Allereerst is "toxi" geen standaardterm. Definieer altijd uw voorwaarden! Of geef op zijn minst relevante links.
En nu de vraag zelf...
Nee, je hebt 3 tafels.
U bent vrijwel op de goede weg, behalve dat u de set-gebaseerde aard van SQL kunt gebruiken om veel van deze stappen te "samenvoegen". U kunt bijvoorbeeld een item 1 taggen met tags:'tag1', 'tag2' en 'tag3' als volgt...
INSERT IGNORE INTO tagmap (item_id, tag_id)
SELECT 1, tag_id FROM tags WHERE tag_text IN ('tag1', 'tag2', 'tag3');
De IGNORE staat dit toe om te slagen, zelfs als het item al is verbonden met een aantal van deze tags.
Dit veronderstelt dat alle vereiste tags zich al in tags bevinden . Ervan uitgaande dat tag.tag_id automatisch verhoogd is, kunt u zoiets doen om ervoor te zorgen dat ze:
INSERT IGNORE INTO tags (tag_text) VALUES ('tag1'), ('tag2'), ('tag3');
Er is geen magie. Als "item is verbonden met een bepaalde tag" een stukje kennis is dat u wilt vastleggen, dan zal het hebben om een soort fysieke representatie in de database te hebben.
Bedoel je het opnieuw taggen van items (geen tags zelf wijzigen)?
Om alle tags te verwijderen die niet in de lijst staan, doe je zoiets als dit:
DELETE FROM tagmap
WHERE
item_id = 1
AND tag_id NOT IN (
SELECT tag_id FROM tags
WHERE tag_text IN ('tag1', 'tag3')
);
Hierdoor wordt het item losgekoppeld van alle tags behalve 'tag1' en 'tag3'. Voer de INSERT hierboven en deze DELETE een voor een uit om zowel het toevoegen als verwijderen van tags te "bedekken".
Je kunt met dit alles spelen in de SQL Fiddle .
Juist. Een onderliggend eindpunt van een FK zal geen referentiële actie activeren (zoals ON DELETE CASCADE), alleen ouder zal dat doen.
Trouwens, je gebruikt dit schema omdat je extra velden wilt in tags (naast tag_text ), Rechtsaf? Als u dat doet, is het gewenst gedrag dat u deze aanvullende gegevens niet kwijtraakt omdat alle verbindingen zijn verbroken.
Maar als je alleen de tag_text , zou u een eenvoudiger schema gebruiken waarbij het verwijderen van alle verbindingen hetzelfde zou zijn als het verwijderen van de tag zelf:
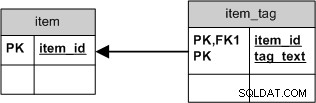
Dit zou niet alleen de SQL vereenvoudigen, het zou ook zorgen voor betere clustering .
Op het eerste gezicht lijkt "toxi" misschien ruimtebesparend, maar in de praktijk is dit misschien niet het geval, omdat er extra tabellen en indexen voor nodig zijn (en tags zijn meestal kort).
Meet voordat u besluit zoiets te doen. Mijn hierboven genoemde SQL Fiddle gebruikt een zeer bewuste volgorde van velden in de tagmap PK, dus gegevens zijn geclusterd op een manier die erg vriendelijk is voor dit soort tellen (onthoud:InnoDB-tabellen zijn geclusterd
). Je zou echt een enorm aantal items moeten hebben (of ongewoon hoge prestaties vereisen) voordat dit een probleem wordt.
Hoe dan ook, meten op realistische hoeveelheden data!