We zullen enkele IP-adressen genereren, geolokaliseren en ze plotten:
library(iptools)
library(rgeolocate)
library(tidyverse)
Genereer een miljoen (veel te uniform verdeelde) willekeurige IPv4-adressen:
ips <- ip_random(1000000)
En geolokaliseer ze:
system.time(
rgeolocate::maxmind(
ips, "~/Data/GeoLite2-City.mmdb", c("longitude", "latitude")
) -> xdf
)
## user system elapsed
## 5.016 0.131 5.217
5s voor 1m IPv4s.
Vanwege de uniformiteit zullen de bubbels stom klein zijn, dus alleen voor dit voorbeeld ronden we ze een beetje af:
xdf %>%
mutate(
longitude = (longitude %/% 5) * 5,
latitude = (latitude %/% 5) * 5
) %>%
count(longitude, latitude) -> pts
En plot ze:
ggplot(pts) +
geom_point(
aes(longitude, latitude, size = n),
shape=21, fill = "steelblue", color = "white", stroke=0.25
) +
ggalt::coord_proj("+proj=wintri") +
ggthemes::theme_map() +
theme(legend.justification = "center") +
theme(legend.position = "bottom")
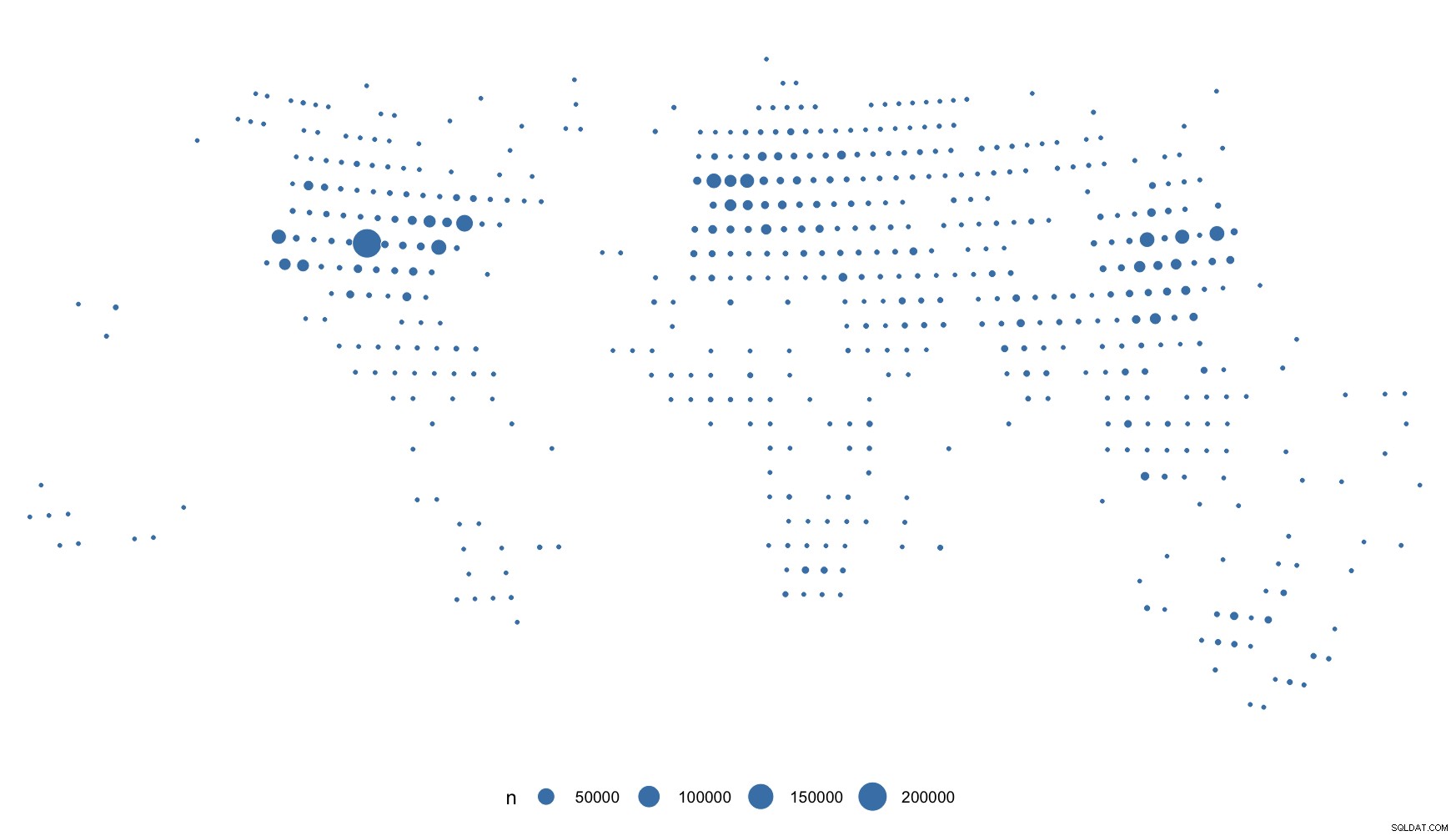
Je kunt zien wat ik bedoel met "te uniform". Maar je hebt "echte" IPv4's, dus je zou gtg moeten zijn.
Overweeg het gebruik van scale_size_area() , maar eerlijk gezegd, overweeg om IPv4's helemaal niet op een geokaart te plotten. Ik doe onderzoek op internetschaal voor de kost en de nauwkeurigheidsclaims laten veel te wensen over. Om die reden ga ik zelden onder de attributie op landniveau (en we betalen voor 'echte' gegevens).