SQL Server biedt ons verschillende oplossingen om een databasetabel of tabellen te repliceren of te archiveren naar een andere database, of dezelfde database met verschillende namen. Als SQL Server-ontwikkelaar of databasebeheerder kunt u te maken krijgen met situaties waarin u moet controleren of de gegevens in deze twee tabellen identiek zijn, en als de gegevens per ongeluk niet tussen deze twee tabellen worden gerepliceerd, moet u de gegevens synchroniseren tussen de tafels. Als u bovendien een foutbericht ontvangt dat het gegevenssynchronisatie- of replicatieproces verbreekt vanwege schemaverschillen tussen de bron- en doeltabellen, moet u een gemakkelijke en snelle manier vinden om de schemaverschillen te identificeren. het schema aan beide kanten identiek en hervat het gegevenssynchronisatieproces.
In andere situaties heeft u een gemakkelijke manier nodig om het antwoord JA of NEE te krijgen, of de gegevens en het schema van twee tabellen identiek zijn of niet. In dit artikel bespreken we de verschillende manieren om de gegevens en het schema tussen twee tabellen te vergelijken. De methoden in dit artikel zullen tabellen vergelijken die in verschillende databases worden gehost, wat het ingewikkelder scenario is, en kunnen ook gemakkelijk worden gebruikt om de tabellen in dezelfde database met verschillende namen te vergelijken.
Voordat we de verschillende methoden en hulpmiddelen beschrijven die kunnen worden gebruikt om de tabelgegevens en schema's te vergelijken, zullen we onze demo-omgeving voorbereiden door twee nieuwe databases te maken en één tabel in elke database te maken, met één klein verschil in gegevenstype tussen deze twee tabellen, zoals getoond in de CREATE DATABASE en CREATE TABLE T-SQL-statements hieronder:
CREATE DATABASE TESTDB CREATE DATABASE TESTDB2 CREATE TABLE TESTDB.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address VARCHAR (500) ) GO CREATE TABLE TESTDB2.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address NVARCHAR (400) ) GO
Nadat we de databases en tabellen hebben gemaakt, vullen we de twee tabellen met vijf identieke rijen en voegen we vervolgens een nieuw record in alleen in de eerste tabel, zoals weergegeven in de INSERT INTO T-SQL-instructies hieronder:
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB2.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('DDD','EEE','FFF')
GO Nu is de testomgeving klaar om te beginnen met het beschrijven van de gegevens en schemavergelijkingsmethoden.
Tabelgegevens vergelijken met een LEFT JOIN
Het LEFT JOIN T-SQL-sleutelwoord wordt gebruikt om gegevens uit twee tabellen op te halen, door alle records uit de linkertabel te retourneren en alleen de overeenkomende records uit de rechtertabel en NULL-waarden uit de rechtertabel wanneer er geen overeenkomst is tussen de twee tabellen.
Voor gegevensvergelijkingsdoeleinden kan het sleutelwoord LEFT JOIN worden gebruikt om twee tabellen te vergelijken, gebaseerd op de gemeenschappelijke unieke kolom, zoals de ID-kolom in ons geval, zoals in de onderstaande SELECT-instructie:
SELECT * FROM TESTDB.dbo.FirstComTable F LEFT JOIN TESTDB2.dbo.FirstComTable S ON F.ID =S.ID
De vorige query retourneert de gemeenschappelijke vijf rijen die in de twee tabellen bestaan, naast de rij die in de eerste tabel bestaat en ontbreekt in de tweede, door NULL-waarden aan de rechterkant van het resultaat weer te geven, zoals hieronder weergegeven:
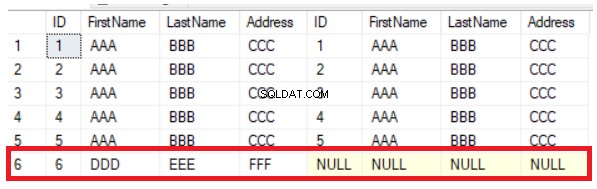
U kunt eenvoudig uit het vorige resultaat afleiden dat de zesde kolom die in de eerste tabel bestaat, wordt gemist in de tweede tabel. Om de rijen tussen de tabellen te synchroniseren, moet u het nieuwe record handmatig in de tweede tabel invoegen. De LEFT JOIN-methode is handig bij het verifiëren van de nieuwe rijen, maar helpt niet bij het bijwerken van de kolomwaarden. Als u de waarde van de adreskolom van de 5e rij wijzigt, zal de LEFT JOIN-methode die wijziging niet detecteren, zoals hieronder duidelijk wordt weergegeven:
Tabelgegevens vergelijken met BEHALVE clausule
De instructie EXCEPT retourneert de rijen van de eerste query (linkerquery) die niet worden geretourneerd door de tweede query (rechterquery). Met andere woorden, de EXCEPT-instructie retourneert het verschil tussen twee SELECT-instructies of tabellen, wat ons helpt om de gegevens in deze tabellen gemakkelijk te vergelijken.
De EXCEPT-instructie kan worden gebruikt om de gegevens in de eerder gemaakte tabellen te vergelijken, door het verschil te nemen tussen de SELECT * -query uit de eerste tabel en de SELECT * -query uit de tweede tabel, met behulp van de onderstaande T-SQL-instructies:
SELECT * FROM TESTDB.dbo.FirstComTable F EXCEPT SELECT * FROM TESTDB2.dbo. FirstComTable S
Het resultaat van de vorige zoekopdracht is de rij die beschikbaar is in de eerste tabel en niet beschikbaar in de tweede, zoals hieronder weergegeven:
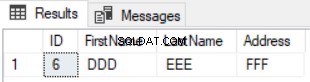
Het gebruik van de EXCEPT-instructie om twee tabellen te vergelijken is beter dan de LEFT JOIN-instructie, omdat de bijgewerkte records worden opgevangen in het resultaat van de gegevensverschillen. Stel dat we het adres van rijnummer 5 in de tweede tabel hebben bijgewerkt en het verschil opnieuw hebben gecontroleerd met de instructie EXCEPT, dan zult u zien dat rijnummer 5 wordt geretourneerd met het resultaat van de verschillen zoals hieronder weergegeven:
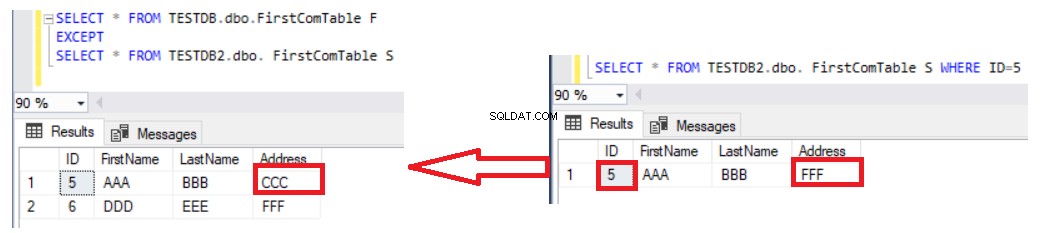
Het enige nadeel van het gebruik van de EXCEPT-instructie om de gegevens in twee tabellen te vergelijken, is dat u de gegevens handmatig moet synchroniseren door een INSERT-instructie te schrijven voor de ontbrekende records in de tweede tabel. Houd er rekening mee dat de twee tabellen die worden vergeleken, sleuteltabellen zijn om het juiste resultaat te krijgen, met een unieke sleutel die wordt gebruikt voor vergelijking. Als we de ID-unieke kolom uit de SELECT-instructie aan beide zijden van de EXCEPT-instructie verwijderen en de rest van de niet-sleutelkolommen opsommen, zoals in de onderstaande instructie:
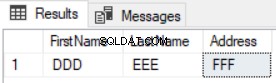
SELECT FirstName, LastName, Address FROM TESTDB.dbo. FirstComTable F EXCEPT SELECT FirstName, LastName, Address FROM TESTDB2.dbo. FirstComTable S
Het resultaat laat zien dat alleen de nieuwe records worden geretourneerd en de bijgewerkte records niet worden weergegeven, zoals weergegeven in het onderstaande resultaat:
Tabelgegevens vergelijken met behulp van een UNION ALL … GROUP BY
Het UNION ALL-statement kan ook worden gebruikt om de gegevens in twee tabellen te vergelijken, op basis van een unieke sleutelkolom. Om de UNION ALL-instructie te gebruiken om het verschil tussen twee tabellen te retourneren, moet u de kolommen die u wilt vergelijken in de SELECT-instructie vermelden en deze kolommen gebruiken in de GROUP BY-component, zoals weergegeven in de T-SQL-query hieronder:
SELECT DISTINCT *
FROM
(
SELECT * FROM
( SELECT * FROM TESTDB.dbo. FirstComTable
UNION ALL
SELECT * FROM TESTDB2.dbo. FirstComTable) Tbls
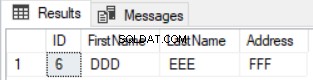
GROUP BY ID,FirstName, LastName, Address
HAVING COUNT(*)<2) Diff En alleen de rij die bestaat in de eerste tabel en gemist wordt in de tweede tabel zal worden geretourneerd zoals hieronder getoond:
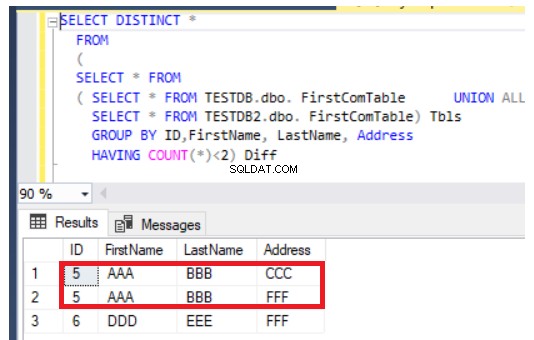
De vorige query werkt ook prima in het geval van het bijwerken van records, maar op een andere manier. Het zal de nieuw ingevoegde records retourneren naast de bijgewerkte kolommen van beide tabellen, zoals in het geval van rij nummer 5, hieronder weergegeven:
Tabelgegevens vergelijken met SQL Server Data Tools
SQL Server Data Tools, ook bekend als SSDT, gebouwd over Microsoft Visual Studio kunnen eenvoudig worden gebruikt om de gegevens in twee tabellen met dezelfde naam te vergelijken, op basis van een unieke sleutelkolom, gehost in twee verschillende databases en de gegevens in deze tabellen te synchroniseren , of genereer een synchronisatiescript om later te gebruiken.
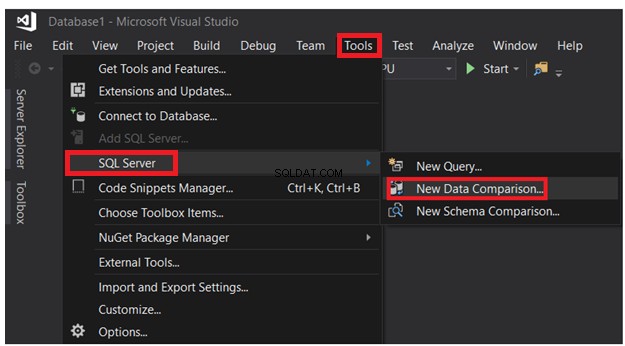
Klik in het geopende SSDT-venster op het menu Extra -> SQL Server-lijst en kies deNieuwe gegevensvergelijking optie, zoals hieronder getoond:
In het weergegeven verbindingsvenster kunt u kiezen uit de eerder verbonden sessies, of u kunt het venster Verbindingseigenschappen vullen met de SQL Server-naam, referenties en de databasenaam en vervolgens op Verbinden klikken. , zoals hieronder weergegeven:

Specificeer in de weergegeven wizard Nieuwe gegevensvergelijking de namen van de bron- en doeldatabases en de vergelijkingsopties die worden gebruikt in het tabellenvergelijkingsproces, en klik vervolgens op Volgende , zoals hieronder weergegeven:
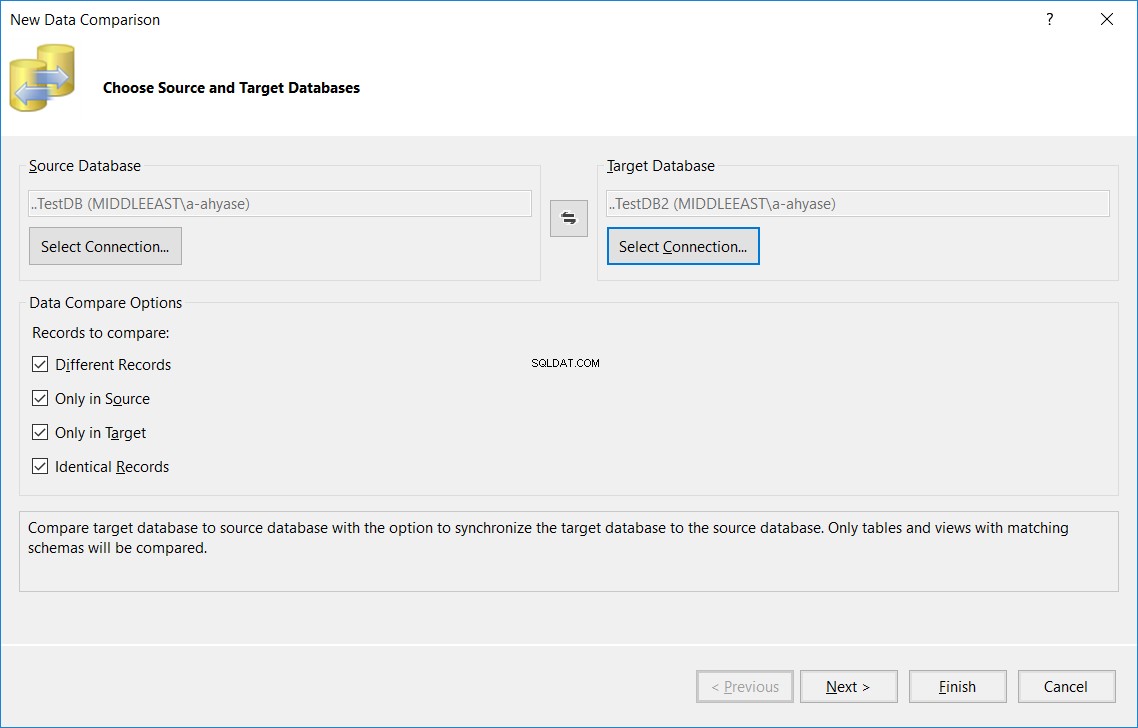
Geef in het volgende venster de naam van de tabel op, die dezelfde naam moet hebben in de bron- en doeldatabases, die in beide databases zal worden vergeleken en klik opVoltooien , zoals hieronder:
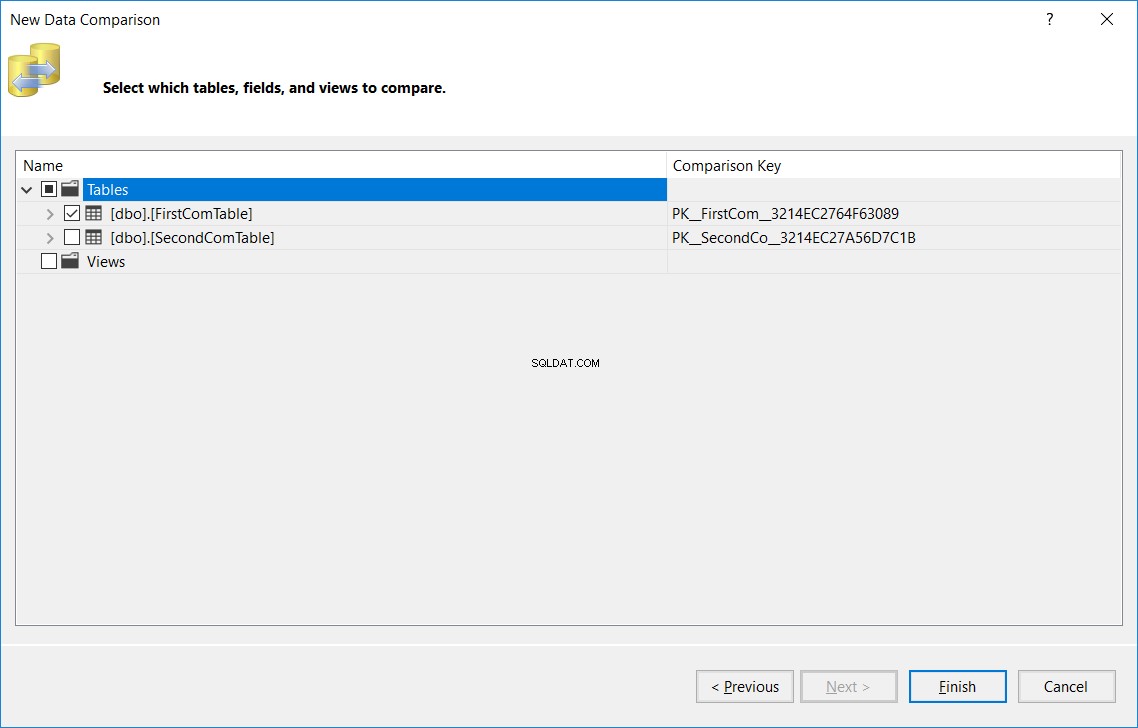
Het weergegeven resultaat toont u het aantal records dat is gevonden in de bron en gemist in het doel, gevonden in het doel en gemist in de bron, het aantal bijgewerkte records met dezelfde sleutel en verschillende kolomwaarden (verschillende records) en tot slot het aantal identieke records gevonden in beide tabellen, zoals hieronder weergegeven:
Klik op de tabelnaam in het vorige resultaat, u vindt een gedetailleerd overzicht van deze bevindingen, zoals hieronder weergegeven:

U kunt dezelfde tool gebruiken om een script te genereren om de bron- en doeltabellen te synchroniseren of de doeltabel rechtstreeks bijwerken met de ontbrekende of andere wijzigingen, zoals hieronder:
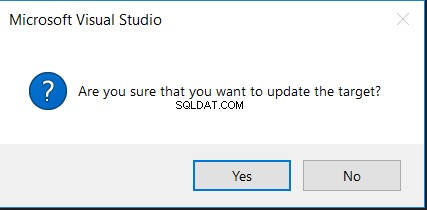
Als u op de optie Script genereren klikt, wordt een INSERT-instructie weergegeven met de ontbrekende kolom in de doeltabel, zoals hieronder weergegeven:
BEGIN TRANSACTIE
BEGIN TRANSACTION SET IDENTITY_INSERT [dbo].[FirstComTable] ON INSERT INTO [dbo].[FirstComTable] ([ID], [FirstName], [LastName], [Address]) VALUES (6, N'DDD', N'EEE', N'FFF') SET IDENTITY_INSERT [dbo].[FirstComTable] OFF COMMIT TRANSACTION
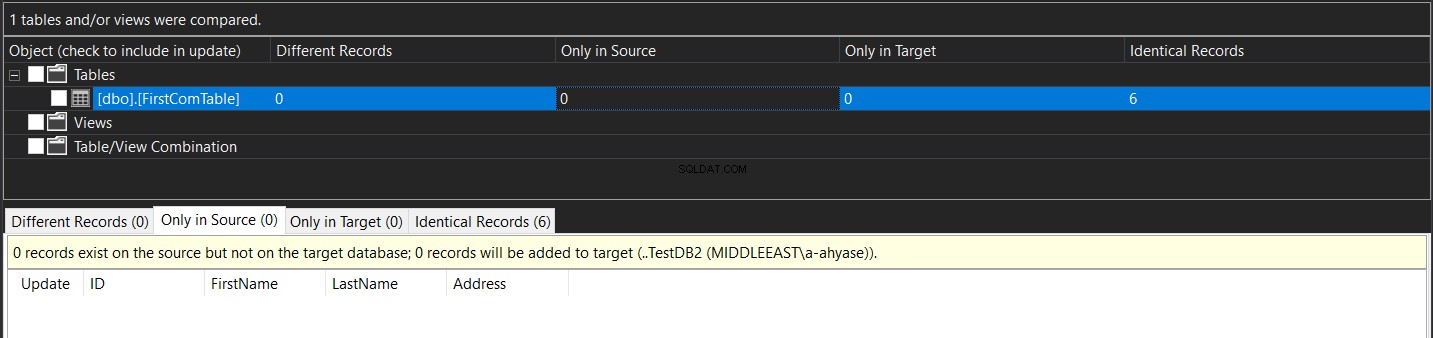
Als u de optie Doel bijwerken kiest, wordt u eerst om bevestiging gevraagd om de wijziging uit te voeren, zoals in het onderstaande bericht:
Na de synchronisatie zult u zien dat de gegevens in de twee tabellen identiek zullen zijn, zoals hieronder weergegeven:
Tabelgegevens vergelijken met het externe hulpprogramma "dbForge Studio for SQL Server"
In de SQL Server-wereld vindt u een groot aantal tools van derden die het leven van databasebeheerders en ontwikkelaars gemakkelijk maken. Een van deze tools, die de databasebeheertaken een fluitje van een cent maken, is de dbForge Studio voor SQL Server, die ons voorziet van eenvoudige manieren om de databasebeheer- en ontwikkelingstaken uit te voeren. Deze tool kan ons ook helpen bij het vergelijken van de gegevens in de databasetabellen en het synchroniseren van deze tabellen.
Kies in het menu Vergelijking Nieuwe gegevensvergelijking optie, zoals hieronder getoond:
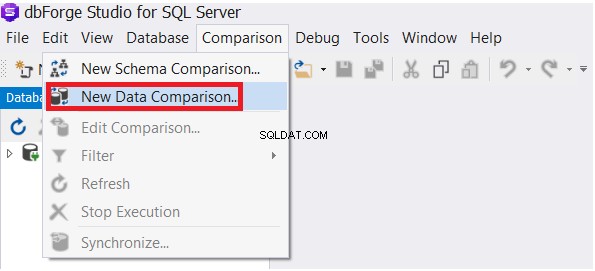
Geef in de wizard Nieuwe gegevensvergelijking de bron- en doeldatabase op en klik vervolgens op Volgende :
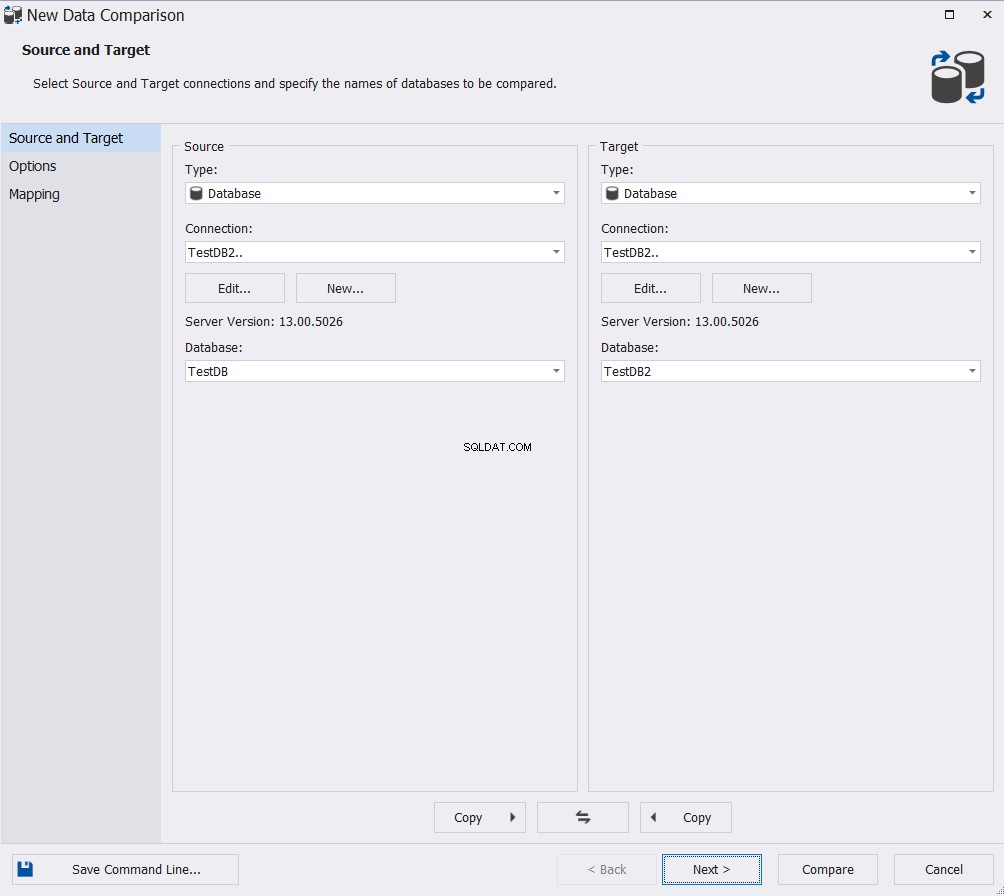
Kies de geschikte opties uit het brede scala aan beschikbare kaart- en vergelijkingsopties en klik op Volgende :
Geef de naam op van de tabel of tabellen die zullen deelnemen aan het gegevensvergelijkingsproces. De wizard geeft een waarschuwingsbericht weer voor het geval er schemaverschillen zijn tussen de bron- en doeldatabasetabellen. Klik op Vergelijken om verder te gaan:
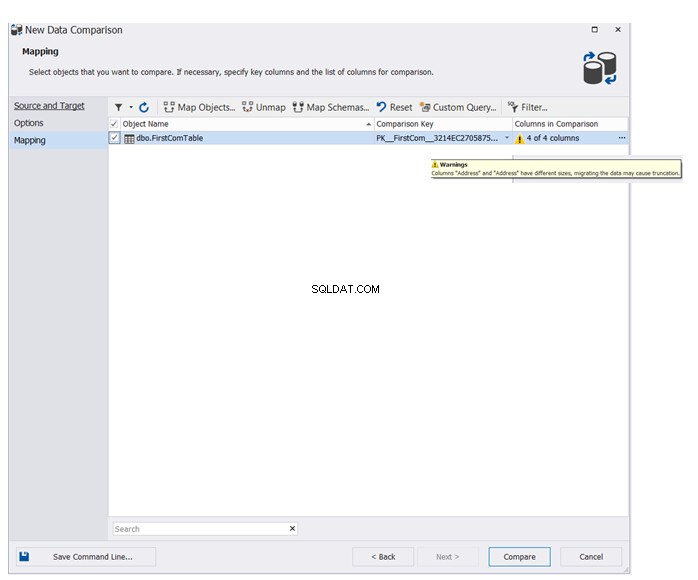
Het uiteindelijke resultaat toont u in detail de gegevensverschillen tussen de bron- en doeltabellen, met de mogelijkheid om te klikken  om de bron- en doeltabellen te synchroniseren, zoals hieronder weergegeven:
om de bron- en doeltabellen te synchroniseren, zoals hieronder weergegeven:
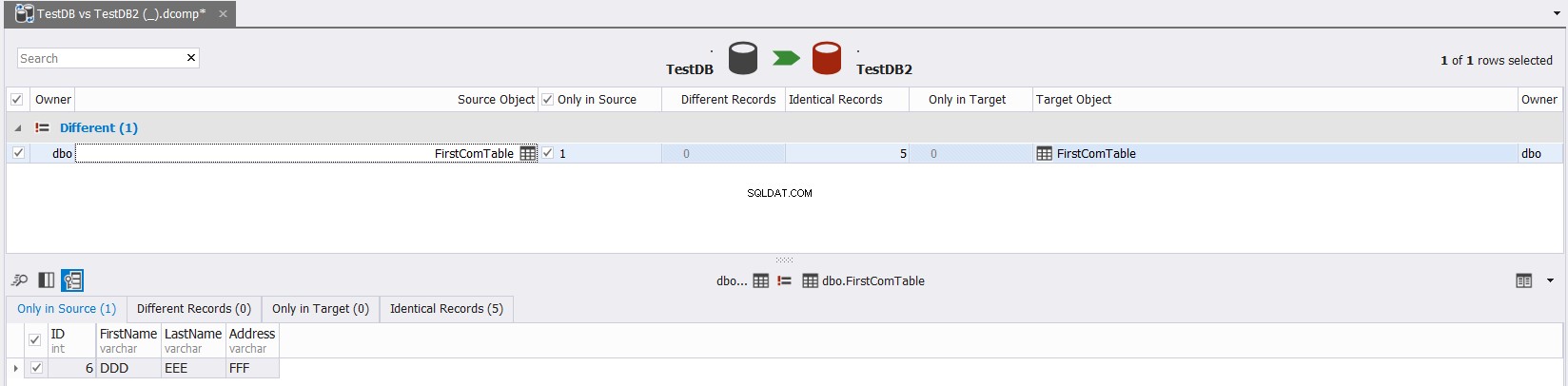
Vergelijk tabellenschema met sys.columns
Zoals aan het begin van dit artikel vermeld, moet u ervoor zorgen dat het schema van de bron- en doeltabellen identiek is om een tabel te repliceren of te archiveren. SQL Server biedt ons verschillende manieren om het schema van de tabellen in dezelfde database of verschillende databases te vergelijken. De eerste methode is het opvragen van de systeemcatalogusweergave sys.columns, die één rij retourneert voor elke kolom van een object dat een kolom heeft, met de eigenschappen van elke kolom.
Om het schema van tabellen in verschillende databases te vergelijken, moet u de sys.columns voorzien van de tabelnaam onder de huidige database, zonder dat u een tabel kunt aanbieden die in een andere database wordt gehost. Om dat te bereiken, zullen we de sys.columns twee keer bevragen, het resultaat van elke query opslaan in een tijdelijke tabel en ten slotte het resultaat van deze twee query's vergelijken met behulp van de EXCEPT T-SQL-opdracht, zoals hieronder duidelijk wordt weergegeven:
USE TESTDB SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DBSchema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable') GO USE TestDB2 GO SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DB2Schema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable '); GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Het resultaat zal ons laten zien dat de definitie van de adreskolom in deze twee tabellen anders is, zonder specifieke informatie over het exacte verschil, zoals hieronder weergegeven:

Vergelijk tabellenschema met INFORMATION_SCHEMA.COLUMNS
De systeemweergave INFORMATION_SCHEMA.COLUMNS kan ook worden gebruikt om het schema van verschillende tabellen te vergelijken door de tabelnaam op te geven. Nogmaals, om twee tabellen te vergelijken die in verschillende databases worden gehost, zullen we de INFORMATION_SCHEMA.COLUMNS twee keer opvragen, het resultaat van elke query in een tijdelijke tabel bewaren en ten slotte het resultaat van deze twee query's vergelijken met behulp van de EXCEPT T-SQL-opdracht, zoals weergegeven duidelijk hieronder:
USE TestDB SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DBSchema FROM [INFORMATION_SCHEMA].[COLUMNS] SC1 WHERE SC1.TABLE_NAME='FirstComTable' GO USE TestDB2 SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DB2Schema FROM [INFORMATION_SCHEMA].[COLUMNS] SC2 WHERE SC2.TABLE_NAME='FirstComTable' GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
En het resultaat zal op de een of andere manier vergelijkbaar zijn met de vorige, wat aantoont dat de definitie van de adreskolom in deze twee tabellen anders is, zonder specifieke informatie over het exacte verschil, zoals hieronder weergegeven:

Tabelschema vergelijken met dm_exec_describe_first_result_set
De tabellenschema's kunnen ook worden vergeleken door een query uit te voeren op de dynamische beheerfunctie dm_exec_describe_first_result_set, die een Transact-SQL-instructie als parameter neemt en de metadata beschrijft van de eerste resultatenset voor de instructie.
Om het schema van twee tabellen te vergelijken, moet u de DMF dm_exec_describe_first_result_set met zichzelf samenvoegen, door de SELECT-instructie van elke tabel als parameter op te geven, zoals in de T-SQL-query hieronder:
SELECT FT.name , ST.name , FT.system_type_name , ST.system_type_name , FT.max_length , ST.max_length , FT.precision , ST.precision , FT.scale , ST.scale , FT.is_nullable , ST.is_nullable , FT.is_identity_column , ST.is_identity_column FROM sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB.DBO.FirstComTable', NULL, 0) FT LEFT OUTER JOIN sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB2.DBO.FirstComTable', NULL, 0) ST ON FT.Name =ST.Name GO
Het resultaat zal deze keer duidelijker zijn, aangezien u met het oog het verschil tussen de twee tabellen kunt vergelijken, dat wil zeggen de grootte en het type van de adreskolom, zoals hieronder weergegeven:

Tabelschema vergelijken met SQL Server Data Tools
SQL Server Data Tools kunnen ook worden gebruikt om het schema van tabellen in verschillende databases te vergelijken. Kies in het menu Extra de optie Nieuwe schemavergelijking optie uit de lijst met SQL Server-opties, zoals hieronder weergegeven:
Nadat u de verbindingsparameters hebt opgegeven, klikt u op de knop Vergelijken:

Het vergelijkingsresultaat toont u specifiek het schemaverschil tussen de twee tabellen in de vorm van CREATE TABLE T-SQL-opdrachten, gearceerd zoals in de onderstaande snapshot:
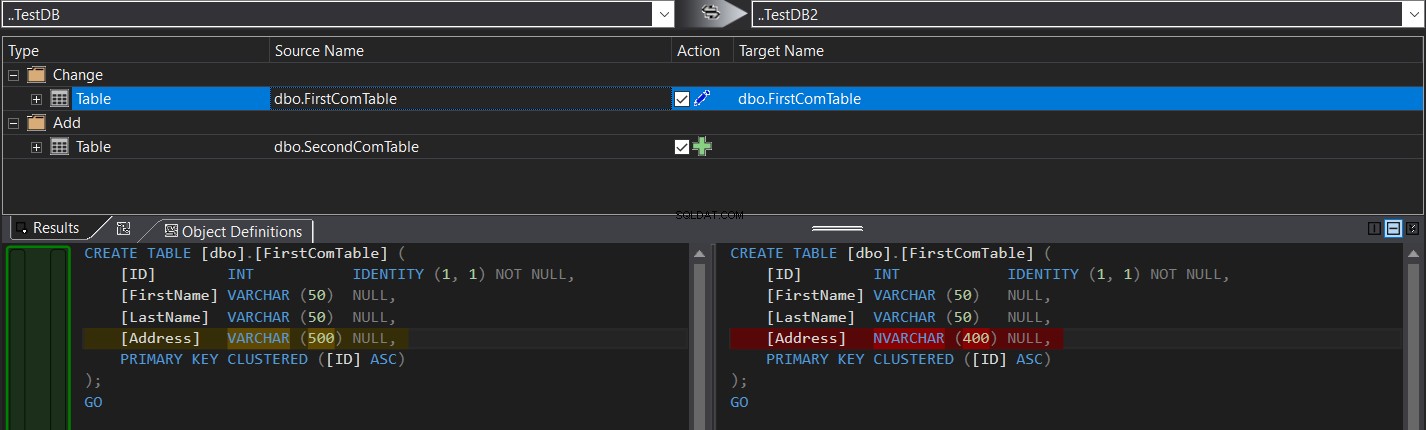
U kunt eenvoudig klikken  om het tabelschema te synchroniseren of klik op
om het tabelschema te synchroniseren of klik op  om de wijziging te scripten en later uit te voeren, zoals hieronder weergegeven:
om de wijziging te scripten en later uit te voeren, zoals hieronder weergegeven:
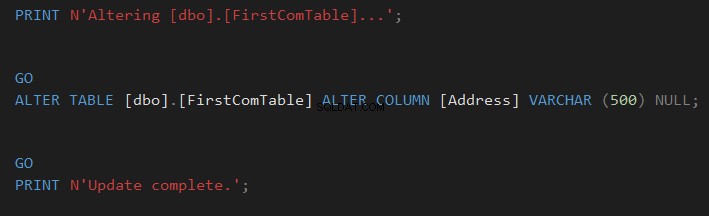
Tabelschema vergelijken met dbForge Studio for SQL Server Third Party Tool
De tool dbForge Studio voor SQL Server biedt ons de mogelijkheid om het schema van de verschillende databasetabellen te vergelijken. Kies in het menu Vergelijking deNieuwe schemavergelijking optie, zoals hieronder:
Nadat u de verbindingseigenschappen van zowel de bron- als de doeldatabase hebt gespecificeerd, kiest u de geschikte toewijzingsoptie uit de beschikbare keuzes en klikt u op Volgende :
Kies de schema's waarmee u het object wilt vergelijken en klik op Volgende :
Specificeer de tabel of tabellen die zullen deelnemen aan het schemavergelijkingsproces en klik op Vergelijken , als u het wijzigen van de standaardinstellingen in het venster Objectfilter wilt overslaan, zoals hieronder:
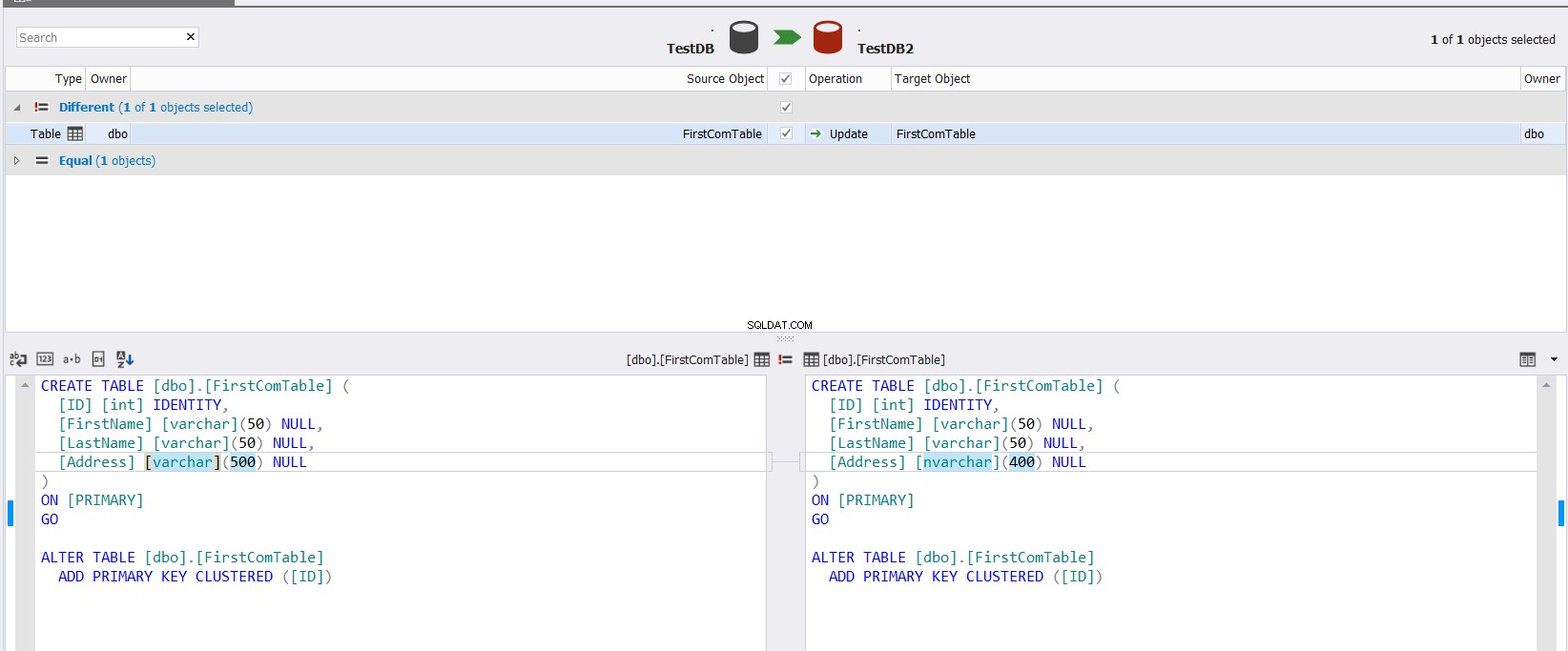
Het weergegeven vergelijkingsresultaat toont u het verschil tussen het schema van de twee tabellen, door precies het deel van het gegevenstype te markeren dat verschilt tussen de twee kolommen, met de mogelijkheid om te specificeren welke actie moet worden ondernomen om de twee tabellen te synchroniseren, zoals hieronder weergegeven :
Als u het schema van de twee tabellen wilt synchroniseren, klikt u op de knop en geeft u in de wizard Schemasynchronisatie op of het u lukt om de wijziging rechtstreeks op de doeltabel uit te voeren, of dat u deze in de toekomst wilt gebruiken, zoals hieronder:
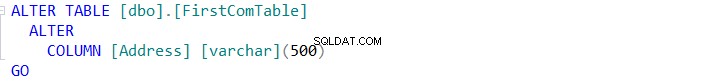
Nuttige links:
- Operators instellen - BEHALVE en INTERSECT (Transact-SQL)
- Operators instellen – UNION (Transact-SQL)
- SQL Server Data Tools (SSDT) downloaden
- Vergelijk en synchroniseer gegevens in een of meer tabellen met gegevens in een referentiedatabase
- sys.dm_exec_describe_first_result_set (Transact-SQL)
- sys.columns (Transact-SQL)
- Systeeminformatieschemaweergaven (Transact-SQL)
Handige hulpmiddelen:
dbForge Schema Compare voor SQL Server – betrouwbare tool die u tijd en moeite bespaart bij het vergelijken en synchroniseren van databases op SQL Server.
dbForge Data Compare voor SQL Server – krachtige SQL-vergelijkingstool die met big data kan werken.