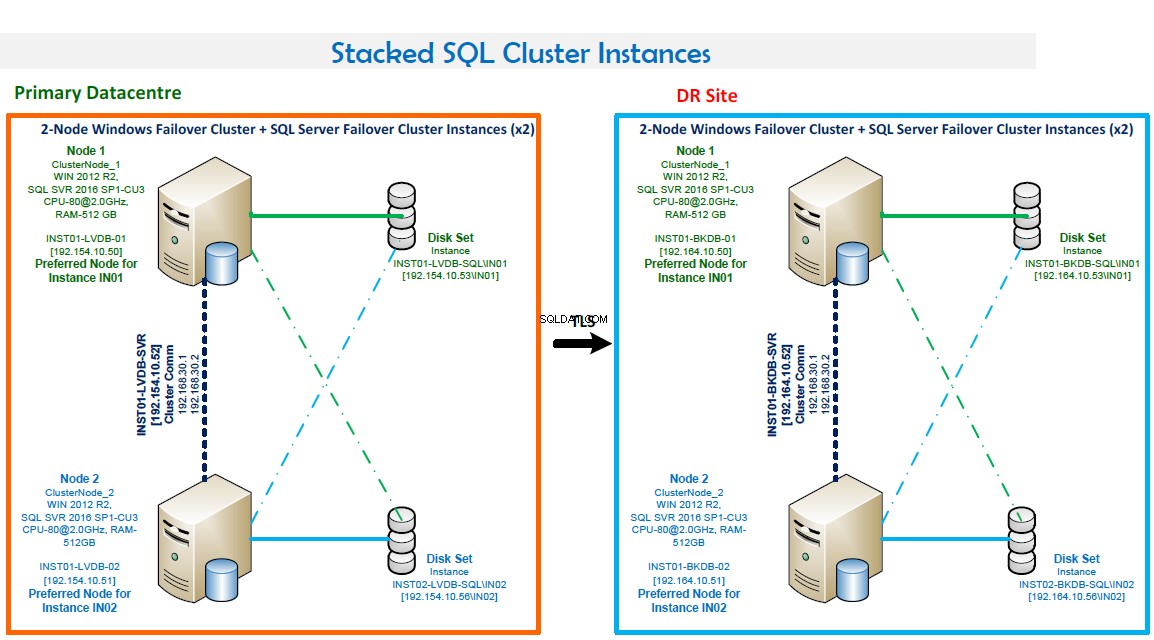
OPMERKINGEN:
- Windows Failover Clustering bestaande uit twee knooppunten.
- Twee SQL Server-failoverclusterinstanties. Deze configuratie optimaliseert de hardware. IN01 heeft de voorkeur op Node1 en IN02 heeft de voorkeur op Node2.
- Poortnummers:IN01 luistert op poort 1435 en IN02 luistert op poort 1436.
- Hoge beschikbaarheid. Beide knooppunten maken een back-up van elkaar. Failover is automatisch in geval van storing.
- Quorum-modus is knooppunt- en schijfmeerderheid.
- Back-up LAN aanwezig en routinematige back-up geconfigureerd met Veritas
Inleiding
Het is niet ongebruikelijk dat ontwikkelaars en projectmanagers voor elke nieuwe toepassing of service een nieuw exemplaar van SQL Server eisen. Hoewel technologieën zoals virtualisatie en cloud het opstarten van nieuwe instances een fluitje van een cent hebben gemaakt, maken sommige eeuwenoude technieken die zijn ingebouwd in SQL Server het mogelijk om korte doorlooptijden te bereiken wanneer er een nieuwe database moet worden geleverd voor een nieuwe service of applicatie. Deze stand van zaken kan worden gecreëerd door een DBA die een groot SQL Server-cluster kan ontwerpen en implementeren dat de meeste door de organisatie vereiste SQL Server-databases kan ondersteunen. Er zijn extra voordelen aan dit soort consolidatie, zoals lagere licentiekosten, beter beheer en beheergemak. In het artikel zullen we enkele overwegingen benadrukken die we hebben mogen ervaren bij het gebruik van clustering en stacking als middel om SQL Server-databases te consolideren.
Clustering
Windows Server Failover Clustering is een zeer bekende High Availability-oplossing die vele versies van Windows Server heeft overleefd en waarin Microsoft van plan is te blijven investeren en verbeteren. SQL Server Failover Cluster-instanties zijn afhankelijk van WSFC. Zowel de Standard- als de Enterprise-editie van SQL Server ondersteunen SQL Server-failoverclusterinstanties, maar de Standard-editie is beperkt tot slechts twee knooppunten. Het consolideren van databases op een enkele SQL Server FCI biedt de volgende voordelen:
- HA standaard — Alle databases die zijn geïmplementeerd op een geclusterde SQL Server-instantie zijn standaard zeer beschikbaar! Zodra een geclusterde instantie is gebouwd, worden nieuwe implementaties van tevoren geregeld in termen van HA.
- Eenvoudig beheer – Minder DBA's kunnen tijd besteden aan het configureren, bewaken en indien nodig oplossen van problemen met EEN geclusterde instantie die veel applicaties ondersteunt. Op de juiste manier wordt het documenteren van de instantie ook veel gemakkelijker gemaakt als je met één grote omgeving te maken hebt. Het configureren van een Enterprise Backup-oplossing om alle databases in uw omgeving te verwerken, wordt gemakkelijker gemaakt door het feit dat u deze configuratie slechts één hoeft te doen wanneer u geconsolideerde instanties gebruikt.
- Naleving – Belangrijke vereisten als patching en zelfs hardening kunnen eenmalig worden uitgevoerd met minimale downtime op een groot aantal databases in één enkele administratieve inspanning. In onze winkel hebben we Transactielogboekverzending tussen geclusterde instanties in twee datacenters gebruikt om ervoor te zorgen dat databases worden beschermd tegen het risico van rampen.
- Standaardisatie – Het afdwingen van standaarden als naamgevingsconventies, toegangsbeheer, Windows-authenticatie, auditing en op beleid gebaseerd beheer is veel gemakkelijker wanneer u met slechts één of twee omgevingen te maken hebt, afhankelijk van de grootte van uw winkel
Vermelding 1: Informatie over uw instantie extraheren
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Stapelen
SQL Server ondersteunt maximaal vijftig afzonderlijke instanties op één server en maximaal 25 failoverclusterinstanties op een Windows Server-failovercluster. Verschillende versies van SQL Server kunnen op dezelfde omgeving worden gestapeld om een robuuste omgeving te bieden die verschillende toepassingen ondersteunt. In een dergelijke configuratie kan het upgraden van databases de vorm aannemen van eenvoudigweg promoveren van de ene SQL Server-instantie naar de volgende versie in hetzelfde cluster tot de hardware ouder wordt. Een belangrijke overweging waarmee u rekening moet houden bij het stapelen van SQL Server is dat u geheugen moet toewijzen aan elk exemplaar op een zodanige manier dat de totale hoeveelheid toegewezen geheugen niet groter is dan het beschikbare geheugen op het besturingssysteem. Het andere punt in deze richting is ervoor te zorgen dat het SQL Server-serviceaccount voor elk exemplaar de vergrendelingspagina's in het geheugen moet hebben. Het toewijzen van vergrendelingspagina's in het geheugen zorgt ervoor dat wanneer SQL Server geheugen verwerft, het besturingssysteem niet probeert om dergelijk geheugen te herstellen wanneer andere processen op de server geheugen nodig hebben. Het opzetten van een gedefinieerd SQL Server-serviceaccount, het configureren van MAX_SERVER_MEMORY en het roosteren van Lock Pages in Memory-privileges zijn een essentieel trio bij het stapelen van SQL Server-instanties.
Microsoft rekent een paar duizend dollar per paar CPU-kernen. Door SQL Server-exemplaren te stapelen, kunt u gebruikmaken van dit licentiemodel door exemplaren dezelfde set CPU's te laten delen (het troef). We hebben al vermeld dat u verschillende versies van SQL Server kunt stapelen en zo kunt zorgen voor legacy-applicaties die nog steeds versies hebben die ouder zijn dan bijvoorbeeld SQL Server 2016. Wanneer u verschillende edities van SQL Server gebruikt, kunt u overwegen om Processor Affinity te gebruiken, zoals beschreven door Glen Berry in dit artikel. Processor Affinity kan ook worden gebruikt om te bepalen hoe CPU-bronnen onder instanties worden gedeeld, net zoals u het geheugen beheert. Stacking lost ook beveiligingsproblemen op voor toepassingen die bijvoorbeeld het SA-account moeten gebruiken of configuratieproblemen voor toepassingen die een speciale instantie vereisen, of dergelijke opties zijn een specifieke sortering. Bezorgdheid over de prestaties van de gedeelde TempDB is een andere reden waarom u misschien liever alle databases op één geclusterde instantie wilt stapelen dan op één hoop gooien.
Het is vermeldenswaard dat de waarde van clustering, zoals eerder benadrukt, nog verder reikt met stapelen. Als u bijvoorbeeld een SQL Server-instantie met meerdere FCI's patcht, kunnen alle FCI's in één keer worden gepatcht.
Aandachtspunten
Bij het gebruik van clustering zullen bepaalde conventies het beheer en beheer van de omgeving een beetje gemakkelijker maken en de activa beter belasten. We zullen er een paar kort bespreken:
- Huidige clienthulpprogramma's — Het kan zijn dat u ongebruikelijke fouten krijgt wanneer u een exemplaar van SQL Server 2016 probeert te beheren met SQL Server Management Studio 2012. De fouten vertellen u niet specifiek dat het probleem de versie van het clienthulpprogramma is. We hebben meestal een SQL Server Management Studio 17.3-instantie op de client die we willen gebruiken om verbinding te maken met onze instanties.
- Naamconventies — Een naamgevingsconventie maakt het u gemakkelijk om zeker te weten aan welke instantie u op elk moment werkt. Door aliassen te gebruiken, kunt u de last van het onthouden van de naam van een lange instantie verminderen voor eindgebruikers die toegang tot de database nodig hebben.
- Voorkeursknooppunt:het instellen van een voorkeursknooppunt voor elke SQL Server-rol in Failover Cluster Manager is een goed idee, een goede manier om ervoor te zorgen dat de verwerkingskracht van al uw clusterknooppunten wordt gebruikt. In onze winkel hebben we, na het instellen van voorkeursknooppunten, de rol geconfigureerd om terug te vallen tussen 0500 HRS en 0600 HRS voor het geval er een onbedoelde failover is.
- Verzending van transactielogboek – Bij het configureren van noodherstel voor FCI's is het logisch om alle UNC-paden te identificeren met behulp van virtuele namen, niet de namen of het IP-adres van de clusterknooppunten. Dit zorgt ervoor dat alles goed blijft functioneren als er een failover optreedt. Het is ook erg belangrijk om ervoor te zorgen dat de SQL Server Agent-accounts op beide sites volledige controle hebben over deze paden.
Vermelding 2: Bewaking configureren voor verzending van transactielogboeken via e-mail
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Schijfstations
Een neveneffect van het stapelen van een SQL Server-exemplaar en het maken van voorzieningen voor verschillende databases is de neiging om geen stationsletters meer te hebben. We hebben dit probleem omzeild door Volume Mount Points te configureren. Elke schijf die aan een clusterrol is toegewezen, is geconfigureerd als een koppelpunt met een stationsletter die alleen nodig is voor één of twee stations per instantie. Een belangrijk punt om op te merken bij het gebruik van volume-aankoppelpunten op een cluster, is dat wanneer u in de toekomst meer aankoppelpunten moet toevoegen om soortgelijke onderhoudstaken uit te voeren, het nodig zal zijn om zowel de primaire schijf die eigenaar is van de stationsletter als de punt in onderhoudsmodus op het cluster.
In ons geval hebben we de naam van elk Volume Mount Point gevonden op basis van de clusterrol waaraan het was toegewezen. Met zoveel schijven om mee om te gaan, zou je zeker een manier moeten bedenken voor zowel jou als de opslagbeheerder om een schijf te identificeren die uniek is, zodat het onderhouden van de schijven op opslagniveau bijvoorbeeld niet zo'n gedoe zou zijn.
Vermelding 3: Het gebruik van schijfruimte controleren bij gebruik van volume-aankoppelpunten
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Database-implementatie
In ons geval was onze strategie ervoor te zorgen dat nieuwe databases onze standaard volgden. Oudere databases werden met wat meer zorg behandeld, omdat we tegelijkertijd bezig waren met consolideren en upgraden. Database Migration Assistant hielp ons te vertellen welke databases absoluut niet compatibel zouden zijn met onze heilige SQL Server 2016-instantie en we lieten ze met rust (sommige met compatibiliteitsniveaus zijn zo laag als 100). Elke geïmplementeerde database moet zijn eigen volumes voor gegevens en logbestanden hebben, afhankelijk van de grootte. Het gebruik van afzonderlijke volumes voor elke database is een volgende stap in de richting van een zeer goed georganiseerde omgeving, wat belangrijk is gezien de potentiële complexiteit van deze geconsolideerde omgeving. De laatste verklaring houdt ook in dat wanneer u een toepassing toestaat om zijn eigen databases te maken, u als DBA de gegevensbestanden moet verplaatsen nadat de implementatie is voltooid, omdat de toepassing dezelfde bestandslocaties zal gebruiken die door de modeldatabase worden gebruikt.
Vermelding 4: Gebruikersdatabases verplaatsen
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Toegangsbeheer
U zult het ermee eens zijn dat we in onze geconsolideerde omgeving een zeer lange lijst met objecten op serverniveau kunnen hebben, zoals logins. Het gebruik van Windows-groepen zal deze lijst helpen verkorten en het toegangsbeheer op elke geclusterde instantie vereenvoudigen. Meestal hebt u groepen nodig die zijn gemaakt op Active Directory voor toepassingsbeheerders die toegang nodig hebben, toepassingsserviceaccounts, zakelijke gebruikers die rapporten moeten ophalen en natuurlijk databasebeheerders. Een belangrijk voordeel van het gebruik van Windows Groepen is dat toegang kan worden verleend of ingetrokken door eenvoudig het lidmaatschap van deze groepen rechtstreeks in Active Directory te beheren.
Het is inmiddels waarschijnlijk duidelijk dat dit voordeel op het gebied van Access Management alleen mogelijk is met Windows Authentication. SQL Server-aanmeldingen kunnen niet in groepen worden beheerd.
Vermelding 5: Inloggegevens van instanties, databasegebruikers en hun rollen
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Conclusie
We hebben op zeer hoog niveau de voordelen onderzocht die kunnen worden behaald door het clusteren en stapelen van SQL Server-instanties als middel om consolidatie, kostenoptimalisatie en beheergemak te bereiken. Als u merkt dat u grote hardware kunt kopen, kunt u deze optie verkennen en profiteren van de voordelen die we hierboven hebben beschreven.