De focus van dit artikel zal liggen op het gebruik van JOINs. We beginnen met een beetje te praten over hoe JOINs gaan plaatsvinden en waarom je JOIN-gegevens nodig hebt. Daarna zullen we kijken naar de JOIN-types die we tot onze beschikking hebben en hoe we ze kunnen gebruiken.
DOE BINNEN DE BASIS
JOIN's in TSQL worden meestal gedaan op de FROM-regel.
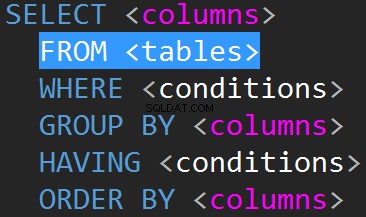
Voordat we aan iets anders beginnen, wordt de echte grote vraag:"Waarom moeten we JOIN's doen en hoe gaan we onze JOIN's eigenlijk uitvoeren?"
Het blijkt dat de gegevens van elke database waarmee we ooit werken, worden opgesplitst in meerdere tabellen. Hier zijn veel verschillende redenen voor:
- De integriteit van gegevens handhaven
- Opgeslagen ruimte besparen
- Gegevens sneller bewerken
- Zoekopdrachten flexibeler maken
Dus elke database waarmee u gaat werken, heeft die gegevens nodig om te worden samengevoegd om ze echt te laten kloppen.
Zo heb je aparte tabellen voor bestellingen en voor klanten. De vraag die wordt:"Hoe verbinden we eigenlijk alle gegevens met elkaar?" Dat is precies wat JOINs gaan doen.
HOE WORDT LID WERKT
Stel je het geval voor, wanneer we twee aparte tafels hebben en die tafels worden samengebracht door een naad te maken.
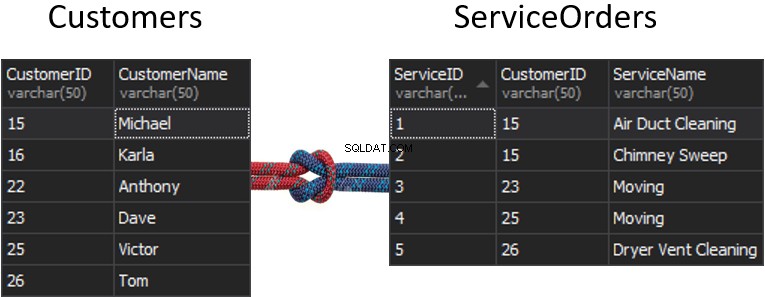
Wat gaat er gebeuren met de naad, als we van elke tabel één kolom krijgen die gebruikt gaat worden om te matchen, en die gaat bepalen welke rijen wel of niet worden geretourneerd? We hebben bijvoorbeeld Klanten aan de linkerkant en ServiceOrders aan de rechterkant. Als we alle klanten en hun bestellingen willen ontvangen, moeten we samen met deze twee tafels AANMELDEN. Hiervoor moeten we één kolom kiezen die als een naad fungeert, en uiteraard is de kolom die we gaan gebruiken CustomerID.
Trouwens, de klant-ID staat bekend als een primaire sleutel voor de linkertabel, die elke rij in de tabel Klanten op unieke wijze identificeert.
In de tabel ServiceOrders hebben we ook de kolom Klant-ID, die bekend staat als een Foreign Key . Een externe sleutel is gewoon een kolom die is ontworpen om naar een andere tabel te verwijzen. In ons geval verwijst het terug naar de tabel Klanten. Daarom gaan we al die gegevens samenbrengen door die naad te bieden.
In deze tabellen hebben we de volgende overeenkomsten:2 bestellingen voor 15 en 1 bestelling voor 23, 25 en 26. 16 en 22 zijn weggelaten.
Een belangrijk ding om hier op te merken is dat we MEERDERE tabellen kunnen DOEN . In feite is het heel gewoon om meerdere tabellen samen te voegen om enige vorm van informatie te krijgen. Als u de meest voorkomende database bekijkt, moet u mogelijk vier, vijf, zes en meer tabellen samenvoegen om de informatie te krijgen waarnaar u op zoek bent. Het is handig om een databasediagram te hebben.
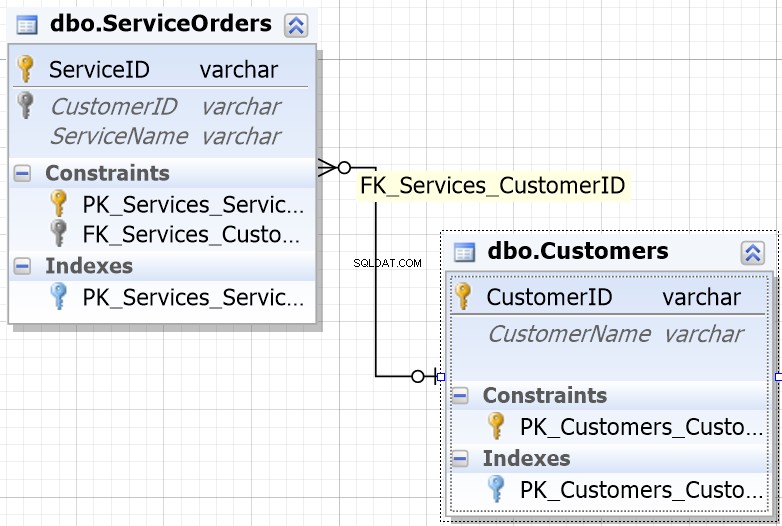
Om u in de meeste database-omgevingen te helpen, zult u merken dat de kolommen die zijn ontworpen om te worden JOINed dezelfde naam hebben.
DOE MEE AAN SYNTAX
De derde revisie van de SQL-databasequerytaal (SQL-92) regelt de JOIN-syntaxis:
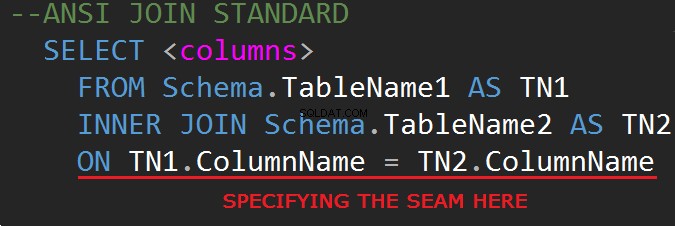
Het is mogelijk om JOINs te doen op de WHERE-regel:
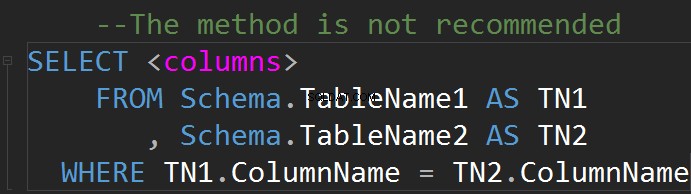
Een relatie heeft meestal een eenvoudige grafische interpretatie in de vorm van een tabel.
Beste praktijken en conventies
- Aliastabelnamen.
- Gebruik tweedelige naamgeving voor kolommen
- Plaats elke JOIN op een aparte regel
- Plaats tabellen in een logische volgorde
SLUIT TYPES
SQL Server biedt de volgende typen JOIN's:
- INNER JOIN
- OUTER JOIN
- ZELF AANMELDEN
- CROSS JOIN
Voor meer informatie over dit onderwerp kunt u dit artikel lezen over de typen joins in SQL Server en leren hoe eenvoudig het is om dergelijke query's te schrijven met behulp van SQL Complete.
INNER JOIN
Het eerste type JOIN dat we mogelijk willen uitvoeren, is de INNER JOIN. Gewoonlijk verwijzen auteurs naar dit type SQL Server JOIN's als een gewone of eenvoudige JOIN. Ze laten gewoon het INNER-voorvoegsel weg. Dit type JOIN combineert twee tabellen samen en retourneert alleen rijen van beide kanten die overeenkomen .
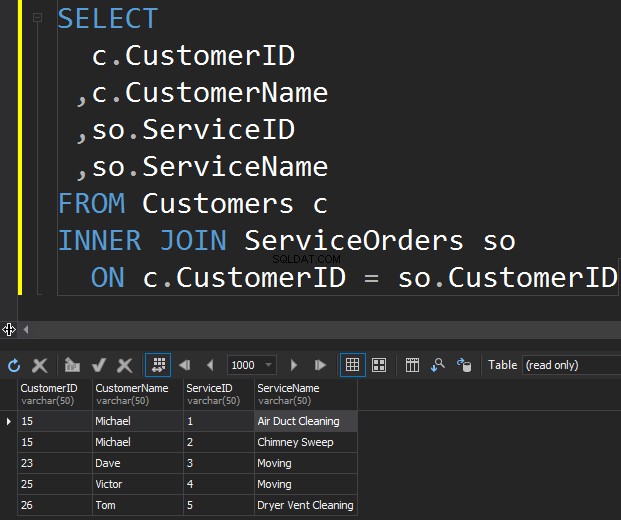
We zien Klara en Anthony hier niet omdat hun CustomerID in beide tabellen niet overeenkomt. Ik wil ook benadrukken dat de JOIN-bewerking een klant retourneert telkens wanneer deze overeenkomt met de bestelling . Er zijn twee bestellingen voor Michael en één bestelling voor Dave, Victor en Tom elk.
Samenvatting:
- INNER JOIN retourneert alleen rijen als er in beide tabellen ten minste één rij is die overeenkomt met de JOIN-voorwaarde.
- INNER JOIN elimineert de rijen die niet overeenkomen met een rij uit de andere tabel
OUTER JOIN
Outer JOIN's zijn anders omdat ze rijen van tabellen of views retourneren, zelfs als ze niet overeenkomen. Dit type JOIN is handig als u alle klanten wilt ophalen die nog nooit een bestelling hebben geplaatst. Of bijvoorbeeld als u op zoek bent naar een product dat nog nooit is besteld.
De manier waarop we onze OUTER JOINs doen, is door LEFT of RIGHT of FULL aan te geven.
Er zijn geen verschillen tussen de volgende clausules:
- LEFT OUTER JOIN =LEFT JOIN
- RIGHT OUTER JOIN =RECHTS JOIN
- VOLLEDIGE OUTER JOIN =VOLLEDIGE JOIN
Ik zou echter aanraden om de volledige clausule te schrijven, omdat dit de code leesbaarder maakt.
LEFT OUTER JOIN gebruiken
Er is geen verschil tussen LINKS of RECHTS, behalve dat we alleen naar de tabel wijzen waar we de extra rijen vandaan willen halen. In het volgende voorbeeld hebben we klanten en hun bestellingen vermeld. We gebruiken LINKS om alle klanten te krijgen die nog nooit een bestelling hebben geplaatst. We vragen SQL Server om extra rijen uit de linkertabel te halen.
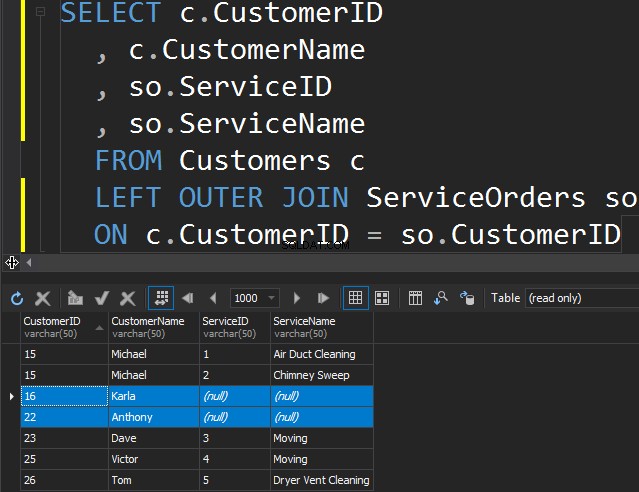
Merk op dat Karla en Anthony geen bestellingen hebben geplaatst en als gevolg daarvan krijgen we NULL-waarden voor de ServiceName en ServiceID. SQL Server weet niet wat hij daar moet plaatsen en plaatst NULL's.
RIGHT OUTER JOIN gebruiken
Om de minder populaire service uit de ServiceOrders-tabel te halen, moeten we de RECHTE richting gebruiken.
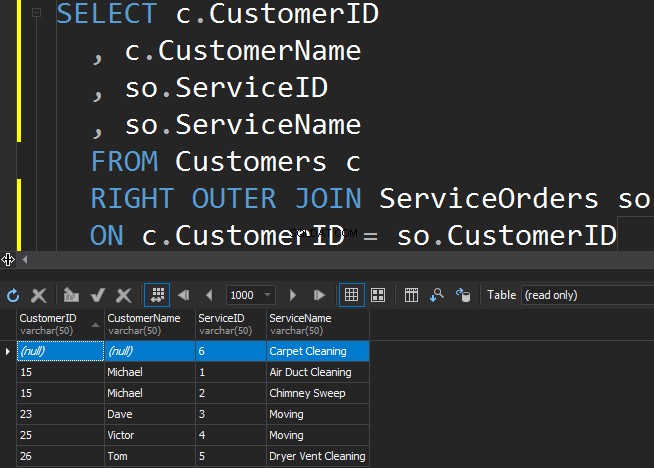
We zien dat in dit geval SQL Server extra rijen uit de juiste tabel heeft geretourneerd en dat de tapijtreinigingsservice nooit is besteld.
VOLLEDIGE OUTER JOIN gebruiken
Met dit type JOIN kunt u de niet-overeenkomende informatie krijgen door niet-overeenkomende rijen uit beide tabellen op te nemen.
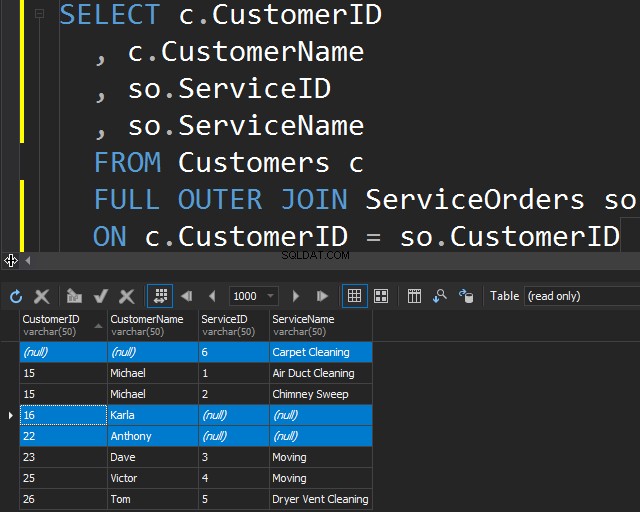
Dit kan ook handig zijn als u gegevens moet opschonen.
Samenvatting:
VOLLEDIGE OUTER JOIN
- Retourneert rijen uit beide tabellen, zelfs als ze niet overeenkomen met de JOIN-instructie
LINKS of RECHTS
- Geen verschil, behalve in de volgorde van de tabellen in de FROM-clausule
- Richting wijst naar een tafel om niet-overeenkomende rijen op te halen
ZELF AANMELDEN
Het volgende type JOINs dat we hebben is SELF JOIN. Dit is waarschijnlijk het op één na minst voorkomende type JOIN dat je ooit gaat uitvoeren. Een SELF JOIN is wanneer je een tafel op zichzelf voegt. Over het algemeen is dit een teken van een slecht ontwerp. Als u dezelfde tabel twee keer in één query wilt gebruiken, moet de tabel een alias hebben. De alias helpt de queryprocessor om te bepalen of kolommen gegevens van de rechter- of linkerkant moeten presenteren. Bovendien moet je rijen die zichzelf marcheren elimineren. Dit wordt meestal gedaan met een niet-equi-join.
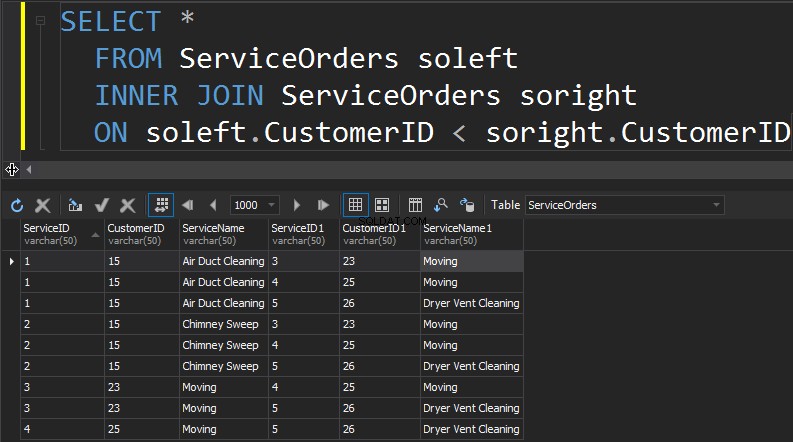
Samenvatting:
- Voeg zich AAN bij een tabel
- Over het algemeen een teken van slecht ontwerp en normalisatie
- Tabellen moeten een alias hebben
- Moet rijen filteren die met zichzelf overeenkomen
CROSS JOINS
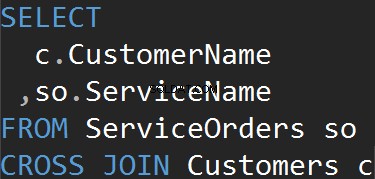
Dit type JOIN heeft niet de ON uitspraak. Elke rij van elke tafel komt overeen. Dit wordt ook wel Cartesiaans product genoemd (in het geval dat een CROSS JOIN geen WHERE-clausule heeft). U zult dit JOIN-type nauwelijks gebruiken in realistische scenario's, maar het is een goede manier om testgegevens te genereren.
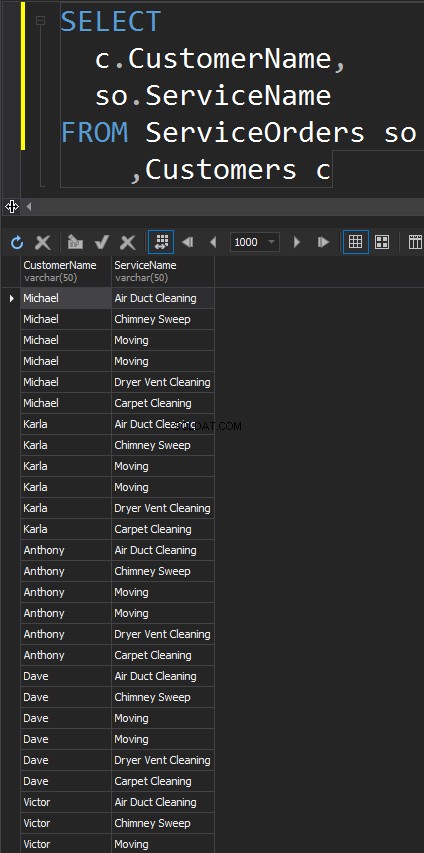
Het resultaat is een dataset, waarbij het aantal rijen in de linkertabel vermenigvuldigd met het aantal rijen in de rechtertabel. Uiteindelijk zien we dat elke klant overeenkomt met elke afzonderlijke service.
We krijgen hetzelfde resultaat als we de CROSS JOIN-clausule expliciet gebruiken.
Samenvatting:
- Alle rijen van elke tafel komen overeen
- Geen ON-verklaring
- Kan worden gebruikt om testgegevens te genereren
DOE MEE MET ALGORITHMEN
In het eerste deel van het artikel hebben we het gehad over logische JOIN-operators die SQL Server gebruikt tijdens het parseren en binden van query's. Dit zijn:
- INNER JOIN
- OUTER JOIN
- CROSS JOIN
De logische operatoren zijn conceptueel en verschillen van de fysieke Doet mee. Anders gezegd, logische JOIN's doen niet echt mee bepaalde tabelkolommen. Een enkele logische JOIN kan overeenkomen met veel fysieke JOIN's. SQL Server vervangt logische JOIN's door fysieke JOIN's tijdens optimalisatie. SQL Server heeft de volgende fysieke JOIN-operators:
- GENSTE LUS
- MERGE
- HASH
Een gebruiker schrijft of gebruikt dit type JOINS niet. Ze maken deel uit van de SQL Server-engine en SQL Server gebruikt ze intern om logische JOIN's te implementeren. Wanneer u het uitvoeringsplan onderzoekt, merkt u wellicht dat SQL Server logische JOIN-operators vervangt door een van de drie fysieke operators.
Aangesloten lus toevoegen
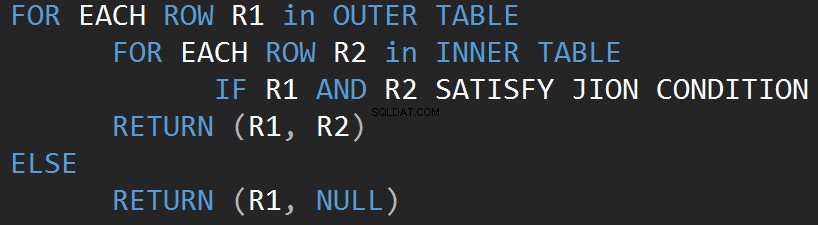
Laten we beginnen met de eenvoudigste operator, namelijk Nested Loop. Het algoritme vergelijkt elke rij van de ene tabel (buitenste tabel) met elke rij van de andere tabel (binnenste tabel) op zoek naar rijen die voldoen aan het JOIN-predikaat.
De volgende pseudo-code beschrijft het inner geneste join loop-algoritme:

De volgende pseudo-code beschrijft het buitenste geneste join-lus-algoritme:
De grootte van de invoer heeft rechtstreeks invloed op de algoritmekosten. De input groeit, de kosten groeien ook. Dit type JOIN-algoritme is efficiënt bij kleine invoer. SQL Server schat een JOIN-predikaat voor elke rij in beide invoer.
Beschouw de volgende zoekopdracht als een voorbeeld, waarmee klanten en hun bestellingen worden opgehaald.
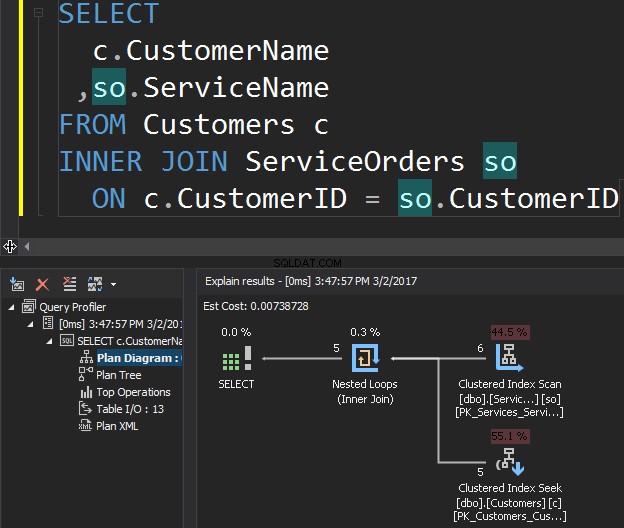
De operator Clustered Index Scan is de uiterlijke invoer en de Clustered Index Seek is de innerlijke input . De geneste lus-operator vindt daadwerkelijk overeenkomsten. De operator zoekt naar elk record in de buitenste invoer en vindt overeenkomende rijen in de binnenste invoer. SQL Server voert de Clustered Index Scan-bewerking (externe invoer) slechts één keer uit om alle relevante records op te halen. Clustered Index Seek wordt uitgevoerd voor elk record van de buitenste invoer. Om dit te bevestigen, gaat u met de cursor naar het operatorpictogram en bekijkt u de tooltip.
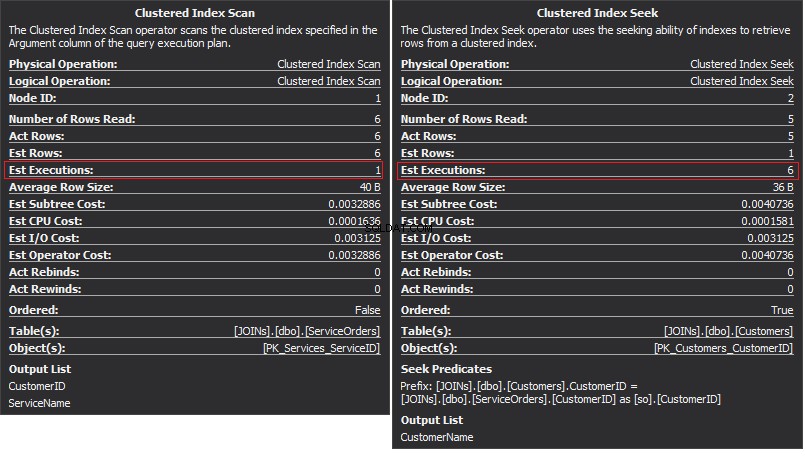
Laten we het hebben over de complexiteit. Stel dat N is het rijnummer voor de buitenste uitvoer. M is het totale rijnummer in de SalesOrders tafel. De complexiteit van de query is dus O(NLogM) waar LogM is de complexiteit van elke zoektocht in de innerlijke invoer. De optimizer selecteert deze operator elke keer wanneer de buitenste invoer klein is en de binnenste invoer een index in de kolom bevat die als naad fungeert. Daarom zijn indexen en statistieken essentieel voor dit JOIN-type, anders zou SQL Server per ongeluk kunnen denken dat er niet zoveel rijen zijn in een van de ingangen. Het is beter om één tabelscan uit te voeren in plaats van Index Seek 100K keer uit te voeren. Vooral wanneer de interne invoergrootte meer dan 100K is.
Samenvatting:
Geneste lussen
- Complexiteit:O(NlogM)
- Meestal toegepast als een tafel klein is
- De grotere tabel bevat een index die het zoeken mogelijk maakt met de join-sleutel
Aanmelden samenvoegen
Sommige ontwikkelaars begrijpen Hash en Merge JOIN's niet helemaal en associëren ze vaak met slecht presterende zoekopdrachten.
In tegenstelling tot Nested Loop die elk JOIN-predikaat accepteert, vereist de Merge Join minstens één equi-join. Bovendien moeten beide invoer worden gesorteerd op de JOIN-toetsen.
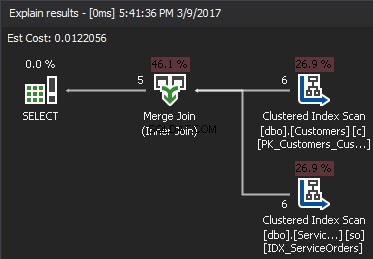
De pseudo-code voor het MERGE JOIN-algoritme:
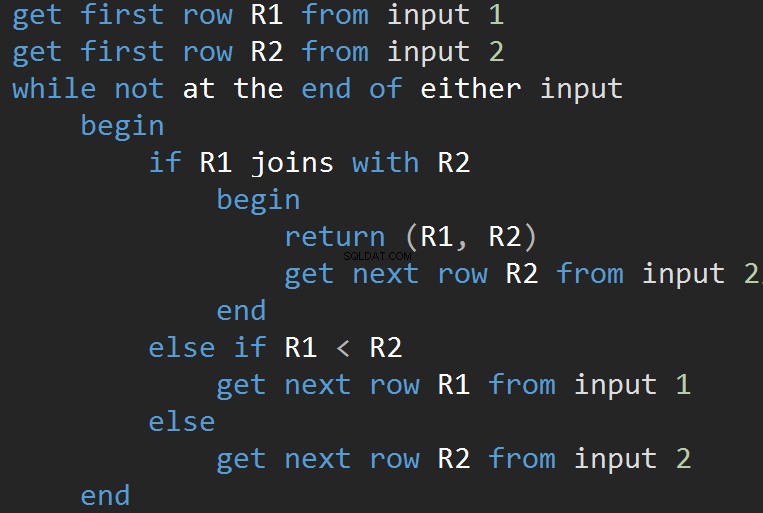
Het algoritme vergelijkt twee gesorteerde invoer. Een rij tegelijk. Als er een gelijkheid is tussen twee rijen, voegt het algoritme de rijen samen en gaat verder. Zo niet, dan negeert het algoritme de minste van de twee invoer en gaat verder. In tegenstelling tot de geneste lus zijn de kosten hier evenredig met de som van het aantal invoerrijen. In termen van complexiteit - O(N+M). Daarom is dit type JOIN vaak beter voor grote invoer.
De volgende animatie laat zien hoe het MERGE JOIN-algoritme daadwerkelijk tabelrijen samenvoegt.
Samenvatting
- Complexiteit:O(N+M)
- Beide invoer moet worden gesorteerd op de samenvoegsleutel
- Er wordt een gelijkheidsoperator gebruikt
- Uitstekend voor grote tafels
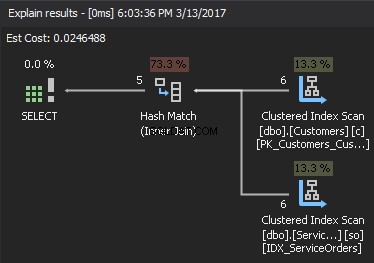
Hash-deelname
Hash Join is zeer geschikt voor grote tabellen zonder bruikbare index. Op de eerste stap - bouwfase het algoritme creëert een hash-index in het geheugen op de invoer aan de linkerkant. De tweede stap heet de sondefase . Het algoritme doorloopt de invoer aan de rechterkant en vindt overeenkomsten met behulp van de index die tijdens de bouwfase is gemaakt. Als we eerlijk zijn, is het geen goed teken wanneer de optimizer dit type JOIN-algoritme kiest.
Er zijn twee belangrijke concepten die ten grondslag liggen aan dit type JOINs:hashfunctie en hashtabel.
Een hash-functie is een functie die kan worden gebruikt om gegevens van variabele grootte toe te wijzen aan gegevens van vaste grootte.
Een hashtabel is een gegevensstructuur die wordt gebruikt om een associatieve array te implementeren, een structuur die sleutels aan waarden kan toewijzen. Een hashtabel gebruikt een hashfunctie om een index te berekenen in een array van buckets of slots, waaruit de gewenste waarde kan worden gevonden.
Op basis van de beschikbare statistieken kiest SQL Server de kleinste invoer als buildinvoer en gebruikt deze om een hashtabel in het geheugen te bouwen. Als er niet genoeg geheugen is, gebruikt SQL Server fysieke schijfruimte in TempDB. Zodra de hashtabel is gemaakt, haalt SQL Server de gegevens op uit de testinvoer (grotere tabel) en vergelijkt deze met de hashtabel met behulp van een hash-matchfunctie. Als resultaat retourneert het overeenkomende rijen.
Als we naar het uitvoeringsplan kijken, is het rechtsbovenste element de build input , en het element rechtsonder is de sondeinvoer . Als beide ingangen extreem groot zijn, zijn de kosten te hoog.
Neem het volgende aan om de complexiteit te schatten:
hc – complexiteit van het maken van een hashtabel
hm – complexiteit van de hash match-functie
N – kleinere tafel
M – grotere tafel
J – complexiteit toevoeging voor de dynamische berekening en creatie van de hash-functie
De complexiteit zal zijn:O(N*hc + M*hm + J)
De optimizer gebruikt statistieken om de kardinaliteit van de waarde te bepalen. Vervolgens creëert het dynamisch een hash-functie die gegevens verdeelt in vele buckets van gelijke grootte. Het is vaak moeilijk om de complexiteit van het aanmaakproces van de hashtabel in te schatten, evenals de complexiteit van elke hash-match vanwege het dynamische karakter. Het uitvoeringsplan kan zelfs onjuiste schattingen weergeven omdat de optimizer al deze dynamische bewerkingen tijdens de uitvoeringstijd uitvoert. In sommige gevallen kan het uitvoeringsplan aantonen dat Nested Loop duurder is dan Hash Join, maar in feite wordt de Hash Join langzamer uitgevoerd vanwege een onjuiste kostenraming.
Samenvatting
- Complexiteit:O(N*hc +M*hm +J)
- Toegangstype laatste redmiddel
- Gebruikt een hashtabel en een dynamische hash-matchfunctie om rijen te matchen
Handige producten:
SQL Compleet - schrijf, verfraai, refactor uw code eenvoudig en verhoog uw productiviteit.