In mijn vorige artikel heb ik het stapsgewijze proces uitgelegd voor het installeren van een knooppunt in een bestaande SQL Server Failover Cluster-instantie. Daarnaast heb ik ook handmatige failover en automatische failover gedemonstreerd.
In dit artikel ga ik het proces demonstreren van het toevoegen van een schijf in een failovercluster en vervolgens de bestaande database naar een nieuwe schijf verplaatsen.
Om een schijf aan het cluster toe te voegen, moeten we eerst de volgende stappen uitvoeren:
1. Maak een nieuwe iSCSI virtuele schijf.
2. Maak verbinding met de nieuwe iSCSI virtuele schijf met behulp van de iSCSI-initiator van failoverclusterknooppunten.
3. Voeg een nieuwe schijf toe aan een bestaande failover-clusteropslag.
4. Verplaats het voorbeelddatabasebestand naar de nieuwe schijf.
Laat me u eerst een korte introductie geven van de demo-setup. Ik heb vier virtuele machines op mijn computer gemaakt. Hier zijn de details:
| Virtuele machine | Hostnaam | IP-adres | Doel |
| Domeincontroller | DC.Local | 192.168.1.110 | Deze virtuele machine wordt gebruikt als domeincontroller. |
| SAN | SAN.DC.Local | 192.168.1.111 | Deze virtuele machine wordt gebruikt als een virtuele SAN. Ik heb twee virtuele iSCSI-schijven gemaakt die ik zal verbinden vanaf failover-clusterknooppunten met behulp van de iSCSI-initiator. |
| Primair SQL-knooppunt | SQL01.DC.Local | 192.168.1.112 | Op deze virtuele machine zullen we de geclusterde failover-instantie installeren. |
| Secundair SQL-knooppunt | SQL02.DC.Local | 192.168.1.113 | Op deze virtuele machine zullen we het secundaire knooppunt van de failover-clusterinstantie installeren. |
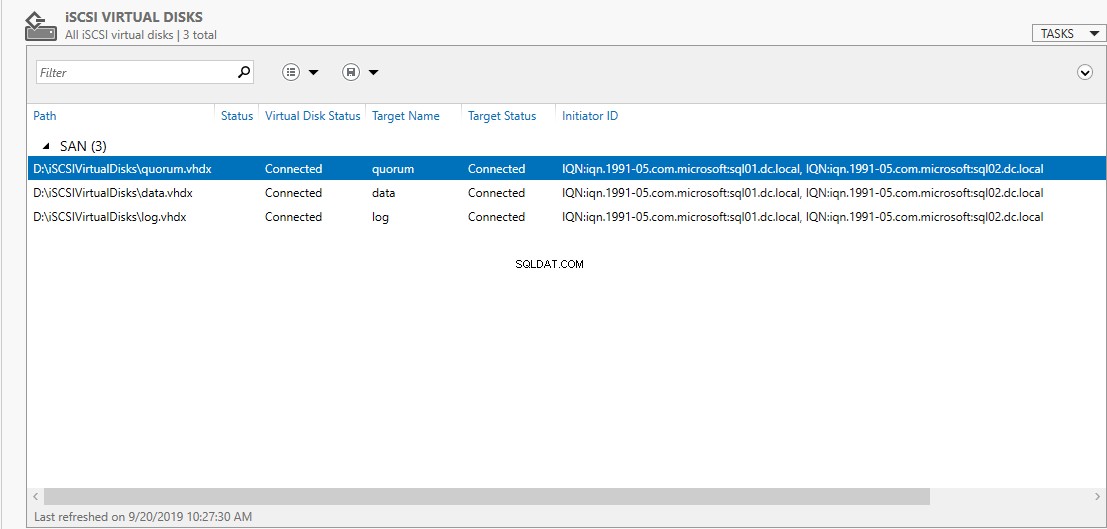
Op SAN.DC.Local , heb ik drie iSCSI-schijven gemaakt. De details zijn als volgt:
| iSCSI-schijfnaam | Doel |
| Sql-data | Op deze schijf slaan we databasebestanden op van gebruikersdatabases en TempDB-bestanden. |
| Sql-log | Op deze schijf slaan we de logbestanden van gebruikersdatabases op. |
| quorum | Deze schijf wordt gebruikt als quorum. |
Hieronder volgt de schermafbeelding van onze configuratie:
Maak een iSCSI-schijf
Zoals ik hierboven al zei, moeten we eerst een virtuele iSCSI-schijf maken. In dit geval ga ik PowerShell gebruiken om virtuele iSCSI-schijven met een vaste grootte te maken en configureren. De grootte van de virtuele schijf is 8 GB. Voer de volgende opdracht uit om een nieuwe iSCSI-drive te maken.
New-IscsiVirtualDisk –Path F:\new-sql-data\new-sql-data.vhdx –SizeBytes (8GB) –UseFixed
Om te controleren of de iSCSI-schijf met succes is gemaakt, opent u de S erver M anager en klik op iSCSI virtuele schijven op het linkerdeelvenster. Zie de volgende afbeelding:
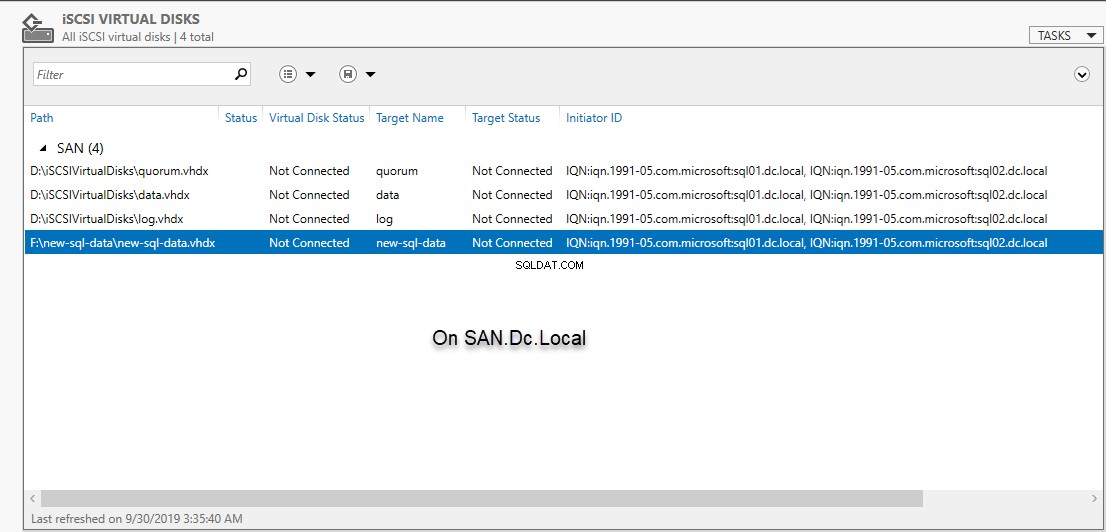
Nu moeten we een iSCSI-doel maken. Externe servers kunnen verbinding maken met een virtuele schijf door de doelnaam te gebruiken. Hier zal ik een doel maken met de naam new-sql-data . Een iSCSI-doel maken met de naam “new-sql-data ” en wijs het toe aan SQL02.dc.Local en SQL02.dc.Local , voer het volgende commando uit.
New-IscsiServerTarget -TargetName "new-sql-data" -InitiatorIds @("IQN:iqn.1991-05.com.microsoft:sql01.dc.local", "IQN:iqn.1991-05.com.microsoft:sql02.dc.local") Zodra het iSCSI-doel is gemaakt, moeten we onze virtuele schijf toewijzen aan het iSCSI-doel. Voer hiervoor de volgende query uit:
Add-IscsiVirtualDiskTargetMapping -TargetName new-sql-data –Path "F:\new-sql-data\new-sql-data.vhdx"
Zodra de doeltoewijzing met succes is voltooid, vernieuwt u het iSCSI-paneel voor virtuele schijven in Serverbeheer. Zie de volgende afbeelding:
Maak verbinding met de nieuwe iSCSI virtuele schijf met behulp van de iSCSI-initiator van failoverclusterknooppunten
Laten we nu verbinding maken met deze schijf vanaf de SQL01.dc.local knooppunt met behulp van RDP.
Om verbinding te maken met de virtuele iSCSI-schijf met behulp van de iSCSI-initiator, opent u de iSCSI-initiator en klikt u op Vernieuwen knop om het doel te ontdekken. Nu kunt u de juiste doelnaam kiezen uit de "Ontdekte doelen " tekstvak. Selecteer het juiste doel en klik op C verbinden . Zie de volgende afbeelding:
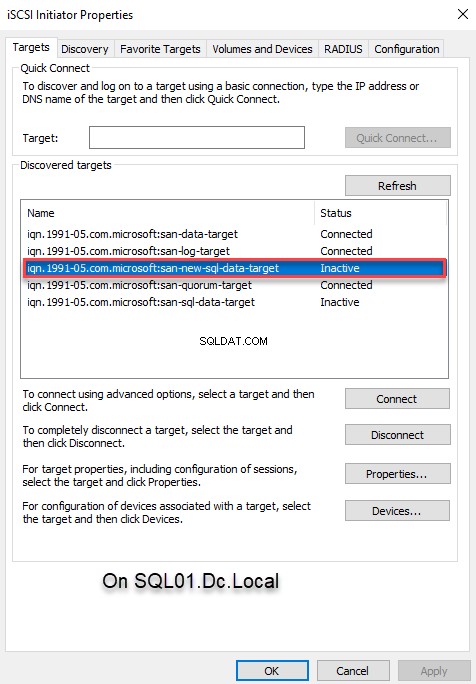
Zodra we zijn verbonden met de virtuele schijf, kunt u de schijf zien in de D isk M anager sectie onder C computer M management . Om de schijf binnen het cluster te gebruiken, moeten we de volgende taken uitvoeren:
- Breng de schijf online. Klik hiervoor met de rechtermuisknop op D isk 4 en selecteer Online . Zie de volgende afbeelding:
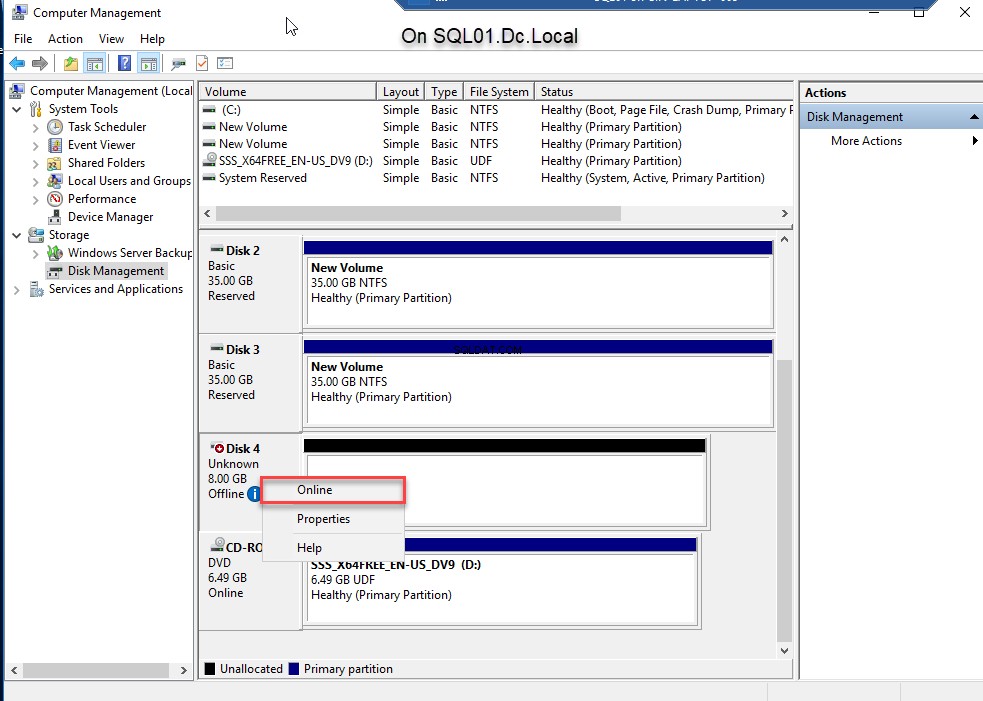
- Als de schijf online is, initialiseert u de schijf. Klik hiervoor met de rechtermuisknop op Schijf 4 en selecteer Schijf initialiseren . Zie de volgende afbeelding:
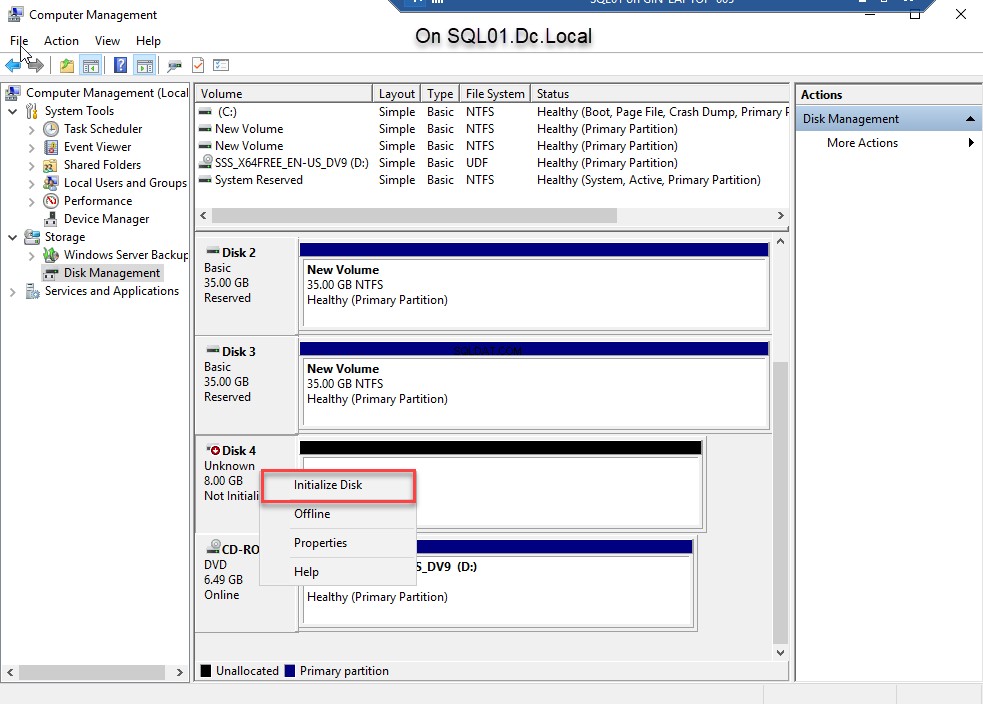
- Zodra de schijf is geïnitialiseerd, klikt u met de rechtermuisknop op Schijf 4 en selecteer Nieuw eenvoudig volume om een partitie te maken. Zie de volgende afbeelding:
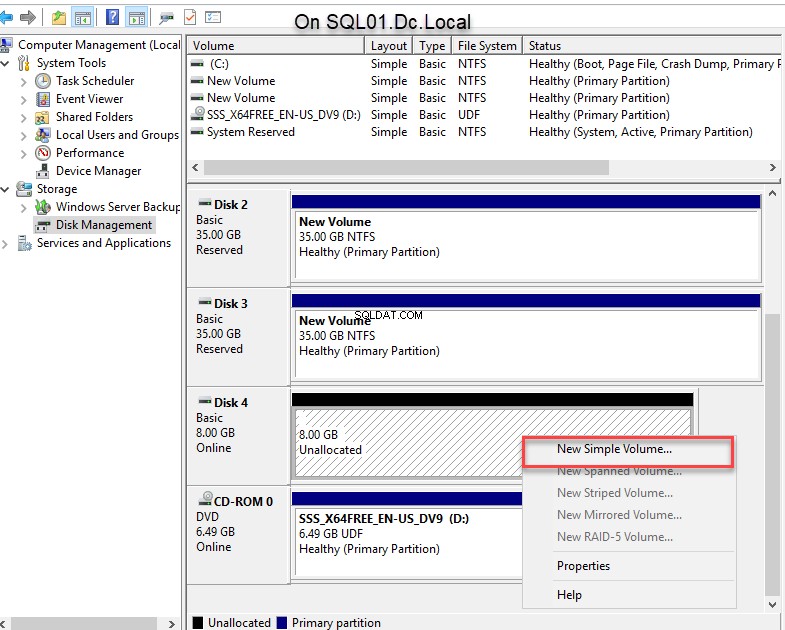
Op dezelfde manier moeten we de virtuele schijf verbinden vanaf de SQL02.dc.local knooppunt. Verbind hiervoor de SQL02.dc.local knooppunt met RDP, open de iSCSI-initiator en klik op Vernieuwen knop om het doel te ontdekken. Nu kunt u de juiste doelnaam kiezen uit de Ontdekte doelen tekstvak. Selecteer het juiste doel en klik op C verbinden . Zie de volgende afbeelding:
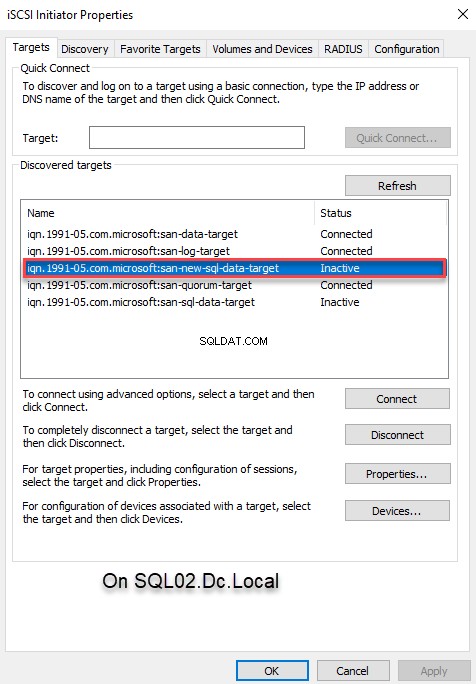
Voeg de nieuwe schijf toe aan een bestaande failover-clusteropslag.
Om deze schijf aan de clusteropslag toe te voegen, maakt u verbinding met SQL01.Dc.Local gebruik RDP, open de F overtocht C glans M anager , maak verbinding met SQLCluster.DC.Local , selecteer D isks in de linkerpan en klik op A dd schijf . Het dialoogvenster "Schijf toevoegen aan cluster" wordt geopend. In dit dialoogvenster wordt de nieuwe geclusterde schijf weergegeven. Zie de volgende afbeelding:
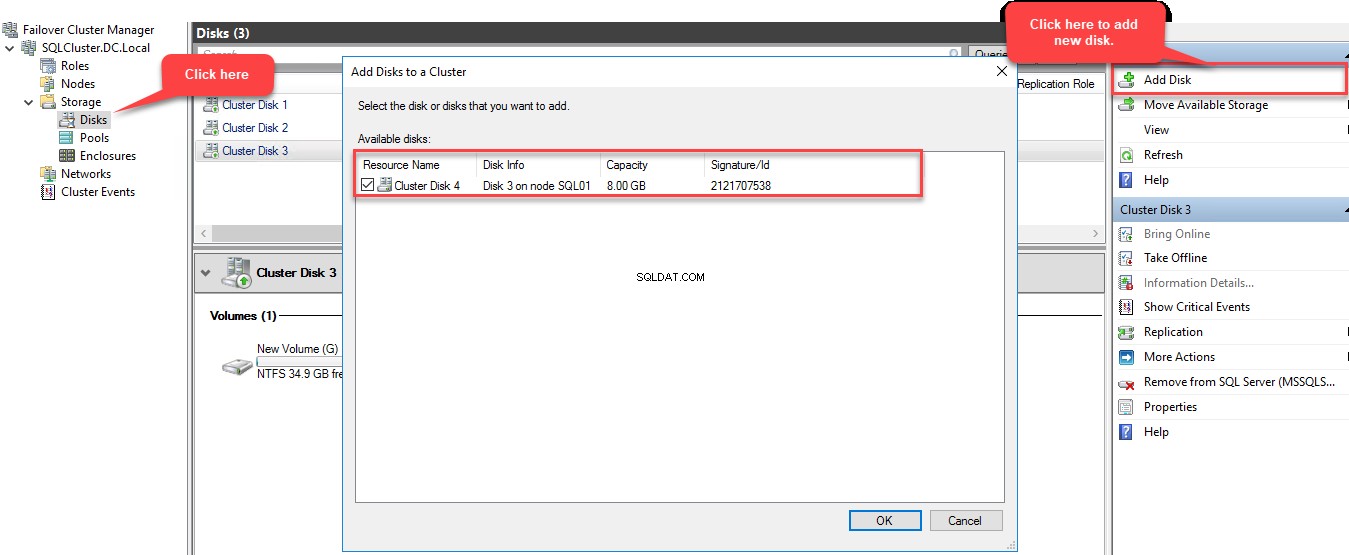
Zodra de nieuwe schijf is toegevoegd, kunt u deze zien in het schijfmenu van de Failover Cluster Manager. Zie de volgende afbeelding:
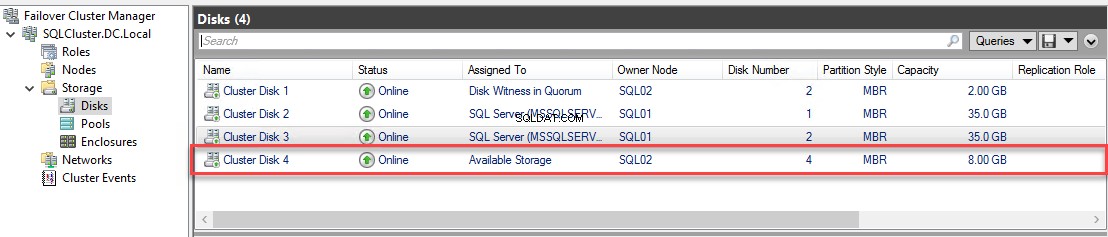
Verplaats het voorbeelddatabasebestand naar de nieuwe schijf.
Nadat de schijf is toegevoegd, gaan we een voorbeelddatabasebestand naar de nieuwe schijf verplaatsen. Ik heb een database gemaakt met de naam de modatabase op SQL01.dc.local . We willen het gegevensbestand naar de nieuwe schijf verplaatsen. Om dat te doen, maakt u verbinding met PowerShell en maakt u vervolgens verbinding met de SQL Server-instantie met behulp van de 'SQLCmd ’ commando.
Zodra u bent verbonden met de instantie, voert u de volgende opdracht uit om de database los te koppelen.
exec sp_detach_db [demodatabase] go
Zodra de database is losgekoppeld, kopieert u het gegevensbestand van station F (oude station) naar station E (nieuwe schijf) en voert u de volgende opdracht uit om de database te koppelen.
CREATE DATABASE demodatabase
ON (FILENAME = 'E:\SQLData\demodatabase.mdf'),
(FILENAME = 'F:\SQLLog\demodatabase_log.ldf')
FOR ATTACH;
GO Wanneer u de bovenstaande opdracht uitvoert, krijgt u de volgende foutmelding:
Msg 5184, Level 16, State 2, Server SQLCLUST, Line 1 Cannot use file 'E:\SQLData\demodatabase.mdf' for clustered server. Only formatted files on which the cluster resource of the server has a dependency can be used. Either the disk resource containing the file is not present in the cluster group or the cluster resource of the Sql Server does not have a dependency on it.
Deze fout treedt op omdat we de nieuwe schijf niet hebben toegevoegd aan de clusterbrongroep en aan de AND-afhankelijkheid van MSSQLSERVER-rol. Zie de volgende afbeelding:
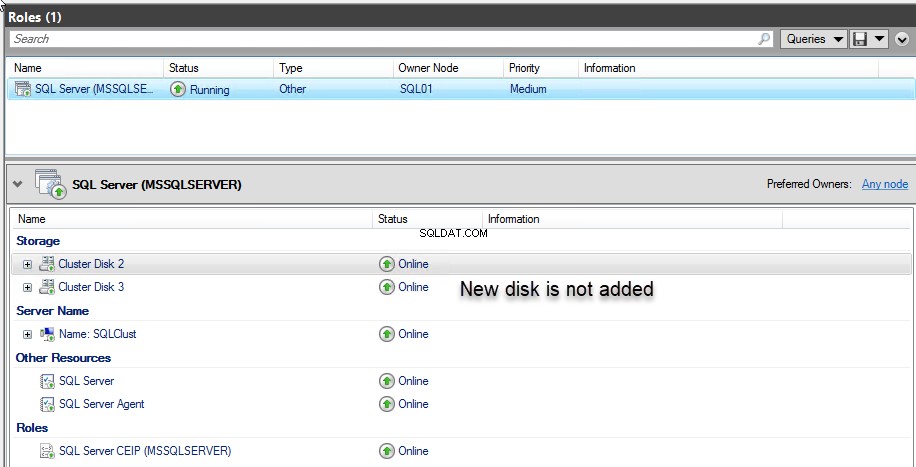
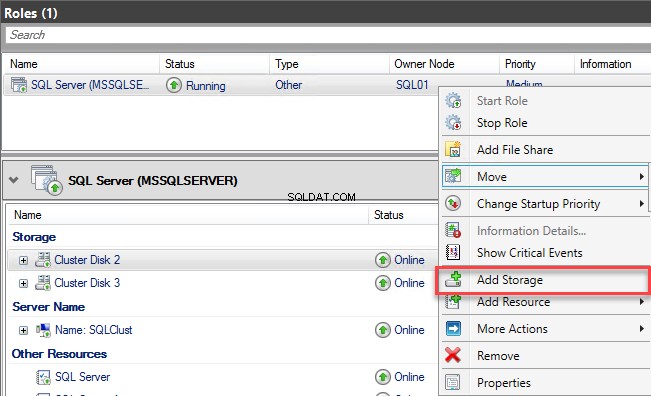
Om deze fout op te lossen, moeten we de nieuwe schijf toevoegen aan de MSSQLSERVER-rol. Open hiervoor de Failover Cluster Manager, klik op Rollen selecteren, klik met de rechtermuisknop op de SQL Server (MSSQLSERVER ) rol en kies Opslag toevoegen . Zie de volgende afbeelding:
De Opslag toevoegen dialoogvenster wordt geopend. Kies uit de lijst met beschikbare opslagruimte de schijf die we hebben gemaakt. Zie de volgende afbeelding:
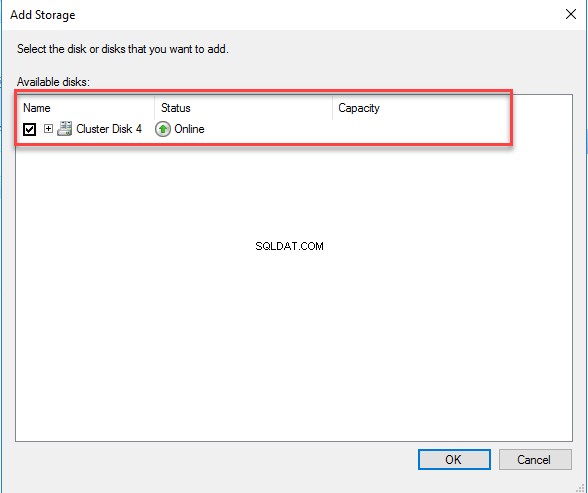
Zodra we de opslag hebben toegevoegd, kunnen we deze verifiëren vanaf het tabblad Resource van de MSSQLSERVER-rol. Zie de volgende afbeelding:
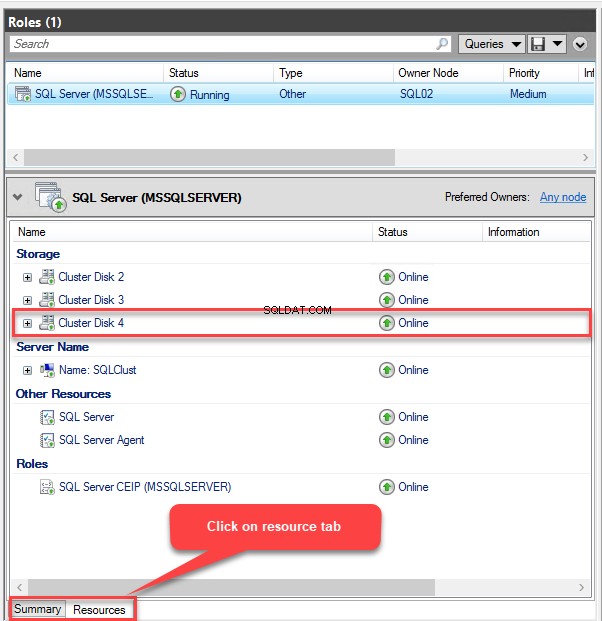
Zodra de schijf is toegevoegd, moeten we deze ook toevoegen aan de SQL Server AND-afhankelijkheid . Om dat te doen, klikt u met de rechtermuisknop op SQL Server in de lijst met bronnen onder de MSSQLSERVER rol en selecteer P roperties . In de P roperties dialoogvenster, ga naar de Afhankelijkheden en selecteer Clusterschijf 4 uit de vervolgkeuzelijst in de Bronnen kolom.
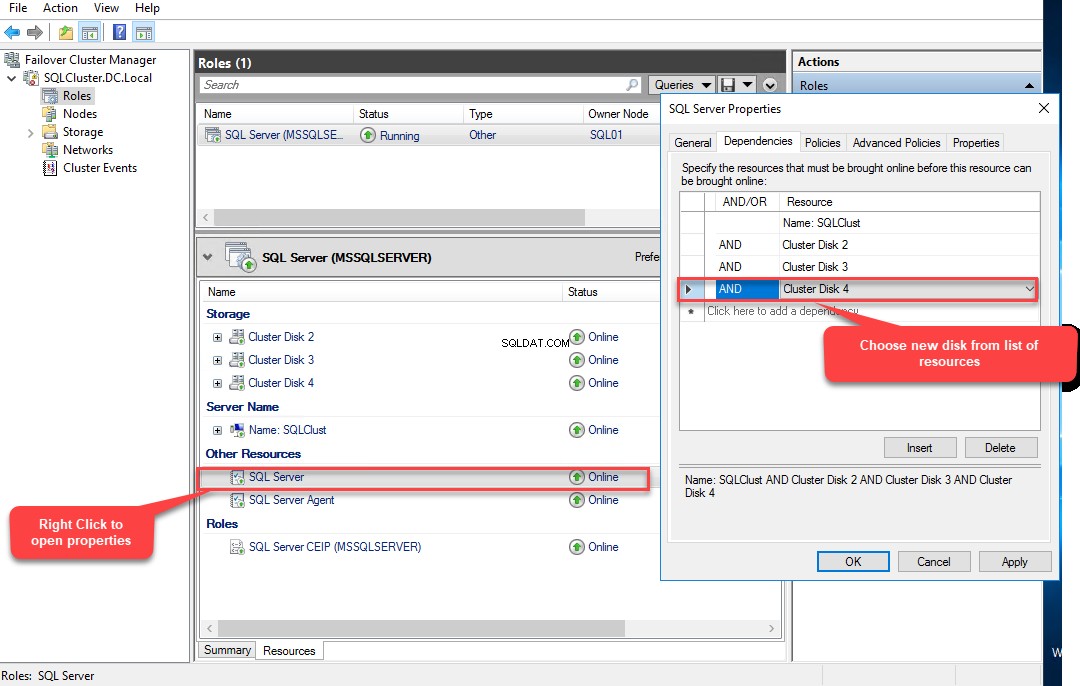
Zodra de schijfbron is toegevoegd, probeert u de database te koppelen met de volgende opdracht:
CREATE DATABASE demodatabase
ON (FILENAME = 'E:\SQLData\demodatabase.mdf'),
(FILENAME = 'F:\SQLLog\demodatabase_log.ldf')
FOR ATTACH;
GO De opdracht wordt met succes uitgevoerd. Voer de volgende query uit in PowerShell om te controleren of het bestand naar de juiste locatie is gekopieerd.
select db_name(database_id) as [database name], physical_name from sys.master_files where db_name(database_id) ='demodatabase'
Hieronder volgt de uitvoer:
Database Name physical_name ------------ --------------------------------- demodatabase E:\SQLData\demodatabase.mdf demodatabase F:\SQLLog\demodatabase_log.ldf
Zoals u kunt zien, is het databasebestand verplaatst naar de nieuwe schijf.
Samenvatting
In dit artikel heb ik uitgelegd dat het stapsgewijze proces van het toevoegen van een schijf aan een bestaande SQL Server-failover-geclusterde instantie. In het volgende artikel zal ik uitleggen hoe u systeemdatabases naar een nieuwe geclusterde schijf verplaatst.
Blijf op de hoogte!