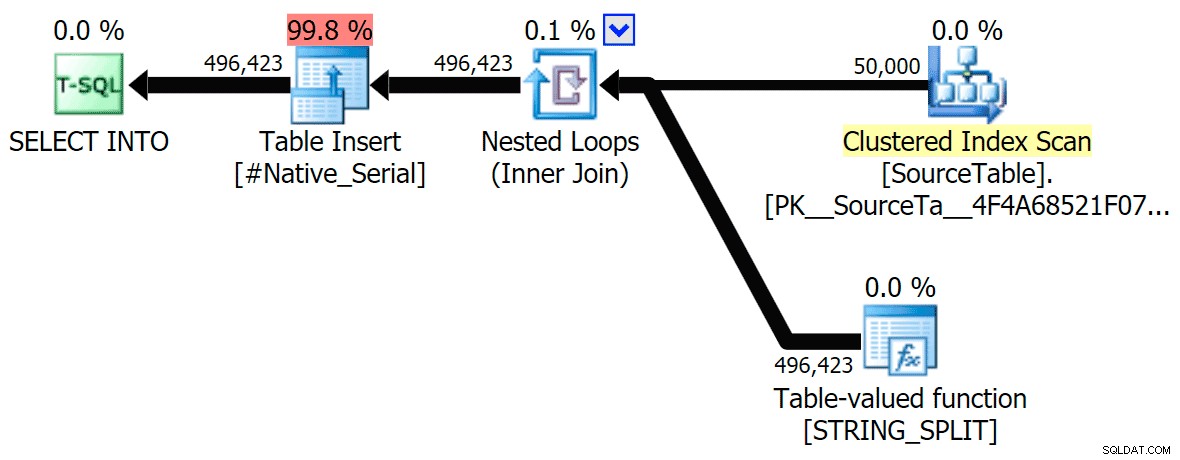
CLR
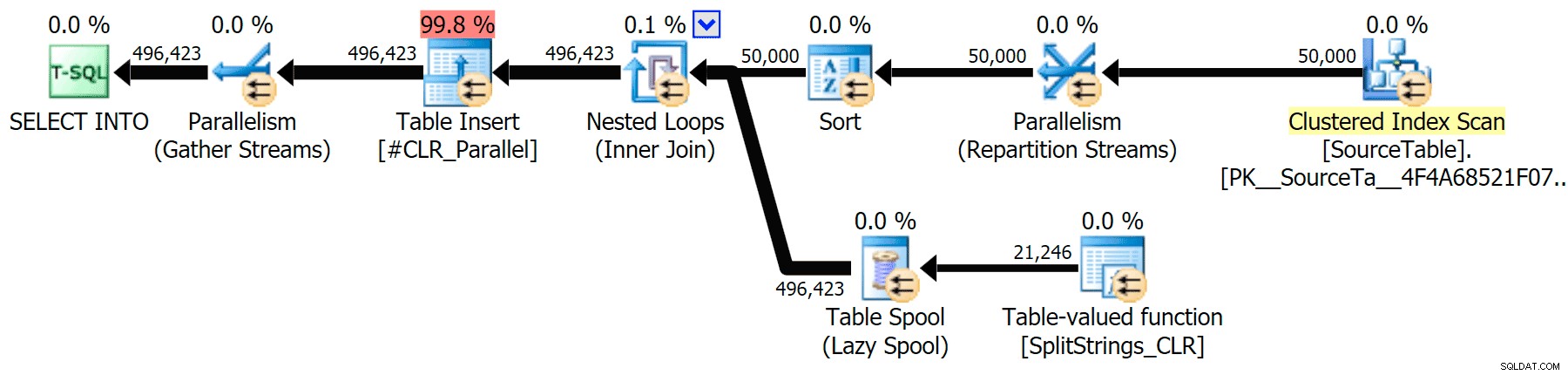
De soortwaarschuwing, ter informatie, was niet al te schokkend en had duidelijk niet veel tastbaar effect op de duur van de zoekopdracht:

- StringSplit.queryanalysis.zip (25kb)
Wordt klaar voor de zomer
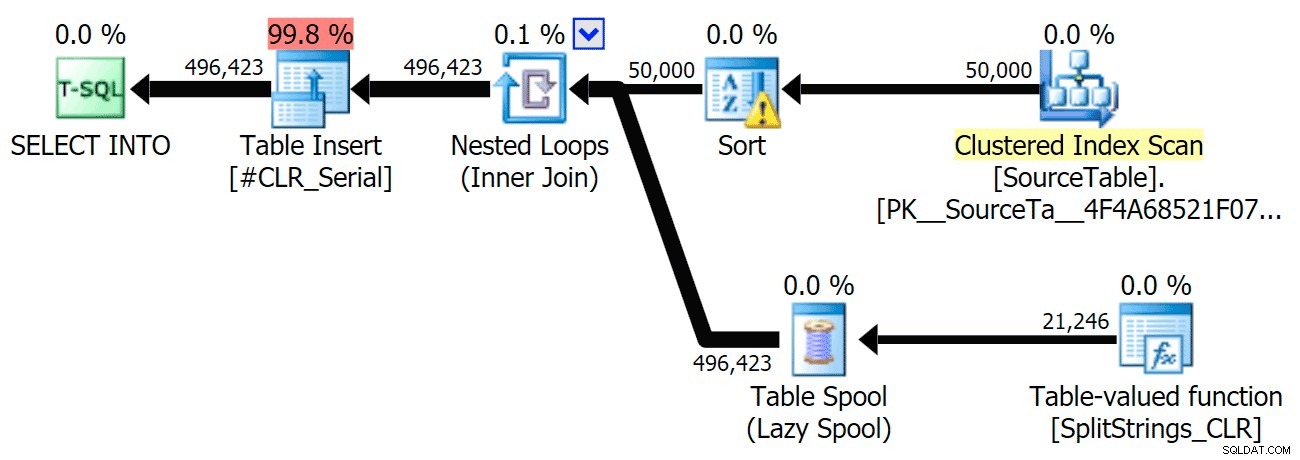
Toen ik die plannen wat beter bekeek, merkte ik dat er in het CLR-plan een luie spoel zit. Dit is geïntroduceerd om ervoor te zorgen dat duplicaten samen worden verwerkt (om werk te besparen door minder daadwerkelijk te splitsen), maar deze spoel is niet altijd mogelijk in alle planvormen, en het kan een voordeel geven aan degenen die het kunnen gebruiken ( bijvoorbeeld het CLR-plan), afhankelijk van schattingen. Om zonder spoelen te vergelijken, heb ik traceringsvlag 8690 ingeschakeld en de tests opnieuw uitgevoerd. Ten eerste is hier het parallelle CLR-plan zonder de spoel:
En hier waren de nieuwe duur voor alle zoekopdrachten die parallel gingen met TF 8690 ingeschakeld:
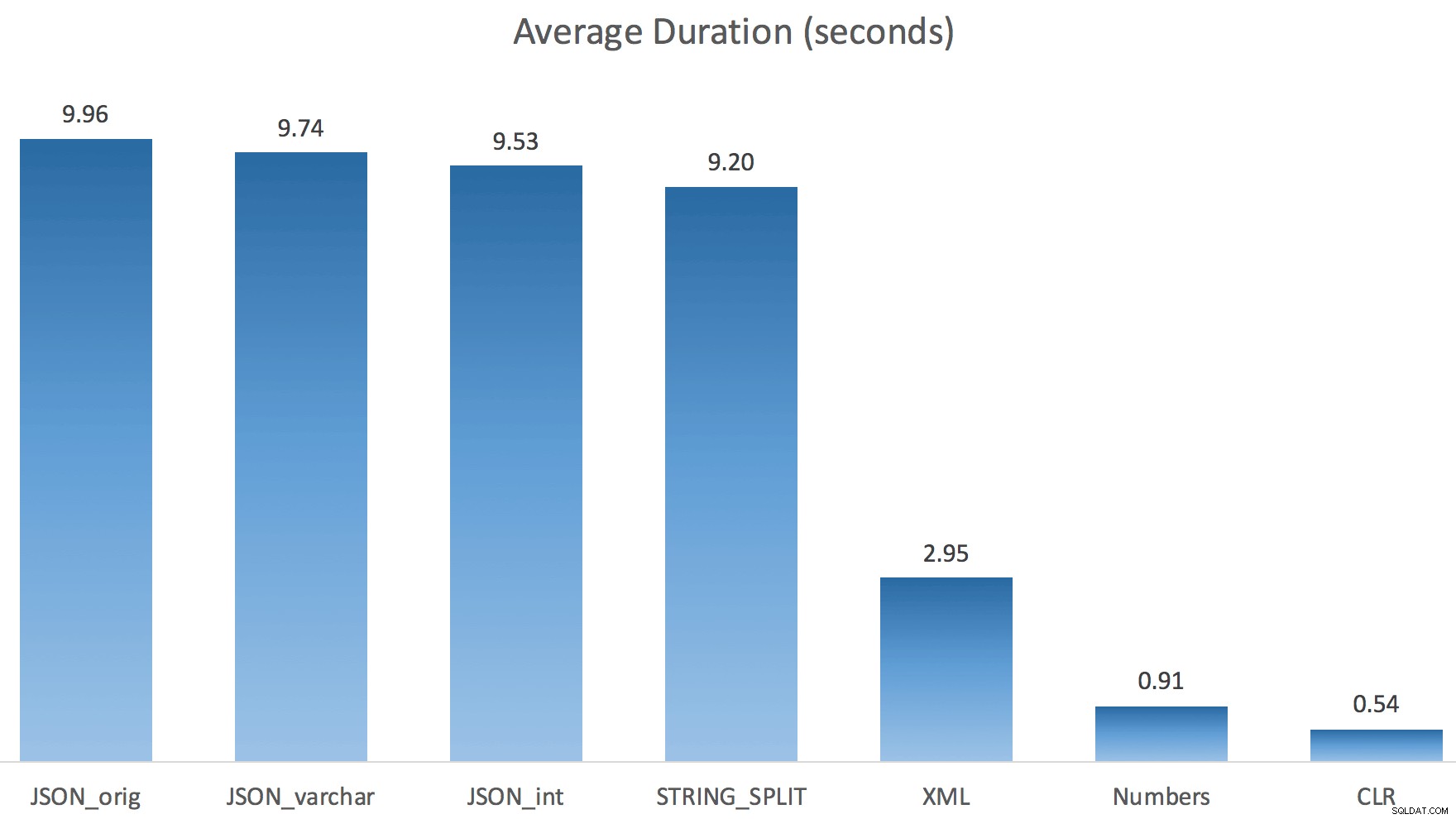
Hier is het seriële CLR-plan zonder de spoel:
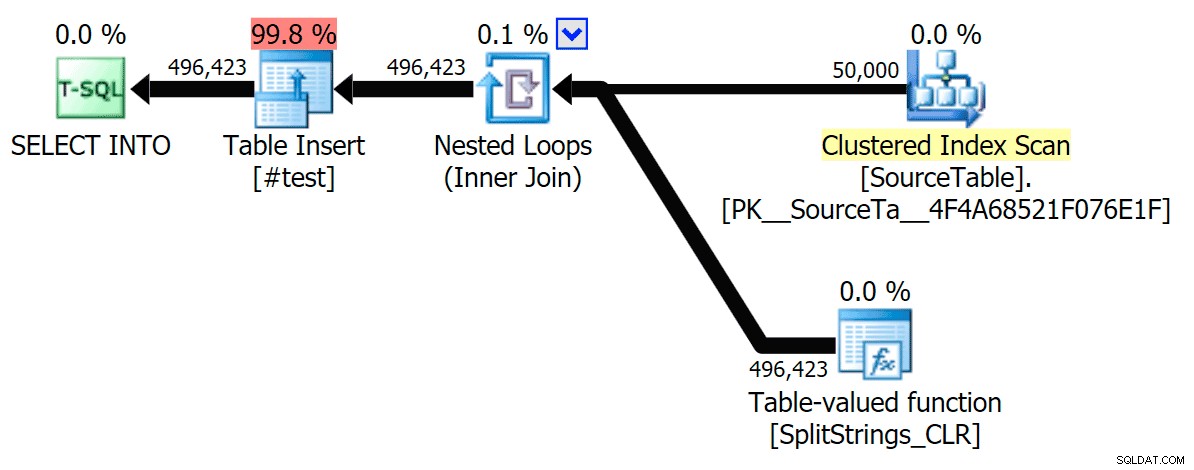
En hier waren de timingresultaten voor zoekopdrachten met zowel TF 8690 als MAXDOP 1 :
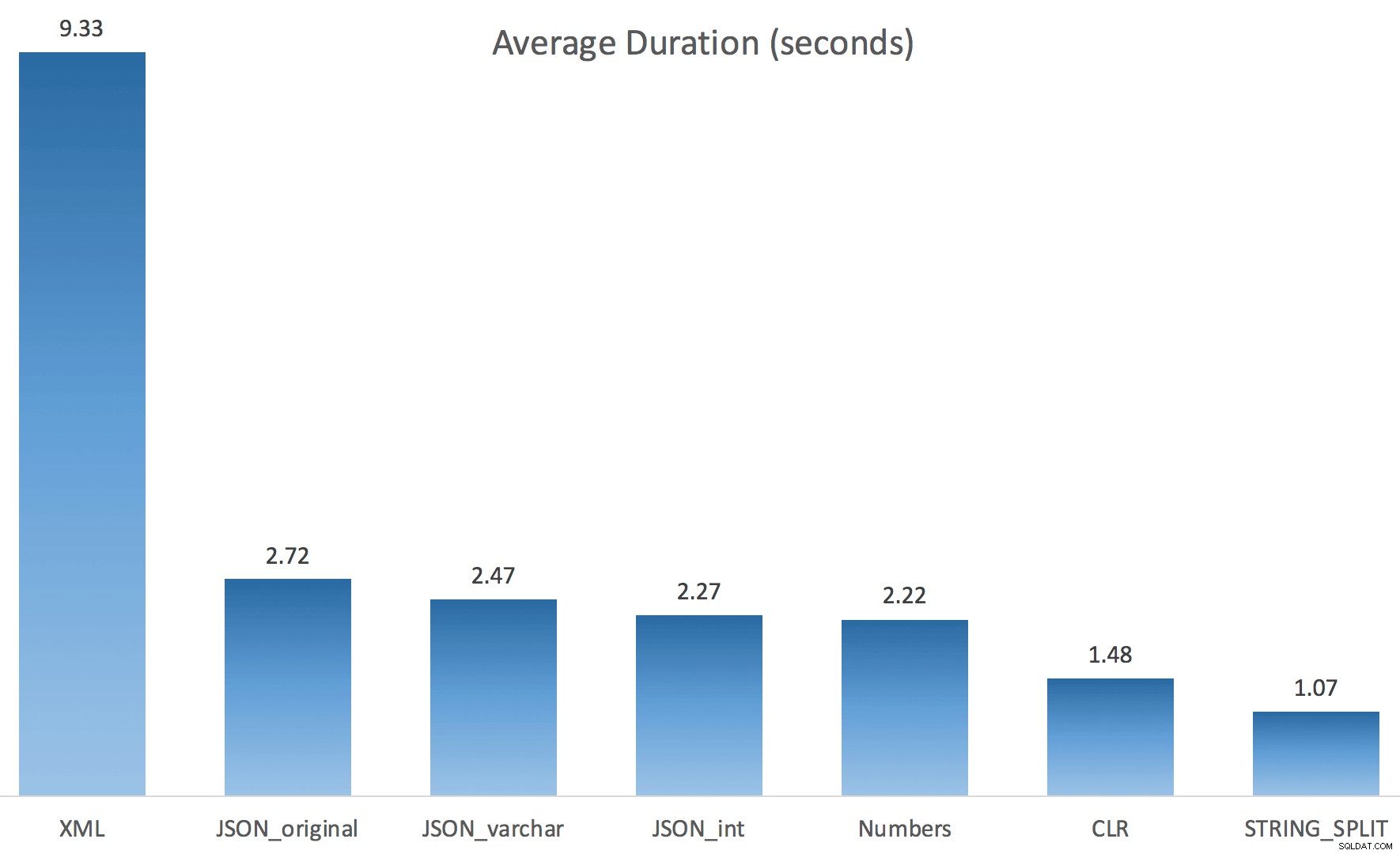
(Merk op dat, afgezien van het XML-plan, de meeste andere helemaal niet zijn gewijzigd, met of zonder de traceringsvlag.)
Geschat aantal rijen vergelijken
Dan Holmes stelde de volgende vraag:
Hoe schat het de gegevensgrootte wanneer het wordt samengevoegd met een andere (of meerdere) splitfunctie? De onderstaande link is een beschrijving van een op CLR gebaseerde gesplitste implementatie. Doet de 2016 het 'beter' met gegevensschattingen? (helaas heb ik nog geen mogelijkheid om de RC te installeren).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Dus ik heb de code uit het bericht van Dan gehaald, gewijzigd om mijn functies te gebruiken en door Plan Explorer te laten lopen:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
De SPLIT_STRING aanpak levert zeker *betere* schattingen op dan CLR, maar nog steeds ruimschoots voorbij (in dit geval, wanneer de string leeg is; dit is misschien niet altijd het geval). De functie heeft een ingebouwde standaard die schat dat de inkomende string 50 elementen zal hebben, dus als je ze nest, krijg je 50 x 50 (2.500); als je ze weer nest, 50 x 2.500 (125.000); en dan tot slot, 50 x 125.000 (6.250.000):
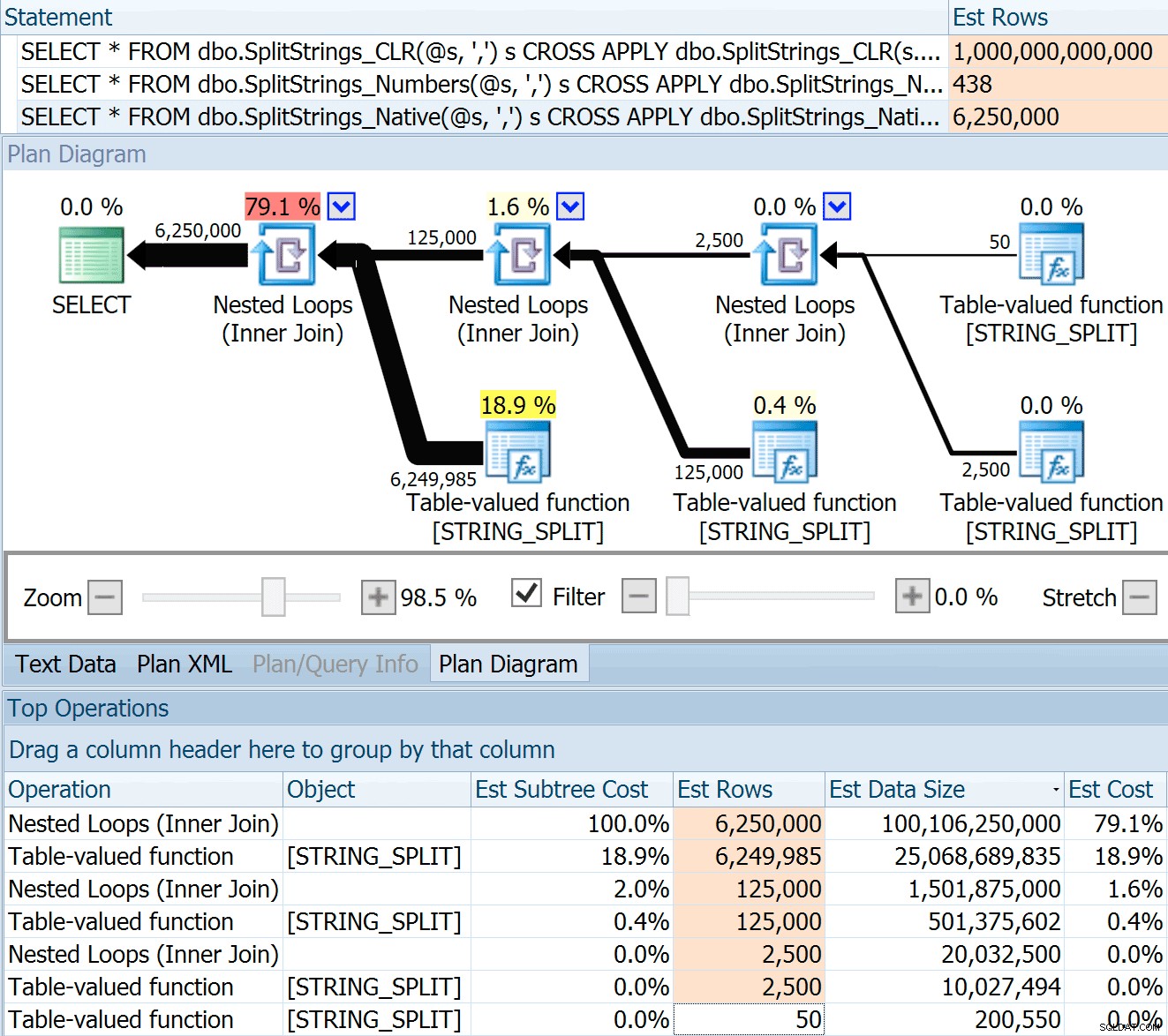
Opmerking:OPENJSON() gedraagt zich exact hetzelfde als STRING_SPLIT - het gaat er ook van uit dat er 50 rijen uit een bepaalde splitsingsbewerking zullen komen. Ik denk dat het nuttig kan zijn om een manier te hebben om kardinaliteit te hinten voor functies als deze, naast traceervlaggen zoals 4137 (pre-2014), 9471 &9472 (2014+), en natuurlijk 9481…
Deze schatting van 6,25 miljoen rijen is niet geweldig, maar het is veel beter dan de CLR-benadering waar Dan het over had, die schat EEN TRILJOEN RIJEN , en ik ben de tel kwijtgeraakt van de komma's om de gegevensgrootte te bepalen - 16 petabytes? exabytes?
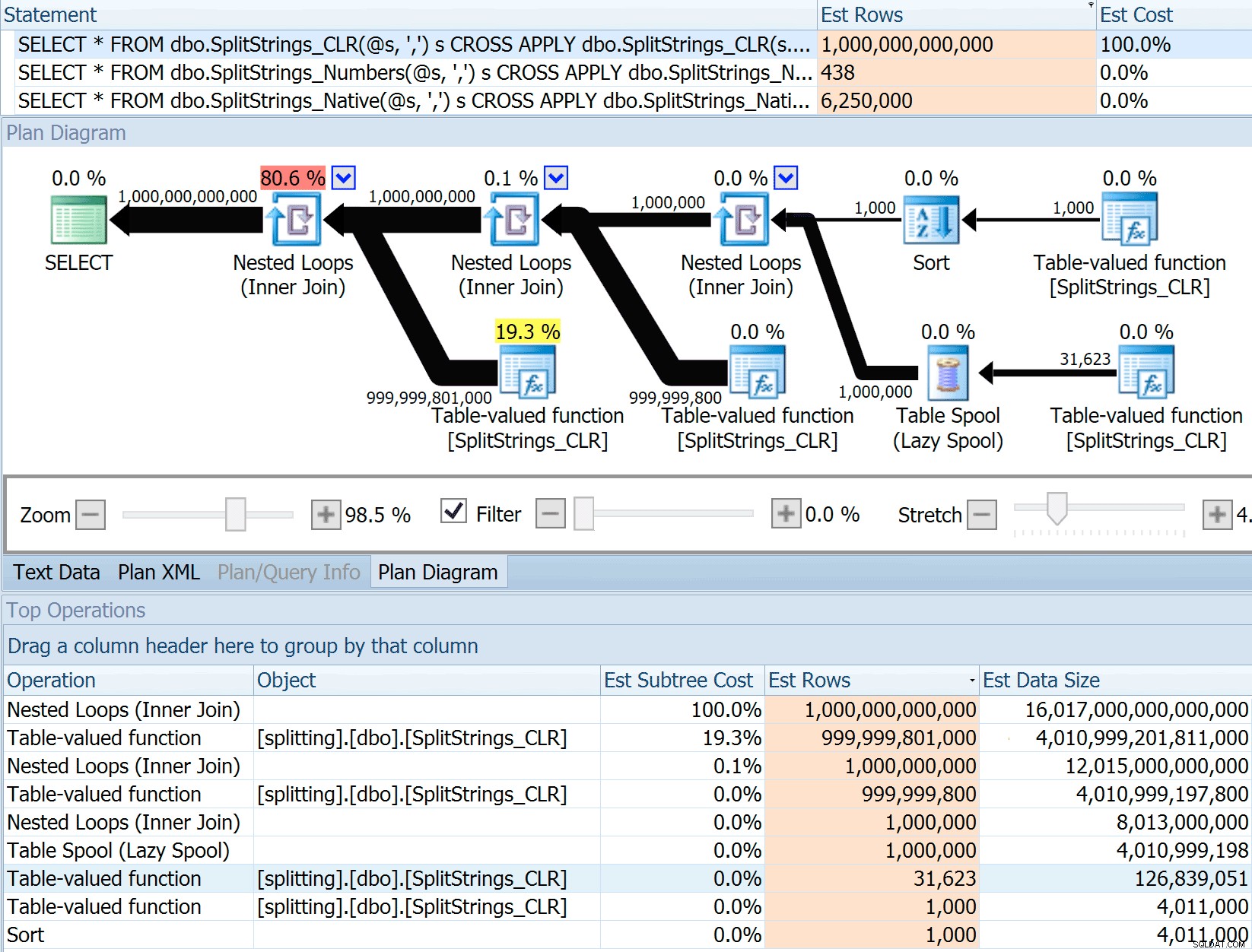
Sommige van de andere benaderingen doen het duidelijk beter in termen van schattingen. De tabel Numbers schatte bijvoorbeeld een veel redelijkere 438 rijen (in SQL Server 2016 RC2). Waar komt dit nummer vandaan? Welnu, er zijn 8.000 rijen in de tabel, en als je het je herinnert, de functie heeft zowel een gelijkheids- als een ongelijkheidspredikaat:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Dus SQL Server vermenigvuldigt het aantal rijen in de tabel met 10% (als schatting) voor het gelijkheidsfilter, en vervolgens de vierkantswortel van 30% (alweer een gok) voor het ongelijkheidsfilter. De vierkantswortel is te wijten aan exponentiële uitstel, wat Paul White hier uitlegt. Dit geeft ons:
8000 * 0,1 * SQRT (0,3) =438,178De XML-variant schatte iets meer dan een miljard rijen (vanwege een table spool die naar schatting 5,8 miljoen keer wordt uitgevoerd), maar het plan was veel te complex om hier te illustreren. Onthoud in ieder geval dat schattingen duidelijk niet het hele verhaal vertellen - alleen omdat een zoekopdracht nauwkeurigere schattingen heeft, betekent niet dat deze beter zal presteren.
Er waren een paar andere manieren waarop ik de schattingen een beetje kon aanpassen:namelijk het forceren van het oude kardinaliteitsschattingsmodel (dat zowel de XML- als de Numbers-tabelvariaties beïnvloedde), en het gebruik van TF's 9471 en 9472 (die alleen de Numbers-tabelvariatie beïnvloedden, aangezien ze controleren allebei de kardinaliteit rond meerdere predikaten). Dit waren de manieren waarop ik de schattingen een klein beetje (of VEEL , in het geval van terugkeer naar het oude CE-model):

Het oude CE-model bracht de XML-schattingen met een orde van grootte naar beneden, maar voor de Numbers-tabel blies het volledig op. De predikaatvlaggen veranderden de schattingen voor de getallentabel, maar die veranderingen zijn veel minder interessant.
Geen van deze traceervlaggen had enig effect op de schattingen voor de CLR, JSON of STRING_SPLIT variaties.
Conclusie
Dus wat heb ik hier geleerd? Een hele hoop eigenlijk:
- Parallisme kan in sommige gevallen helpen, maar als het niet helpt, is het echt helpt niet. De JSON-methoden waren ~5x sneller zonder parallellisme, en
STRING_SPLITwas bijna 10x sneller. - De spoel heeft de CLR-aanpak in dit geval geholpen om beter te presteren, maar TF 8690 kan nuttig zijn om mee te experimenteren in andere gevallen waarin je spoelen ziet en de prestaties probeert te verbeteren. Ik ben er zeker van dat er situaties zijn waarin het elimineren van de spoel over het algemeen beter zal zijn.
- Het elimineren van de spool deed de XML-aanpak echt pijn (maar alleen drastisch toen het gedwongen werd single-threaded te zijn).
- Er kunnen veel gekke dingen gebeuren met schattingen, afhankelijk van de aanpak, samen met de gebruikelijke statistieken, distributie en traceervlaggen. Nou, ik denk dat ik dat al wist, maar er zijn hier zeker een paar goede, tastbare voorbeelden.
Bedankt aan de mensen die vragen hebben gesteld of me hebben aangespoord om meer informatie op te nemen. En zoals je misschien uit de titel hebt geraden, behandel ik nog een andere vraag in een tweede vervolg, deze over TVP's:
- STRING_SPLIT() in SQL Server 2016:vervolg #2