Inleiding
In dit artikel gaan we het hebben over het gebruik van de nvarchar data type. We zullen onderzoeken hoe SQL Server dit gegevenstype op de schijf opslaat en hoe het in het RAM wordt verwerkt. We zullen ook onderzoeken hoe de grootte van nvarchar de prestaties kan beïnvloeden.
Werkelijke gegevensgrootte:nchar vs nvarchar
We gebruiken nvarchar wanneer de grootte van kolomgegevensinvoer waarschijnlijk aanzienlijk zal variëren. De opslaggrootte (in bytes) is twee keer zo groot als de werkelijke lengte van de ingevoerde gegevens + 2 bytes. Hierdoor kunnen we schijfopslag besparen in vergelijking met het gebruik van nchar data type. Laten we eens kijken naar het volgende voorbeeld. We maken twee tabellen. Een tabel bevat nvarchar-kolommen, een andere tabel bevat nchar-kolommen. De grootte van de kolom is 2000 tekens (4000 bytes).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
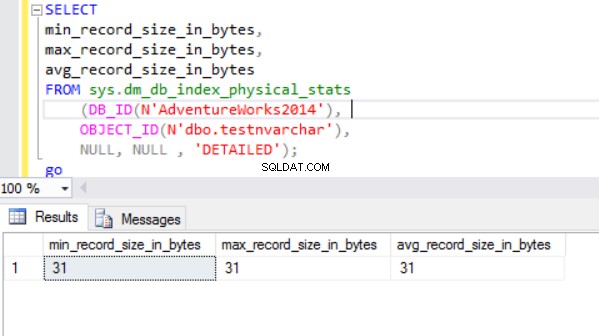
De werkelijke rijgrootte is:
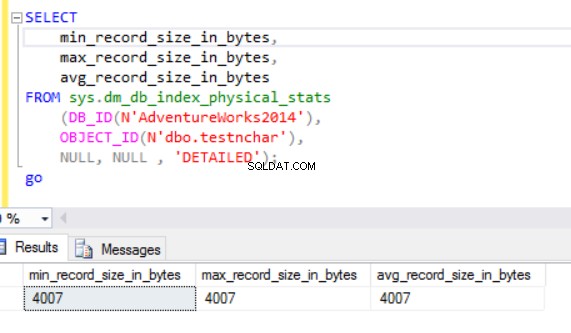
Zoals we kunnen zien, is de werkelijke rijgrootte van het nvarchar-gegevenstype veel kleiner dan het nchar-gegevenstype. In het geval van het nchar-gegevenstype gebruiken we ~4000 bytes om een tekenreeks van 10 symbolen op te slaan. We gebruiken ~20 bytes om dezelfde tekenreeks op te slaan in het geval van het nvarchar-gegevenstype.
De SQL Server-engine verwerkt gegevens in RAM (bufferpool). Hoe zit het met de rijgrootte in het geheugen?
Werkelijke gegevensgrootte:HDD versus RAM
Laten we de volgende query uitvoeren:
SELECT col1 FROM dbo.testnchar;

Er is geen verschil tussen schijf- en RAM-gebruik in het geval van een tekenreeks met een vaste lengte.
SELECT col1 FROM dbo.testnvarchar;

We kunnen zien dat de SQL Server Engine het geheugen heeft opgevraagd voor slechts de helft van de aangegeven rijgrootte (2000 bytes in plaats van de werkelijke 20 bytes) en enkele bytes voor aanvullende informatie. Aan de ene kant verminderen we het gebruik van schijfruimte, maar aan de andere kant kunnen we het gevraagde RAM-geheugen opblazen. Dit is een neveneffect van het gebruik van de verschillende karakterdatatypes. Deze bijwerking kan in sommige gevallen een grote impact hebben op de middelen.
FORMAT():RAM gevraagd vs RAM gebruikt
We gebruiken de FORMAT-functie, die een opgemaakte waarde retourneert met de opgegeven indeling en optionele cultuur. De retourwaarde is nvarchar of nul. De lengte van de retourwaarde wordt bepaald door het formaat . FORMAT(getdate(), 'yyyyMMdd','en-US') resulteert in '20170412'. We hebben 16 bytes nodig om dit resultaat op te slaan in de kolom op de schijf (het resultaat zal nvarchar(8) zijn). Wat is de gegevensgrootte in het RAM voor de specifieke gegevens?
Laten we de volgende query uitvoeren. We gebruiken de volgende omgeving:
- AdventureWorks2014
- MS SQL 2016 ontwikkelingseditie
- dbo.Customer (19.820.000 records) bevat gegevens van Sales.Customer (19.820 records zijn 1000 keer geüpload)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Het uitvoeringsplan voor de query is vrij eenvoudig:

De eerste bewerking is "Geclusterde indexscan" op de dbo.Klanttabel. ~19 000 000 records zijn gelezen. Geschatte gegevensgrootte is 435 Mb.
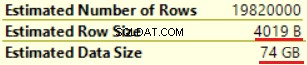
De volgende bewerking is "Compute Scalar" (berekening van de FORMAT()-functie). Het resultaat is nogal onverwacht aangezien we een tekenreeks van 16 bytes formatteren. De rijgrootte nam drastisch toe van 23 bytes tot 4019 bytes. Hetzelfde geldt voor de geschatte gegevensgrootte - van 435 MB tot 74 GB. We kunnen zien dat FORMAT() NVARCHAR(4000) retourneert.
MS SQL Server 2016 heeft het grote vermogen om overmatige geheugentoelage te tonen. We kunnen de waarschuwing zien in de laatste bewerking (T-SQL SELECT INTO):
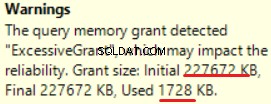
Dit is "over-toegekend" van het geheugen:meer dan 90% van het toegekende geheugen wordt niet gebruikt.
De zoektijdstatistieken zijn:
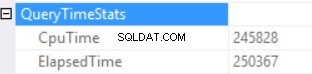
De lange uitvoeringstijd is afhankelijk van een niet-effectieve uitvoering van de scalaire functie en een neveneffect van een Excessive Memory Grant – Hash Match (Right Outer Join). We hebben een cumulatief effect van twee verschillende oorzaken:uitvoering van meerdere scalaire functies en overmatige geheugentoekenning.
De SQL Server-engine kan niet meer dan 25% van het toegestane geheugen per query toekennen. We kunnen dit bedrag wijzigen in de enterprise-editie van de MS SQL Server met behulp van de resource-gouverneur. Het toegekende geheugen bestaat uit twee delen:verplicht en aanvullend. Een vereist geheugen wordt gebruikt voor de interne behoeften - voor sorteer- en hash-join-bewerkingen. Extra geheugen is gebaseerd op de geschatte gegevensgrootte. Als zowel het vereiste als het extra geheugen de limiet van 25% overschrijdt, verleent de SQL Server-engine nog eens 25% van het beschikbare geheugen. Lees de SQL Server-geheugentoekenningspost voor details.
Laten we dezelfde query uitvoeren zonder de functie FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
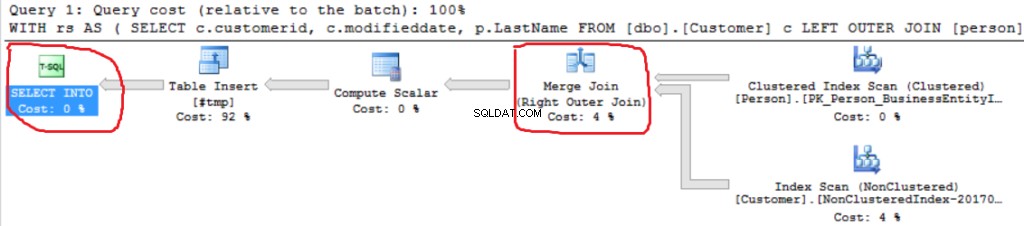
We kunnen een andere Right Outer Join-implementatie zien (Merge Join in plaats van Hash Join).
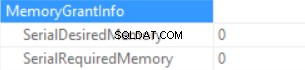
Geheugentoekenningsinfo is (als er geen sortering is en de Hash Join SQL Server kan geen geheugen toekennen):
De querytijd Statistieken zijn (tijd wordt voorspelbaar verminderd:geen scalaire functie-uitvoering, de geschatte gegevensgrootte is kleiner dan in het vorige voorbeeld):

Dus we blazen het "toegekende geheugen" op tot 222 MB (en gebruiken er minder dan 2 MB van) door de functie FORMAT() te gebruiken. Het datavolume in het voorbeeld is klein.
Lange uitvoeringsquery
Denk aan de echte SQL-query vanuit een productieomgeving. Deze query is uitgevoerd tijdens een batchlaadproces (geen klassiek transactiescenario). We gebruiken MS SQL Server gestart op Amazon Web Services (AWS, Amazon Relational Database Service). Kenmerken van DB-instances zijn 160 GB RAM (per query kan niet meer dan ~30 GB RAM worden toegewezen) en 40 vCPU. De SQL-query was bijna hetzelfde als in het bovenstaande voorbeeld (het verschil zit in het aantal tabellen en de gegevensgrootte):CTE omvatte join tussen 6 tabellen. De "Mastertabel" (een tabel in de FROM-clausule) bevat ~175'000'000 records en de gegevensgrootte is 20 GB. De opzoektabellen (rechtertabel in de JOIN-component) zijn klein (in vergelijking met de hoofdtabel). De SQL-query bevat twee aanroepen van de functie FORMAT() (twee kolommen uit de tabel "master table" zijn de parameter van deze functie).
Productiequery ziet er als volgt uit:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
De "foto" van het uitvoeringsplan staat hieronder (het uitvoeringsplan is eenvoudig:sequentiële samenvoegingen en sortering (DISTINCT-sleutelwoorden) bovenaan):

Laten we de informatie in detail bekijken.
De eerste handeling is "Tafelscan" (alles is correct, geen verrassingen):

De bewerking "Scalar compute" vergroot zowel de geschatte rijgrootte als de geschatte rijgrootte (van 19 GB tot 1,3 TB). Twee aanroepen van de functie FORMAT() voegden ongeveer 8000 bytes toe aan de geschatte rijgrootte (maar de werkelijke gegevensgrootte is kleiner).

Een van de JOIN-bewerkingen (Hash Match, Right Outer Join) gebruikt niet-unieke kolommen uit de rechtertabel. Bij enkele records maakt het niet uit. Dit is niet ons geval. Als gevolg hiervan neemt de geschatte gegevensgrootte toe tot ~ 2,4 TB.

Er is ook een waarschuwing (niet genoeg RAM om deze bewerking te verwerken):
De SQL-query bevat bovenaan een bewerking "Distinct Sort", die eruitziet als de kers op de taart. We kunnen daar dezelfde waarschuwing zien.
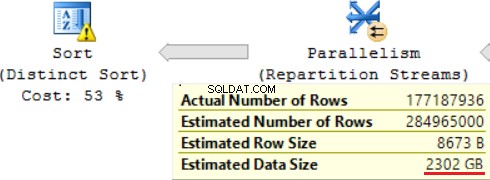
Een resultaat van het gebruik van een scalaire functie is een lange tijd voor het uitvoeren van query's:24 uur. Een van de oorzaken van dit probleem is een onjuiste schatting van de gevraagde gegevensgrootte op basis van "Geschatte gegevensgrootte". Zonder de functie FORMAT() te gebruiken, voert MS SQL Server deze query in 2 uur uit.
Conclusie
Ontwikkelaars moeten voorzichtig zijn bij het gebruik van de gegevenstypen nvarchar en varchar. Het selecteren van redundante datatypes voor kolommen kan leiden tot het opblazen van het benodigde geheugen. Als gevolg hiervan wordt RAM verspild en worden de databaseprestaties verslechterd.