Als je IT-infrastructuur op AWS draait, heb je waarschijnlijk wel eens gehoord van Amazon Relational Database Service (RDS), een eenvoudige manier om een relationele database in de cloud op te zetten, te bedienen en te schalen. Het biedt kosteneffectieve en aanpasbare capaciteit en automatiseert tijdrovende beheertaken zoals hardware-provisioning, database-configuratie, patching en back-ups. Er zijn een aantal database-engine-aanbiedingen voor RDS, zoals MySQL, MariaDB, PostgreSQL, Microsoft SQL Server en Oracle Server.
ClusterControl 1.7.3 werkt op dezelfde manier als RDS omdat het de implementatie, het beheer, de bewaking en het schalen van databaseclusters op het AWS-platform ondersteunt. Het ondersteunt ook een aantal andere cloudplatforms zoals Google Cloud Platform en Microsoft Azure. ClusterControl begrijpt de databasetopologie en is in staat om automatisch herstel, topologiebeheer en nog veel meer geavanceerde functies uit te voeren om controle over uw database te krijgen.
In deze blogpost gaan we automatische failover-tijden vergelijken voor Amazon Aurora, Amazon RDS voor MySQL en een MySQL-replicatieconfiguratie die wordt geïmplementeerd en beheerd door ClusterControl. Het type failover dat we gaan doen is slave-promotie in het geval dat de master uitvalt. Dit is waar de meest up-to-date slave de masterrol in het cluster overneemt om de databaseservice te hervatten.
Onze failover-test
Om de failover-tijd te meten, gaan we een eenvoudige MySQL connect-update-test uitvoeren, met een lus om de SQL-instructiestatus te tellen die verbinding maakt met een enkel database-eindpunt. Het script ziet er als volgt uit:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Het bovenstaande Bash-script maakt eenvoudig verbinding met een MySQL-host en voert een update uit op een enkele rij met een time-out van 1 seconde op zowel Bash- als mysql-clientopdrachten. De aan time-outs gerelateerde parameters zijn vereist zodat we de downtime in seconden correct kunnen meten, aangezien de mysql-client standaard altijd opnieuw verbinding maakt totdat de MySQL wait_timeout wordt bereikt. We hebben vooraf een testdataset gevuld met het volgende commando:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareHet script meldt of de bovenstaande query is geslaagd (OK) of mislukt (Fail). Voorbeelduitgangen worden verderop weergegeven.
Failover met Amazon RDS voor MySQL
In onze test gebruiken we het laagste RDS-aanbod met de volgende specificaties:
- MySQL-versie:5.7.22
- vCPU:4
- RAM:16 GB
- Opslagtype:ingerichte IOPS (SSD)
- IOPS:1000
- Opslag:100Gib
- Multi-AZ-replicatie:Ja
Nadat Amazon RDS uw DB-instantie heeft ingericht, kunt u elke standaard MySQL-clienttoepassing of -hulpprogramma gebruiken om verbinding te maken met de instantie. In de verbindingsreeks specificeert u het DNS-adres van het DB-instance-eindpunt als de hostparameter en specificeert u het poortnummer van het DB-instance-eindpunt als de poortparameter.
Volgens de Amazon RDS-documentatiepagina schakelt Amazon RDS in het geval van een geplande of ongeplande uitval van uw DB-instantie automatisch over naar een standby-replica in een andere Beschikbaarheidszone als u Multi-AZ hebt ingeschakeld. De tijd die nodig is om de failover te voltooien, hangt af van de databaseactiviteit en andere omstandigheden op het moment dat het primaire DB-subsysteem niet meer beschikbaar was. Failover-tijden zijn meestal 60-120 seconden.
Om een multi-AZ-failover in RDS te starten, hebben we een herstartbewerking uitgevoerd met "Reboot with Failover" aangevinkt, zoals weergegeven in de volgende schermafbeelding:
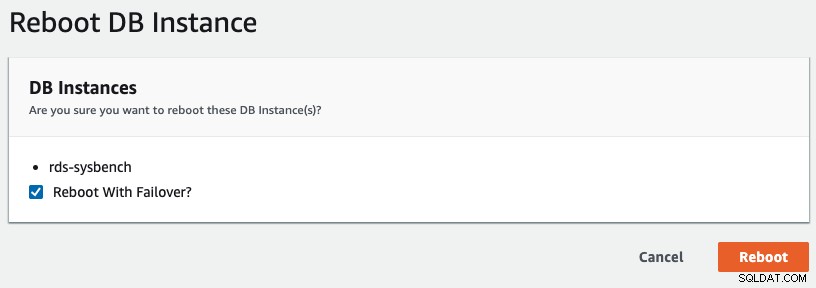
Het volgende is wat wordt waargenomen door onze applicatie:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...De MySQL-downtime zoals gezien door de applicatiezijde, werd gestart van 03:41:09 tot 03:41:36, wat in totaal ongeveer 27 seconden is. Uit de RDS-gebeurtenissen kunnen we zien dat de multi-AZ-failover pas 15 seconden na de daadwerkelijke downtime plaatsvond:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Nadat de nieuwe database-instantie rond 03:41:33 opnieuw was opgestart, was de MySQL-service ongeveer 3 seconden later toegankelijk.
Failover met Amazon Aurora voor MySQL
Amazon Aurora kan worden beschouwd als een superieure versie van RDS, met veel opvallende kenmerken, zoals snellere replicatie met gedeelde opslag, geen gegevensverlies tijdens failover en een opslaglimiet tot 64 TB. Amazon Aurora voor MySQL is gebaseerd op de open source MySQL-editie, maar is op zichzelf geen open source; het is een eigen, closed-source database. Het werkt op dezelfde manier met MySQL-replicatie (één en slechts één master, met meerdere slaves) en failover wordt automatisch afgehandeld door Amazon Aurora.
Volgens Amazon Aurora FAQS, als je een Amazon Aurora-replica hebt, in dezelfde of een andere beschikbaarheidszone, draait Aurora bij failover het canonieke naamrecord (CNAME) voor je DB-instantie om naar de gezonde replica, die zich in beurt wordt gepromoveerd om de nieuwe primaire te worden. Start-to-finish, failover wordt doorgaans binnen 30 seconden voltooid.
Als u geen Amazon Aurora-replica hebt (d.w.z. een enkele instantie), probeert Aurora eerst een nieuwe DB-instantie te maken in dezelfde beschikbaarheidszone als de oorspronkelijke instantie. Als dit niet lukt, zal Aurora proberen een nieuwe DB-instantie in een andere beschikbaarheidszone te maken. Van begin tot eind is de failover doorgaans in minder dan 15 minuten voltooid.
Uw toepassing moet de databaseverbindingen opnieuw proberen in het geval van verbindingsverlies.
Nadat Amazon Aurora uw DB-instantie heeft ingericht, krijgt u twee eindpunten, één voor de schrijver en één voor de lezer. Het eindpunt van de lezer biedt ondersteuning voor taakverdeling voor alleen-lezen verbindingen met het DB-cluster. De volgende eindpunten zijn afkomstig uit onze testopstelling:
- schrijver - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- lezer - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
In onze test hebben we de volgende Aurora-specificaties gebruikt:
- Exemplaartype:db.r5.large
- MySQL-versie:5.7.12
- vCPU:2
- RAM:16 GB
- Multi-AZ-replicatie:Ja
Om een failover te activeren, kiest u gewoon de writer-instantie -> Acties -> Failover, zoals weergegeven in de volgende schermafbeelding:
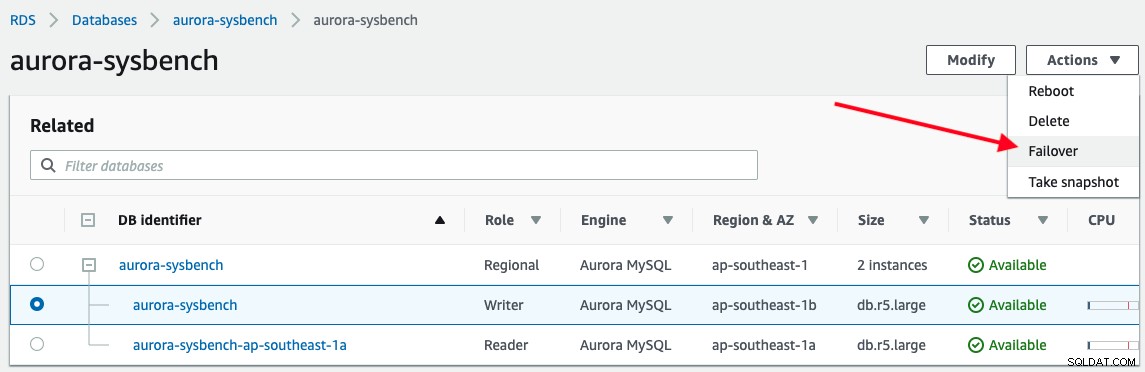
De volgende uitvoer wordt gerapporteerd door onze applicatie tijdens het verbinden met het Aurora-schrijvereindpunt :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...De downtime van de database begon om 12:35:49 tot 12:35:56 met een totaal van 7 seconden. Dat is behoorlijk indrukwekkend.
Kijkend naar de databasegebeurtenis van de Aurora-beheerconsole, vonden alleen deze twee gebeurtenissen plaats:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedHet kost Aurora niet veel tijd om een slaaf te promoveren om een meester te worden en de meester te degraderen om een slaaf te worden. Houd er rekening mee dat alle Aurora-replica's hetzelfde onderliggende volume delen met de primaire instantie en dit betekent dat replicatie in milliseconden kan worden uitgevoerd, aangezien updates die door de primaire instantie zijn aangebracht direct beschikbaar zijn voor alle Aurora-replica's. Daarom heeft het een minimale replicatievertraging (Amazon beweerde 100 milliseconden en minder te zijn). Dit zal de tijd voor de gezondheidscontrole aanzienlijk verkorten en de hersteltijd aanzienlijk verbeteren.
Failover met ClusterControl
In dit voorbeeld imiteren we een vergelijkbare setup met Amazon RDS met behulp van m5.xlarge-instanties, met een ProxySQL ertussen om de failover van een applicatie te automatiseren met behulp van een enkel eindpunttoegang, net als RDS. Het volgende diagram illustreert onze architectuur:
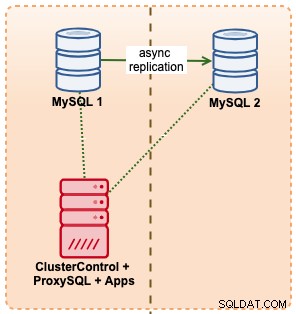
Omdat we directe toegang hebben tot de database-instanties, zouden we een automatische failover activeren door simpelweg het MySQL-proces op de actieve master te beëindigen:
$ kill -9 $(pidof mysqld)Het bovenstaande commando activeerde een automatisch herstel binnen ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Vanuit het oogpunt van onze testtoepassing gebeurde de downtime op het volgende moment tijdens het verbinden met ProxySQL-hostpoort 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Door te kijken naar zowel de hersteltaakgebeurtenissen als de uitvoer van onze applicatie, was het MySQL-databaseknooppunt 4 seconden voordat de clusterhersteltaak begon uit de lucht, van 11:08:28 tot 11:08:39, met een totale MySQL-downtime van 11 seconden . Een van de meest indrukwekkende dingen van ClusterControl is dat u de voortgang van het herstel kunt volgen over welke actie wordt ondernomen en uitgevoerd door ClusterControl tijdens de failover. Het biedt een niveau van transparantie dat u niet kunt krijgen met database-aanbiedingen van cloudproviders.
Voor MySQL/MariaDB/PostgreSQL-replicatie stelt ClusterControl u in staat om uw databases nauwkeuriger af te stemmen met de ondersteuning van de volgende geavanceerde configuratie en parameters:
- Master-master replicatietopologiebeheer
- Beheer van ketenreplicatietopologie
- Topologie-viewer
- Slaves op de witte/zwarte lijst die worden gepromoot als meester
- Foutieve transactiecontrole
- Pre/post, succes/fail failover/switchover-gebeurtenissen hook met extern script
- Slaaf automatisch opnieuw opbouwen bij fout
- Slaaf uit bestaande back-up schalen
Samenvatting failovertijd
In termen van failover-tijd is Amazon RDS Aurora voor MySQL de duidelijke winnaar met 7 seconden , gevolgd door ClusterControl 11 seconden en Amazon RDS voor MySQL met 27 seconden .
Merk op dat dit slechts een eenvoudige test is, met één klant en één transactie per seconde om de snelste hersteltijd te meten. Grote transacties of een langdurig herstelproces kunnen de failover-tijd verlengen. Langlopende transacties kunnen bijvoorbeeld lang duren voordat ze worden teruggedraaid bij het afsluiten van MySQL.