Inleiding
Deze tutorial bevat informatie over SQL (DDL, DML) die ik tijdens mijn professionele leven heb verzameld. Dit is het minimum dat u moet weten als u met databases werkt. Als er behoefte is aan complexe SQL-constructies, dan surf ik meestal in de MSDN-bibliotheek, die gemakkelijk op internet te vinden is. Naar mijn mening is het heel moeilijk om alles in je hoofd te houden en dat is trouwens ook niet nodig. Ik raad je aan om alle hoofdconstructies te kennen die in de meeste relationele databases zoals Oracle, MySQL en Firebird worden gebruikt. Toch kunnen ze verschillen in gegevenstypes. Om bijvoorbeeld objecten te maken (tabellen, beperkingen, indexen, enz.), kunt u eenvoudigweg de geïntegreerde ontwikkelomgeving (IDE) gebruiken om met databases te werken en is het niet nodig om visuele hulpmiddelen te bestuderen voor een bepaald databasetype (MS SQL, Oracle , MySQL, Firebird, enz.). Dit is handig omdat u de hele tekst kunt zien en u niet door talloze tabbladen hoeft te bladeren om bijvoorbeeld een index of een beperking te maken. Als u constant met databases werkt, gaat het maken, wijzigen en vooral opnieuw opbouwen van een object met behulp van scripts veel sneller dan in een visuele modus. Bovendien is het naar mijn mening in de scriptmodus (met de nodige precisie) gemakkelijker om regels te specificeren en te controleren voor het benoemen van objecten. Daarnaast is het handig om scripts te gebruiken wanneer u databasewijzigingen moet overbrengen van een testdatabase naar een productiedatabase.
SQL is opgedeeld in verschillende delen. In mijn artikel zal ik de belangrijkste bespreken:
DDL – Taal voor gegevensdefinitie
DML – Taal voor gegevensmanipulatie, die de volgende constructies omvat:
- SELECT – gegevensselectie
- INSERT – nieuwe gegevensinvoer
- UPDATE – gegevensupdate
- VERWIJDEREN – gegevens verwijderen
- MERGE – gegevens samenvoegen
Ik zal alle constructies uitleggen in studiecases. Daarnaast denk ik dat een programmeertaal, met name SQL, in de praktijk bestudeerd moet worden voor een beter begrip.
Dit is een stapsgewijze zelfstudie, waarbij u tijdens het lezen voorbeelden moet uitvoeren. Als u de opdracht echter in details wilt weten, surf dan op internet, bijvoorbeeld MSDN.
Bij het maken van deze tutorial heb ik de MS SQL Server-database, versie 2014 en MS SQL Server Management Studio (SSMS) gebruikt om scripts uit te voeren.
Kort over MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) is het hulpprogramma van Microsoft SQL Server voor het configureren, beheren en beheren van databasecomponenten. Het bevat een scripteditor en een grafisch programma dat werkt met serverobjecten en instellingen. Het belangrijkste hulpmiddel van SQL Server Management Studio is Object Explorer, waarmee een gebruiker serverobjecten kan bekijken, ophalen en beheren. Deze tekst is gedeeltelijk overgenomen van Wikipedia.
Gebruik de knop Nieuwe zoekopdracht om een nieuwe scripteditor te maken:
Om over te schakelen van de huidige database, kunt u het vervolgkeuzemenu gebruiken:
Om een bepaalde opdracht of reeks opdrachten uit te voeren, markeert u deze en drukt u op de knop Uitvoeren of F5. Als er maar één commando in de editor is of als je alle commando's moet uitvoeren, markeer dan niets.
Nadat u scripts hebt uitgevoerd die objecten maken (tabellen, kolommen, indexen), selecteert u het bijbehorende object (bijvoorbeeld tabellen of kolommen) en klikt u vervolgens op Vernieuwen in het snelmenu om de wijzigingen te zien.
Dit is eigenlijk alles wat u moet weten om de hierin gegeven voorbeelden uit te voeren.
Theorie
Een relationele database is een verzameling tabellen die aan elkaar zijn gekoppeld. Over het algemeen is een database een bestand waarin gestructureerde gegevens worden opgeslagen.
Database Management System (DBMS) is een set tools om met bepaalde databasetypes te werken (MS SQL, Oracle, MySQL, Firebird, enz.).
Opmerking: Zoals in ons dagelijks leven, zeggen we "Oracle DB" of gewoon "Oracle" wat eigenlijk "Oracle DBMS" betekent, en in deze tutorial zal ik de term "database" gebruiken.
Een tabel is een verzameling kolommen. Heel vaak hoor je de volgende definities van deze termen:velden, rijen en records, die hetzelfde betekenen.
Een tabel is het hoofdobject van de relationele database. Alle gegevens worden rij voor rij opgeslagen in tabelkolommen.
Voor elke tabel en voor de kolommen moet u een naam opgeven, volgens welke u een vereist item kunt vinden.
De naam van het object, de tabel, de kolom en de index mogen minimaal 128 symbolen lang zijn.
Opmerking: In Oracle-databases kan een objectnaam de minimale lengte van 30 symbolen hebben. In een bepaalde database is het dus nodig om aangepaste regels voor objectnamen te maken.
SQL is een taal waarmee query's in databases via DBMS kunnen worden uitgevoerd. In een bepaalde DBMS kan een SQL-taal zijn eigen dialect hebben.
DDL en DML – de SQL-subtaal:
- De DDL-taal dient voor het maken en wijzigen van een databasestructuur (verwijdering van tabellen en links);
- De DML-taal maakt het mogelijk om tabelgegevens, de rijen, te manipuleren. Het dient ook voor het selecteren van gegevens uit tabellen, het toevoegen van nieuwe gegevens en het bijwerken en verwijderen van huidige gegevens.
Het is mogelijk om twee soorten opmerkingen in SQL te gebruiken (enkelregelig en gescheiden):
-- single-line comment
en
/* delimited comment */
Dat is alles wat betreft de theorie.
DDL – Taal voor gegevensdefinitie
Laten we een voorbeeldtabel bekijken met gegevens over werknemers weergegeven op een manier die bekend is bij iemand die geen programmeur is.
| Werknemers-ID | Volledige naam | Verjaardag | Positie | Afdeling | |
| 1000 | Jan | 19.02.1955 | voorbeeld@sqldat.com | CEO | Beheer |
| 1001 | Daniël | 03.12.1983 | voorbeeld@sqldat.com | programmeur | IT |
| 1002 | Mike | 07.06.1976 | voorbeeld@sqldat.com | Accountant | Accountafdeling |
| 1003 | Jordanië | 17.04.1982 | voorbeeld@sqldat.com | Senior programmeur | IT |
In dit geval hebben de kolommen de volgende titels:Werknemer-ID, Volledige naam, Geboortedatum, E-mail, Functie en Afdeling.
We kunnen elke kolom van deze tabel beschrijven aan de hand van het gegevenstype:
- Werknemers-ID – geheel getal
- Volledige naam – tekenreeks
- Verjaardag – datum
- E-mail – tekenreeks
- Positie – tekenreeks
- Afdeling – tekenreeks
Een kolomtype is een eigenschap die specificeert welk gegevenstype elke kolom kan opslaan.
Om te beginnen moet u de belangrijkste gegevenstypen onthouden die in MS SQL worden gebruikt:
| Definitie | Aanduiding in MS SQL | Beschrijving |
| Tekenreeks met variabele lengte | varchar(N) en nvarchar(N) | Met het N-nummer kunnen we de maximaal mogelijke tekenreekslengte voor een bepaalde kolom specificeren. Als we bijvoorbeeld willen zeggen dat de waarde van de kolom Volledige naam maximaal 30 symbolen kan bevatten, moet het type nvarchar(30) worden opgegeven.
Het verschil tussen varchar en nvarchar is dat varchar het opslaan van strings in het ASCII-formaat toestaat, terwijl nvarchar strings opslaat in het Unicode-formaat, waarbij elk symbool 2 bytes in beslag neemt. |
| Tekenreeks met vaste lengte | char(N) en nchar(N) | Dit type verschilt van de tekenreeks met variabele lengte in het volgende:als de tekenreekslengte kleiner is dan N symbolen, worden altijd spaties toegevoegd aan de N-lengte aan de rechterkant. In een database zijn dus precies N symbolen nodig, waarbij één symbool 1 byte nodig heeft voor char en 2 bytes voor nchar. In mijn praktijk wordt dit type niet veel gebruikt. Maar als iemand het gebruikt, dan heeft dit type meestal het formaat char(1), d.w.z. wanneer een veld wordt gedefinieerd door 1 symbool. |
| Geheel getal | int | Met dit type kunnen we alleen gehele getallen (zowel positief als negatief) in een kolom gebruiken. Opmerking:een nummerbereik voor dit type is als volgt:van 2 147 483 648 tot 2 147 483 647. Gewoonlijk is dit het belangrijkste type dat wordt gebruikt om identifiers te gebruiken. |
| Drijvende-kommagetal | zwevend | Getallen met een decimale punt. |
| Datum | datum | Het wordt gebruikt om alleen een datum (datum, maand en jaar) in een kolom op te slaan. Bijvoorbeeld 15-02-2014. Dit type kan worden gebruikt voor de volgende kolommen:ontvangstdatum, geboortedatum, etc., wanneer u alleen een datum hoeft op te geven of wanneer tijd niet belangrijk voor ons is en we deze kunnen laten vallen. |
| Tijd | tijd | Je kunt dit type gebruiken als het nodig is om tijd op te slaan:uren, minuten, seconden en milliseconden. U heeft bijvoorbeeld 17:38:31.3231603 of u moet de vertrektijd van de vlucht toevoegen. |
| Datum en tijd | datumtijd | Met dit type kunnen gebruikers zowel datum als tijd opslaan. U heeft bijvoorbeeld het evenement op 15-02-2014 17:38:31.323. |
| Indicator | bit | Je kunt dit type gebruiken om waarden op te slaan zoals 'Ja'/'Nee', waarbij 'Ja' 1 is en 'Nee' 0 is. |
Bovendien is het niet nodig om de veldwaarde op te geven, tenzij dit verboden is. In dit geval kunt u NULL gebruiken.
Om voorbeelden uit te voeren, zullen we een testdatabase maken met de naam 'Test'.
Voer de volgende opdracht uit om een eenvoudige database te maken zonder extra eigenschappen:
CREATE DATABASE Test
Voer deze opdracht uit om een database te verwijderen:
DROP DATABASE Test
Gebruik het commando om naar onze database te gaan:
USE Test
U kunt ook de Testdatabase selecteren in het vervolgkeuzemenu in het SSMS-menugebied.
Nu kunnen we een tabel in onze database maken met behulp van beschrijvingen, spaties en Cyrillische symbolen:
CREATE TABLE [Employees]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar(30) )
In dit geval moeten we namen tussen vierkante haken plaatsen […].
Toch is het beter om alle objectnamen in het Latijn te specificeren en geen spaties in de namen te gebruiken. In dit geval begint elk woord met een hoofdletter. Voor het veld 'EmployeeID' kunnen we bijvoorbeeld de naam PersonnelNumber specificeren. U kunt ook cijfers in de naam gebruiken, bijvoorbeeld Telefoonnummer1.
Opmerking: In sommige DBMS'en is het handiger om het volgende naamformaat «PHONE_NUMBER» te gebruiken. U kunt dit formaat bijvoorbeeld zien in ORACLE-databases. Bovendien mag de veldnaam niet samenvallen met de trefwoorden die in DBMS worden gebruikt.
Om deze reden kunt u de syntaxis van vierkante haken vergeten en de tabel Werknemers verwijderen:
DROP TABLE [Employees]
U kunt bijvoorbeeld de tabel met werknemers een naam geven als "Werknemers" en de volgende namen voor de velden instellen:
- ID
- Naam
- Verjaardag
- Positie
- Afdeling
Heel vaak gebruiken we 'ID' voor het identificatieveld.
Laten we nu een tabel maken:
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Om de verplichte kolommen in te stellen, kunt u de optie NOT NULL gebruiken.
Voor de huidige tabel kunt u de velden opnieuw definiëren met de volgende opdrachten:
-- ID field update ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- Name field update ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
Opmerking: Het algemene concept van de SQL-taal voor de meeste DBMS's is hetzelfde (uit eigen ervaring). Het verschil tussen DDL's in verschillende DBMS'en zit voornamelijk in de gegevenstypen (ze kunnen niet alleen verschillen door hun naam, maar ook door hun specifieke implementatie). Bovendien zijn de specifieke SQL-implementaties (commando's) hetzelfde, maar kunnen er kleine verschillen zijn in het dialect. Als u de basisprincipes van SQL kent, kunt u gemakkelijk van het ene DBMS naar het andere overschakelen. In dit geval hoeft u alleen de details van het implementeren van commando's in een nieuw DBMS te begrijpen.
Vergelijk dezelfde commando's in het ORACLE DBMS:
-- create table CREATE TABLE Employees( ID int, -- In ORACLE the int type is a value for number(38) Name nvarchar2(30), -- in ORACLE nvarchar2 is identical to nvarchar in MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- ID and Name field update (here we use MODIFY(…) instead of ALTER COLUMN ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (in this case the construction is the same as in the MS SQL) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE verschilt in het implementeren van het varchar2-type. Het formaat is afhankelijk van de DB-instellingen en u kunt een tekst opslaan, bijvoorbeeld in UTF-8. Bovendien kunt u de veldlengte zowel in bytes als in symbolen specificeren. Om dit te doen, moet u de BYTE- en CHAR-waarden gebruiken, gevolgd door het lengteveld. Bijvoorbeeld:
NAME varchar2(30 BYTE) – field capacity equals 30 bytes NAME varchar2(30 CHAR) -- field capacity equals 30 symbols
De waarde (BYTE of CHAR) die standaard moet worden gebruikt wanneer u alleen varchar2(30) in ORACLE aangeeft, hangt af van de DB-instellingen. Vaak kun je gemakkelijk in de war raken. Daarom raad ik aan om CHAR expliciet op te geven wanneer je het varchar2-type gebruikt (bijvoorbeeld met UTF-8) in ORACLE (omdat het handiger is om de tekenreekslengte in symbolen te lezen).
Als er in dit geval echter gegevens in de tabel staan, moeten de velden ID en Naam in alle tabelrijen worden ingevuld om opdrachten met succes uit te voeren.
Ik zal het in een bepaald voorbeeld laten zien.
Laten we gegevens invoegen in de velden ID, Positie en Afdeling met behulp van het volgende script:
INSERT Employees(ID,Position,Department) VALUES (1000,’CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Senior Programmer',N'IT')
In dit geval retourneert de opdracht INSERT ook een fout. Dit gebeurt omdat we de waarde voor het verplichte veld Naam niet hebben opgegeven.
Als er enkele gegevens in de oorspronkelijke tabel waren, zou de opdracht "ALTER TABLE Employees ALTER COLUMN ID int NOT NULL" werken, terwijl de opdracht "ALTER TABLE Employees ALTER COLUMN Name int NOT NULL" een fout zou retourneren die het veld Naam heeft NULL-waarden.
Laten we waarden toevoegen in het veld Naam:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
Bovendien kunt u NOT NULL gebruiken bij het maken van een nieuwe tabel met de instructie CREATE TABLE.
Laten we eerst een tabel verwijderen:
DROP TABLE Employees
Nu gaan we een tabel maken met de verplichte velden ID en Naam:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
U kunt ook NULL opgeven na een kolomnaam, wat inhoudt dat NULL-waarden zijn toegestaan. Dit is niet verplicht, omdat deze optie standaard is ingesteld.
Als u de huidige kolom niet-verplicht wilt maken, gebruikt u de volgende syntaxis:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
U kunt ook dit commando gebruiken:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Bovendien kunnen we met deze opdracht het veldtype wijzigen in een ander compatibel type of de lengte ervan wijzigen. Laten we bijvoorbeeld het veld Naam uitbreiden tot 50 symbolen:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Primaire sleutel
Wanneer u een tabel maakt, moet u een kolom of een reeks kolommen opgeven die uniek zijn voor elke rij. Met deze unieke waarde kunt u een record identificeren. Deze waarde wordt de primaire sleutel genoemd. De ID-kolom (die «het persoonlijke nummer van een werknemer» bevat – in ons geval is dit de unieke waarde voor elke werknemer en kan niet worden gedupliceerd) kan de primaire sleutel zijn voor onze tabel Werknemers.
U kunt de volgende opdracht gebruiken om een primaire sleutel voor de tabel te maken:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
'PK_Employees' is een beperkingsnaam die de primaire sleutel definieert. Gewoonlijk bestaat de naam van een primaire sleutel uit het voorvoegsel 'PK_' en de tabelnaam.
Als de primaire sleutel meerdere velden bevat, moet u deze velden tussen haakjes vermelden, gescheiden door een komma:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Houd er rekening mee dat in MS SQL alle velden van de primaire sleutel NIET NULL mogen zijn.
Bovendien kunt u een primaire sleutel definiëren bij het maken van een tabel. Laten we de tabel verwijderen:
DROP TABLE Employees
Maak vervolgens een tabel met de volgende syntaxis:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – describe PK after all the fileds as a constraint )
Voeg gegevens toe aan de tabel:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior programmer',N'IT',N'Jordan')
U hoeft de naam van de beperking eigenlijk niet op te geven. In dit geval wordt een systeemnaam toegewezen. Bijvoorbeeld:«PK__Medewerker__3214EC278DA42077»:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
of
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Persoonlijk zou ik aanraden om de naam van de beperking expliciet op te geven voor permanente tabellen, omdat het in de toekomst gemakkelijker is om met een expliciet gedefinieerde en duidelijke waarde te werken of deze te verwijderen. Bijvoorbeeld:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Toch is het handiger om deze korte syntaxis toe te passen, zonder beperkingsnamen bij het maken van tijdelijke databasetabellen (de naam van een tijdelijke tabel begint met # of ##.
Samenvatting:
We hebben de volgende commando's al geanalyseerd:
- TABEL MAKEN table_name (lijst van velden en hun typen, evenals beperkingen) – dient voor het maken van een nieuwe tabel in de huidige database;
- LAAG TAFEL table_name – dient voor het verwijderen van een tabel uit de huidige database;
- WIJZIG TABEL table_name ALTER COLUMN column_name … – dient voor het bijwerken van het kolomtype of voor het wijzigen van de instellingen (bijvoorbeeld wanneer u NULL of NOT NULL moet instellen);
- WIJZIG TABEL table_name BEPERKING TOEVOEGEN constraint_name PRIMAIRE SLEUTEL (field1, field2,…) – wordt gebruikt om een primaire sleutel aan de huidige tabel toe te voegen;
- WIJZIG TABEL table_name DROP CONSTRAINT constraint_name – gebruikt om een beperking uit de tabel te verwijderen.
Tijdelijke tafels
Samenvatting van MSDN. Er zijn twee soorten tijdelijke tabellen in MS SQL Server:lokaal (#) en globaal (##). Lokale tijdelijke tabellen zijn alleen zichtbaar voor hun makers voordat het exemplaar van SQL Server wordt losgekoppeld. Ze worden automatisch verwijderd nadat de gebruiker is losgekoppeld van het exemplaar van SQL Server. Globale tijdelijke tabellen zijn zichtbaar voor alle gebruikers tijdens eventuele verbindingssessies na het maken van deze tabellen. Deze tabellen worden verwijderd zodra gebruikers de verbinding met het exemplaar van SQL Server hebben verbroken.
Tijdelijke tabellen worden gemaakt in de tempdb-systeemdatabase, wat betekent dat we de hoofddatabase niet overspoelen. Bovendien kunt u ze verwijderen met de opdracht DROP TABLE. Heel vaak worden lokale (#) tijdelijke tabellen gebruikt.
Om een tijdelijke tabel aan te maken, kunt u de opdracht CREATE TABLE gebruiken:
CREATE TABLE #Temp( ID int, Name nvarchar(30) )
U kunt de tijdelijke tabel verwijderen met het DROP TABLE-commando:
DROP TABLE #Temp
Bovendien kunt u een tijdelijke tabel maken en deze invullen met de gegevens met behulp van de syntaxis SELECT … INTO:
SELECT ID,Name INTO #Temp FROM Employees
Opmerking: In verschillende DBMS'en kan de implementatie van tijdelijke databases variëren. In de ORACLE- en Firebird-DBMS'en moet de structuur van tijdelijke tabellen bijvoorbeeld vooraf worden gedefinieerd door de opdracht CREATE GLOBAL TEMPORARY TABLE. Ook moet u de manier van gegevensopslag specificeren. Hierna ziet een gebruiker het tussen gewone tabellen en werkt ermee als met een conventionele tafel.
Databasenormalisatie:opsplitsen in subtabellen (referentietabellen) en tabelrelaties definiëren
Onze huidige werknemerstabel heeft een nadeel:een gebruiker kan elke tekst typen in de velden Positie en Afdeling, wat fouten kan opleveren, aangezien hij voor de ene werknemer "IT" als afdeling kan specificeren, terwijl hij voor een andere werknemer "IT" kan specificeren afdeling". Hierdoor zal het onduidelijk zijn wat de gebruiker bedoelde, of deze medewerkers voor dezelfde afdeling werken of dat er sprake is van een spelfout en dat er 2 verschillende afdelingen zijn. Bovendien kunnen we in dit geval de gegevens voor een rapport niet correct groeperen, waarbij we het aantal medewerkers voor elke afdeling moeten weergeven.
Een ander nadeel is het opslagvolume en de duplicatie ervan, d.w.z. u moet voor elke medewerker een volledige naam van de afdeling opgeven, wat ruimte in databases vereist om elk symbool van de afdelingsnaam op te slaan.
Het derde nadeel is de complexiteit van het bijwerken van veldgegevens wanneer u een naam van een functie moet wijzigen - van programmeur tot junior programmeur. In dit geval moet u nieuwe gegevens toevoegen in elke tabelrij waar de Positie "Programmer" is.
Om dergelijke situaties te voorkomen, wordt aanbevolen om databasenormalisatie te gebruiken - opsplitsen in subtabellen - referentietabellen.
Laten we 2 referentietabellen "Posities" en "Afdelingen" maken:
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
Merk op dat we hier een nieuwe eigenschap IDENTITY hebben gebruikt. Dit betekent dat gegevens in de ID-kolom automatisch worden weergegeven, beginnend met 1. Dus bij het toevoegen van nieuwe records worden de waarden 1, 2, 3, etc. opeenvolgend toegewezen. Gewoonlijk worden deze velden autoincrement-velden genoemd. Er kan slechts één veld met de eigenschap IDENTITY als primaire sleutel in een tabel worden gedefinieerd. Gewoonlijk, maar niet altijd, is zo'n veld de primaire sleutel van de tabel.
Opmerking: In verschillende DBMS'en kan de implementatie van velden met een incrementer verschillen. In MySQL wordt zo'n veld bijvoorbeeld gedefinieerd door de eigenschap AUTO_INCREMENT. In ORACLE en Firebird zou je deze functionaliteit kunnen emuleren door sequenties (SEQUENCE). Maar voor zover ik weet, is de eigenschap GENERATED AS IDENTITY toegevoegd in ORACLE.
Laten we deze tabellen automatisch invullen op basis van de huidige gegevens in de velden Positie en Afdeling van de tabel Medewerkers:
-- fill in the Name field of the Positions table with unique values from the Position field of the Employees table INSERT Positions(Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL – drop records where a position is not specified
U moet dezelfde stappen uitvoeren voor de tabel Afdelingen:
INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL
Als we nu de tabellen Posities en Afdelingen openen, zien we een genummerde lijst met waarden in het ID-veld:
SELECT * FROM Positions
| ID | Naam |
| 1 | Accountant |
| 2 | CEO |
| 3 | Programmeur |
| 4 | Senior programmeur |
SELECT * FROM Departments
| ID | Naam |
| 1 | Beheer |
| 2 | Accountafdeling |
| 3 | IT |
Deze tabellen zullen de referentietabellen zijn om posities en afdelingen te definiëren. Nu zullen we verwijzen naar identifiers van posities en afdelingen. Laten we eerst nieuwe velden maken in de tabel Werknemers om de ID's op te slaan:
-- add a field for the ID position ALTER TABLE Employees ADD PositionID int -- add a field for the ID department ALTER TABLE Employees ADD DepartmentID int
Het type referentievelden moet hetzelfde zijn als in de referentietabellen, in dit geval is het int.
Bovendien kunt u met één commando meerdere velden toevoegen door de velden gescheiden door komma's op te sommen:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Nu zullen we referentiebeperkingen (BUITENLANDSE SLEUTEL) aan deze velden toevoegen, zodat een gebruiker geen waarden kan toevoegen die niet de ID-waarden van de referentietabellen zijn.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
Dezelfde stappen moeten worden gedaan voor het tweede veld:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Nu kunnen gebruikers in deze velden alleen de ID-waarden uit de bijbehorende referentietabel invoegen. Om een nieuwe afdeling of functie te gebruiken, moet een gebruiker dus een nieuw record toevoegen aan de bijbehorende referentietabel. Aangezien functies en afdelingen in één kopie in referentietabellen worden opgeslagen, hoeft u deze alleen in de referentietabel te wijzigen om hun naam te wijzigen.
De naam van een referentiebeperking is meestal samengesteld. Het bestaat uit het voorvoegsel «FK» gevolgd door een tabelnaam en een veldnaam die verwijst naar de referentietabel-ID.
De identifier (ID) is meestal een interne waarde die alleen voor links wordt gebruikt. Het maakt niet uit welke waarde het heeft. Probeer dus geen hiaten in de reeks waarden op te lossen die verschijnen wanneer u met de tabel werkt, bijvoorbeeld wanneer u records verwijdert uit de referentietabel.
In sommige gevallen is het mogelijk om een referentie op te bouwen uit meerdere velden:
ALTER TABLE table ADD CONSTRAINT constraint_name FOREIGN KEY(field1,field2,…) REFERENCES reference table(field1,field2,…)
In dit geval wordt een primaire sleutel vertegenwoordigd door een set van verschillende velden (field1, field2, …) in tabel “reference_table”.
Laten we nu de velden PositionID en DepartmentID bijwerken met de ID-waarden uit de referentietabellen.
Om dit te doen, gebruiken we het UPDATE-commando:
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
Voer de volgende query uit:
SELECT * FROM Employees
| ID | Naam | Verjaardag | Positie | Afdeling | Positie-ID | Afdelings-ID | |
| 1000 | Jan | NULL | NULL | CEO | Beheer | 2 | 1 |
| 1001 | Daniël | NULL | NULL | Programmeur | IT | 3 | 3 |
| 1002 | Mike | NULL | NULL | Accountant | Accountafdeling | 1 | 2 |
| 1003 | Jordanië | NULL | NULL | Senior programmeur | IT | 4 | 3 |
Zoals u kunt zien, komen de velden PositionID en DepartmentID overeen met posities en afdelingen. U kunt dus de velden Positie en Afdeling in de tabel Medewerkers verwijderen door de volgende opdracht uit te voeren:
ALTER TABLE Employees DROP COLUMN Position,Department
Voer nu deze instructie uit:
SELECT * FROM Employees
| ID | Naam | Verjaardag | Positie-ID | Afdelings-ID | |
| 1000 | Jan | NULL | NULL | 2 | 1 |
| 1001 | Daniël | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordanië | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
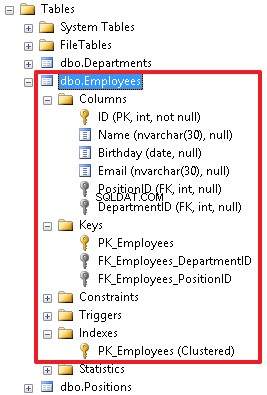
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
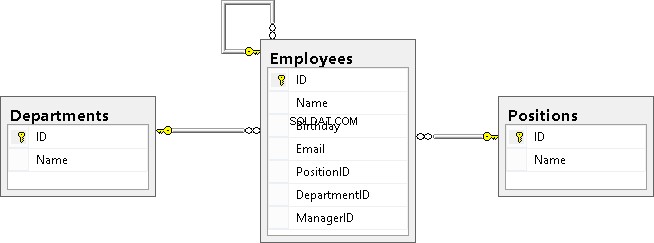
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Samenvatting:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
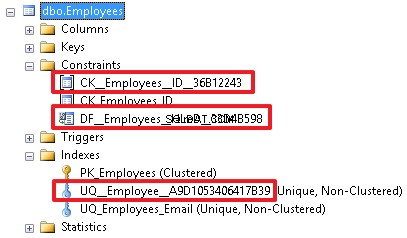
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Samenvatting
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.