Houd je nog steeds vast aan het bovenliggende/onderliggende ontwerp, of wil je iets nieuws proberen, zoals SQL Server hiërarchieID? Welnu, het is echt nieuw omdat hiërarchieID sinds 2008 deel uitmaakt van SQL Server. Natuurlijk is de nieuwigheid zelf geen overtuigend argument. Maar merk op dat Microsoft deze functie heeft toegevoegd om een-op-veel-relaties met meerdere niveaus op een betere manier weer te geven.
U vraagt zich misschien af wat voor verschil het maakt en welke voordelen u haalt uit het gebruik van hiërarchieID in plaats van de gebruikelijke ouder/kind-relaties. Als je deze optie nog nooit hebt onderzocht, is het misschien verrassend voor je.
De waarheid is dat ik deze optie niet heb onderzocht sinds deze is uitgebracht. Maar toen ik het eindelijk deed, vond ik het een geweldige innovatie. Het is een mooiere code, maar er zit veel meer in. In dit artikel gaan we meer te weten komen over al die uitstekende mogelijkheden.
Voordat we echter ingaan op de eigenaardigheden van het gebruik van SQL Server-hiërarchie-ID, laten we de betekenis en reikwijdte ervan verduidelijken.
Wat is SQL Server Hiërarchie-ID?
SQL Server-hiërarchie-ID is een ingebouwd gegevenstype dat is ontworpen om bomen weer te geven, het meest voorkomende type hiërarchische gegevens. Elk item in een boom wordt een knoop genoemd. In een tabelindeling is het een rij met een kolom van het gegevenstype hiërarchieID.
Meestal demonstreren we hiërarchieën met behulp van een tabelontwerp. Een ID-kolom vertegenwoordigt een knooppunt en een andere kolom staat voor de ouder. Met de SQL Server HiërarchieID hebben we slechts één kolom nodig met het gegevenstype hiërarchieID.
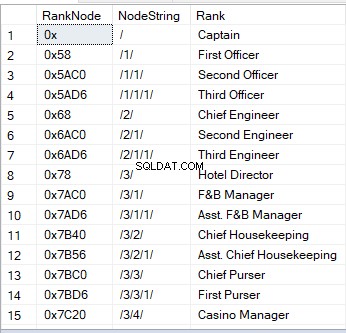
Wanneer u een query uitvoert op een tabel met een hiërarchieID-kolom, ziet u hexadecimale waarden. Het is een van de visuele beelden van een knoop. Een andere manier is een string:
'/' staat voor het hoofdknooppunt;
‘/1/’, ‘/2/’, ‘/3/’ of ‘/n/’ staan voor de kinderen – directe afstammelingen 1 t/m n;
'/1/1/' of '/1/2/' zijn de "kinderen van kinderen - "kleinkinderen". De string zoals '/1/2/' betekent dat het eerste kind van de wortel twee kinderen heeft, die op hun beurt twee kleinkinderen van de wortel zijn.
Hier is een voorbeeld van hoe het eruit ziet:
In tegenstelling tot andere gegevenstypen kunnen hiërarchieID-kolommen profiteren van ingebouwde methoden. Als u bijvoorbeeld een kolom hiërarchieID heeft met de naam RankNode , kunt u de volgende syntaxis hebben:
RankNode.
SQL Server HiërarchieID Methoden
Een van de beschikbare methoden is IsDescendantOf . Het retourneert 1 als het huidige knooppunt een afstammeling is van een hiërarchieID-waarde.
U kunt code schrijven met deze methode vergelijkbaar met de onderstaande:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Andere methoden die worden gebruikt met hiërarchieID zijn de volgende:
- GetRoot – de statische methode die de wortel van de boom teruggeeft.
- GetDescendant – retourneert een onderliggende node van een ouder.
- GetAncestor – retourneert een hiërarchieID die de n-de voorouder van een bepaald knooppunt vertegenwoordigt.
- GetLevel – retourneert een geheel getal dat de diepte van het knooppunt vertegenwoordigt.
- ToString – retourneert de string met de logische representatie van een knoop. ToString wordt impliciet aangeroepen wanneer de conversie van hiërarchieID naar het tekenreekstype plaatsvindt.
- GetReparentedValue – verplaatst een knooppunt van de oude bovenliggende naar de nieuwe bovenliggende.
- Parsen – werkt als het tegenovergestelde van ToString . Het converteert de tekenreeksweergave van een hiërarchieID waarde naar hexadecimaal.
SQL Server HiërarchieID Indexeringsstrategieën
Om ervoor te zorgen dat query's voor tabellen die gebruikmaken van hiërarchieID zo snel mogelijk worden uitgevoerd, moet u de kolom indexeren. Er zijn twee indexeringsstrategieën:
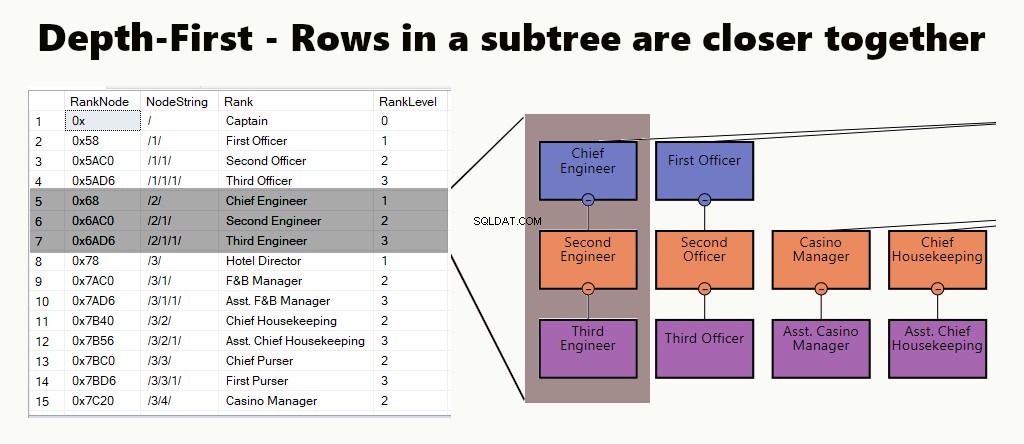
DIEPTE-EERSTE
In een depth-first index liggen de subboomrijen dichter bij elkaar. Het is geschikt voor vragen zoals het vinden van een afdeling, de subeenheden en werknemers. Een ander voorbeeld is een manager en zijn medewerkers die dichter bij elkaar zijn opgeslagen.
In een tabel kunt u een diepte-eerst-index implementeren door een geclusterde index voor de knooppunten te maken. Verder voeren we zomaar een van onze voorbeelden uit.
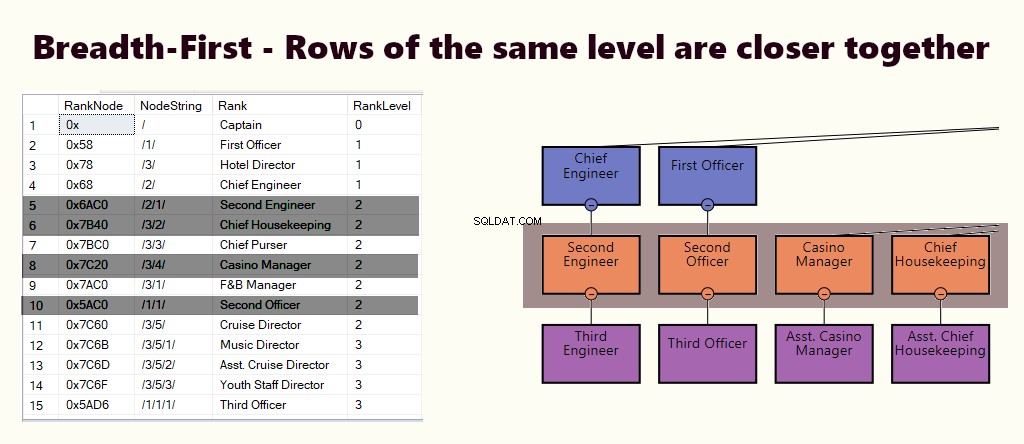
BREEDTE EERST
In een breedte-eerste index staan de rijen van hetzelfde niveau dichter bij elkaar. Het is geschikt voor vragen zoals het vinden van alle direct rapporterende medewerkers van de manager. Als de meeste zoekopdrachten hierop lijken, maak dan een geclusterde index op basis van (1) niveau en (2) knooppunt.
Het hangt af van uw vereisten of u een diepte-eerst-index, een breedte-eerst-index of beide nodig hebt. U moet een evenwicht vinden tussen het belang van het type query en de DML-instructies die u op de tafel uitvoert.
SQL Server HiërarchieID Beperkingen
Helaas kan het gebruik van hiërarchieID niet alle problemen oplossen:
- SQL Server kan niet raden wat het kind van een ouder is. U moet de boom in de tabel definiëren.
- Als u geen unieke beperking gebruikt, is de gegenereerde hiërarchieID-waarde niet uniek. Het oplossen van dit probleem is de verantwoordelijkheid van de ontwikkelaar.
- Relaties van een bovenliggende en onderliggende knooppunten worden niet afgedwongen zoals een externe-sleutelrelatie. Vraag daarom, voordat u een knoop verwijdert, naar eventuele bestaande nakomelingen.
Hiërarchieën visualiseren
Overweeg nog een vraag voordat we verder gaan. Als u naar de resultatenset met knooppuntreeksen kijkt, vindt u de hiërarchie moeilijk te visualiseren voor uw ogen?
Voor mij is het een groot ja, want ik word niet jonger.
Om deze reden gaan we Power BI en hiërarchiegrafiek van Akvelon gebruiken samen met onze databasetabellen. Ze zullen helpen om de hiërarchie weer te geven in een organigram. Ik hoop dat het het werk gemakkelijker zal maken.
Laten we nu aan de slag gaan.
Gebruik van SQL Server Hiërarchie-ID
U kunt HiërarchieID gebruiken met de volgende bedrijfsscenario's:
- Organisatiestructuur
- Mappen, submappen en bestanden
- Taken en subtaken in een project
- Pagina's en subpagina's van een website
- Geografische gegevens met landen, regio's en steden
Zelfs als uw bedrijfsscenario vergelijkbaar is met het bovenstaande en u zelden query's uitvoert op de hiërarchiesecties, heeft u hiërarchieID niet nodig.
Uw organisatie verwerkt bijvoorbeeld de loonlijsten van medewerkers. Heeft u toegang tot de substructuur nodig om iemands loonlijst te verwerken? Helemaal niet. Als je echter commissies van mensen verwerkt in een multi-level marketingsysteem, kan dat anders zijn.
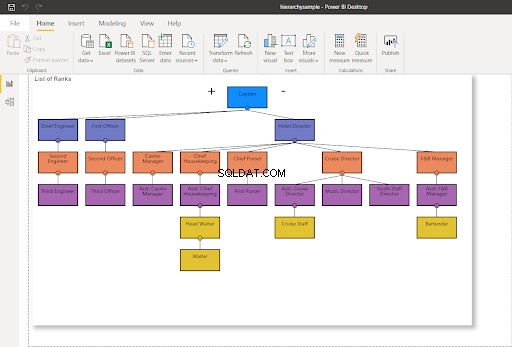
In deze post gebruiken we het deel van de organisatiestructuur en de commandostructuur op een cruiseschip. De structuur is vanaf hier aangepast vanuit het organigram. Bekijk het in Afbeelding 4 hieronder:

Nu kunt u de betreffende hiërarchie visualiseren. We gebruiken de onderstaande tabellen in dit bericht:
- Vaartuigen – staat de tafel voor de lijst van cruiseschepen.
- Ranglijsten – is de tabel met de rangen van de bemanning. Daar stellen we hiërarchieën vast met behulp van de hiërarchieID.
- Bemanning – is de lijst van de bemanning van elk vaartuig en hun rangen.
De tabelstructuur van elk geval is als volgt:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOTabelgegevens invoegen met SQL Server HierarchyID
De eerste taak bij het grondig gebruiken van hiërarchieID is om records aan de tabel toe te voegen met eenhiërarchieID kolom. Er zijn twee manieren om dit te doen.
Snaren gebruiken
De snelste manier om gegevens met hiërarchieID in te voegen, is door tekenreeksen te gebruiken. Laten we, om dit in actie te zien, enkele records toevoegen aan de Ranks tafel.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)De bovenstaande code voegt 20 records toe aan de Ranks-tabel.
Zoals u kunt zien, is de boomstructuur gedefinieerd in de INSERT verklaring hierboven. Het is gemakkelijk te onderscheiden wanneer we strings gebruiken. Bovendien converteert SQL Server het naar de corresponderende hexadecimale waarden.
Max(), GetAncestor() en GetDescendant() gebruiken
Het gebruik van strings past bij de taak van het vullen van de initiële gegevens. Op de lange termijn heb je de code nodig om het invoegen af te handelen zonder strings op te geven.
Om deze taak uit te voeren, haalt u het laatste knooppunt op dat door een ouder of voorouder is gebruikt. We bereiken dit door de functies MAX() . te gebruiken en GetAncestor() . Zie de voorbeeldcode hieronder:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Hieronder staan de punten uit de bovenstaande code:
- Eerst heb je een variabele nodig voor het laatste knooppunt en de direct leidinggevende.
- Het laatste knooppunt kan worden verkregen met MAX() tegen RankNode voor de opgegeven ouder of direct leidinggevende. In ons geval is dat de Assistant F&B Manager met een knooppuntwaarde van 0x7AD6.
- Gebruik vervolgens @ImmediateSuperior.GetDescendant(@MaxNode, NULL) om er zeker van te zijn dat er geen dubbel kind verschijnt. . De waarde in @MaxNode is het laatste kind. Als het niet NULL is , GetDescendant() geeft de volgende mogelijke knoopwaarde terug.
- Laatste, GetLevel() geeft het niveau terug van het nieuwe knooppunt dat is gemaakt.
Gegevens opvragen
Nadat u records aan onze tabel hebt toegevoegd, is het tijd om deze op te vragen. Er zijn 2 manieren om gegevens op te vragen:
De vraag naar directe afstammelingen
Als we de medewerkers zoeken die rechtstreeks aan de manager rapporteren, moeten we twee dingen weten:
- De knooppuntwaarde van de manager of ouder
- Het niveau van de medewerker onder de manager
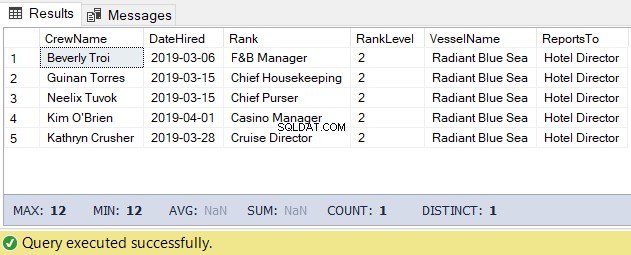
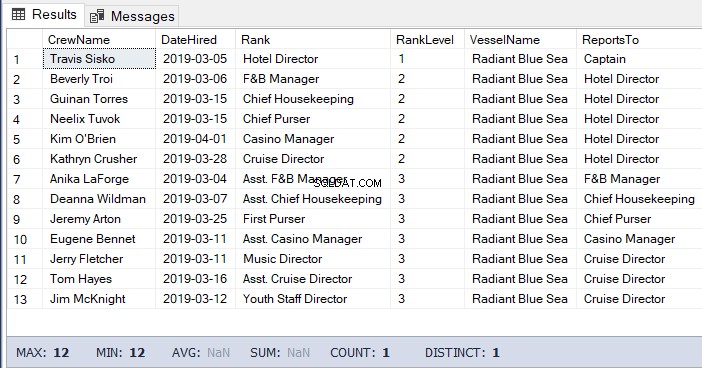
Voor deze taak kunnen we de onderstaande code gebruiken. De output is de lijst van de bemanning onder de hoteldirecteur.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorHet resultaat van de bovenstaande code is als volgt in figuur 5:
Query voor substructuren
Soms moet je ook de kinderen en de kinderen van de kinderen tot op de bodem opsommen. Om dit te doen, moet u de hiërarchieID van de ouder hebben.
De query zal vergelijkbaar zijn met de vorige code, maar zonder de noodzaak om het niveau te krijgen. Zie het codevoorbeeld:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Het resultaat van de bovenstaande code:
Knooppunten verplaatsen met SQL Server HierarchyID
Een andere standaardbewerking met hiërarchische gegevens is het verplaatsen van een kind of een hele substructuur naar een ander bovenliggend element. Houd echter rekening met één mogelijk probleem voordat we verder gaan:
Potentieel probleem
- Ten eerste hebben bewegende knooppunten I/O nodig. Hoe vaak u knooppunten verplaatst, kan de beslissende factor zijn als u hiërarchieID of de gebruikelijke ouder/kind gebruikt.
- Ten tweede wordt het verplaatsen van een knooppunt in een bovenliggend/onderliggend ontwerp één rij bijgewerkt. Wanneer u tegelijkertijd een knooppunt met hiërarchie-ID verplaatst, worden een of meer rijen bijgewerkt. Het aantal betrokken rijen hangt af van de diepte van het hiërarchieniveau. Het kan een aanzienlijk prestatieprobleem worden.
Oplossing
U kunt dit probleem oplossen met uw database-ontwerp.
Laten we eens kijken naar het ontwerp dat we hier hebben gebruikt.
In plaats van de hiërarchie te definiëren op de Bemanning tabel, we hebben het gedefinieerd in de Ranks tafel. Deze aanpak verschilt van de Medewerker tabel in de AdventureWorks voorbeelddatabase, en het biedt de volgende voordelen:
- De bemanningsleden verplaatsen zich vaker dan de rangen in een vaartuig. Dit ontwerp zal de bewegingen van knooppunten in de hiërarchie verminderen. Als resultaat minimaliseert het het hierboven gedefinieerde probleem.
- Meer dan één hiërarchie definiëren in de Bemanning tabel is ingewikkelder, omdat twee schepen twee kapiteins nodig hebben. Het resultaat is twee hoofdknooppunten.
- Als je alle rangen met het bijbehorende bemanningslid wilt weergeven, kun je een LEFT JOIN gebruiken. Als er niemand aan boord is voor die rang, wordt er een leeg vakje voor de positie weergegeven.
Laten we nu verder gaan met het doel van deze sectie. Voeg onderliggende knooppunten toe onder de verkeerde ouders.
Om te visualiseren wat we gaan doen, stel je een hiërarchie voor zoals die hieronder. Let op de gele knooppunten.

Een knoop zonder kinderen verplaatsen
Het verplaatsen van een onderliggende node vereist het volgende:
- Definieer de hiërarchieID van het onderliggende knooppunt dat moet worden verplaatst.
- Definieer de hiërarchie-ID van de oude ouder.
- Definieer de hiërarchie-ID van de nieuwe ouder.
- Gebruik UPDATE met GetReparentedValue() om het knooppunt fysiek te verplaatsen.
Begin met het verplaatsen van een knoop zonder kinderen. In het onderstaande voorbeeld verplaatsen we de Cruise Staff van onder de Cruise Director naar onder de Asst. Cruisedirecteur.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
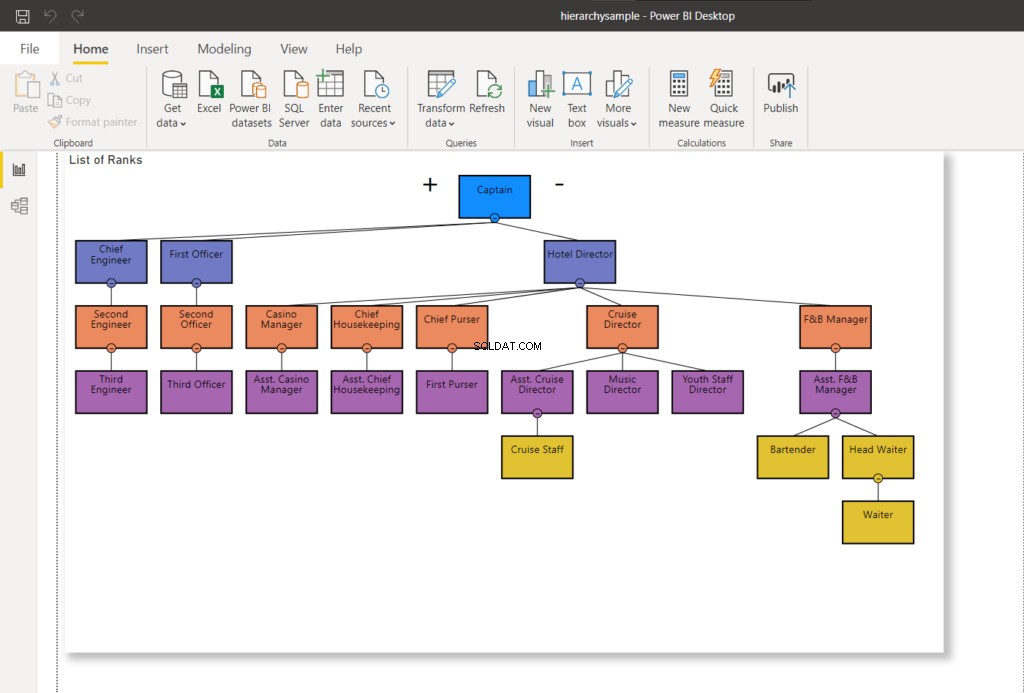
WHERE RankNode = @NodeToMoveZodra het knooppunt is bijgewerkt, wordt een nieuwe hexadecimale waarde voor het knooppunt gebruikt. Mijn Power BI-verbinding met SQL Server vernieuwen - het zal de hiërarchiegrafiek wijzigen zoals hieronder weergegeven:
In figuur 8 rapporteert het Cruise-personeel niet langer aan de Cruise Director - het is veranderd om te rapporteren aan de Assistant Cruise Director. Vergelijk het met Afbeelding 7 hierboven.
Laten we nu doorgaan naar de volgende fase en de hoofdkelner verplaatsen naar de assistent F&B-manager.
Een knoop met kinderen verplaatsen
Er zit een uitdaging in dit onderdeel.
Het punt is dat de vorige code niet werkt met een knooppunt met zelfs maar één kind. We herinneren ons dat het verplaatsen van een knooppunt vereist is om een of meer onderliggende knooppunten bij te werken.
Verder houdt het daar niet op. Als de nieuwe ouder een bestaand kind heeft, kunnen we dubbele knooppuntwaarden tegenkomen.
In dit voorbeeld moeten we dat probleem onder ogen zien:de Asst. F&B Manager heeft een Bartender-kinderknooppunt.
Klaar? Hier is de code:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;In het bovenstaande codevoorbeeld begint de iteratie als de noodzaak om het knooppunt naar het kind op het laatste niveau over te dragen.
Nadat je het hebt uitgevoerd, worden de Ranks tabel wordt bijgewerkt. En nogmaals, als u de wijzigingen visueel wilt zien, vernieuw dan het Power BI-rapport. U ziet de wijzigingen vergelijkbaar met die hieronder:
Voordelen van het gebruik van SQL Server-hiërarchie-ID versus ouder/kind
Om iemand te overtuigen een functie te gebruiken, moeten we de voordelen kennen.
Daarom zullen we in deze sectie uitspraken vergelijken met dezelfde tabellen als die van het begin. De ene gebruikt hiërarchieID en de andere gebruikt de bovenliggende/kind-benadering. De resultatenset zal voor beide benaderingen hetzelfde zijn. We verwachten het voor deze oefening als die van Afbeelding 6 hierboven.
Nu de vereisten precies zijn, gaan we de voordelen grondig onderzoeken.
Eenvoudiger te coderen
Zie onderstaande code:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Dit voorbeeld heeft alleen een hiërarchieID-waarde nodig. U kunt de waarde naar believen wijzigen zonder de query te wijzigen.
Vergelijk nu de verklaring voor de ouder/kind-benadering die dezelfde resultatenset oplevert:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Wat denk je? De codevoorbeelden zijn bijna hetzelfde, behalve één punt.
De WAAR clausule in de tweede query zal niet flexibel zijn om aan te passen als een andere substructuur vereist is.
Maak de tweede query generiek genoeg, en de code zal langer zijn. Klopt!
Sneller uitvoering
Volgens Microsoft zijn "substructuurquery's aanzienlijk sneller met hiërarchieID" in vergelijking met bovenliggende/onderliggende. Laten we eens kijken of het waar is.
We gebruiken dezelfde query's als eerder. Een belangrijke statistiek om te gebruiken voor prestaties zijn de logische uitlezingen van de STEL STATISTIEKEN IO . Het vertelt hoeveel pagina's van 8 KB SQL Server nodig heeft om de gewenste resultatenset te krijgen. Hoe hoger de waarde, hoe groter het aantal pagina's dat SQL Server opent en leest, en hoe langzamer de query wordt uitgevoerd. Voer STEL STATISTIEKEN IN IO IN uit en voer de twee bovenstaande query's opnieuw uit. De laagste waarde van de logische uitlezingen zal de winnaar zijn.
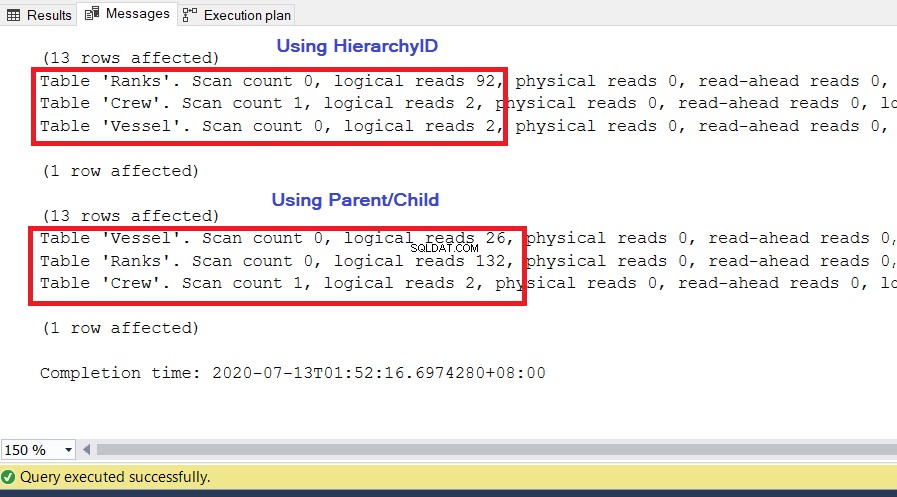
ANALYSE
Zoals u kunt zien in afbeelding 10, hebben de I/O-statistieken voor de query met hiërarchie-ID lagere logische waarden dan hun bovenliggende/onderliggende tegenhangers. Let op de volgende punten in dit resultaat:
- Het Vaartuig tafel is de meest opvallende van de drie tafels. Het gebruik van hiërarchieID vereist slechts 2 * 8KB =16KB aan pagina's die door SQL Server uit de cache (geheugen) moeten worden gelezen. Ondertussen vereist het gebruik van ouder/kind 26 * 8 KB =208 KB aan pagina's - aanzienlijk hoger dan het gebruik van hiërarchieID.
- De Ranglijsten tabel, die onze definitie van hiërarchieën bevat, vereist 92 * 8 KB =736 KB. Aan de andere kant vereist het gebruik van ouder/kind 132 * 8 KB =1056 KB.
- De Bemanning tabel heeft 2 * 8 KB =16 KB nodig, wat hetzelfde is voor beide benaderingen.
Kilobytes aan pagina's is misschien een kleine waarde voor nu, maar we hebben maar een paar records. Het geeft ons echter een idee van hoe belastend onze zoekopdracht op elke server zal zijn. Om de prestaties te verbeteren, kunt u een of meer van de volgende acties uitvoeren:
- Voeg geschikte index(en) toe
- De query herstructureren
- Statistieken bijwerken
Als u het bovenstaande deed en de logische uitlezingen zouden afnemen zonder meer records toe te voegen, zouden de prestaties toenemen. Zolang je de logische waarden lager maakt dan voor degene die hiërarchieID gebruikt, is dat goed nieuws.
Maar waarom verwijzen naar logische uitlezingen in plaats van verstreken tijd?
De verstreken tijd voor beide zoekopdrachten controleren met STEL STATISTIEKEN TIJD AAN onthult een klein aantal millisecondenverschillen voor onze kleine set gegevens. Ook kan uw ontwikkelserver een andere hardwareconfiguratie, SQL Server-instellingen en werkbelasting hebben. Een verstreken tijd van minder dan een milliseconde kan u misleiden of uw zoekopdracht zo snel presteert als u verwacht of niet.
VERDER GRADEN
STEL STATISTIEKEN IO IN onthult niet wat er "achter de schermen" gebeurt. In deze sectie komen we erachter waarom SQL Server met die cijfers arriveert door naar het uitvoeringsplan te kijken.
Laten we beginnen met het uitvoeringsplan van de eerste query.
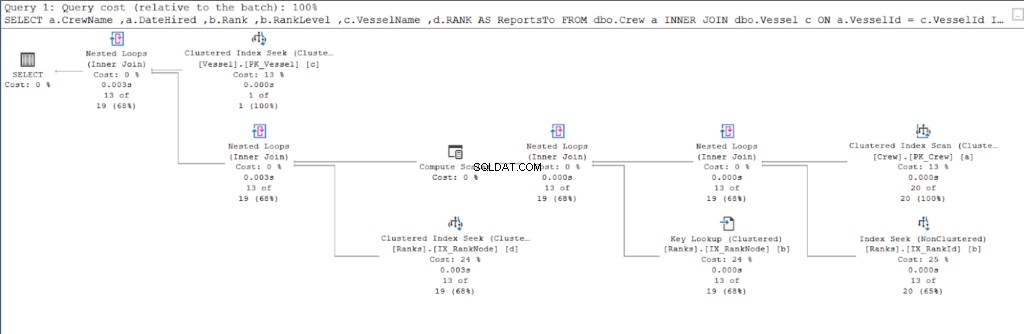
Kijk nu naar het uitvoeringsplan van de tweede query.
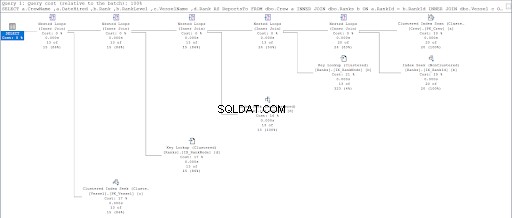
Als we Figuren 11 en 12 vergelijken, zien we dat SQL Server extra inspanning nodig heeft om de resultatenset te produceren als u de parent/child-benadering gebruikt. De WAAR clausule is verantwoordelijk voor deze complicatie.
De fout kan echter ook in het ontwerp van de tafel liggen. We gebruikten dezelfde tabel voor beide benaderingen:de Ranks tafel. Dus ik probeerde de Ranglijsten te dupliceren tabel, maar gebruik verschillende geclusterde indexen die geschikt zijn voor elke procedure.
In het resultaat had het gebruik van hiërarchieID nog steeds minder logische leesbewerkingen in vergelijking met de bovenliggende/onderliggende tegenhanger. Ten slotte hebben we bewezen dat Microsoft gelijk had door het te claimen.
Conclusie
Hier is het centrale aha-moment voor hiërarchieID:
- HierarchyID is een ingebouwd gegevenstype dat is ontworpen voor een meer geoptimaliseerde weergave van bomen, het meest voorkomende type hiërarchische gegevens.
- Elk item in de structuur is een knooppunt en hiërarchieID-waarden kunnen in hexadecimale of tekenreeksindeling zijn.
- HierarchyID is van toepassing op gegevens van organisatiestructuren, projecttaken, geografische gegevens en dergelijke.
- Er zijn methoden voor het doorkruisen en manipuleren van hiërarchische gegevens, zoals GetAncestor (), GetDescendant (). GetLevel (), GetReparentedValue (), en meer.
- De conventionele manier om hiërarchische gegevens op te vragen is om de directe afstammelingen van een knooppunt te krijgen of de subbomen onder een knooppunt te krijgen.
- Het gebruik van hiërarchieID voor het opvragen van substructuren is niet alleen eenvoudiger te coderen. Het presteert ook beter dan ouder/kind.
Ouder / kind-ontwerp is helemaal niet slecht, en dit bericht is niet om het te verminderen. Het uitbreiden van de mogelijkheden en het introduceren van nieuwe ideeën is echter altijd een groot voordeel voor een ontwikkelaar.
U kunt de voorbeelden die we hier hebben aangeboden zelf uitproberen. Ontvang de effecten en kijk hoe u deze kunt toepassen voor uw volgende project met hiërarchieën.
Als je het bericht en de ideeën ervan leuk vindt, kun je het verspreiden door op de deelknoppen voor de gewenste sociale media te klikken.