Inleiding
Nu zijn uw matchingvoorwaarden misschien te breed. U kunt echter levenshtein-afstand gebruiken om uw woorden te controleren. Het is misschien niet zo eenvoudig om er alle gewenste doelen mee te vervullen, zoals geluidsovereenkomst. Daarom stel ik voor om uw probleem op te splitsen in een aantal andere problemen.
U kunt bijvoorbeeld een aangepaste checker maken die door gegeven aanroepbare invoer gebruikt die twee strings nodig heeft en vervolgens de vraag beantwoordt of ze hetzelfde zijn (voor levenshtein dat zal een afstand kleiner zijn dan een bepaalde waarde, voor similar_text - enige procent van de overeenkomst e t.c. - het is aan jou om regels te definiëren).
Overeenkomst, gebaseerd op woorden
Welnu, alle ingebouwde functies zullen mislukken als we het hebben over het geval dat je op zoek bent naar een gedeeltelijke match - vooral als het gaat om niet-geordende match. U moet dus een complexere vergelijkingstool maken. Je hebt:
- Gegevensreeks (die zich bijvoorbeeld in DB bevindt). Het ziet eruit als D =D0 D1 D2 ... Dn
- Zoekreeks (dat is gebruikersinvoer). Het ziet eruit als S =S0 S1 ... Sm
Ruimtesymbolen betekenen hier gewoon elke spatie (ik neem aan dat ruimtesymbolen de gelijkenis niet beïnvloeden). Ook n > m . Met deze definitie gaat uw probleem over - het vinden van een set van m woorden in D die zal lijken op S . Door set Ik bedoel elke ongeordende volgorde. Dus, als we een dergelijke reeks vinden, in D , dan S lijkt op D .
Uiteraard, als n < m dan bevat invoer meer woorden dan een gegevensreeks. In dit geval denkt u misschien dat ze niet vergelijkbaar zijn of handelt u zoals hierboven, maar wisselt u van gegevens en invoer (dat ziet er echter een beetje vreemd uit, maar is in zekere zin van toepassing)
Implementatie
Om de dingen te doen, moet je een reeks tekenreeksen kunnen maken die delen zijn van m woorden van D . Gebaseerd op mijn deze vraag
je kunt dit doen met:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-dus voor elke array, getAssoc() retourneert een reeks ongeordende selecties bestaande uit m elk item.
De volgende stap gaat over de volgorde in de geproduceerde selectie. We moeten zowel Niels Andersen . zoeken en Andersen Niels in onze D snaar. Daarom moet u permutaties voor array kunnen maken. Het is een veel voorkomend probleem, maar ik zal hier ook mijn versie plaatsen:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Hierna kunt u selecties maken van m woorden en verkrijg, door ze allemaal te permuteren, alle varianten om te vergelijken met de zoekreeks S . Die vergelijking zal elke keer worden gedaan via een terugroepactie, zoals levenshtein . Hier is een voorbeeld:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Dit controleert op gelijkenis, gebaseerd op callback van de gebruiker, die ten minste twee parameters moet accepteren (d.w.z. vergeleken strings). Mogelijk wilt u ook een string retourneren die een positieve callback-return heeft geactiveerd. Houd er rekening mee dat deze code niet zal verschillen tussen hoofdletters en kleine letters - maar het kan zijn dat u dergelijk gedrag niet wilt (vervang dan gewoon strtolower() ).
Een voorbeeld van de volledige code is beschikbaar in deze lijst (Ik heb sandbox niet gebruikt omdat ik niet zeker weet hoe lang de codelijst daar beschikbaar zal zijn). Met dit gebruiksvoorbeeld:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
je krijgt resultaten als:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-hier is een demo voor deze code, voor het geval dat.
Complexiteit
Aangezien u niet alleen om welke methode dan ook geeft, maar ook om - hoe goed is het, zult u merken dat dergelijke code nogal buitensporige bewerkingen zal produceren. Ik bedoel in ieder geval het genereren van snaaronderdelen. Complexiteit bestaat hier uit twee delen:
- Onderdeel voor het genereren van snarenonderdelen. Als je alle stringparts wilt genereren, moet je dit doen zoals ik hierboven heb beschreven. Mogelijk verbeterpunt:het genereren van ongeordende stringsets (die vóór permutatie komen). Maar toch betwijfel ik of het kan, omdat de methode in de verstrekte code ze niet met "brute-force" zal genereren, maar omdat ze wiskundig worden berekend (met kardinaliteit van
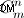 )
) - Onderdeel voor het controleren van overeenkomsten. Hier hangt uw complexiteit af van de gegeven gelijkenischecker. Bijvoorbeeld
similar_text()heeft O(N)-complexiteit, dus met grote vergelijkingssets zal het extreem traag zijn.
Maar u kunt de huidige oplossing nog steeds verbeteren door on-the-fly te controleren. Nu zal deze code eerst alle string-subreeksen genereren en ze dan een voor een controleren. In het algemeen hoef je dat niet te doen, dus misschien wil je dat vervangen door gedrag, wanneer het na het genereren van de volgende reeks onmiddellijk wordt gecontroleerd. Dan verhoog je de prestaties voor strings die een positief antwoord hebben (maar niet voor strings die geen match hebben).