Eerder deze week plaatste ik een vervolg op mijn recente bericht over STRING_SPLIT() in SQL Server 2016, ingaand op verschillende opmerkingen die op het bericht zijn achtergelaten en/of rechtstreeks naar mij zijn gestuurd:
STRING_SPLIT()in SQL Server 2016:vervolg #1
Nadat dat bericht grotendeels was geschreven, was er een late vraag van Doug Ellner:
Hoe verhouden deze functies zich tot tabelwaardeparameters?
Nu stond het testen van TVP's al op mijn lijst met toekomstige projecten, na een recente twitteruitwisseling met @Nick_Craver bij Stack Overflow. Hij zei dat ze enthousiast waren dat STRING_SPLIT() presteerden goed, omdat ze niet tevreden waren met de prestatie van het verzenden van ~7.000 waarden via een tabelwaardeparameter.
Mijn testen
Voor deze tests heb ik SQL Server 2016 RC3 (13.0.1400.361) gebruikt op een 8-core Windows 10 VM, met PCIe-opslag en 32 GB RAM.
Ik heb een eenvoudige tabel gemaakt die nabootste wat ze aan het doen waren (door ongeveer 10.000 waarden te selecteren uit een tabel met meer dan 3 miljoen rijberichten), maar voor mijn tests heeft deze veel minder kolommen en minder indexen:
MAAK TABEL dbo.Posts_Regular( PostID int PRIMARY KEY, HitCount int NOT NULL STANDAARD 0); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) VANUIT sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
Ik heb ook een In-Memory-versie gemaakt, omdat ik benieuwd was of een aanpak daar anders zou werken:
MAAK TABEL dbo.Posts_InMemory( PostID int PRIMARY KEY NIET-GECLUSTERDE HASH WITH (BUCKET_COUNT =4000000), HitCount int NOT NULL STANDAARD 0) WITH (MEMORY_OPTIMIZED =ON);
Nu wilde ik een C#-app maken die 10.000 unieke waarden zou doorgeven, hetzij als een door komma's gescheiden tekenreeks (gebouwd met behulp van een StringBuilder) of als een TVP (doorgegeven vanuit een gegevenstabel). Het punt zou zijn om een selectie van rijen op te halen of bij te werken op basis van een overeenkomst, ofwel met een element dat is geproduceerd door de lijst te splitsen, ofwel met een expliciete waarde in een TVP. Dus de code is geschreven om elke 300ste waarde toe te voegen aan de string of DataTable (C#-code staat in een bijlage hieronder). Ik nam de functies die ik in de originele post had gemaakt, wijzigde ze om varchar(max) te verwerken , en voegde vervolgens twee functies toe die een TVP accepteerden - een daarvan geoptimaliseerd voor geheugen. Dit zijn de tabeltypes (de functies staan in de bijlage hieronder):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY);GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE( PostID int NOT NULL PRIMARY KEY NIET-CLUSTERED HASH WITH (BUCKET_COUNT =1000000)) WITH (MEMORY_OPTIMIZED); /pre>Ik moest ook de Numbers-tabel groter maken om strings> 8K en met> 8K-elementen aan te kunnen (ik maakte er rijen van 1MM van). Daarna heb ik zeven opgeslagen procedures gemaakt:vijf ervan met een
varchar(max)en samenvoegen met de functie-uitvoer om de basistabel bij te werken, en vervolgens twee om de TVP te accepteren en daar direct mee samen te werken. De C#-code roept elk van deze zeven procedures aan, met de lijst van 10.000 berichten die moeten worden geselecteerd of bijgewerkt, 1000 keer. Deze procedures staan ook in de bijlage hieronder. Dus om samen te vatten, de methoden die worden getest zijn:
- Native (
STRING_SPLIT()) - XML
- CLR
- Getallentabel
- JSON (met expliciete
intuitvoer) - Parameter met tabelwaarde
- Voor het geheugen geoptimaliseerde tabelwaardeparameter
We testen het ophalen van de 10.000 waarden, 1.000 keer, met behulp van een DataReader - maar niet itereren over de DataReader, omdat dat de test alleen maar langer zou maken en dezelfde hoeveelheid werk zou zijn voor de C#-toepassing, ongeacht hoe de database de set geproduceerd. We testen ook het bijwerken van de 10.000 rijen, elk 1000 keer, met behulp van ExecuteNonQuery() . En we zullen testen met zowel de reguliere als voor het geheugen geoptimaliseerde versies van de Posts-tabel, die we heel gemakkelijk kunnen wisselen zonder een van de functies of procedures te hoeven veranderen, met behulp van een synoniem:
CREER SYNONIEM dbo.Posts VOOR dbo.Posts_Regular; -- om voor geheugen geoptimaliseerde versie te testen:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts VOOR dbo.Posts_InMemory; -- om de schijfversie opnieuw te testen:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Ik startte de applicatie, voerde hem verschillende keren uit voor elke combinatie om ervoor te zorgen dat compilatie, caching en andere factoren niet oneerlijk waren ten opzichte van de batch die eerst werd uitgevoerd, en analyseerde vervolgens de resultaten van de logtabel (ik controleerde ook ter plaatse sys. dm_exec_procedure_stats om er zeker van te zijn dat geen van de benaderingen significante applicatiegebaseerde overhead had, en dat deden ze niet).
Resultaten – op schijf gebaseerde tabellen
Ik heb soms moeite met datavisualisatie - ik heb echt geprobeerd een manier te bedenken om deze statistieken op een enkele grafiek weer te geven, maar ik denk dat er gewoon veel te veel datapunten waren om de meest opvallende eruit te laten springen.
Je kunt erop klikken om ze te vergroten in een nieuw tabblad/venster, maar zelfs als je een klein venster hebt, heb ik geprobeerd de winnaar duidelijk te maken door middel van kleur (en de winnaar was in alle gevallen dezelfde). En voor alle duidelijkheid, met 'Gemiddelde duur' bedoel ik de gemiddelde hoeveelheid tijd die de applicatie nodig had om een lus van 1000 bewerkingen te voltooien.
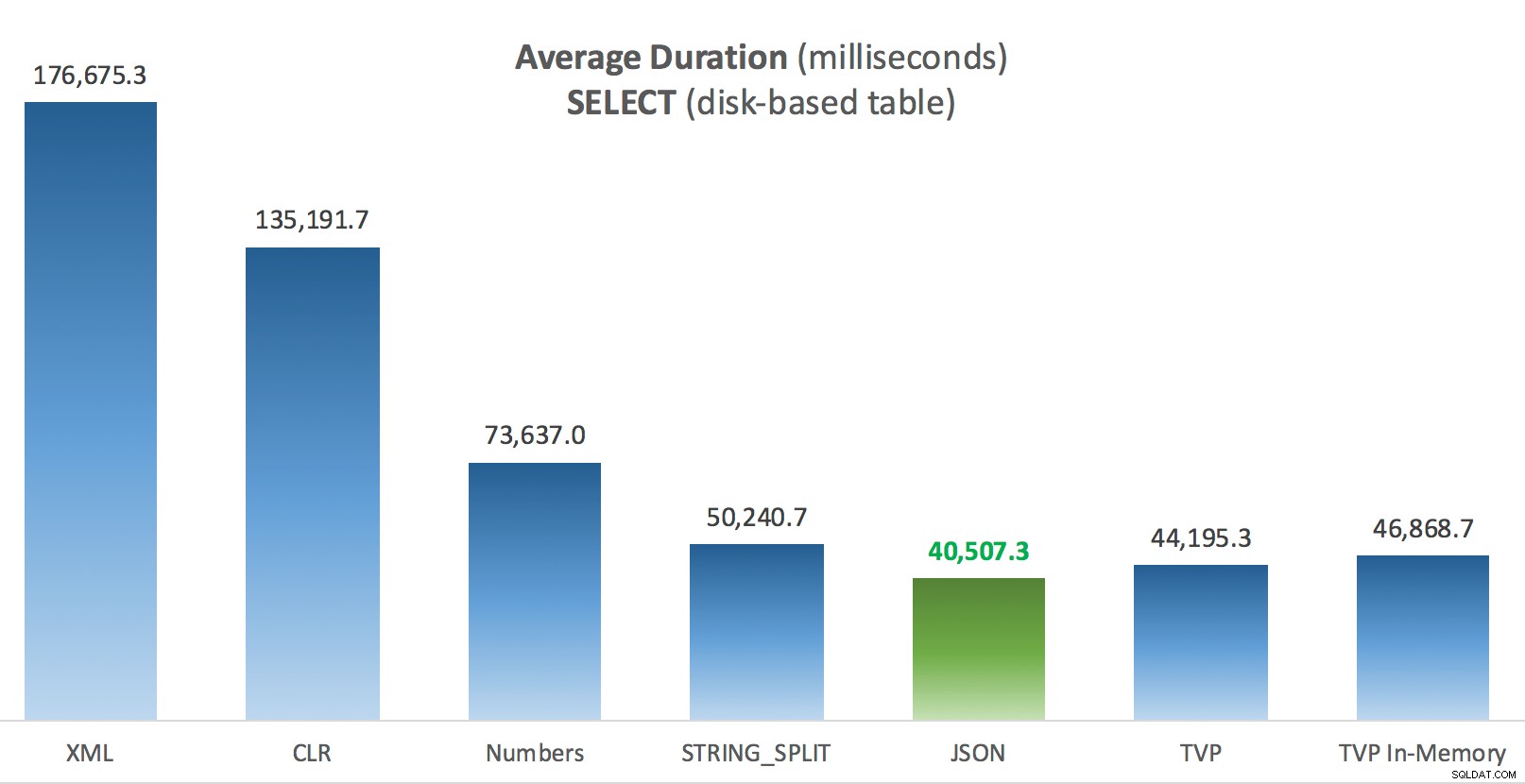 Gemiddelde duur (milliseconden) voor SELECT's in vergelijking met de tabel Posts op schijf
Gemiddelde duur (milliseconden) voor SELECT's in vergelijking met de tabel Posts op schijf
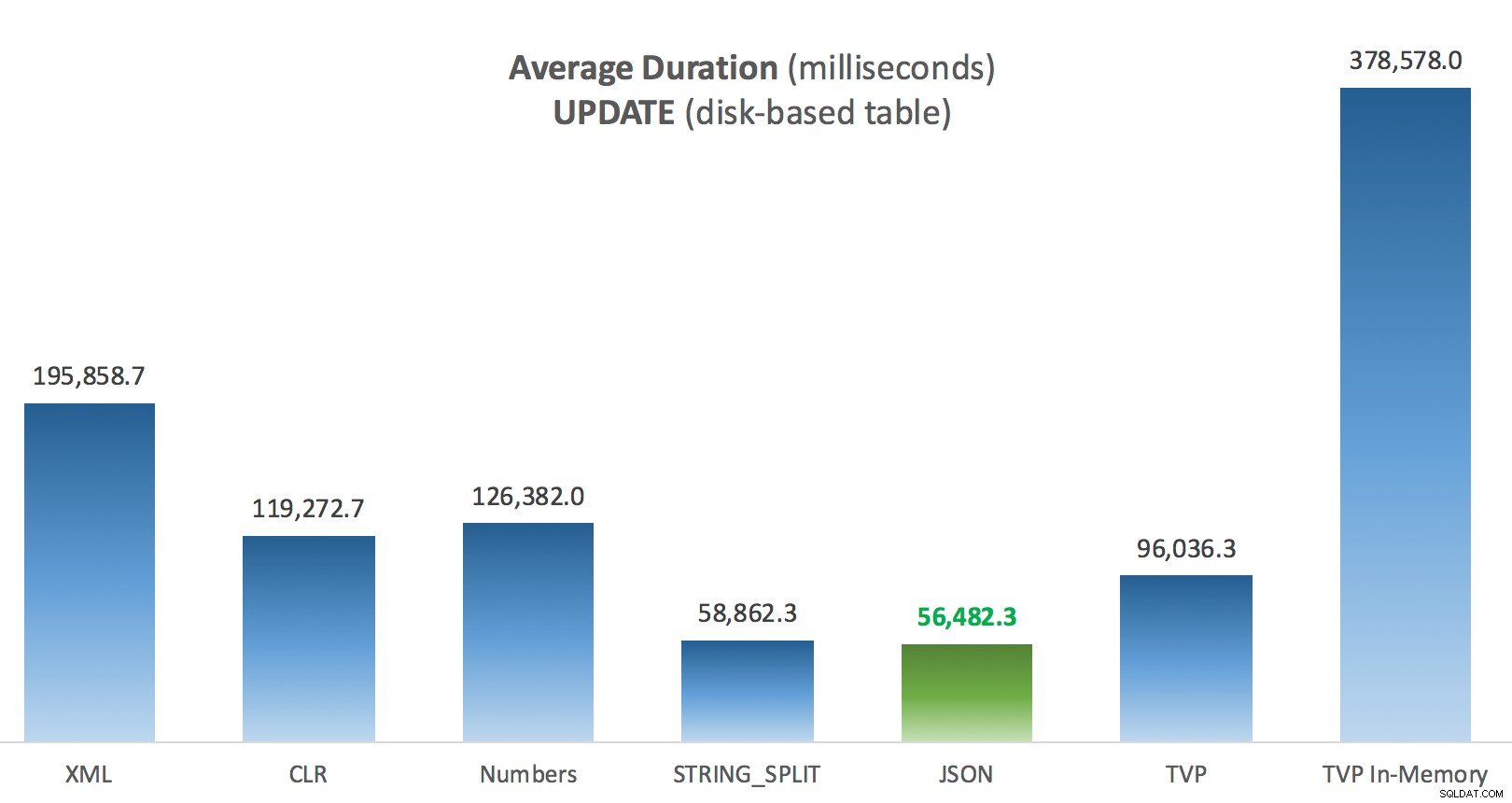 Gemiddelde duur (milliseconden) voor UPDATE's ten opzichte van de tabel Posts op schijf
Gemiddelde duur (milliseconden) voor UPDATE's ten opzichte van de tabel Posts op schijf
Het meest interessante voor mij is hoe slecht de voor geheugen geoptimaliseerde TVP het deed bij het assisteren bij een UPDATE . Het blijkt dat parallelle scans momenteel te agressief worden geblokkeerd als het om DML gaat; Microsoft heeft dit erkend als een hiaat in de functies en ze hopen dit binnenkort te verhelpen. Merk op dat parallelle scan momenteel mogelijk is met SELECT maar het is nu geblokkeerd voor DML. (Het wordt niet opgelost in SQL Server 2014, omdat deze specifieke parallelle scanbewerkingen daar voor geen enkele bewerking beschikbaar zijn.) Als dat is opgelost, of wanneer uw TVP's kleiner zijn en/of parallellisme toch niet gunstig is, zou u moeten zien dat voor geheugen geoptimaliseerde TVP's beter zullen presteren (het patroon werkt gewoon niet goed voor dit specifieke gebruiksgeval van relatief grote TVP's).
Voor dit specifieke geval zijn hier de plannen voor de SELECT (die ik zou kunnen dwingen om parallel te gaan) en de UPDATE (wat ik niet kon):
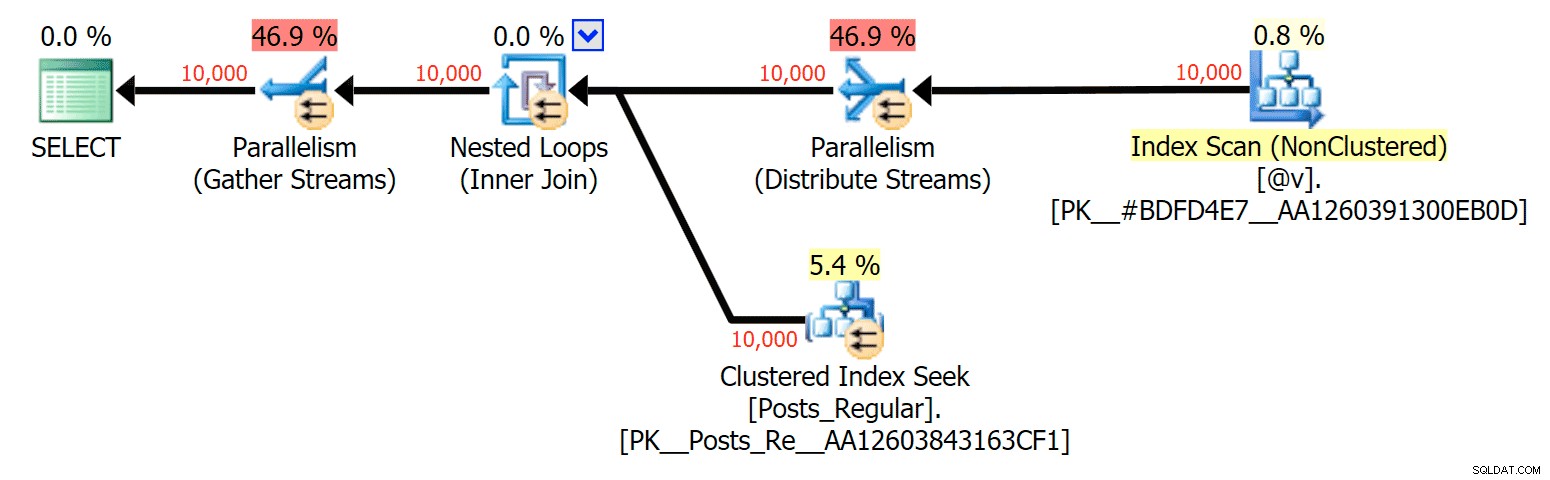 Parallisme in een SELECT-plan dat een schijfgebaseerde tabel koppelt aan een in-memory TVP
Parallisme in een SELECT-plan dat een schijfgebaseerde tabel koppelt aan een in-memory TVP
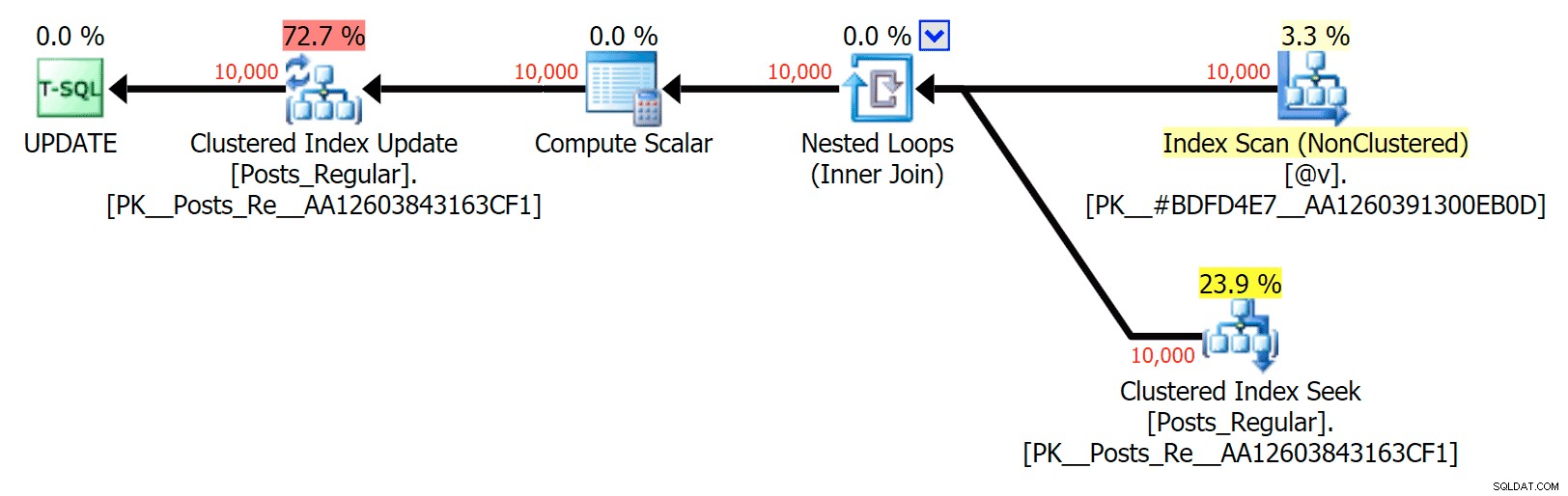 Geen parallelliteit in een UPDATE-plan dat een schijfgebaseerde tabel koppelt aan een in-memory TVP
Geen parallelliteit in een UPDATE-plan dat een schijfgebaseerde tabel koppelt aan een in-memory TVP
Resultaten – voor geheugen geoptimaliseerde tabellen
Een beetje meer consistentie hier - de vier methoden aan de rechterkant zijn relatief gelijk, terwijl de drie aan de linkerkant daarentegen erg ongewenst lijken. Besteed ook bijzondere aandacht aan absolute schaal in vergelijking met de op schijf gebaseerde tabellen - voor het grootste deel, met behulp van dezelfde methoden, en zelfs zonder parallellisme, krijgt u veel snellere bewerkingen tegen voor geheugen geoptimaliseerde tabellen, wat leidt tot een lager algemeen CPU-gebruik.
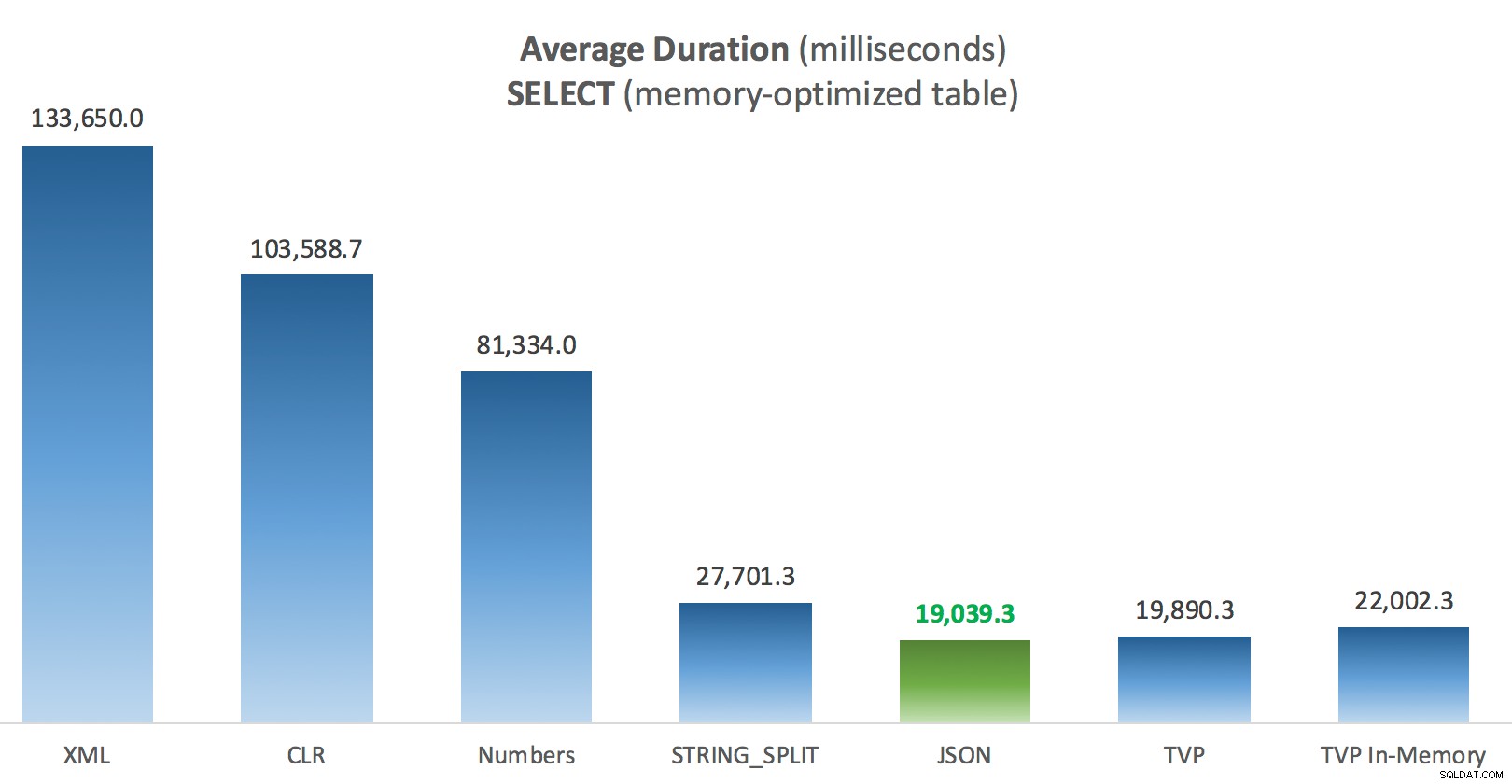 Gemiddelde duur (milliseconden) voor SELECT's ten opzichte van voor geheugen geoptimaliseerde berichtentabel
Gemiddelde duur (milliseconden) voor SELECT's ten opzichte van voor geheugen geoptimaliseerde berichtentabel
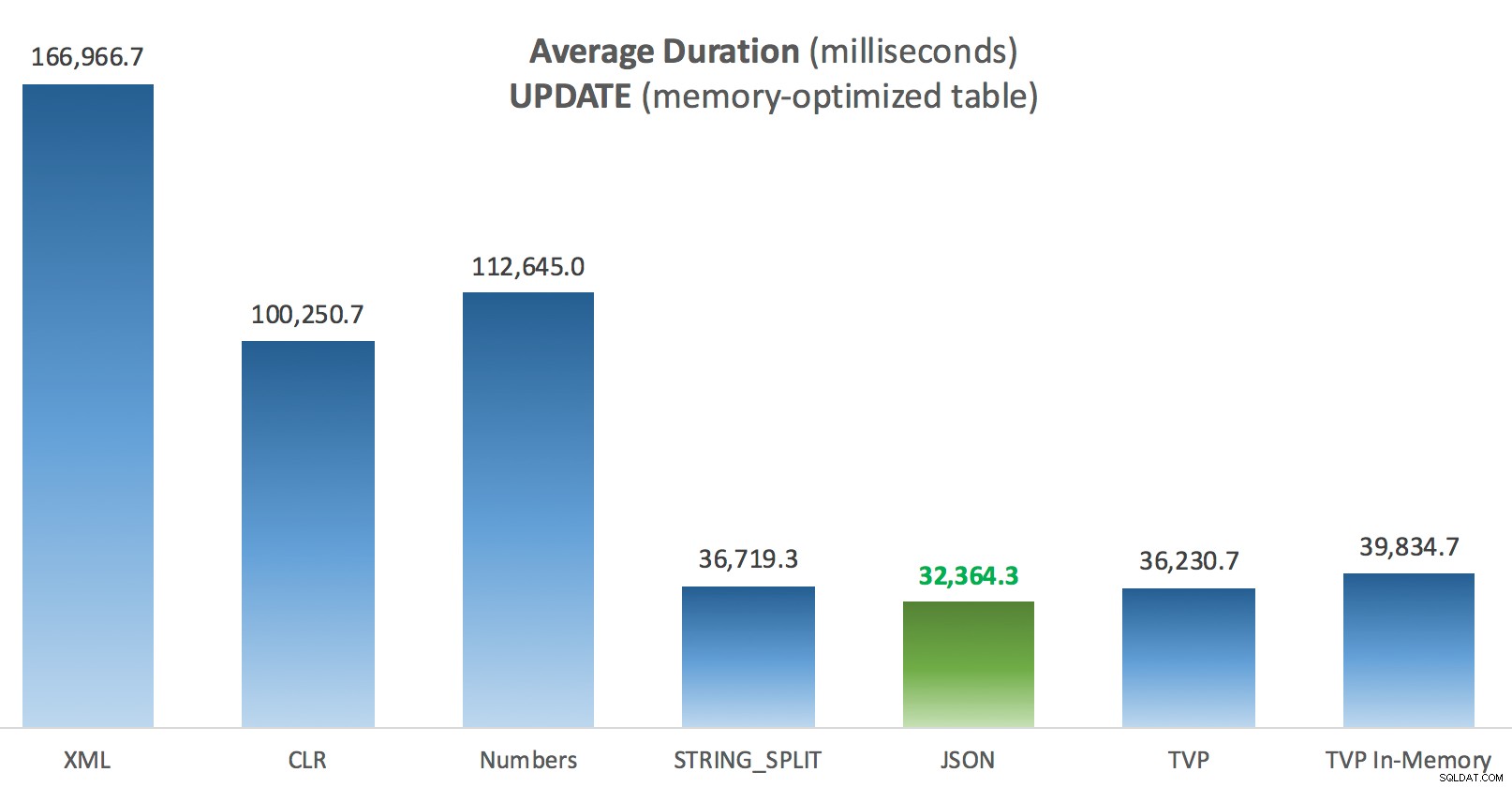 Gemiddelde duur (milliseconden) voor UPDATE's ten opzichte van voor geheugen geoptimaliseerde berichtentabel
Gemiddelde duur (milliseconden) voor UPDATE's ten opzichte van voor geheugen geoptimaliseerde berichtentabel
Conclusie
Voor deze specifieke test, met een specifieke gegevensgrootte, distributie en aantal parameters, en op mijn specifieke hardware, was JSON een consistente winnaar (hoewel marginaal). Voor sommige van de andere tests in eerdere berichten deden andere benaderingen het echter beter. Slechts een voorbeeld van hoe wat je doet en waar je het doet een dramatische impact kan hebben op de relatieve efficiëntie van verschillende technieken. Dit zijn de dingen die ik heb getest in deze korte serie, met mijn samenvatting van welke techniek je moet gebruiken. gebruik in dat geval en welke u als 2e of 3e keuze moet gebruiken (bijvoorbeeld als u CLR niet kunt implementeren vanwege bedrijfsbeleid of omdat u Azure SQL Database gebruikt, of als u geen JSON of STRING_SPLIT() omdat u nog geen SQL Server 2016 gebruikt). Merk op dat ik niet terug ben gegaan en de variabeletoewijzing opnieuw heb getest en SELECT INTO scripts die TVP's gebruiken - deze tests zijn opgezet in de veronderstelling dat u al bestaande gegevens in CSV-indeling had die toch eerst moesten worden opgesplitst. Als je het kunt vermijden, moet je je sets in het algemeen niet in door komma's gescheiden tekenreeksen verpletteren, IMHO.
| Doel | 1e keuze | 2e keuze (en 3e, indien van toepassing) |
|---|---|---|
| Eenvoudige variabele toewijzing | STRING_SPLIT() | CLR indien <2016 XML indien geen CLR en <2016 |
| SELECTEER IN | CLR | XML indien geen CLR |
| SELECTEER IN (geen spoel) | CLR | Getallentabel indien geen CLR |
| SELECTEER IN (geen spoel + MAXDOP 1) | STRING_SPLIT() | CLR indien <2016 Getallentabel indien geen CLR en <2016 |
| SELECTEER deelname aan grote lijst (op schijf) | JSON (int) | TVP indien <2016 |
| SELECTEER deelname aan grote lijst (geoptimaliseerd voor geheugen) | JSON (int) | TVP indien <2016 |
| UPDATE toevoegen aan grote lijst (op schijf) | JSON (int) | TVP indien <2016 |
| UPDATE toevoegen aan grote lijst (geoptimaliseerd voor geheugen) | JSON (int) | TVP indien <2016 |
Voor de specifieke vraag van Doug:JSON, STRING_SPLIT() , en TVP's presteerden gemiddeld vrij gelijkaardig in deze tests - dicht genoeg dat TVP's de voor de hand liggende keuze zijn als u geen SQL Server 2016 gebruikt. Als u verschillende gebruiksscenario's hebt, kunnen deze resultaten verschillen. Geweldig .
Dat brengt ons bij de moraal van dit verhaal:ik en anderen kunnen zeer specifieke prestatietests uitvoeren, die draaien om een functie of benadering, en tot een conclusie komen over welke benadering het snelst is. Maar er zijn zoveel variabelen dat ik nooit het vertrouwen zal hebben om te zeggen "deze benadering is altijd de snelste." In dit scenario heb ik heel hard mijn best gedaan om de meeste bijdragende factoren te beheersen, en hoewel JSON in alle vier de gevallen won, kun je zien hoe die verschillende factoren de uitvoeringstijden beïnvloedden (en drastisch voor sommige benaderingen). Dus het is altijd de moeite waard om je eigen tests te maken, en ik hoop dat ik heb geholpen te illustreren hoe ik dat soort dingen aanpak.
Bijlage A:Console-toepassingscode
Alsjeblieft, geen gezeur over deze code; het werd letterlijk samengevoegd als een zeer eenvoudige manier om deze opgeslagen procedures 1000 keer uit te voeren met echte lijsten en DataTables geassembleerd in C #, en om de tijd te loggen die elke lus naar een tabel kostte (om er zeker van te zijn dat alle applicatiegerelateerde overhead bij het afhandelen ofwel een grote reeks of een verzameling). Ik zou foutafhandeling kunnen toevoegen, een andere lus kunnen maken (bijv. de lijsten in de lus maken in plaats van een enkele werkeenheid opnieuw te gebruiken), enzovoort.
systeem gebruiken; System.Text gebruiken; System.Configuration gebruiken; System.Data gebruiken; System.Data.SqlClient gebruiken; namespace SplitTesting{ class Program { static void Main(string [] args) { string operation ="Update"; if (args[0].ToString() =="-Select") { operation ="Select"; } var csv =nieuwe StringBuilder(); DataTable-elementen =nieuwe DataTable(); elementen.Columns.Add("value", typeof(int)); for (int i =1; i <=10000; i++) { csv.Append((i*300).ToString()); if (i <10000) { csv.Append(","); } elementen.Rijen.Toevoegen(i*300); } string[] methoden ={ "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" }; met behulp van (SqlConnection con =new SqlConnection()) { con.ConnectionString =ConfigurationManager.ConnectionStrings["primary"].ToString(); con.Open(); SqlParameter p; foreach (stringmethode in methoden) { SqlCommand cmd =new SqlCommand ("dbo." + bewerking + "Posts_" + methode, con); cmd.CommandType =CommandType.StoredProcedure; if (method =="TVP" || method =="TVP_InMemory") { cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value =elementen; } else { cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value =csv.ToString(); } var timer =System.Diagnostics.Stopwatch.StartNew(); for (int x =1; x <=1000; x++) { if (operatie =="Update") { cmd.ExecuteNonQuery(); } else { SqlDataReader rdr =cmd.ExecuteReader(); rdr.Sluiten(); } } timer.Stop(); long this_time =timer.ElapsedMilliseconds; // log time - de logging procedure voegt kloktijd toe en // records geheugen/schijf-gebaseerd (bepaald via synoniem) SqlCommand log =new SqlCommand("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure; log.Parameters.Add("@Operation", SqlDbType.VarChar, 32). Waarde =bewerking; log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value =methode; log.Parameters.Add("@Timing", SqlDbType.Int).Value =this_time; log.ExecuteNonQuery(); Console.WriteLine(methode + ":" + this_time.ToString()); } } } }} Voorbeeldgebruik:
SplitTesting.exe -SelecteerSplitTesting.exe -Update
Bijlage B:Functies, procedures en logtabel
Hier zijn de functies bewerkt om varchar(max) te ondersteunen (de CLR-functie is al geaccepteerd nvarchar(max) en ik was nog steeds terughoudend om te proberen het te veranderen):
FUNCTIE MAKEN dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))RETURNS TABEL MET SCHEMABINDINGAS RETURN (SELECT [waarde] FROM STRING_SPLIT(@List, @Delimiter));GO CREATE FUNCTIE dbo.SplitStrings_X ( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [value] =y.i.value('(./text())[1]', 'varchar(max)') FROM (SELECT x =CONVERTEREN(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('.')) ALS een CROSS APPLY x.nodes('i') AS y(i));GO CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [value] =SUBSTRING (@List, Number, CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number) VAN dbo.Numbers WHERE Number <=CONVERT(INT, LEN(@List)) AND SUBSTRING(@Delimiter + @List, Number , LEN(@Delimiter)) =@Delimiter);GA FUNCTIE MAKEN dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))RETURNS TABLE MET SCH EMABINDINGAS RETURN (SELECT [waarde] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (waarde int '$'));GO En de opgeslagen procedures zagen er als volgt uit:
PROCEDURE MAKEN dbo.UpdatePosts_Native @PostList varchar(max)ASBEGIN UPDATE p SET HitCount +=1 VAN dbo.Posts AS p INNERLIJKE JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s. [waarde];ENDGOCREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max)ASBEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s.[value];ENDGO-- herhaal voor de 4 andere op varchar(max) gebaseerde methoden CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular naar _InMemoryASBEGIN STEL NOCOUNT ON in; UPDATE p SET HitCount +=1 VAN dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGOCREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular naar GEEN SB_InMemory SELECT p.PostID, p.HitCount VAN dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGO-- herhaal voor in-memory
En tot slot, de logtabel en procedure:
CREATE TABLE dbo.SplitLog( LogID int IDENTITY(1,1) PRIMARY KEY, ClockTime datetime NOT NULL STANDAARD GETDATE(), OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory of Posts_Regular Operation varchar(32) NOT NULL DEFAULT 'Update', -- of selecteer Methode varchar (32) NOT NULL STANDAARD 'Native', -- of TVP, JSON, etc. Timing int NOT NULL DEFAULT 0);GA PROCEDURE MAKEN dbo.LogBatchTime @Operation varchar(32), @Methode varchar(32), @Timing intASBEGIN STEL NOCOUNT IN; INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts';ENDGO -- en de query om de grafieken te genereren:;WITH x AS (SELECT OperationTable, Operation, Method, Timing, Recency =ROW_NUMBER () OVER (PARTITION BY OperatingTable, Operation, Method ORDER BY ClockTime DESC) VAN dbo.SplitLog)SELECT OperatingTable, Operation, Method, AverageDuration =AVG(1.0*Timing) VANAF x WHERE Recentheid <=3GROEP NAAR OperatingTable,Operation,Methode;